JavaScript 事件循环:从起源到浏览器再到 Node.js
很多文章都在讨论事件循环 (Event Loop) 是什么,而几乎没有人讨论为什么 JavaScript 中会有事件循环。博主认为这是为什么很多人都不能很好理解事件循环的一个重要原因 —— 知其然不知其所以然。所以本文试图抛砖引玉,从一些更溯源的方式来与大家探讨 event loop,希望大家能从中有些收获。
本文从三个角度来研究 JavaScript 的事件循环:
- 为什么是事件循环
- 事件循环是什么
- 浏览器与 Node.js 的事件循环差异
为什么是事件循环
JavaScript 是网景 (Netscape) 公司为其旗下的网景浏览器提供更复杂网页交互时所推出的一个动态脚本语言。其创作者 Eich 在 10 天内写出了 JavaScript 的第一个版本,通过 Eich 在 JavaScript 20 周年的演讲回顾中,我们可以发现 JavaScript 在最初设计的时候没有考虑所谓的事件循环。那么事件循环到底是怎么出现的?
首先让我们来看看引入 JavaScript 到网页端的经典用例:一个用户打开一个网页,填写完表单提交之后,等待 30s 的白屏之后发现表单中的某个地方填写错误了需要重新填写。在这个场景中,如果我们有 JavaScript 就可以在用户提交表单之前先在用户本地的浏览器端做一次校验,避免用户每次都通过网络找服务端来校验所浪费的时间。
分析一下这个场景,我们就可以发现,最早的 JavaScript 的执行就是用户通过浏览器的事件来触发的,例如用户填写完表单之后点击提交的时候,浏览器触发一个 DOM 的点击事件,而点击事件绑定了对应的 JavaScript 代码来执行校验的过程。在这个过程中,JavaScript 的代码都是被动被调用的。
仔细思考一下就会发现,JavaScript 所谓的事件和触发本质上都通过浏览器中转,更像是浏览器行为而不仅仅是 JavaScript 语言内的一个队列。顺着这个思路我们顺藤摸瓜,就会发现 EcmaScript 的标准定义中压根 就没有事件循环,反倒是 HTML 的标准中定义了事件循环(目前 HTML 有 whatwg 和 w3c 标准,这里讨论的是 wahtwg 的标准):
To coordinate events, user interaction, scripts, rendering, networking, and so forth, user agents must use event loops as described in this section. Each agent has an associated event loop, which is unique to that agent.
根据标准中对事件循环的定义描述,我们可以发现事件循环本质上是 user agent (如浏览器端) 用于协调用户交互(鼠标、键盘)、脚本(如 JavaScript)、渲染(如 HTML DOM、CSS 样式)、网络等行为的一个机制。
了解到这个定义之后,我们就能够清楚的知道,与其说是 JavaScript 提供了事件循环,不如说是嵌入 JavaScript 的 user agent 需要通过事件循环来与多种事件源交互。
事件循环是什么
所以说事件循环本质是一个 user agent 上协调各类事件的机制,而这一节我们主要讨论一下浏览器中的这个机制与 JavaScript 的交互部分。
