深入浅出 | 谈谈MNN GPU性能优化策略
MNN(Mobile Neural Network)是一个高性能、通用的深度学习框架,支持在移动端、PC端、服务端、嵌入式等各种设备上高效运行。MNN利用设备的GPU能力,全面充分“榨干”设备的GPU资源,来进行深度学习的高性能部署与训练。
概述
MNN自开源以来,一直以高性能、通用性、易用性等特性闻名于业界。近一年来,MNN GPU再发力,OpenCL后端针对移动端(Adreno/Mali GPU)、PC端性能总体提升超过100%,部分机型性能翻几番。请看下图:
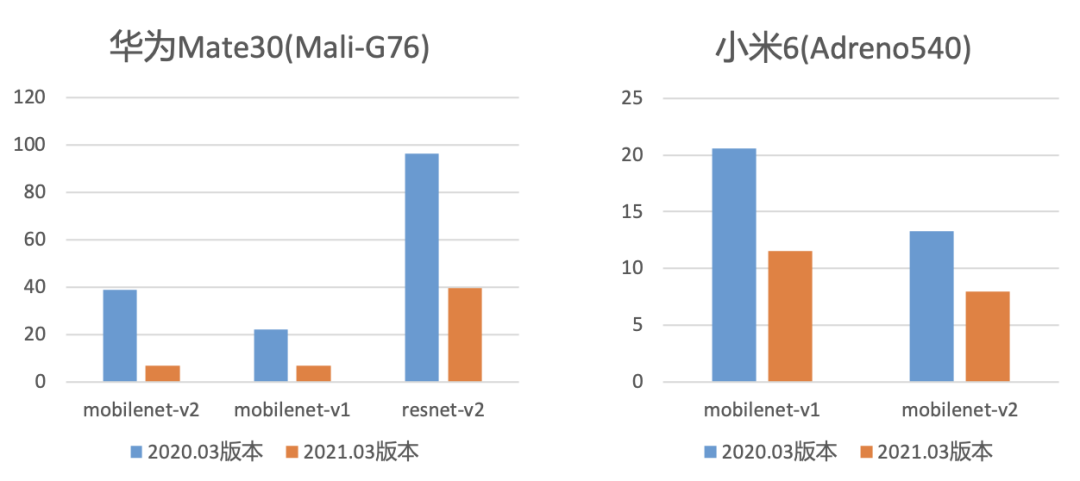
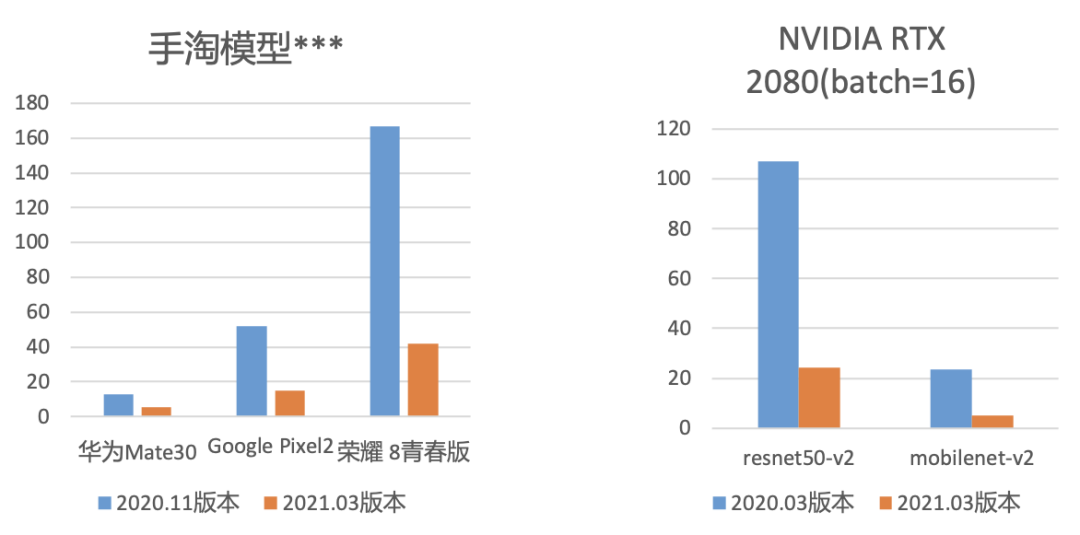
移动端GPU受限于芯片面积、能耗以及成本等因素,通常需要在IO带宽和运算资源上严格受控压缩。GPU硬件多样性、OpenCL本身支持力度取决于设备生产商,这导致了不同设备GPU软硬件层面的差异化。那么,如何在有限且碎片化的资源下充分发挥出硬件的性能优势,加快深度学习模型推理速度,给MNN GPU平台通用性与高性能兼备的定位带来很高的挑战。 是什么优化手段能在高端手机、低端千元机、服务端显卡上,模型推理都能加速如此之多呢?MNN OpenCL在最近一年内做了什么优化呢?且看下文~
内存访问效率角度
▐ 内存对象多元化调优
OpenCL提供两种内存对象接口,Buffer-object和Image-object。有的GPU厂商对Image-object具有更快速的访问和支持,高通Adreno GPU用户手册明确建议使用Image-object进行存储更有利于访问效率;但是ARM Mali GPU系列众多,有不少机型对Image-object内存支持没有那么好,适合更通用的Buffer-object。面对不同GPU内存存储格式引起的不同访问效率,MNN支持多元的内存存储格式,以应对差异化的GPU型号。
下表为OpenCL Imgae-object与Buffer-object的区别对比。

高通平台明确给出下图数据流路结构图,当使用Image-object存储时,在进去读数据时候可以使用Texture处理器和L1 cache进行快速读取。如果使用Buffer-object的话将无法使用该硬件缓存优势。所以对于高通骁龙系列手机,使用其GPU资源,选择OpenCL Image-object性能更优。
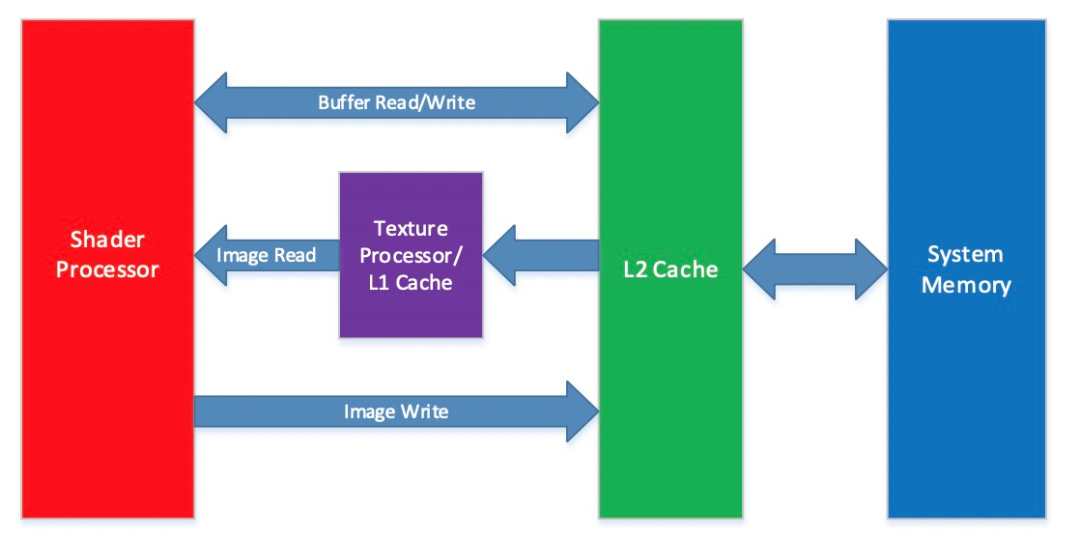
