高端的面试从来不会在HashMap的红黑树上纠缠太多
前言
在一场面试中最能打动面试官的其实是细节,候选人对细节的了解程度决定了留给面试官的印象到底是“基础扎实”还是“基础薄弱”,如果候选人能够举一反三主动阐述自己对一些技术细节的理解和总结,那无疑是面试过程中的一大亮点。HashMap是一个看着简单,但其实里面有很多技术细节的数据结构,在一场高端的面试中即使不问任何红黑树(Java 8中HashMap引入了红黑树来处理极端情况下的哈希碰撞)相关的问题,也会有很多的技术细节值得挖掘。
把书读薄
在Java 7中HashMap实现有1000多行,到了Java 8中增长为2000多行,虽然代码行数不多,但代码中有比较多的位运算,以及其他的一些细枝末节,导致这部分代码看起来很复杂,理解起来比较困难。但是如果我们跳出来看,HashMap这个数据结构是非常基础的,我们大脑中首先要有这样一幅图:
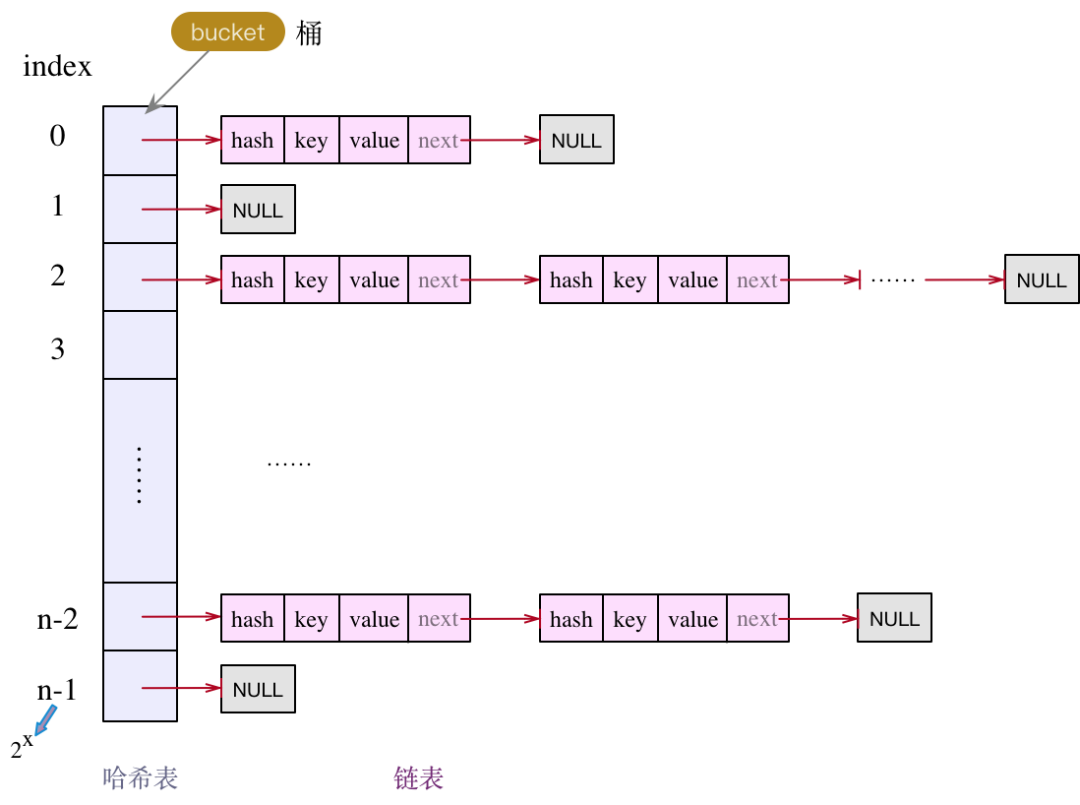
图片来源:https://www.cnblogs.com/tianzhihensu/p/11972780.html
这张图囊括了HashMap中最基础的几个点:
Java中HashMap的实现的基础数据结构是数组,每一对key->value的键值对组成Entity类以双向链表的形式存放到这个数组中- 元素在数组中的位置由
key.hashCode()的值决定,如果两个key的哈希值相等,即发生了哈希碰撞,则这两个key对应的Entity将以链表的形式存放在数组中 - 调用
HashMap.get()的时候会首先计算key的值,继而在数组中找到key对应的位置,然后遍历该位置上的链表找相应的值。
当然这张图中没有体现出来的有两点:
- 为了提升整个
HashMap的读取效率,当HashMap中存储的元素大小等于桶数组大小乘以负载因子的时候整个HashMap就要扩容,以减小哈希碰撞,具体细节我们在后文中讲代码会说到 - 在
Java 8中如果桶数组的同一个位置上的链表数量超过一个定值,则整个链表有一定概率会转为一棵红黑树。
整体来看,整个HashMap中最重要的点有四个:初始化,数据寻址-hash方法,数据存储-put方法,扩容-resize方法,只要理解了这四个点的原理和调用时机,也就理解了整个HashMap的设计。
把书读厚
在理解了HashMap的整体架构的基础上,我们可以试着回答一下下面的几个问题,如果对其中的某几个问题还有疑惑,那就说明我们还需要深入代码,把书读厚。
HashMap内部的bucket数组长度为什么一直都是2的整数次幂HashMap默认的bucket数组是多大HashMap什么时候开辟bucket数组占用内存HashMap何时扩容?- 桶中的元素链表何时转换为红黑树,什么时候转回链表,为什么要这么设计?