各种浏览器事件同时触发时,肯定有一个先来后到的排队问题。决定这些事件如何排队触发的机制,就是事件循环。这个排队行为以 JavaScript 开发者的角度来看,主要是分成两个队列:
- 一个是 JavaScript 外部的队列。外部的队列主要是浏览器协调的各类事件的队列,标准文件中称之为 Task Queue。下文中为了方便理解统一称为外部队列。
- 另一个是 JavaScript 内部的队列。这部分主要是 JavaScript 内部执行的任务队列,标准中称之为 Microtask Queue。下文中为了方便理解统一称为内部队列。
值得注意的是,虽然为了好理解我们管这个叫队列 (Queue),但是本质上是有序集合 (Set),因为传统的队列都是先进先出(FIFO)的,而这里的队列则不然,排到最前面但是没有满足条件也是不会执行的(比如外部队列里只有一个 setTimeout 的定时任务,但是时间还没有到,没有满足条件也不会把他出列来执行)。
▐ 外部队列
外部队列(Task Queue [1]),顾名思义就是 JavaScript 外部的事件的队列,这里我们可以先列举一下浏览器中这些外部事件源(Task Source),他们主要有:
- DOM 操作 (页面渲染)
- 用户交互 (鼠标、键盘)
- 网络请求 (Ajax 等)
- History API 操作
- 定时器 (setTimeout 等) [2]
可以观察到,这些外部的事件源可能很多,为了方便浏览器厂商优化,HTML 标准中明确指出一个事件循环由一个或多个外部队列,而每一个外部事件源都有一个对应的外部队列。不同事件源的队列可以有不同的优先级(例如在网络事件和用户交互之间,浏览器可以优先处理鼠标行为,从而让用户感觉更加流程)。
▐ 内部队列
内部队列(Microtask Queue),即 JavaScript 语言内部的事件队列,在 HTML 标准中,并没有明确规定这个队列的事件源,通常认为有以下几种:
- Promise 的成功 (.then) 与失败 (.catch)
- MutationObserver
- Object.observe (已废弃)
▐ 处理模型
在标准定义中事件循环的步骤比较复杂,这里我们简单描述一下这个处理过程:
- 从外部队列中取出一个可执行任务,如果有则执行,没有下一步。
- 挨个取出内部队列中的所有任务执行,执行完毕或没有则下一步。
- 浏览器渲染。
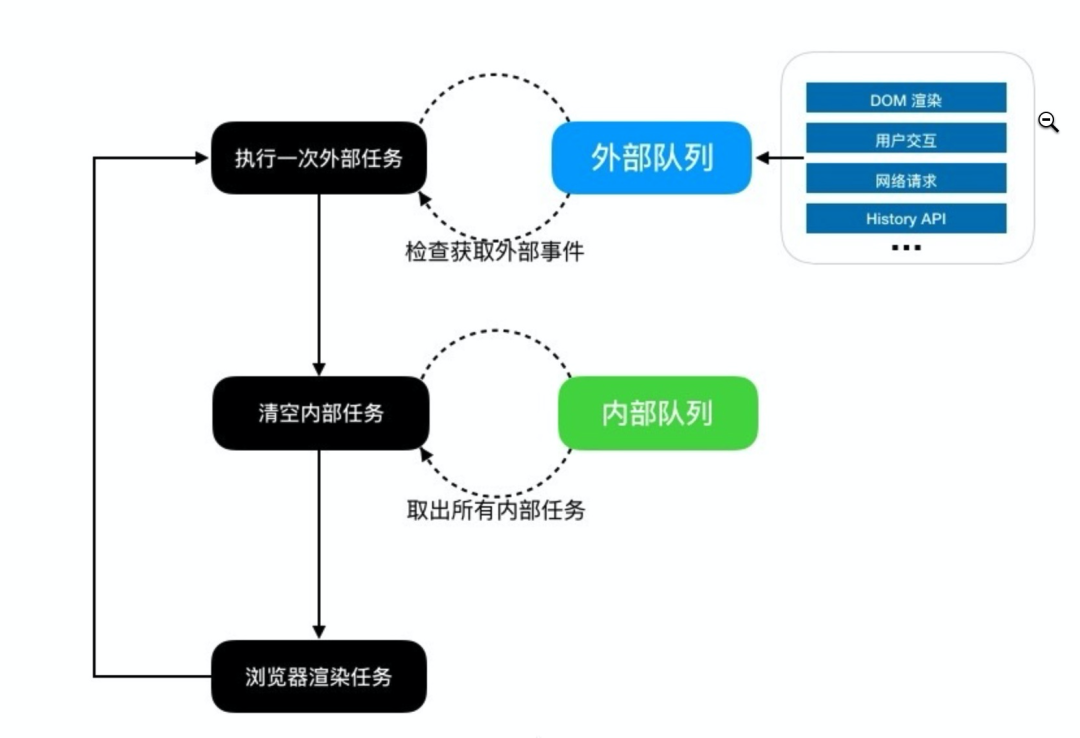
▐ 案例分析
根据上述的处理模型,我们可以来看以下例子:
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
Promise.resolve().then(function() {
console.log('promise1');
}).then(function() {
console.log('promise2');
});
console.log('script end');输出结果:
script start
script end
promise1
promise2
setTimeout对应的处理过程则是:
- 执行 console.log (输出 script start)
- 遇到 setTimeout 加入外部队列
- 遇到两个 Promise 的 then 加入内部队列
- 遇到 console.log 直接执行(输出 script end)