Buffer-object也有其使用范围和优势。首先,Image-object的2D/3D内存每个维度申请尺寸是有上限的(不同硬件不同),当要申请的内存某个维度的尺寸超过硬件支持的上限时,Image-object内存会申请失败,这个时候只能使用Buffer-object。其次,Buffer-object内存排布是线性的,排布紧密,cache miss较友好,Image-object如果第一维度尺寸太小容易造成很严重的cache miss。ARM Mali GPU并没有很友好的Texture处理器和L1 Cache(官方未提及),官方开源项目采用Buffer-object存储模式,可见目前Buffer-object对ARM Mali GPU更有优势。 MNN OpenCL2020年之前已经支持Image-object,今年新增了对Buffer-object内存对象格式的支持,针对不同硬件平台和算法模型,MNN OpenCL目前框架内支持根据实验经验化,在ARM-Mali GPU上采用Buffer内存,其他GPU型号采用Image内存。目前这个策略只是比较粗糙的经验化手段。为了精确的内存选择,用户可以通过提前试跑两种内存设置,来得到两种内存模式推理性能的更优者,在实际推理过程中设置此内存模式即可。
▐ 内存对齐优化
下图是CPU和GPU拥有的硬件资源(运算单元ALU/控制单元/缓存等)的示意图。
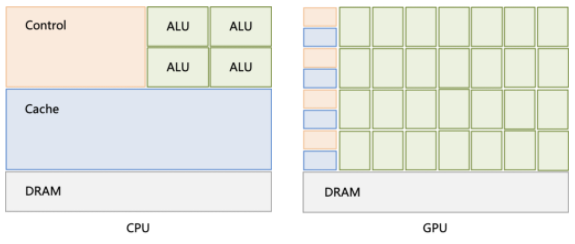
CPU配置强大的控制单元和缓存机制,具有厉害的分支预测能力,擅长处理复杂逻辑。GPU硬件资源大量运算单元,控制单元和缓存相对来说较薄弱,使得分支预测能力较弱,所以在编程过程中需要尽量避免逻辑分支。 通常某个维度的并行量不会太大,在MNN OpenCL实现中,宽方向最高并行量是4,在申请内存时可以将该维度4对齐向上取整,这样可以避免在读取数据时为了防止读越界而带来的边界判断需求,从而减少GPU kernel内部分支。同时在遇到部分实在无法避免的分支判断时,尽可能选择三目运算符替代if分支。
▐ local memory并行归约优化
归约是一种并行算法,对于传入进来N个输入,通过二元操作,得到一个输出值。典型的就是求最值、取平均值、求和等操作。以取最大值为例,传统的串行算法,实现简单,需要N次迭代运算操作。通常如下:-
float maxValue = -MAXFLOAT;
for (int i = 0; i < N; i++) {
maxValue = max(maxValue, array[i]);
