腾讯广告 3000+万行大代码库主干开发实战
互联网行业竞争激烈,产品迭代快,其中研发效能越来越成为跑赢竞争对手的重要影响因素。需求两天就能上线和两个星期才能上线,结果可能大相径庭。本文总结了腾讯广告系统主要采用的目前业界标杆公司引领的单代码仓库+主干开发+城际快线发布模式,供大家参考,以此作为对我个人两年多以来专职从事工程效能工作的一个总结,也欢迎大家多提宝贵意见。
基本概念
单一代码仓库
相信很多人都看过这篇文章:

Google 用的是自己开发的[piper]系统:
[https://medium.com/@gitship/which-version-control-tool-is-google-using-how-is-it-proving-useful-for-it-7fbde4296fbf]
Facebook 为此魔改了 mercurial 代码管理系统:
[https://engineering.fb.com/2014/01/07/core-data/scaling-mercurial-at-facebook/]
而 Microsoft 则选择了在 git 上做文章,开发了 git 虚拟文件系统:
[https://docs.microsoft.com/en-us/azure/devops/learn/git/git-at-scale]
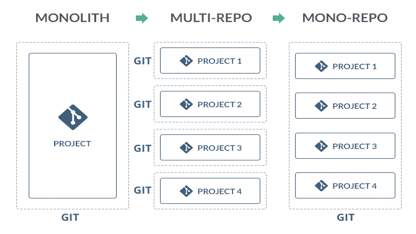
为什么这些公司都选择了单一代码仓库呢?简单说来,单代码仓库的主要好处有:
- 方便代码复用,减少重复劳动
- 方便跨语言共享代码,提高开发效率
- 让有问题的代码尽早暴露,降低修复成本
- 方便实施原子提交,减少 CI 失败
- 方便实施代码重构,减慢代码腐化
- 不用考虑兼容旧版本,消除了可怕的菱形依赖
- 方便实施统一的工具检查,减少不同技术团队重复建设
- 方便实施主干开发模式
有工蜂加持,虽然我们搞不定全公司的单仓,但是经过努力,保持了在广告系统内半个 BG(AMS)单仓的持续运转,也颇不容易,背后的故事值得一说。
