闲鱼社区如何快准稳的完成无缝数据迁移
背景
在内容社区中,内容标签用来辅助说明内容,内容标签对内容分发和理解具有重要作用,能够帮助内容社区将对的内容分发到对的人。目前闲鱼会玩社区的标签分为分类和属性标签两种,两种标签的用法不同,但是目前二者都是存在于同一个标签系统中,这样会出现打错标和属性与分类无法独立扩展的问题。为了解决以上问题,现在要将原标签系统拆分为分类系统和属性系统。整个过程,不仅需要迁移底层数据,还需要将属性服务从原标签系统迁移到新属性系统。

现状
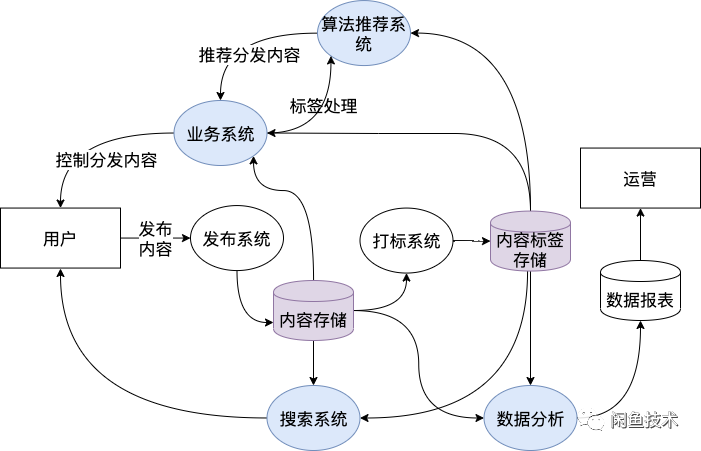
如下图所示,闲鱼会玩社区对属性标签依赖非常之多,除了自身的业务系统之外,还有图中标蓝的算法、搜索、数据等也会依赖。迁移过程中需要保证这些上层依赖不受影响。另外,业务方希望能够尽早启用属性系统,尽快提高打标效率。总结起来,迁移过程中面临了如下的挑战。
- 快,短时间内迁移完成,尽早使用新属性系统
- 稳,依赖众多,在迁移时需要保证属性服务可用,不影响上层业务,用户无感知
- 准,迁移最最最基本的要求就是要保证数据正确
迁移方案
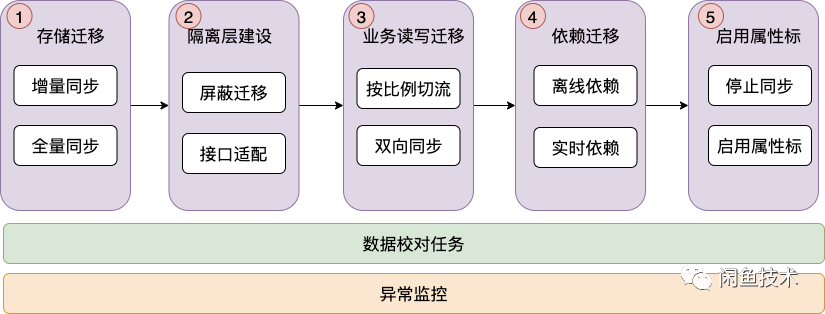
我们按照影响面从小到大的顺序,制定了1.底层存储同步、2.建设隔离层、3.业务读写迁移、4.依赖迁移、5.启用新属性系统共五步。其中依赖是指搜索、算法和数据,这些依赖影响面较广,迁移需要更加慎重,需要有己方业务迁移正确这个前提作为保证。因此依赖迁移需要单独列为一部分,且放在己方业务迁移完成后进行。迁移中的每一步迁移需要保证上一步正确,且出现问题,每一步都可以回滚回上一个正确状态。为了保证数据的一致性,我们全程都有数据校对服务。
迁移过程
存储迁移
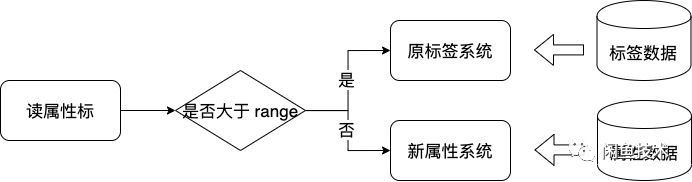
整个迁移过程,我们首先先从底层存储开始同步,为了保证原标签系统和属性系统中的属性标签相同。实现这个目标需要从两方面做起,一方面是全量同步,就是将全部数据同步一遍。一方面是实时增量同步,一旦有新的属性标签被写入原标签系统中,那么属性系统中也要同步一份。这个套路比较固定。下面是我们全量同步的数据处理过程。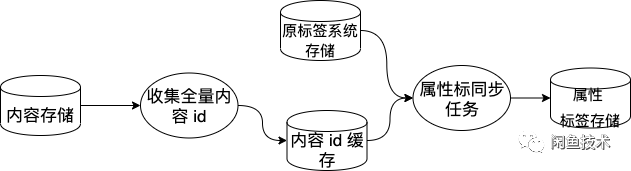
