探索emoji字符串长度之谜
不知道读者们是否被以下三个问题困扰过。
问题一:
在某一期迭代中我们遇到了这样的问题:有一串带有emoji的字符串,前端和后端获取到该字符串的长度不一致,导致在字符串最大长度限制的判断功能上出现了问题,是什么造成了这样的差异?
问题二:
"".charAt(0) === "".charAt(0)
charAt() 方法从一个字符串中返回指定的字符。—— MDN
问题三:
能否准确地说出以下字符的长度?
'a'.length
'嗨'.length
''.length
''.length
'♂️'.length
Unicode
这一切追根溯源,都和Unicode有关。而Unicode对我们来说是一个熟悉而又陌生的词。
Unicode是计算机科学领域里的一项业界标准。它对世界上大部分的文字系统进行了整理、编码,使得电脑可以用更为简单的方式来呈现和处理文字。—— wiki
在unicode还没有问世前,英语国家使用的编码规则是ASCII,但是亚洲许多国家,比如中国,又有自己的编码规则,如GB2312。各国之间传输文件一定会因此出现乱码的问题。而Unicode的出现帮我们统一了这些规则。
在我们更深入了解Unicode之前,先让我们了解几个术语
几个术语
-
Code points(码点) :
在unicode中,每一个符号都会对应一个以U+的形式记录的序列
-
Scripts:
在一个或多个书写系统中用来代表文本信息的字母和符号的集合。比如对于每一种语言都有一个对应的script。
-
Planes:
在unicode中用17个plane来管理所有的code points。每一个平面一共有65,536 个码点。
-
第一组就是我们最熟悉的基础多文种平面BMP(Basic Multilingual Plane)。为什么说最熟悉呢?因为其中包含了大部分通用语言的字符都坐落在这个平面内,比如ASCII字符,汉字等。
-
其他的16组就是补充多文种平面SMP(Supplementary Multilingual Plane)。存储了一些不常用的图形字符,比如其中有一个平面包含了一些古老的汉字。
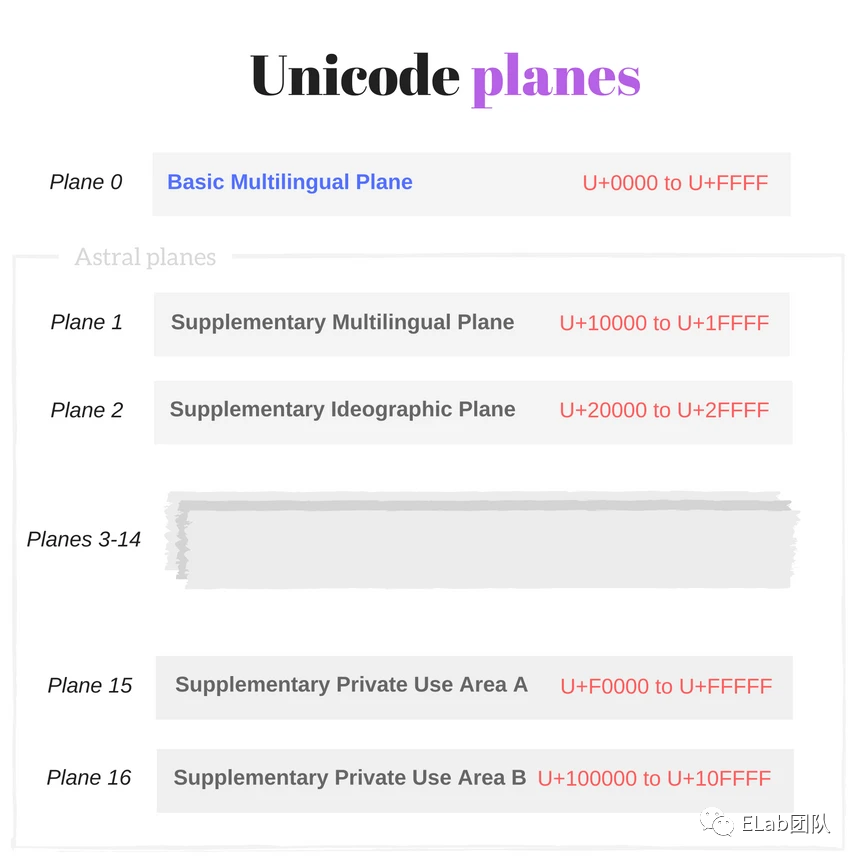
- Code unit(码元): 一串二进制序列,也是真正存储在计算机内部的形式。
这样说可能还有一些模糊,不急,我们慢慢往下看。
Unicode是一个符号集,将一个符号映射到一个唯一的十六进制序列上,但是却并没有规定计算机应该如何存储这个码点。
比如,汉字严的 Unicode 是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说,这个符号的表示至少需要15个bits。而如果想要表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这样就会造成问题:
- 计算机无法知道一个符号用几个字节表示,因为在Unicode中,存在4个字节表示一个符号的情况,最少的只需要1个字节(英文字母),然而如果我们告诉计算机规定用4个字节来表示一个符号的话,对于英文来说就是一种严重的浪费。
- 在一些古老的电脑系统中,会将连续的8个0标志认定为一个字符串的结尾。
- 向前兼容,需要和一些只能理解ASCII的机器兼容。
因此就有了 (字符编码)character encoding。把我们之前提到的code points翻译成为唯一的code units序列。常见的编码方式有:UTF - 8,UTF - 16。而每一种字符编码定义了他们各自的code units。
UTF - 8
在utf-8中将一个code unit定义为8个bits。
他有两条规则:
- 对于只有一个字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
- 对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
| Unicode编码(十六进制) | UTF-8字节流(二进制) |
|---|---|
| 000000-00007F | 0xxxxxxx |
| 000080-00007FF | 110xxxxx 10xxxxxx |