主干开发模式
主干开发,顾名思义,就是在主干上开发。但是主干开发并非完全不要分支,在 SVN 时代,我们确实是在主干上直接修改、发 CR、提交的,但是在切换到 git 后,我们用短生命周期的分支(变更不超过数百行,工作量不超过一天)来实现主干开发。
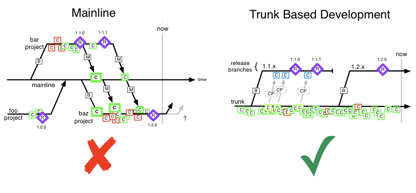
在主干开发分支模式下,还要有发布分支,发布评审系统自动/手动从主干上合适的点拉出发布分支,保持其相对稳定,只有 bugfix 和紧急需求才会从主干上 cherry-pick 的方式合入新的变更。
主干开发模式下,配合持续集成系统,可以得到最快的反馈速度,有 bug 的代码很快就会被发现,也更容易被定位和修改。当然如果缺乏足够的保障机制,也更容易引发问题。
单一代码库往往采用主干开发模式,因为在大量开发人员频繁修改的大代码库上合并长期分支的难度是地狱级的,而主干开发模式离开单一代码库,其价值也大打折扣。
城际快线发布模式
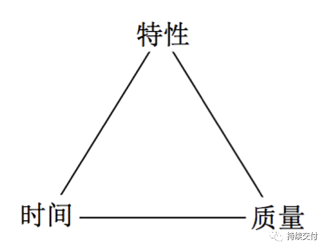
在乔梁老师的《持续交付 2.0》中,从特性、时间、质量三个角度总结了三种发布模式:
• 项目制发布模式(Project Release Mode) 先规划好版本的功能点和期限,比如 Windows 的各个版本。• 传统版本火车模式(Release Train Mode) 按季度/半年交付,比如 JDK 半年一个版本。• 城际快线模式(Intercity Express Mode) 两周~一天的发布节奏,甚至更快。
其中城际快线发布模式是目前最适合互联网产品节奏的发布模式。
我们的实践
我们经过长期的学习摸索实践以及工具平台建设,在广告系统内实现了单一代码库主干开发,城际快线发布模式。支持了重要的核心业务模块一天一发甚至一天多发(不少服务因为业务需求没那么多本身发布频率较低,按需发布的模式更合适),有力地支持了业务需求的快速上线。