- 内部队列中的任务挨个执行完 (输出 promise1 和 promise2)
- 外部队列中的任务执行 (输出 setTimeout)
只要理解了外部队列与内部队列的概念,再看这类问题就会变得很简单,我们再简单扩展看看:
setTimeout(() => {
console.log('setTimeout1')
})
Promise.resolve().then(() => {
console.log('promise1')
})
setTimeout(() => {
console.log('setTimeout2')
})
Promise.resolve().then(() => {
console.log('promise2')
})
Promise.resolve().then(() => {
console.log('promise3')
})
console.log('script end');结果输出:
script end
promise1
promise2
promise3
setTimeout1
setTimeout2可以发现加入内部队列的顺序和时间虽然后差异,但是轮到内部队列执行的时候,一定会先全部执行完内部队列才会继续往下走去执行外部队列的任务。
最后我们再看一个引入了 HTML 渲染的例子:
<html>
<body>
<pre id="main"></pre>
</body>
<script>
const main = document.querySelector('#main');
const callback = (i, fn) => () => {
console.log(i)
main.innerText += fn(i);
};
let i = 1;
while(i++ < 5000) {
setTimeout(callback(i, (i) => '\n' + i + '<'))
}
while(i++ < 10000) {
Promise.resolve().then(callback(i, (i) => i +','))
}
console.log(i)
main.innerText += '[end ' + i + ' ]\n'
</script>
</html>通过这个例子,我们就可以发现,渲染过程很明显分成三个阶段:
- JavaScript 执行完毕 innerText 首先加上 [end 10001]
- 内部队列:Promise 的 then 全部任务执行完毕,往 innerText 上追加了很长一段字符串
- HTML 渲染:1 和 2 追加到 innerText 上的内容同时渲染
- 外部队列:挨个执行 setTimeout 中追加到 innerText 的内容
- HTML 渲染:将 4 中的内容渲染。
- 回到第 4 步走外部队列的流程(内部队列已清空)
▐ script 事件是外部队列
有的同学看完上面的几个例子之后可能有个问题,为什么 JavaScript 代码执行到 script end 之后,是先执行内部队列然后再执行外部队列的任务?
这里不得不把上文总出现过的 HTML 事件循环标准 再拉出来一遍:
To coordinate events, user interaction, scripts, rendering, networking, and so forth, user agents must use event loops as described in this section...