}下图二分法并行归约算法示意图,每个步骤可以并行去求最大值,在opencl实现中,将放在同一个工作组的线程采用局部内存(local memory)进行存储,因为同一工作组中的线程访问共享数据时,local memory由于其得天独厚的物理设计,效率远高于global memory。二分归约只需要logN次迭代操作。相较于传统串行方法时间复杂度有降维优势。对于归约数目N较时,该方法性能提升明显;但是N较少时使用串行方法即可,因为线程间barrier开销会明显盖过local memory和操作次数带来的优势。
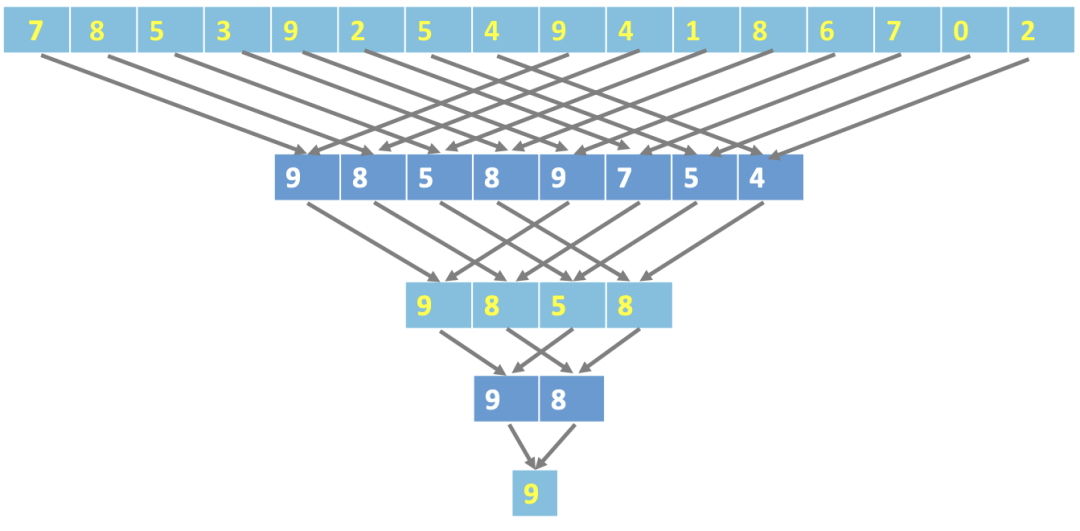
如下是opencl归约算法kernel代码示例:
const int idx = get_local_id(0);
FLOAT local sum[256];
sum[idx] = -MAXFLOAT;
const int reduce_num = get_local_size(0);//获取工作组中的线程数量
for (int h = idx; h < total_num; h+=reduce_num) {//将多个工作组的值映射到当前工作组
FLOAT in = read_input_data(input);
sum[idx] = max(sum[idx], in);
}
barrier(CLK_LOCAL_MEM_FENCE);
for(int i = reduce_num/2; i > 0; i /= 2){//对当前工作组进行二分归约运算
if (idx < i)
sum[idx] = max(sum[idx], sum[idx + i]);
barrier(CLK_LOCAL_MEM_FENCE);
}
if (idx == 0) {
write_output_data(output, sum[0]);//将sum[0]的值写入输出地址处
}GPU计算分块角度
▐ 工作组大小选择
下图示意的是一个GPU任务分块执行示意图。左侧NDRange size表示的是任务拥有的总子任务(子线程)数量。子线程会被组织成一系列work-group分块线程,每个work-group分块会被分配到一个SP上面执行。这个执行过程是GPU SIMT架构的必然映射。
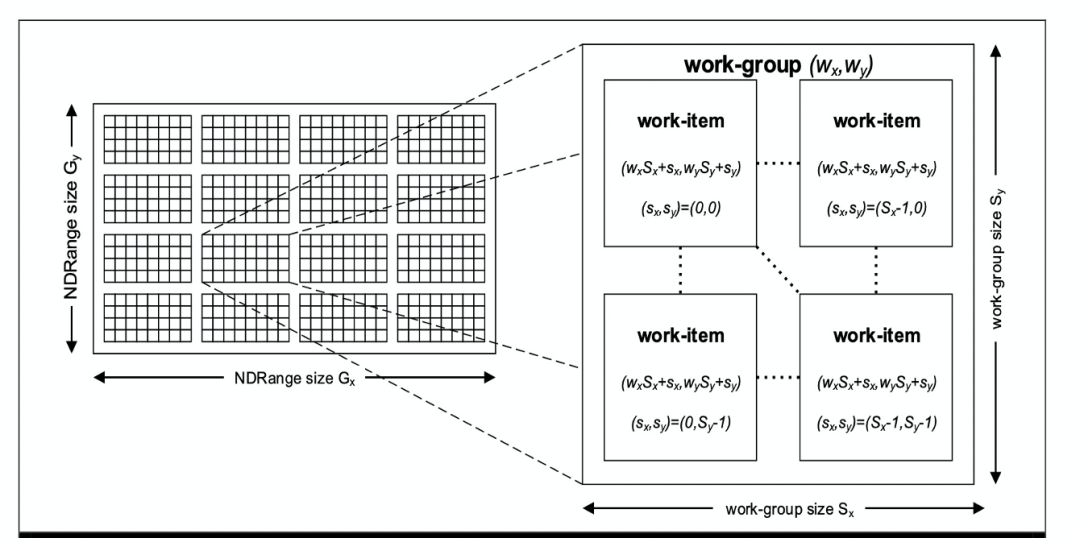
work-group大小的划分会影响到整个GPU硬件资源的利用情况。针对一个特定的任务,最合适的work-group大小受单个线程需要完成的任务量、机型GPU硬件资源的强弱以及总线程数目等很多综合因素影响,选择不合适的work-group会对计算效率性产生不好的影响。