代码库管理
广告系统内并非只有一个代码仓库。不过至少后台部分的绝大部分代码都在一个叫 main 的仓库里,这个代码库的规模:
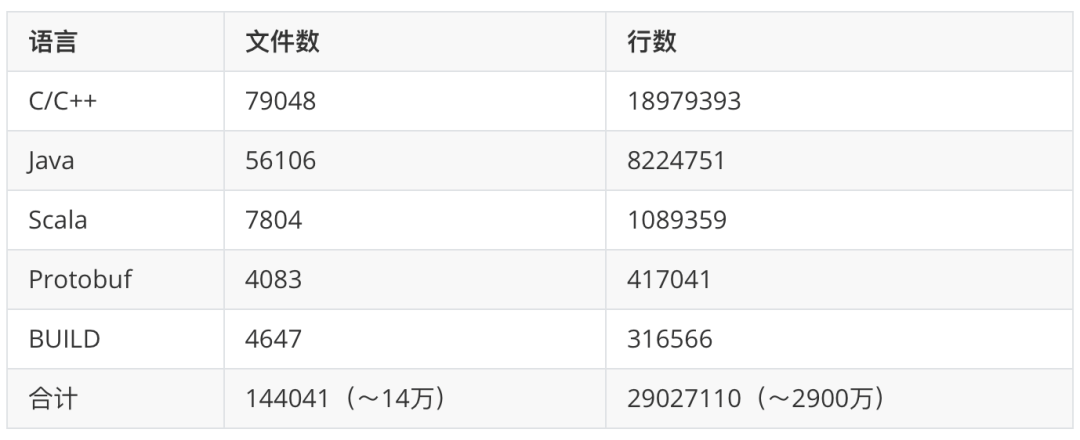
- 只统计了最常见的几种语言
- 包含第三方代码
- 不包含生成的文件
Git 的挑战
目前代码库 clone 后占 37GB,其中.git 目录占 15G。我们的代码库原来在 SVN 上,迁移 git 前,发现直接迁移问题比较大,分析后发现有不少二进制文件(历史遗留原因),采取了如下措施:
- 截断历史,只保留到 2019 年 7 月 1 日,之前的仍然到 SVN 上去查。
- 使用 LFS 存放大文件,并且通过下述 legit 工具限制大文件必须用 LFS。
- 在代码评审和合并阶段控制大文件进入。
工蜂团队对广告系统代码库从 SVN 迁移到 GIT 做了大量的服务、帮助和指导,特此感谢。
用 OWNERS 文件控制权限
由于 GIT 的权限控制模型,在单一代码库下每个用户要么完全没有权限,要么只读,要么可以读写。我们鼓励“代码共有”,但是不同的项目和子项目还是要有明确的负责人。
我们用 OWNERS 机制来管理代码权限:

OWNERS 机制并非原创,而是来自 Google(在 Chromium 和 k8s 项目中也能看到它的影子,我们参考的是Chromium 项目的语法并做了扩充,而k8s 则用的 YAML 格式,看起来更好一些,也许考虑将来跟进),公司的 SVN 系统上本来也支持类似的语法,不过工蜂系统里不再支持了。因此我们迁移到了新的语法,并在底层换成了下述的 legit 来保证实施。
通过 OWNERS 文件,即使你不是某个目录或者文件的 OWNER,只要其 OWNERS 通过你的 CR,就能修改其中的代码,实现了代码的可控公有。通过 OWNERS 文件,也能明确项目各自的归属,方便后续做各种数据度量和驱动工作。
保密代码构建系统