| 000800-00FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 010000-10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
计算机针对每一个字符,可以直接从他的第一个code unit的前几位,迅速地判断这个字符共有几个code unit(第一个code unit开头有几个1,就说明有几个code unit)。
让我们继续回到之前的严字。他的Unicode 是4E25(100111000100101)。那么使用utf-8转换之后的结果是什么呢?
- 从上表中可看到4E25落在了第三档 ,所以我们将选用1110xxxx 10xxxxxx 10xxxxxx的形式表示我们最终的二进制序列。
- 将4E25转换得到的二进制序列从后往前依次填入,并将剩下的空余位补0。
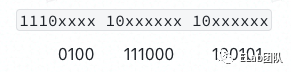
UTF - 16
大部分的JavaScript引擎使用UTF-16进行编码,这可以说是我们在日常处理字符串时遇到各种奇怪问题的根本原因。
在UTF-16中一个code unit是16bits。
并且规定:
- BMP 的code point保存在一个code unit(16bits)中
- SMP 保存在两个code unit(32bits)中
对于BMP来说编码前后没有任何区别,只是将16进制变为了二进制。
但是对于SMP来说就比较复杂。之前我们说过SMP的Unicode范围在0x10000 - 0x10FFFF之间。从0x10000开始,我们已经需要17个bits了
由于补充多语言平面的字符共有 个,而且在基本多文种平面内,我们预留出了一个空段(U+D800 到 U+DFFF )不映射任何字符,总共有 个,UTF-16 将补充多语言平面的 20 位拆成两半,前 10 位映射在空段中的 U+D800 到 U+DBFF(空间大小 ),称为高位,后10位映射在空段中的U+DC00 到 U+DFFF(空间大小 ),称为低位,它们组成了代理对(Surrogate pairs),也就是说补充多文种平面的字符是由两个基本多文种平面的字符表示。
这就解释了为什么
''.length == 2 // true
| Code Point | UTF-16 | |
|---|---|---|
| U+1F4A9 | '\uD83D\uDCA9' |
关于代理对的具体转换,可以关注以下文章
- https://mathiasbynens.be/notes/javascript-encoding#surrogate-pairs
现在我们就可以更好地理解 字素与字素簇(Grapheme and Grapheme Cluster) 的概念了。
字素是文本在书写时最小的单位,可以被理解为单独的“字”。在 Unicode 标准中,字符(Character)一般指码点。通常,一个字素就是一个字符。但是,也有些字素是由多个字符序列组合而成的,这样的字符序列被称为字素簇。比如字母 é 可以用字母 e (U+0065) 加上重音符(U+0301) 组合而成。像重音符这样用于修饰前一个字符的字符,被称为组合字符(Combining Character)。
Emoji在Unicode中的表达方式
但是为什么 ♂️.length == 7 ?这就和emoji的组合有关了。
零宽连字 (Zero-width joiner ZWJ)
最关键的就是零宽连字。他可以使两个本不会发生连字的字符产生连字效果。当一个ZWJ被放在两个emoji之间时,可以让它成为一个新的字符。
比如你可以打开控制台输入"\ud83d\udc68\u200d\ud83d\udc69\u200d\ud83d\udc66\u200d\ud83d\udc66"
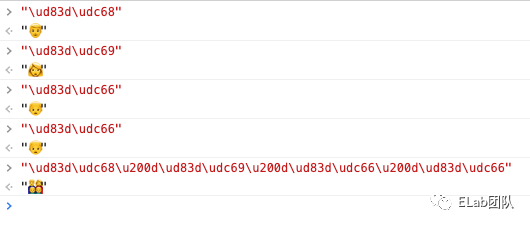
\u200d在这里就是ZWJ对应的utf-16码元表示形式。他可以把多个emoji粘合成一个emoji。
Emoji修饰符
另外,在emoji中还有其他的修饰符,比如emoji modifiers,他们可以用来修饰emoji的肤色

让我们来看一看消防员的构成