OpenCL框架允许编程者不去设定这个尺寸大小,会根据情况自行调度决定。但这往往不能带来较好的性能效果。通常较合适的work-group size是NDRange size的因子或者是2的幂次方,这种极简的设置往往可以带来“还不错”的性能。为了极佳的性能,MNN在预推理阶段会选取多组work-group分块大小进行Auto-Tuning试跑,选出性能最佳的work-group size,以此配置在实际推理中应用。
▐ 数据分块复用方案
对于CNN网络中常见的二维卷积运算,实际上是三维张量到三维张量的映射操作。拿kernel为3x3,stride为1x1,pad为1x1,dilate为1x1的卷积运算(暂不考虑偏置的情况)举例,对于
输入维度是Cin*H*W
权重维度是Cout*Cin*Kh*Kw,(3x3卷积核,Kw=Kh=3)
输出维度则是Cout*H*W
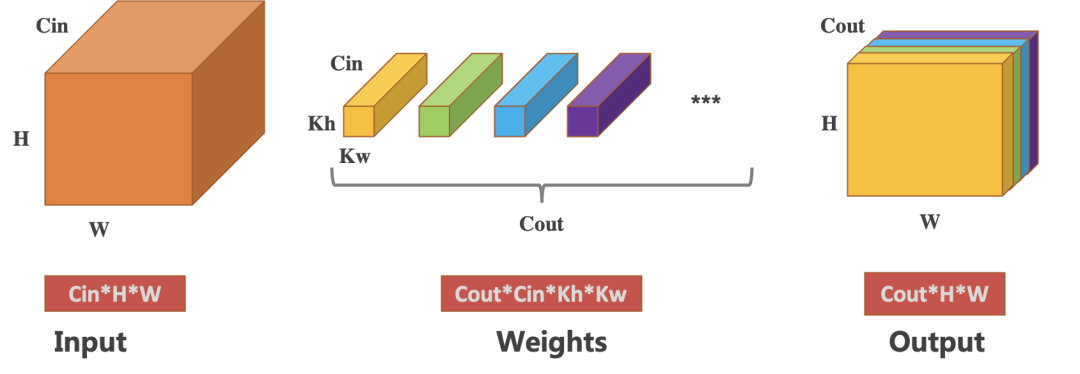
下表给出了,单个线程不同粒度计算量对应的总的计算复杂度和内存访问量大小。可以看出总的计算复杂度都是恒定的,但是随着单个线程计算量的则增加,数据可复用力度越高,总的内存访问量将会越少。拿单个像素输出粒度为基准,单个线程输出连续4个通道和连续4个宽方向的16个像素时,内存访问量将减少75%。

增大数据分块可以在计算复杂度不变的前提下,有效的降低数据内存访问次数,对于提升性能有很重要的作用。但是,随着单个线程GPU kernel计算量越大,需要使用的寄存器资源越多,全局工作项数目也将对应减少。单个线程计算量过大时必然会导致寄存器等资源不够用,也可能导致全局工作项数目过小起不到较佳的GPU任务发射并行度。
最适宜的数据分块量,会随着总线程数量/硬件平台寄存器/硬件ALU数目/IO带宽等资源以及单个线程的计算量大小的不同,也会有较大的差别。譬如,当总线程数目较少时,此时为了足够的并发量,数据分块大小需要相对应尽可能减小;当总线程数/寄存器资源足够的时候,可以考虑加大数据分块大小,来增大数据复用的优势。
当前MNN OpenCL针对核心算子支持多种数据复用分块量,支持在预推理阶段提前Auto-Tuning试跑找到最适宜当前设备/计算规模的数据分块量,以获得最佳的优化性能。
异构调度角度
异构系统的调度,相比于同构系统调度会复杂一些,因为会涉及到主机端与设备端交互部分。下图是一个典型的OpenCL异构系统调度图。主要包含了三个部分。其一:主机CPU端,负责整个异构系统的主控调度,包括资源的申请调配、任务的发射等;其二:各种异构设备端(比如GPU/DSP/FPGA等),是异构系统的核心处理器;其三:OpenCL kernel代码,负责对异构处理器进行操纵。