虽然我们确保代码尽量开放,但是作为涉及到大量利益的商业产品,广告系统其实也是有一些代码需要保密的,比如一些重要的算法、策略等,这部分代码不开放给所有的人。但是我们不希望把这些代码编译成库放到代码库里,这不但可能导致二进制兼容问题(我们的基础库只保证源代码兼容不保证二进制兼容),而且还会成为编译器升级的障碍,并增加代码丢失的风险。
因此我们把这些代码放在多个分散权限控制的仓库里,并且通过保密代码构建系统在有专用的服务器上用专用账号构建这些代码,并返回二进制的构建结果(.o 文件)。
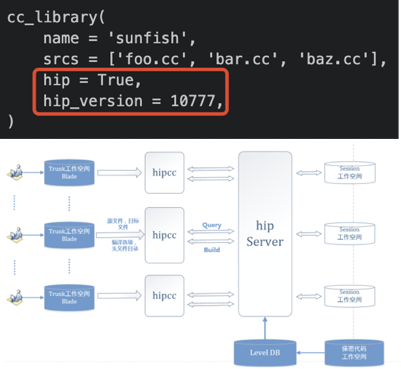
保密代码在远程编译时,使用的是开发者本地的头文件,从而确保二进制兼容性。
质量保证体系
代码评审
腾讯广告系统从 2013 年就强制要求代码评审,养成了良好的技术氛围,做到了"让 CodeReview 成为一种习惯"。我们在 legit(下面会详细描述)上加入了 Push 前的代码检查,拦截了大量有问题的 Push,让评审者看到的代码基本上没有这些低级问题,提高了评审的质量和效率。
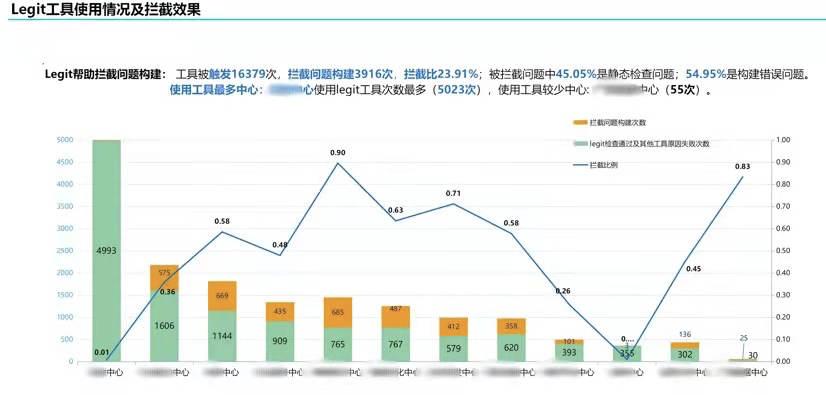
- 由于 legit 对 js 检查还有些欠缺,最左侧的中心更依赖蓝盾上的 codecc 工具,因此数据表现有差异。
持续集成
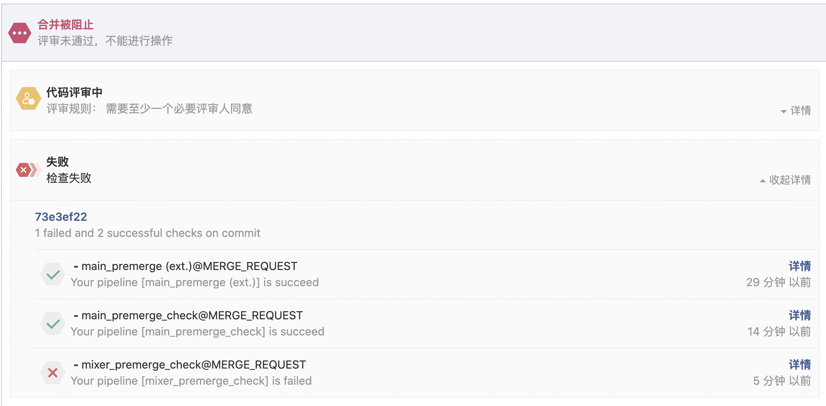
因为代码库较大,拆成了多个 premerge 流水线以增加并行度,premerge 失败的 MR 不能合入主干。
单元测试
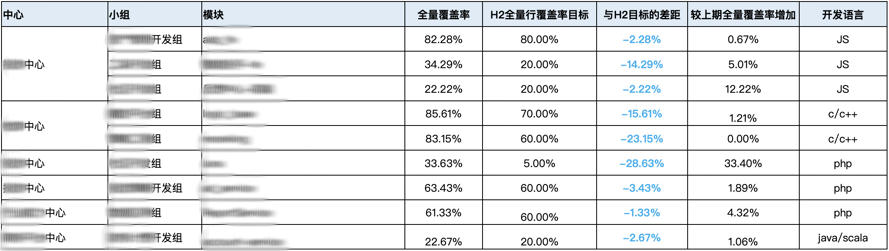
我们很早就要求写单元测试,通过 OWNES 文件自动识别模块归属,落实到各个中心/小组。
回归测试
我们开发了 Lego 的系统进行环境搭建回归测试。lego 基于容器技术,能够在服务调度的拓扑图中根据需要创建出一套隔离的子集环境。
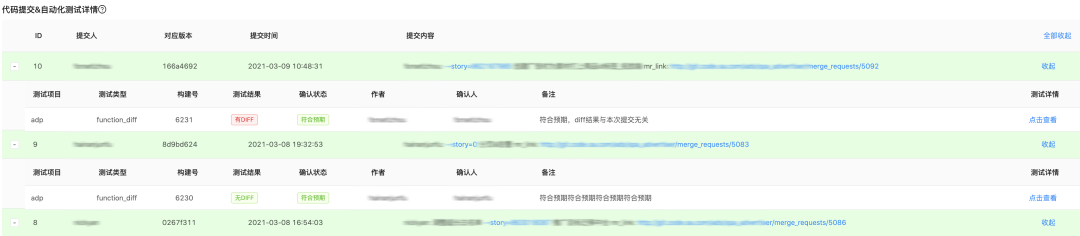