看到这里,大家可能就反应过来了,scripts 执行也是一个事件,我们只要归类一下就会发现 JavaScript 的执行也是一个浏览器发起的外部事件。所以本质的执行顺序还是:
- 一次外部事件
- 所有内部事件
- HTML 渲染
- 回到到 1
浏览器与 Node.js 的事件循环差异
根据本文开头我们讨论的事件循环起源,很容易理解为什么浏览器与 Node.js 的事件循环会存在差异。如果说浏览端是将 JavaScript 集成到 HTML 的事件循环之中,那么 Node.js 则是将 JavaScript 集成到 libuv 的 I/O 循环之中。
简而言之,二者都是把 JavaScript 集成到他们各自的环境中,但是 HTML (浏览器端) 与 libuv (服务端) 面对的场景有很大的差异。首先能直观感受到的区别是:
- 事件循环的过程没有 HTML 渲染。只剩下了外部队列和内部队列这两个部分。
- 外部队列的事件源不同。Node.js 端没有了鼠标等外设但是新增了文件等 IO。
- 内部队列的事件仅剩下 Promise 的 then 和 catch。
至于内在的差异,有一个很重要的地方是 Node.js (libuv)在最初设计的时候是允许执行多次外部的事件再切换到内部队列的,而浏览器端一次事件循环只允许执行一次外部事件。这个经典的内在差异,可以通过以下例子来观察:
setTimeout(()=>{
console.log('timer1');
Promise.resolve().then(function() {
console.log('promise1');
});
});
setTimeout(()=>{
console.log('timer2');
Promise.resolve().then(function() {
console.log('promise2');
});
});这个例子在浏览器端执行的结果是 timer1 -> promise1 -> timer2 -> promise2,而在 Node.js 早期版本(11 之前)执行的结果却是 timer1 -> timer2 -> promise1 -> promise2。
究其原因,主要是因为浏览器端有外部队列一次事件循环只能执行一个的限制,而在 Node.js 中则放开了这个限制,允许外部队列中所有任务都执行完再切换到内部队列。所以他们的情况对应为:
▐ 浏览器端
- 外部队列:代码执行,两个 timeout 加入外部队列
- 内部队列:空
- 外部队列:第一个 timeout 执行,promise 加入内部队列
- 内部队列:执行第一个 promise
- 外部队列:第二个 timeout 执行,promise 加入内部队列
- 内部队列:执行第二个 promise
▐ Node.js 服务端