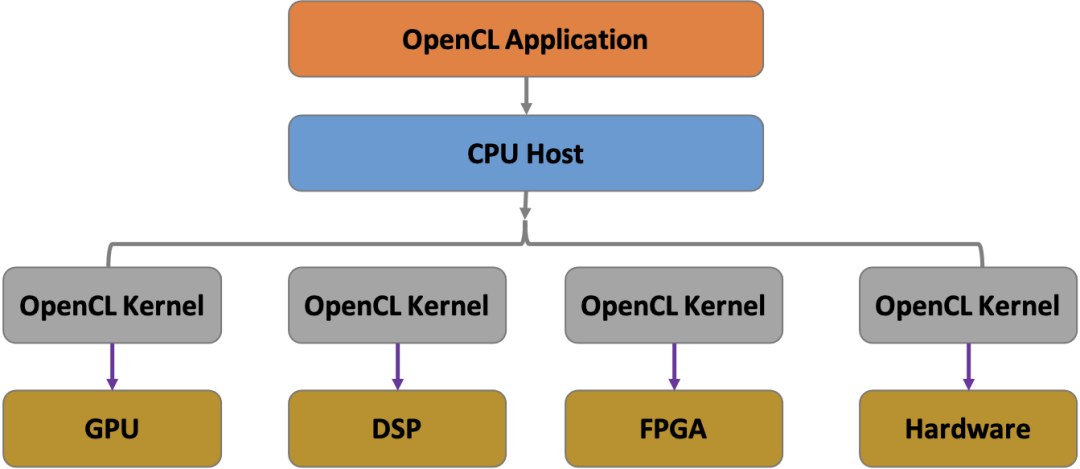
OpenCL kernel从CPU提交到任务队列后会经历
Queued/Submitted/Ready/Running等整个执行状态。和CPU算子执行存在明显的差别,GPU算子执行需要统一入队,然后GPU会对同一个任务队列上的任务进行队列式排队。对于某个算子从入队等待到真正执行是有延迟的。具体延迟情况依赖厂商平台调度。
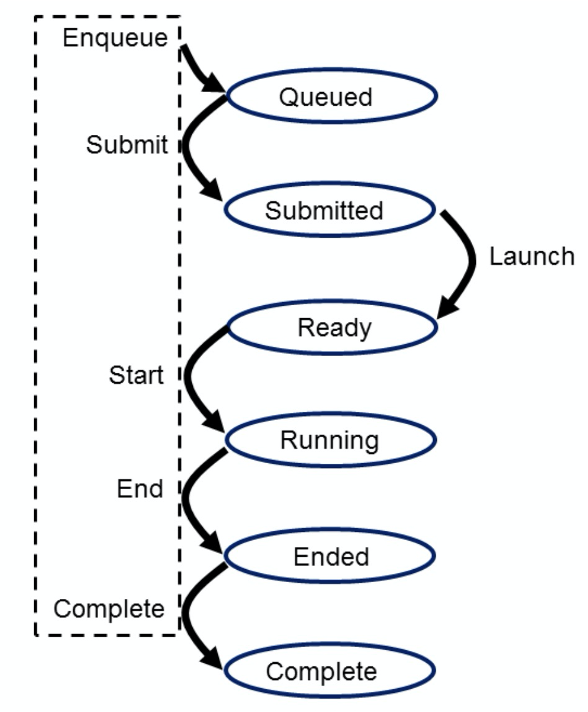
从Queued到Submitted状态之间的软件开销/CPU cache开销,调度好的系统能尽量最优化处理调度。但是,由于不同机型,对OpenCL的任务调度不尽如人意,往往这段时延较大。OpenCL提供flush接口,可以在一定kernel量的时候手动加速提交任务,在调度上加入人为的动态队列刷新机制。
在华为系列手机(Mali GPU),需要在kernel累计量较少的时候就需要人为加入刷新机制,整体性能提升可观,对人为刷新机制依赖比较严重。高通系列手机,在kernel累计量较多的时候加入刷新机制即可,不依赖人为刷新机制,整体系统调度情况较好。MNN根据实验经验公式,针对不同机型调优出动态的命令队列刷新机制。
预推理Auto-tuning调优
GPU种类众多,不同厂家设计差异大,相同厂家GPU设计更新变迁复杂。这一系列导致的GPU碎片化,使得不同机型最优的算子实现都不一样。很可能会出现某些机型算子实现了最优化,其他部分机型上出现负优化的情况。这给MNN GPU平台通用且高性能兼备的定位带来很大的挑战。要想使得全机型、多模型性能都能达到很优,Auto-tuning试跑是一个很有效的方式。
但是,Auto-tuning必然会增加不少额外的试跑耗时。MNN之前已经支持了“预推理”机制,核心目的是:在真正推理之前,将推理过程中需要的内存/任务准备与分发等提前推理出来,从而优化降低实际推理过程中的耗时。功能主要包括:
- 进行内存管理:申请每个算子的输入输出Tensor内存与运算时所需的缓存。
- 任务准备与分发:对CPU来说,可以在这个环节生成Lambda函数。对GPU来说,可以制作相关算子的命令缓冲(Command Buffer),填充参数等等。
MNN的OpenCL后端扩充新增“预推理”的功能——任务Auto-tuning试跑,找出最优的计算配置方案。增加此功能主要基于以下考虑:
- 每个模型的算子固定,每次推理只是算子的输入数据不同,计算方式和计算量完全一致。最优的实现方式一致,可以在“预推理”阶段提前Auto-tuning出每个算子的最优配置。
- “预推理”机制可以有效降低推理阶段的耗时。