UTF-8和UTF-16的区别
在大多数网站上,UTF-8编码优于UTF-16编码,因为它使用较少的内存。回想一下,UTF-8仅在一个字节中编码每个ASCII字符。UTF-16必须将这些相同的字符编码为两个或四个字节。这意味着,以UTF-16编码的英文文本文件的大小至少是以UTF-8编码的同一文本文件大小的两倍。
Unicode in JavaScript
ES2015
字符串长度
对于普通的SMP来说,我们可以用String.prototype@iterator。因为他是可以感知unicode(unicode-aware),并且结合 [...str]or Array.from(str)(这两个属性都结合了字符串迭代器),最终会获得一个没有被打破的代理对,每一项均为一个独立symbol的数组。但是在处理比较复杂的emoji时,这个方法还有一定的缺陷,在针对组合的emoji(就比如上面的♂️)时,长度依然不是我们所想要的答案。所以使用字符串迭代器并不能很好的满足我们的需求,只能通过第三方依赖库实现。
- 推荐使用的依赖库:Mathias Bynens 的 Punycode.js[1]
正则表达式
/foo.bar/.test('foobar') // false
// ES6
/foo.bar/u.test('foobar') // true.只能匹配 ("\ud83d\udca9") 的代理对的高位 "\ud83d",但是 ES6 加了一个u flag 来支持匹配。
其他更多的u flag使用可以在以下视频中获得
- Mathias Bynens: RegExp.prototype.unicode | JSConf EU 2015[2]
ES2018
Unicode property escapes
Unicode标准为每个符号分配各种属性和属性值。例如,要获取专用于希腊语脚本的符号集,可以在Unicode数据库中将Script属性设置为Greek。但遗憾的是当前无法在ECMAScript正则表达式中使用这些Unicode字符属性。这使开发人员很难在正则表达式中支持完整的Unicode。
为解决这个问题,ES2018引入了Unicode property escapes。以前,希望在JavaScript中使用等效正则表达式的开发人员不得不求助于依赖项或构建脚本,这两者都会导致性能和可维护性问题。借助对Unicode属性转义的内置支持,基于Unicode属性创建正则表达式将会变得很简单。
- 匹配语种
Unicode script 按照字符所属的书写系统来划分字符,它一般对应某种语言。比如 \p{Script=Greek} 表示希腊语,\p{Script=Han} 表示汉语。
匹配下列字符串中的中文
let input = `I'm chinese!我是中国人`
console.log(input.match(/\p{Script=Han}+/u))
// ["我是中国人", index: 12, input: "I'm chinese!我是中国人", groups: undefined]2 . 匹配emoji
const regex = /\p{Emoji_Modifier_Base}\p{Emoji_Modifier}|\p{Emoji_Presentation}|\p{Emoji}\uFE0F/gu;
我们可以使用上述的正则匹配emoji
const regex = /\p{Emoji_Modifier_Base}\p{Emoji_Modifier}?|\p{Emoji_Presentation}|\p{Emoji}\uFE0F/gu;
const text = `
\u{231A}: ⌚ default emoji presentation character (Emoji_Presentation)
\u{2194}\u{FE0F}: ↔️ default text presentation character rendered as emoji
\u{1F469}: emoji modifier base (Emoji_Modifier_Base)
\u{1F469}\u{1F3FF}: emoji modifier base followed by a modifier
`;