- 外部队列:代码执行,两个 timeout 加入外部队列
- 内部队列:空
- 外部队列:两个 timeout 都执行完
- 内部队列:两个 promise 都执行完
虽然 Node.js 的这个问题在 11 之后的版本里修复了,但是为了继续探究这个影响,我们引入一个新的外部事件 setImmediate。这个方法目前是 Node.js 独有的,浏览器端没有。
setImmediate 的引入是为了解决 setTimeout 的精度问题,由于 setTimeout 指定的延迟时间是毫秒(ms)但实际一次时间循环的时间可能是纳秒级的,所以在一次事件循环的多个外部队列中,找到某一个队列直接执行其中的 callback 可以得到比 setTimeout 更早执行的效果。我们继续以开始的场景构造一个例子,并在 Node.js 10.x 的版本上执行(存在一次事件循环执行多次外部事件):
setTimeout(()=>{
console.log('setTimeout1');
Promise.resolve().then(() => console.log('promise1'));
});
setTimeout(()=>{
console.log('setTimeout2');
Promise.resolve().then(() => console.log('promise2'));
});
setImmediate(() => {
console.log('setImmediate1');
Promise.resolve().then(() => console.log('promise3'));
});
setImmediate(() => {
console.log('setImmediate2');
Promise.resolve().then(() => console.log('promise4'));
});输出结果:
setImmediate1setImmediate2
promise3
promise4
setTimeout1
setTimeout2
promise1
promise2根据这个执行结果 [3],我们可以推测出 Node.js 中的事件循环与浏览器类似,也是外部队列与内部队列的循环,而 setImmediate 在另外一个外部队列中。
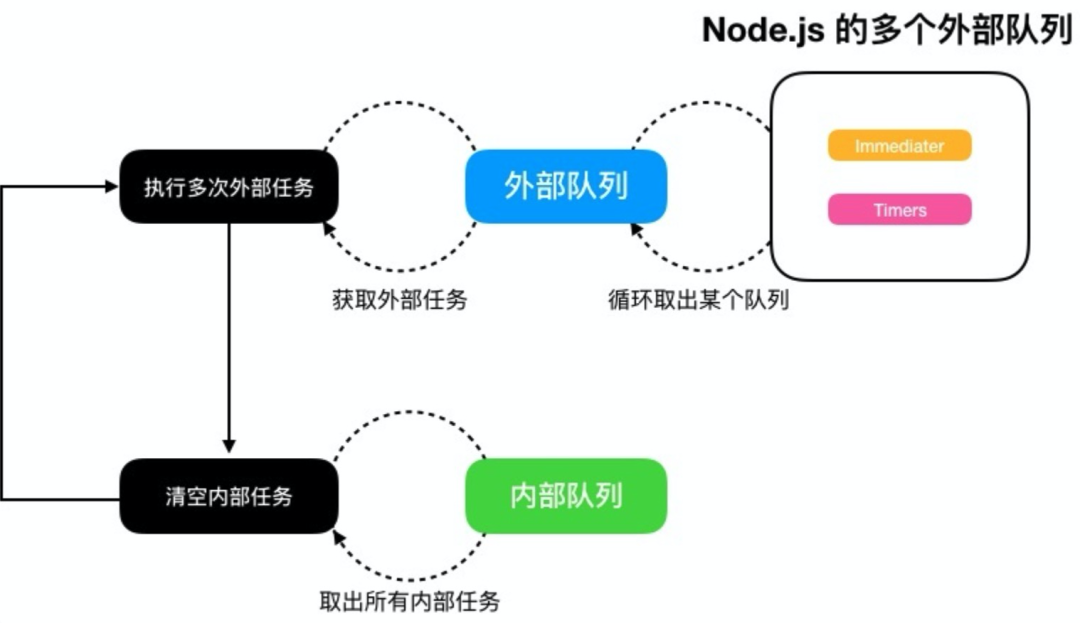
接下来,我们再来看一下当 Node.js 在与浏览器端对齐了事件循环的事件之后,这个例子的执行结果为:
setImmediate1
promise3
setImmediate2
promise4
setTimeout1
promise1
setTimeout2