MNN OpenCL增加此“预推理”功能后,在推理阶段,可以直接使用“预推理”出的Auto-tuning计算配置,获得优化的性能。目前支持了工作组大小选择和数据分块复用两种优化策略的Auto-tuning试跑,具体内容在GPU分块角度优化模块里已经阐述过。
GPU业务落地设计与建议
▐ 用户可配置的Gpu-Mode
上述通过经验实验方法与Auto-Tuning试跑的方式来提升推理速度。由于经验实验公式不可能覆盖所有情况,支持增加接口给用户自行选择。目前GPU内存对象选择提供开放选项给用户自行配置。Auto-Tuning试跑会增加“预推理”的耗时,MNN OpenCL提供不同的Auto-tuning力度选项可供用户选择。用户可选取性能满足要求的前提下尽可能缩减Auto-tuning的力度。
MNN OpenCL提供用户可自行配置的MNNGpuMode,具体选项如下图所示。
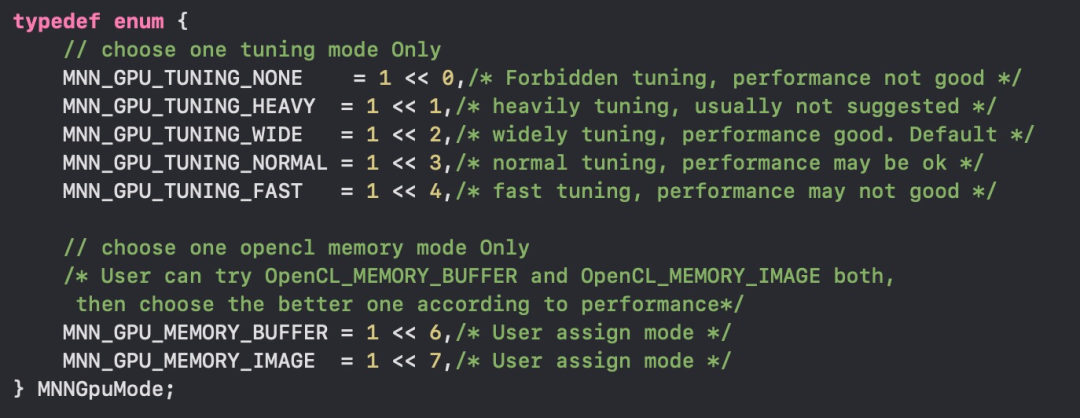
指定需要使用的Tuning-mode和Gpu-Memory类型,在代码中设置config的mode设置即可。代码示例如下:
MNN::ScheduleConfig config;
config.mode = MNN_GPU_TUNING_NORMAL | MNN_GPU_MEMORY_IMAGE;通常如果介意“预推理”耗时较长可以选取较低level的Tuning-mode(下面也会介绍Cache机制解决初始化耗时长的问题)。Gpu-Memory用户可以Buffer模式和Image模式都自行设置一次,选择推理速度较优的模式,当然如果不设置的话框架会根据机型进行自动选择(不可能保证所有情况下都最优)。
▐ MNN Cache技术设计
由于OpenCL kernel需要根据不同机型在线编译源码program,以及加入精细化调优Auto-tuning试跑机制后,获得极佳性能的同时会带来启动时间较慢的代价。很多情况下,用户对于初始化时间不太能接受,导致很多业务难以真正落地。
为了优化GPU初始化时间,MNN将当前机型编译好的program转成二进制、Auto-tuning出的最佳配置进行记录,并存储成Cache文件。之后初始化的时候加载Cache文件读取二进制版program(无需编译源码)和tune好的配置信息(无需再次Auto-tuning),从而大大提高初始化速度。
如果应用仅限某种或某几种特定机型,可以事先生成好该机型的cache文件。这样实际启动的时候就可以直接加载cache文件,享受快速的启动速度。如果应用机型太多,不能接受每种机型都事先提前生成好Cache文件,可以考虑在调度上可以事先提前初始化,在跑其他应用的时候就提前初始化生成Cache文件,在调度上“隐藏”掉生成Cache的时间。