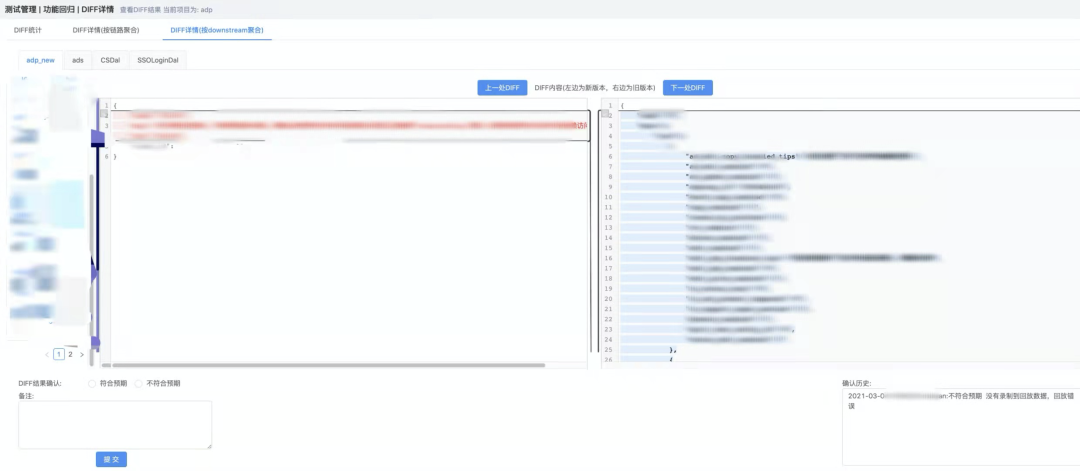
基于 lego 系统,测试团队搭建了自动化回归平台,可以对每次代码合入对请求和回应的影响做出精确对比,方便业务开发人员确认是否有问题。
特性开关
主干开发模式下,代码库中会有开发中的特性,这些特性并不适合发布到线上。业界通常用特性开关(FeatureFlags)来解决这个问题。
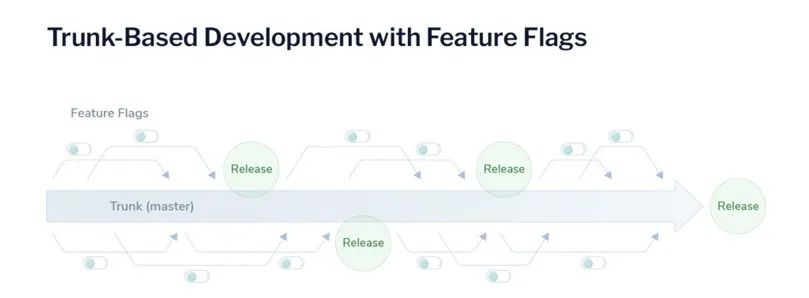
规范地讲,特性开关的生存期不应该太长,否则会引起“特性开关技术债务”,因为每个有效的特性开关在代码中都至少对应着一条 if 语句,引起函数的圈复杂度增加。过于已经固化的特性,应当限期清理掉。但是实际上却有很多特性开关不敢轻易删除。
其中原因之一,就是业务开发人员如果不是对代码特别熟,可能不知道这个开关是否真的还在使用,贸然删除可能会导致错误乃至事故。如果每个开关都引入监控项,使用成本又增加了很多。
因此我们开发了在线的特性开关管理系统。对每个开关的访问情况作出统计。
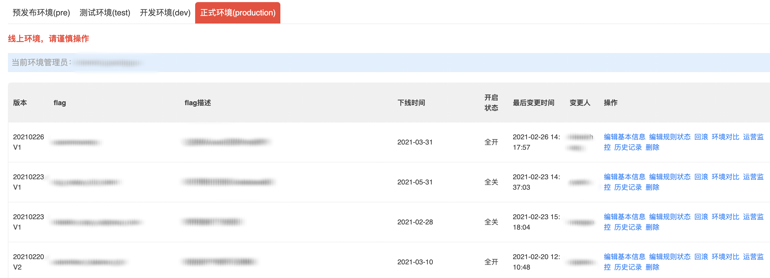
系统在开关快要到达期限前,就会自动通过企业微信通知其开发人员删除,并且在真正删除之前也会检查是否还有有效的请求。
特性开关管理系统也支持以配置文件为主的方式,此时在线系统就成为特性开关的查看和监控系统,了解系统有多少特性开关,使用情况如何。
特性开关系统也支持对一些上下文参数(IP,用户 id 等,广告位 id)等通过开发人员配置的表达式动态判断是否开启。
发布评审和自动发布
我们开发了 LeFlow 发布评审系统和自动发布系统。
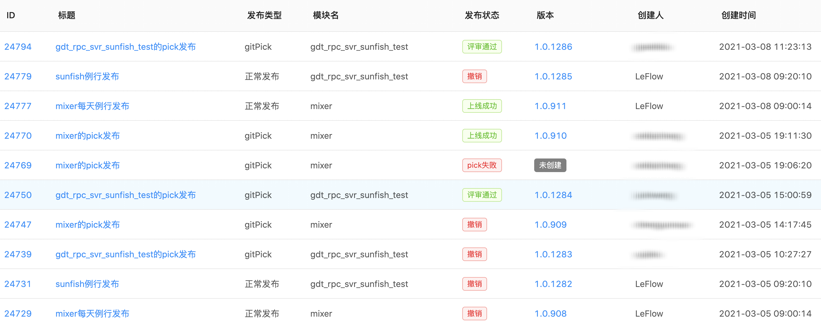

支持以手动和自动两种模式拉起发布评审,评审确认后,可以自动部署到发布系统中。目前后台需求频繁的几个关键模块,比如 mixer(业务逻辑总管服务)、sunfish(广告检索系统)做到了每天一发,投放端有些模块甚至做到了按需发布。