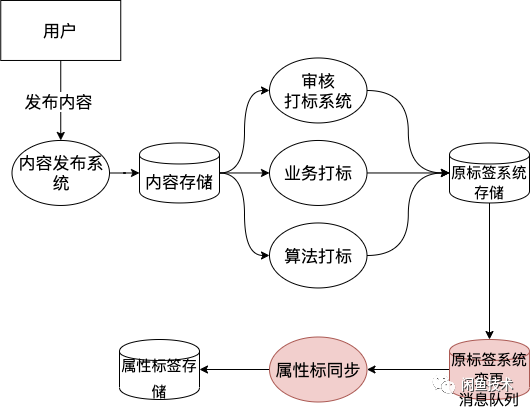
讲完了全量同步,下面讲一下实时增量拆分的过程,数据流过程如下图所示。即一旦触发了原标签系统变更,会实时将属性标的变化同步到属性系统。
隔离层建设
屏蔽迁移细节
做了存储迁移,那么现在属性系统和原标签系统中的属性标相同了,下面可以做业务读迁移了。业务迁移,这是迁移过程中工作量最大最复杂的地方,需要梳理清楚依赖很多。经过梳理发现,多个应用多个业务场景都在使用原标签系统。假如逐个迁移改造,一方面重复性工作比较多,需要重复验证的功能点多,另一方面,迁移细节无法统一管理,一旦有问题,需要逐个应用修改。所以在做业务迁移之前,我们做了一件事情,就是将散落在多个应用的读写原标签系统的操作都收归到了一个 jar 包中,然后在该 jar 中统一控制读写切换。jar 包相当于一个隔离层,隔离了上层业务和属性标签的存储逻辑。这样上层业务系统不必关心属性标是从原标签系统读取的抑或是从属性系统中读取的,只管从隔离层提供的方法中读取即可。有了隔离层统一管理,可以同时统一迁移,减少不必要的重复工作。具体的变化从 a 图变换到 b 图。
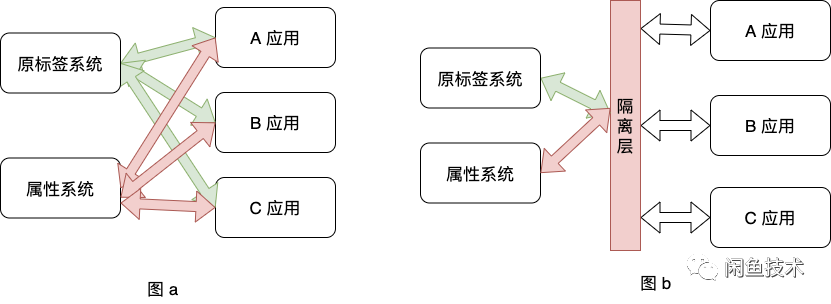
接口适配
由于分类系统和属性系统两种标签的业务语义和功能不同,内容中台对这两个系统的领域建模也不同,对应的数据服务接口能力也不同,为了让上层业务对此无感知,我们保持原服务接口不变,在隔离层做了对于分类系统和属性系统两个系统的适配。
业务读写迁移
读迁移
前置工作做完之后,我们开始具体的读迁移。读迁移是最好做的,可以先按照比例切流,逐步放量从属性系统中读取属性标,一旦发现有问题,那么直接将流量切回读原标签系统 ,没有问题,就直至全量。
写迁移