Java 8中为什么要引进红黑树,是为了解决什么场景的问题?HashMap如何处理key为null的键值对?
new HashMap()
在JDK 8中,在调用new HashMap()的时候并没有分配数组堆内存,只是做了一些参数校验,初始化了一些常量
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}tableSizeFor的作用是找到大于cap的最小的2的整数幂,我们假设n(注意是n,不是cap哈)对应的二进制为000001xxxxxx,其中x代表的二进制位是0是1我们不关心,
n |= n >>> 1;执行后n的值为:

n的二进制最高两位已经变成了1(1和0或1异或都是1),再接着执行第二行代码:

n的二进制最高四位已经变成了1,等到执行完代码n |= n >>> 16;之后,n的二进制最低位全都变成了1,也就是n = 2^x - 1其中x和n的值有关,如果没有超过MAXIMUM_CAPACITY,最后会返回一个2的正整数次幂,因此tableSizeFor的作用就是保证返回一个比入参大的最小的2的正整数次幂。
在JDK 7中初始化的代码大体一致,在HashMap第一次put的时候会调用inflateTable计算桶数组的长度,但其算法并没有变:
// 第一次put时,初始化table
private void inflateTable(int toSize) {
// Find an power of 2 >= toSize
int capacity = roundUpToPowerOf2(toSize);
threshold = (int)Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry(capacity);
initHashSeedAsNeeded(capacity);
}这里我们也回答了开头提出来的问题:
HashMap什么时候开辟bucket数组占用内存?答案是在HashMap第一次put的时候,无论Java 8还是Java 7都是这样实现的。这里我们可以看到两个版本的实现中,桶数组的大小都是2的正整数幂,至于为什么这么设计,看完后文你就明白了。
hash
在HashMap这个特殊的数据结构中,hash函数承担着寻址定址的作用,其性能对整个HashMap的性能影响巨大,那什么才是一个好的hash函数呢?
- 计算出来的哈希值足够散列,能够有效减少哈希碰撞
- 本身能够快速计算得出,因为
HashMap每次调用get和put的时候都会调用hash方法
下面是Java 8中的实现:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}这里比较重要的是(h = key.hashCode()) ^ (h >>> 16),这个位运算其实是将key.hashCode()计算出来的hash值的高16位与低16位继续异或,为什么要这么做呢?
我们知道hash函数的作用是用来确定key在桶数组中的位置的,在JDK中为了更好的性能,通常会这样写:
index =(table.length - 1) & key.hash();
回忆前文中的内容,table.length是一个2的正整数次幂,类似于000100000,这样的值减一就成了000011111,通过位运算可以高效寻址,这也回答了前文中提到的一个问题,HashMap内部的bucket数组长度为什么一直都是2的整数次幂?好处之一就是可以通过构造位运算快速寻址定址。
回到本小节的议题,既然计算出来的哈希值都要与table.length - 1做与运算,那就意味着计算出来的hash值只有低位有效,这样会加大碰撞几率,因此让高16位与低16位做异或,让低位保留部分高位信息,减少哈希碰撞。
我们再看Java 7中对hash的实现:
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}Java 7中为了避免hash值的高位信息丢失,做了更加复杂的异或运算,但是基本出发点都是一样的,都是让哈希值的低位保留部分高位信息,减少哈希碰撞。
put
在Java 8中put这个方法的思路分为以下几步:
- 调用
key的hashCode方法计算哈希值,并据此计算出数组下标index - 如果发现当前的桶数组为
null,则调用resize()方法进行初始化 - 如果没有发生哈希碰撞,则直接放到对应的桶中
- 如果发生哈希碰撞,且节点已经存在,就替换掉相应的
value - 如果发生哈希碰撞,且桶中存放的是树状结构,则挂载到树上
- 如果碰撞后为链表,添加到链表尾,如果链表长度超过
TREEIFY_THRESHOLD默认是8,则将链表转换为树结构 - 数据
put完成后,如果HashMap的总数超过threshold就要resize
具体代码以及注释如下:
public V put(K key, V value) {
// 调用上文我们已经分析过的hash方法
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
// 第一次put时,会调用resize进行桶数组初始化
n = (tab = resize()).length;
// 根据数组长度和哈希值相与来寻址,原理上文也分析过
if ((p = tab[i = (n - 1) & hash]) == null)
// 如果没有哈希碰撞,直接放到桶中
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// 哈希碰撞,且节点已存在,直接替换
e = p;
else if (p instanceof TreeNode)
// 哈希碰撞,树结构
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 哈希碰撞,链表结构
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 链表过长,转换为树结构
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
// 如果节点已存在,则跳出循环
break;
// 否则,指针后移,继续后循环
p = e;
}
}
if (e != null) { // existing mapping for key
// 对应着上文中节点已存在,跳出循环的分支
// 直接替换
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
// 如果超过阈值,还需要扩容
resize();
afterNodeInsertion(evict);
return null;
}相比之下Java 7中的put方法就简单不少
public V put(K key, V value) {
// 如果 key 为 null,调用 putForNullKey 方法进行处理
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K, V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key
|| key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K, V> e = table[bucketIndex]; // ①
table[bucketIndex] = new Entry<K, V>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length); // ②
}这里有一个小细节,HashMap允许putkey为null的键值对,但是这样的键值对都放到了桶数组的第0个桶中。
resize()
resize是整个HashMap中最复杂的一个模块,如果在put数据之后超过了threshold的值,则需要扩容,扩容意味着桶数组大小变化,我们在前文中分析过,HashMap寻址是通过index =(table.length - 1) & key.hash();来计算的,现在table.length发生了变化,势必会导致部分key的位置也发生了变化,HashMap是如何设计的呢?