效率优化
只有质量,没有效率显然也不行。我们在效率方面也做了大量的工作。
开发效率
开发环境升级
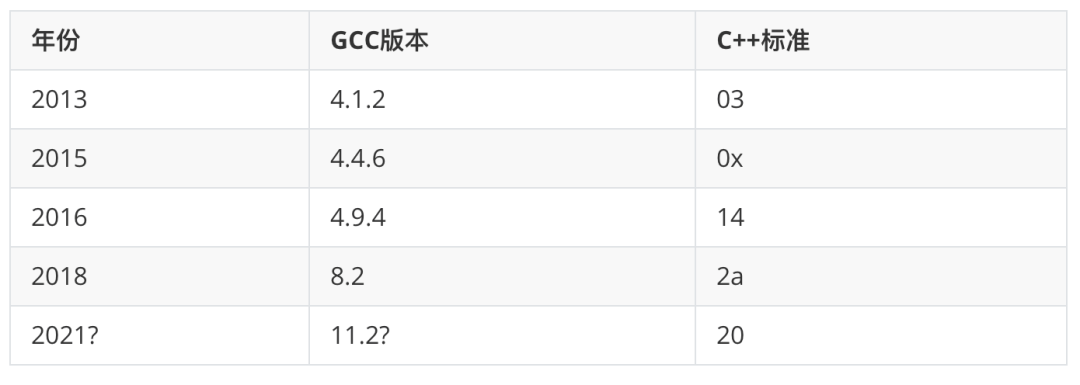
我们会不定期地跟踪开发工具升级,确保代码库能用编译器构建。比如 C++编译器:
基础库
为何大家都觉得 Python 效率高?因为他有大量方便易用的基础库。广告系统大量使用 C++和 Java 代码,Java 有庞大的 maven 仓库,但是 C++就惨了点,因此我们开发了一系列的基础库(包含字符串处理,加密解密,压缩编码,网络库,HTTP 库等等),帮助业务开发尽量能用更少的代码开发业务逻辑。
第三方库
代码库中充斥着大量不同版本的第三方库是代码管理混乱的重要特点,我们不允许这种事情发生,制定了第三方库管理规范,严格把控第三方库的使用、升级、旧版清理。
开发框架
我们开发了基于现代 C++风格的低延迟高性能服务框架——Flare,简化了业务代码开发的难度,保证了质量。
代码清理
要保证代码库的健康,就需要经常检查代码库中的问题。废弃的代码要清理,break 的构建要修复,编译器升级可能要改代码,工程效能团队要有权力、有自信、有勇气改动业务的代码。
构建效率
Blade 优化
Blade 构建系统是我主导开发的(也是主力开发者之一),2013 年广告系统开始使用 Blade,而微信用的是很早就 fork 出去后自己做了大量修改过的 Blade 系统。
2017 年,由于构建速度的问题,微信选择了改用 Bazel,花了 2 年多时间才完成。
我们则选择了优化了 Blade 构建系统(原因之一是那时候的 Bazel 还很不成熟,其次是确实没有动力和人力去改已经存在的几千个 BUILD 文件),包括用 Chrome 和 Android 的构建后端 ninja 替换了原来的 scons 后端,大幅度优化了构建代码生成等等多种手段,让整个代码库全量构建的启动时间从几分钟缩短到二十秒。根据 luobogao 在 Yadcc 上的测试,Bazel 在数百个进程并发构建下的调度和 CPU 占用表现都不如 ninja。