写迁移是很难一刀切的,一方面,即使是经过了梳理,还是可能会有遗漏的地方。另一方面,还有部分依赖方的写入(比如内容中台的标签写入)不在我们这边,暂时无法迁移。假如己方业务的写迁移了,那么己方业务只会写到属性系统 ,而没迁移的依赖方只会写到原标签系统。这会造成原标签系统和属性系统的属性标数据不一致。这导致两方面的问题,一方面,影响依赖方读,依赖方读的还是原标签系统,读取不到属性系统上的属性标。另一方面,两方不一致的话,如果属性系统出现问题,那么写无法即时回滚到原标签系统。
因此在迁移过程中,还需要保证原标签系统和属性系统上的属性标时刻是相同的,在存储拆分中,已经有了 原标签系统-> 属性系统的同步链路,现在还需要将只写入属性系统的属性标同步回原标签系统。
那么现在有 原标签系统->属性系统 和 属性系统 -> 原标签系统 两条同步链路。如果不做任何控制的话,明显会出现同步死循环原标签系统->属性系统->原标签系统。解决这种双向同步死循环的一般办法是加标志,用标志标识这次数据变更是源自哪一方,当发现自己的更新消息回流到了自己这里,那么就不再更新,这样就切断了更新的死循环。

依赖方迁移
当己方业务能够保证无误的时候,那么可以做依赖迁移了。依赖方一般为算法、搜索和数据等。链路分为实时链路和离线链路。对于实时链路,这部分工作因为有了前面的业务读迁移,可以复用;对于离线链路,提供好离线数据表给到相关依赖方,让他们按时迁移完成即可。
启用新属性系统
依赖方也迁移完成后,经过一段时间的观察,没有问题,便可以使用新的属性标签系统来打标了。启用新系统打标的之后,便不再需要 原标签系统->属性系统 的同步链路了,可以停止。后续再观察一段时间后,确认使用属性系统无问题后,便不再有将读写切回原标签系统的必要了,可以再切断 属性系统 -> 原标签系统 的同步链路,至此迁移完成。
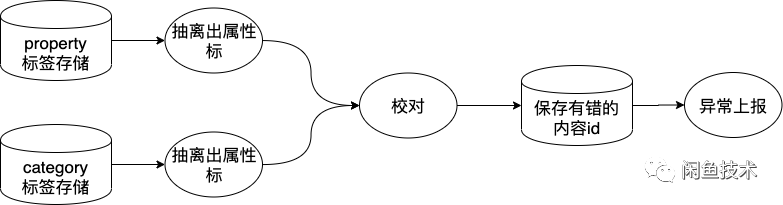
数据校对任务
在整个同步过程中,还要有对账任务来实时查看同步的数据是否正确。如果发现数据不正确,要及时找到原因,修正,然后做好数据矫正。
总结与思考
本次迁移排除依赖方迁移所用时间外,共计两周。
- 迁移过程中属性服务正常。零客诉舆情。
- 迁移后,数据零差异。
最后捋一下本次迁移中的经验点
- 迁移过程中,如果服务依赖众多,可以用隔离层来隔离依赖对迁移的感知。
- 双写,过程中避免出现同步死循环,可以通过给更新消息加标志避免。