promise2其中主要有两点需要关注,一是外部列队在每次事件循环只执行了一个,另一个是 Node.js 的固定了多个外部队列的优先级。setImmediate 的外部队列没有执行完的时候,是不会执行 timeout 的外部队列的。了解了这个点之后,Node.js 的事件循环就变得很简单了,我们可以看下 Node.js 官方文档中对于事件循环顺序的展示:
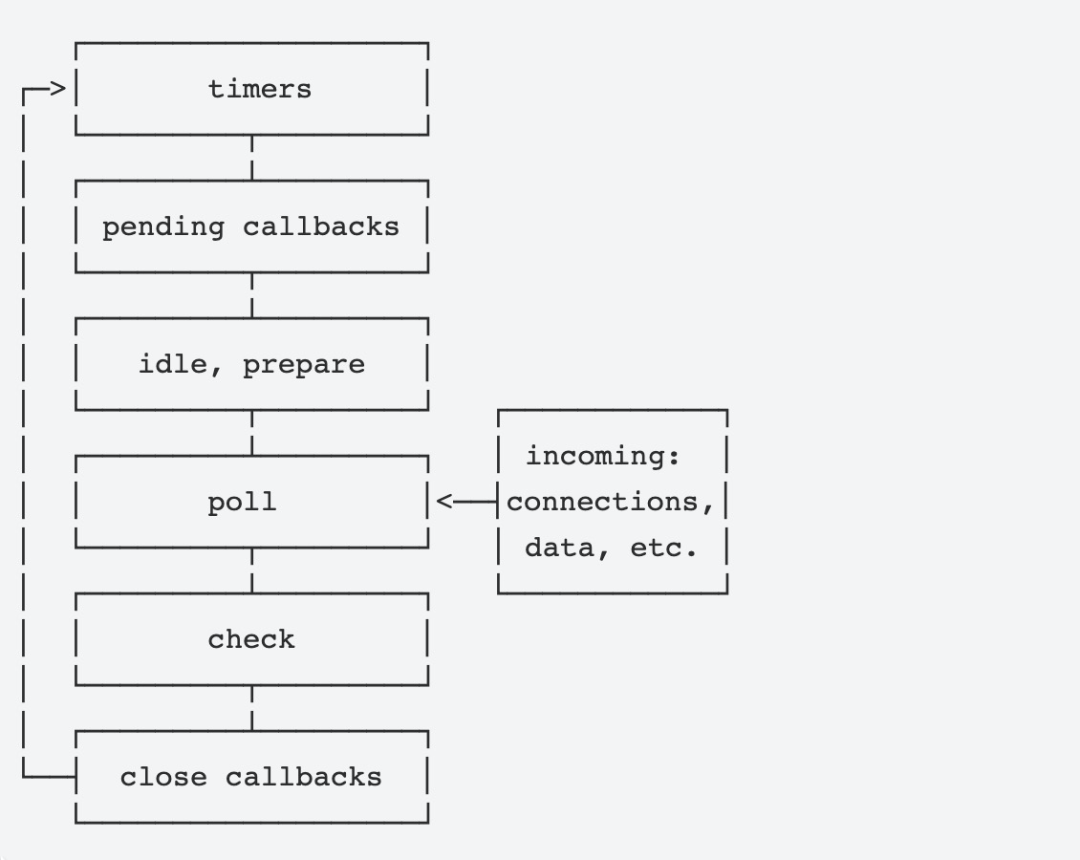
其中 check 阶段是用于执行 setImmediate 事件的。结合本文上面的推论我们可以知道,Node.js 官方这个所谓事件循环过程,其实只是完整的事件循环中 Node.js 的多个外部队列相互之间的优先级顺序。
我们可以在加入一个 poll 阶段的例子来看这个循环:
const fs = require('fs');
setImmediate(() => {
console.log('setImmediate');
});
fs.readdir(__dirname, () => {
console.log('fs.readdir');
});
setTimeout(()=>{
console.log('setTimeout');
});
Promise.resolve().then(() => {
console.log('promise');
});输出结果(v12.x):
promise
setTimeout
fs.readdir
setImmediate根据输出结果,我们可以知道梳理出来:
- 外部队列:执行当前 script
- 内部队列:执行 promise
- 外部队列:执行 setTimeout
- 内部队列:空
- 外部队列:执行 fs.readdir
- 内部队列:空
- 外部队列:执行 check (setImmediate)
这个顺序符合 Node.js 对其外部队列的优先级定义:
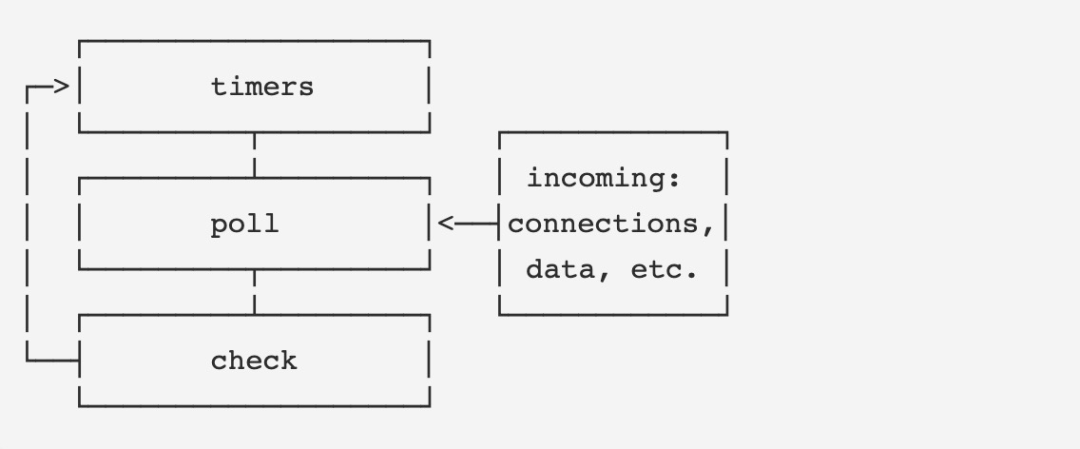
timer(setTimeout)是第一阶段的原因在 libuv 的文档中有描述 —— 为了减少时间相关的系统调用(System Call)。setImmediate 出现在 check 阶段是蹭了 libuv 中 poll 阶段之后的检查过程(这个过程放在 poll 中也很奇怪,放在 poll 之后感觉比较合适)。
idle, prepare 对应的是 libuv 中的两个叫做 idle 和 prepare 的句柄。由于 I/O 的 poll 过程可能阻塞住事件循环,所以这两个句柄主要是用来触发 poll (阻塞)之前需要触发的回调:

至此 Node.js 多个外部队列的优先级已经演化到类似原版的程度。最后剩下的 socket close 为什么是在 check 和 timers 之间,这个具体的权衡留待大家一起探讨。