MNN Cache使用上极其方便简洁,用户只需要调用一行代码,接口如下:
setCacheFile(const std::string& fileName, size_t keySize = 128)//keySize: 使用模型Buffer的前 keySize 个 byte 作为校验
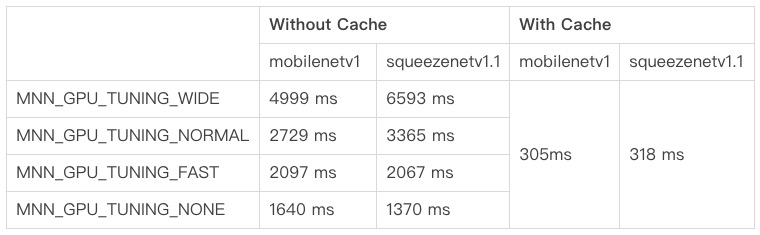
下表给出小米6(Adreno-540 GPU)设备上,在使用Cache前后不同tuning-mode时OpenCL总初始化耗时。可以看到使用Cache能极大优化启动速度,助力业务落地。
▐ 用户透明的性能分析
用户在设计了一个模型后,使用MNN benchmark工具测试GPU性能,当遇到不太符合预期的性能时,这个时候用户就像是用了个盲盒似的,无从分析,无从下手。在此需求下,MNN GPU提供了性能热点分析工具,帮助用户定位性能热点。
性能热点分析对于提升总体推理性能的重要性,就好比生病了去医院需要抽血分析各项指标报告一样,只有知道各处的指标详情才好对症下药。MNN GPU提供统计OpenCL kernel耗时方法,使用opencl event进行GPU端计时统计,可以精确地进行单个kernel耗时分析,准确性能明显高于CPU端计时器。
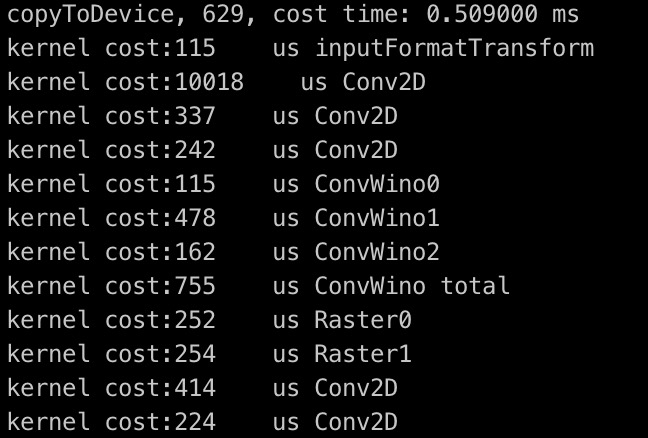
MNN OpenCL用户可以在编译库的时候打开MNN_OPENCL_PROFILE宏,运行程序可以看到每个部分的耗时,去进行性能热点定位分析。下图给出的是部分算子耗时图,可以看到各个算子的耗时情况,可以看出第一个Conv2D算子耗时是绝对的热点。用户可以为了提升性能,对这个卷积算子考虑采用减小通道数或者使用多个小卷积核代替一个大卷积核方式。提供这样的Profile功能,对模型设计带来更多指导性灵感和参考,提供了结合框架去设计模型的可能性。
▐ 适合GPU加速模型设计建议
经常会有用户反馈,为什么使用GPU加速反而性能不如运行CPU上呢?通常在用户潜意识里,GPU总比CPU快。其实这是个误解。GPU的硬件结构设计特性,决定了GPU对具有大量可并行的运算才更有优势。对于运算量过小或者并行度较低的模型,通常GPU上运行效率不如CPU。
对于CPU耗时本身较少的小模型(如几个ms),不建议使用GPU加速。因为GPU运行启动调度本身需要一定耗时,其次CPU/GPU数据拷贝耗时,加之不符合GPU适合大量运算的特性。因此,模型太小选择CPU就好。在移动端和PC端,要用GPU加速,模型设计方面要尽可能设计一些并行量大的高速模型。具体给出以下几点建议:
- 卷积核不宜太大,常用的1x1和3x3较好。如果模型需要更大卷积核(如5x5)可以考虑使用5x1和1x5来代替,或者采用两个3x3卷积去替代5x5卷积。
- 通道数设计尽量保持4对齐
- 对于feature map和通道数都较大的卷积,可以考虑使用depthwise卷积。
- 加减乘除乘方这类binary/unary运算量较低的算子,可以有,但是不要过多。
- 尽量减少只改变形状没有计算量的算子,如squeeze、transpose、permute、reshape等。
- 尽量减少concat/slice这类纯访存类算子,无计算量。
- 尽量避免使用global pooling。
- 尽量减少使用除reduce轴之外的维度尺寸较大的reduction操作。
总之,适合GPU计算的模型,就是模型中的算子,尽可能多的满足具有大量可并行的特点;减少低计算量、高访存算子的使用,避免不好并行运算的算子。
▐ 参考文献
[1] https://en.wikipedia.org/wiki/OpenCL
[2] "Qualcomm Snapdragon Mobile Platform OpenCL General Programming and Optimization Guide"
[3] "The OpenCL Specification,Version: 1.2,Document Revision: 15"
[4] "ARM Mali GPU OpenCL,Version 3.3 Developer Guide"
[5] "Arm Mali GPU Datasheet 2020"
[6] "Building Heterogeneous Systems with PowerVROpenCL Programmer’s Reference"
[7] "颜深根等. "基于OpenCL 的归约算法优化." 软件学报 (2011)."
[8] https://www.cnblogs.com/xudong-bupt/p/3586518.html
[9] https://zhuanlan.zhihu.com/p/273657259
[10] https://developer.arm.com/solutions/graphics-and-gaming/developer-guides/advanced-guides/mali-gpu-best-practices
[11] https://zhuanlan.zhihu.com/p/107141045