Yadcc 分布式编译器
当代码库规模很大时,又基本是全源代码编译,一个底层的被依赖库的变动(比如基础库和基础的 pb 文件)就会引发大量的编译。因此我们在调查了一些业界的解决方案,包括开源项目后,开发了 Yadcc 分布式编译器。
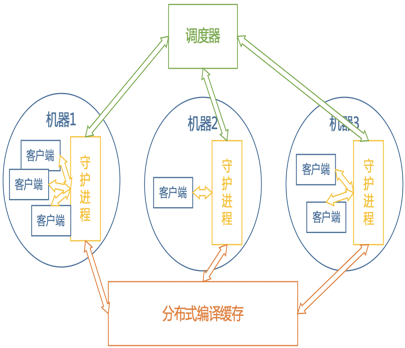
最大的特点是除了我们自己的机器资源外,我们还可以把使用者的计算资源也纳入到集群中,因此用户越多反而越快。目前集群已经有 2000 多核,再加上高命中率的缓存,能够轻松支持 CI 和本地开发环境中大量单个构建批次上并发任务高达 500 多的任务的并发构建。目前只支持 C++,但是我们正在开发对 Java 和 scala 的支持。
代码评审效率
如果代码评审不够效率,那么开发人员的工作时间就就白白损失在等待上。
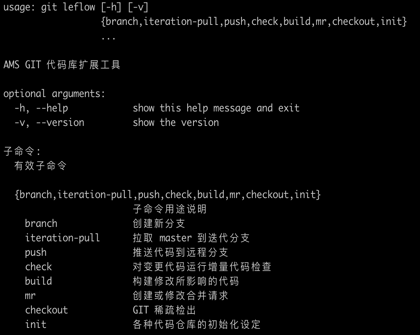
为了提高代码评审的效率,我们开发了 Legit Git 增强工具,具备以下功能:
• 分支管理,包括命名规范和过期清理 • 自动代码检查 • 增强代码评审 • 自动合并通过的 MR • 自动催办待评审变更
legit 已加入《代码工具平台》Oteam。
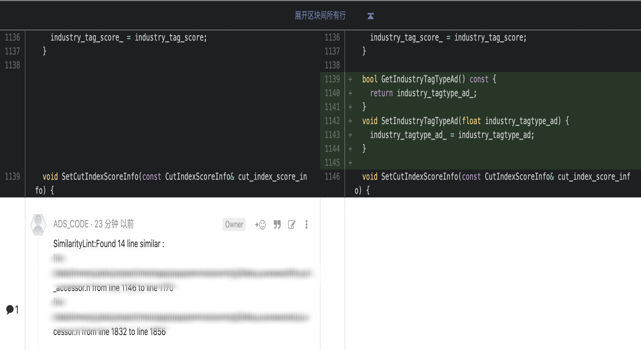
Legit 内置 14 种代码检查工具,包括公司代码规范尚未覆盖的 scala,bash,markdown 等,其中 protobuf,bash 以及 cpplint 的增强版是我自己写的。每个历史悠久的仓库都免不了有不少技术债务,我们采用了主要检查增量代码的策略。对于可能比较难以解决的问题,允许继续 Push,展示在工蜂页面上,供人工审查和讨论。
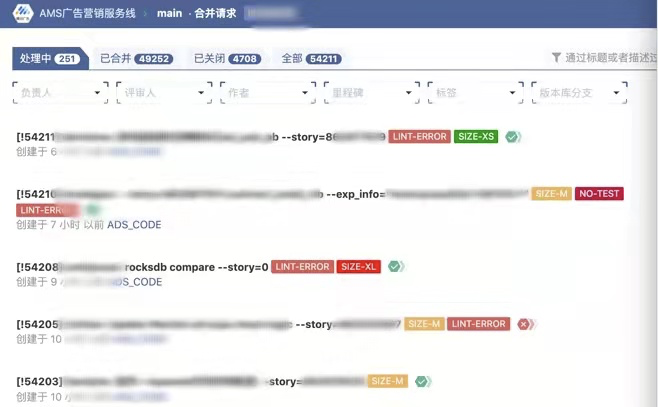