关于浏览器与 Node.js 的事件循环,如果你要问我那边更加简单,那么我肯定会说是 Node.js 的事件循环更加简单,因为它的多个外部队列是可枚举的并且优先级是固定的。但是浏览器端在对它的多个外部队列做优先级排列的时候,我们一没法枚举,二不清楚其优先级策略,甚至浏览器端的事件循环可能是基于多线程或者多进程的(HTML 的标准中并没有规定一定要使用单线程来实现事件循环)。
小结
我们都知道浏览器端是直面用户的,这也意味着浏览器端会更加注重用户的体验(如可见性、可交互性),如果有一个优化效果是能够极大的减少 JavaScript 的执行时间,但要消耗更多 HTML 渲染的时间的话,通常来说我们都不会做这个优化。通过这个例子来观察,可以发现我们在浏览器并不是主要关注某件事整体所消耗的时间是否更少,而是用户是否能快的体验到交互(感受到 HTML 渲染)。而到了 Node.js 这个服务端 JavaScript 的场景下,这一点是明确不一样的。在服务端为了保持应用的流畅,早期甚至出现了一次事件循环执行多个外部事件的优化方式。
很多同学在理解事件循环时感到隔靴搔痒的一个重要原因,便是把事件循环与 JavaScript 的关系弄错了。JavaScript 的事件循环与其说是 JavaScript 的语言特性,更准确的理解应该是某个设备/端(如浏览器)的事件循环中与 JavaScript 交互的部分。
造成浏览器端与 Node.js 端事件循环的差异的一个很大的原因在于 。事件循环的设计初衷更多的是方便 JavaScript 与其嵌入环境的交互,所以事件循环如何运作,也更多的会受到 JavaScript 嵌入环境的影响,不同的设备、嵌入式环境甚至是不同的浏览器都会有各自的想法。
注 [1]: 关于 Task,常有人称它为 Marcotask (宏任务),但 HTML 标准中没有这种说法。 注 [2]: 定时器操作主要依赖 JavaScript 外部的 agent 实现。所以归类为外部事件。 注 [3]: 这里 setTimeout 在 setImmediate 后面执行的原因是因为 ms 精度的问题,想要手动 fix 这个精度可以插入一段 const now = Date.now(); wihle (Date.now() < now + 1) {} 即可看到 setTimeout 在 setImmediate 之前执行了。
参考文献:
https://html.spec.whatwg.org/multipage/webappapis.html#event-loops https://nodejs.org/zh-cn/docs/guides/event-loop-timers-and-nexttick/#what-is-the-event-loop https://zhuanlan.zhihu.com/p/34229323 https://juejin.im/post/5c337ae06fb9a049bc4cd218