这里就涉及到桶数组长度为2的正整数幂的第二个优势了:当桶数组长度为2的正整数幂时,如果桶发生扩容(长度翻倍),则桶中的元素大概只有一半需要切换到新的桶中,另一半留在原先的桶中就可以,并且这个概率可以看做是均等的。

通过这个分析可以看到如果在即将扩容的那个位上key.hash()的二进制值为0,则扩容后在桶中的地址不变,否则,扩容后的最高位变为了1,新的地址也可以快速计算出来newIndex = oldCap + oldIndex;
下面是Java 8中的实现:
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 如果oldCap > 0则对应的是扩容而不是初始化
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 没有超过最大值,就扩大为原先的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
// 如果oldCap为0, 但是oldThr不为0,则代表的是table还未进行过初始化
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
// 如果到这里newThr还未计算,比如初始化时,则根据容量计算出新的阈值
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
// 遍历之前的桶数组,对其值重新散列
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
// 如果原先的桶中只有一个元素,则直接放置到新的桶中
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
// 如果原先的桶中是链表
Node<K,V> loHead = null, loTail = null;
// hiHead和hiTail代表元素在新的桶中和旧的桶中的位置不一致
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
// loHead和loTail代表元素在新的桶中和旧的桶中的位置一致
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
// 新的桶中的位置 = 旧的桶中的位置 + oldCap, 详细分析见前文
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}Java 7中的resize方法相对简单许多:
- 基本的校验之后
new一个新的桶数组,大小为指定入参 - 桶内的元素根据新的桶数组长度确定新的位置,放置到新的桶数组中
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
boolean oldAltHashing = useAltHashing;
useAltHashing |= sun.misc.VM.isBooted() &&
(newCapacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
boolean rehash = oldAltHashing ^ useAltHashing;
transfer(newTable, rehash);
table = newTable;
threshold = (int) Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K, V> e : table) {
//链表跟table[i]断裂遍历,头部往后遍历插入到newTable中
while (null != e) {
Entry<K, V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}总结
在看完了HashMap在Java 8和Java 7的实现之后我们回答一下前文中提出来的那几个问题:
HashMap内部的bucket数组长度为什么一直都是2的整数次幂
答:这样做有两个好处,第一,可以通过(table.length - 1) & key.hash()这样的位运算快速寻址,第二,在HashMap扩容的时候可以保证同一个桶中的元素均匀的散列到新的桶中,具体一点就是同一个桶中的元素在扩容后一般留在原先的桶中,一般放到了新的桶中。
2. HashMap默认的bucket数组是多大
答:默认是16,即时指定的大小不是2的整数次幂,HashMap也会找到一个最近的2的整数次幂来初始化桶数组。
3. HashMap什么时候开辟bucket数组占用内存
答:在第一次put的时候调用resize方法
4. HashMap何时扩容?
答:当HashMap中的元素熟练超过阈值时,阈值计算方式是capacity * loadFactor,在HashMap中loadFactor是0.75
5. 桶中的元素链表何时转换为红黑树,什么时候转回链表,为什么要这么设计?
答:当同一个桶中的元素数量大于等于8的时候元素中的链表转换为红黑树,反之,当桶中的元素数量小于等于6的时候又会转为链表,这样做的原因是避免红黑树和链表之间频繁转换,引起性能损耗
6. Java 8中为什么要引进红黑树,是为了解决什么场景的问题?
答:引入红黑树是为了避免hash性能急剧下降,引起HashMap的读写性能急剧下降的场景,正常情况下,一般是不会用到红黑树的,在一些极端场景下,假如客户端实现了一个性能拙劣的hashCode方法,可以保证HashMap的读写复杂度不会低于O(lgN)
public int hashCode() {
return 1;
}HashMap如何处理key为null的键值对?
答:放置在桶数组中下标为0的桶中