Legit 创建出来的 MR 会有整齐划一的标题以及漂亮的标签,以方便评审人员。比如我们给 MR 的变更规模设置了 XS-XL 的标签,就能方便利用碎片时间快速评审一些小的变更。而把大块时间留给较大的变更。而 LINT-ERROR 标签提醒评审人员注意确认 MR 中的代码检查问题。
我们强烈不鼓励大规模的单次变更,不但入职培训会讲,而且大的变更会自动引发评审委员会的评审,没有合理的理由会被驳回,所以现在也来越少了。
数据收集,度量与推动
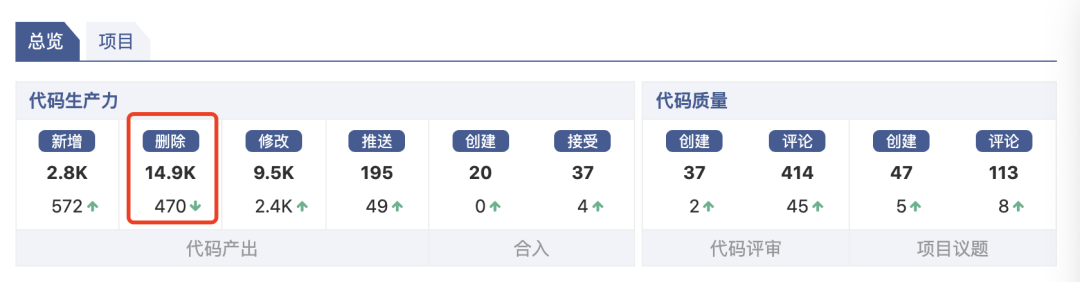
我们在整个流程的收集了大量数据,然后有专业而负责的 QA 团队输出各种报表,和各个业务研发团队对齐目标,推动其改进。比如上面的 UT 覆盖率只是其中一种。不过度量这部分目前做的确实还不好,有待加强。不过要强调的是,数据采集出来,主要用作对研发流程效率提升的分析工作,一定要谨慎考虑是否能纳入度量体系,以免起到负面引导作用。
未来的挑战
废弃代码与废弃模块
在多仓库模式下,废弃代码会自然淘汰。但是在单一代码仓库下却不会,需要结合变更历史和发布系统来识别定位废弃模块。
依赖债务清理
不必要的依赖,会造成构建速度变慢,不必要的构建和测试增多。需要通过构建系统结合源码分析技术来识别并清理。这对 C++相当的困难。
代码库存储空间问题
由于 git 的天性,需要开发者本地保存整个代码库的 clone,即使有稀疏检出,检出深度控制等,效果也不明显。如果代码仓库继续变大,可能就需要引入虚拟文件系统,虚拟大仓库等做法。有些公司比如 twitter 采用了截断历史的做法。
总结
我们学习业界先进实践经验,结合自身特点,在广告系统的范围内实现了单一代码库主干开发,城际快线的发布模式,在研发效能上达到了比较先进的程度。这离不开团队小伙伴的努力和业务团队的配合,但是由于人力/经验等的限制,和业界做的最好的公司比,我们依然有很多需要提高的地方,在整个公司范围内统一这种模式,目前看更是遥不可及。但是对于有较强技术把控能力的团队,建议尝试这种模式。