let match;
while (match = regex.exec(text)) {
const emoji = match[0];
console.log(`Matched sequence ${ emoji } — code points: ${ [...emoji].length }`);
}但是它对于♂️这类的复杂emoji,依然无法准确匹配
ESNext
Intl.Segmenter: Unicode segmentation in JavaScript
其实Unicode官方已经定义了字素分割的算法来帮助我们找到字素之间的边界。但是目前这部分算法只能通过开发者自己实现,现在终于有希望通过JavaScrip原生方法实现。
let segmenter = new Intl.Segmenter("cn", {granularity: "grapheme"});
let input = "有几个字?♂️";
let segments = segmenter.segment(input);
for (let {segment, index, isGraphemeLike} of segments) {
console.log("segment at code units [%d, %d): «%s»%s",
index, index + segment.length,
segment,
isGraphemeLike ? " (grapheme-like)" : ""
);
}目前granularity提供了三种类型:grapheme, word, sentence
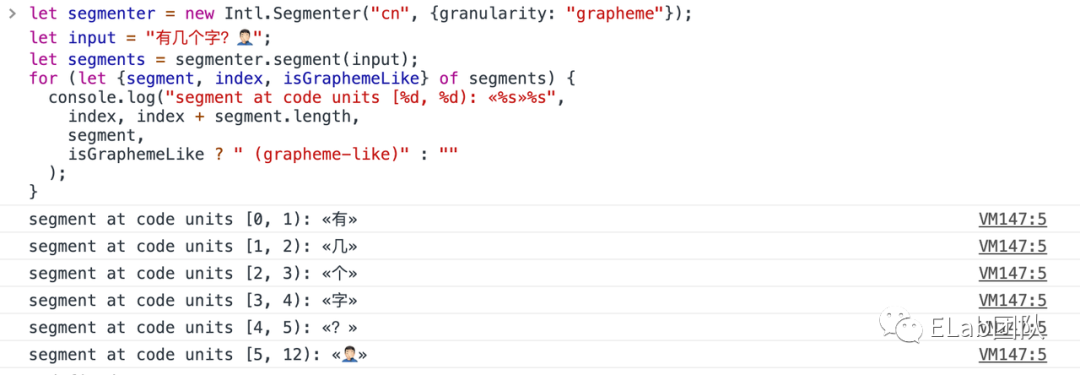
终于!终于我们可以看到♂️在segments中只被当作为一个segment,而不是之前用[...str]的方法分解出的五个。目前这一提案还在TC39的第三阶段,即将与大家见面!
参考:
- A Programmer's Introduction to Unicode[3]
- What every JavaScript developer should know about Unicode[4]
- JavaScript’s internal character encoding: UCS-2 or UTF-16?[5]
- Mathias Bynens: RegExp.prototype.unicode | JSConf EU 2015[6]
- Unicode In JavaScript [7]
- Unicode property escapes | MDN[8]
- JavaScript has a Unicode problem[9]
- https://mathiasbynens.be/notes/es-unicode-property-escapes
- UNICODE EMOJI Standard[10]
- https://github.com/tc39/proposal-regexp-unicode-sequence-properties
- https://github.com/tc39/proposal-regexp-unicode-property-escapes
- https://github.com/tc39/proposal-intl-segmenter
- http://speakingjs.com/es5/ch24.html
- 字符编码笔记:ASCII, Unicode和UTF-8[11]
参考资料
[1]Punycode.js: https://github.com/bestiejs/punycode.js
[2]Mathias Bynens: RegExp.prototype.unicode | JSConf EU 2015: https://www.youtube.com/watch?v=raJcug_vW0c
[3]A Programmer's Introduction to Unicode: http://reedbeta.com/blog/programmers-intro-to-unicode/?utm_source=ESnextNews.com&utm_medium=Weekly+Newsletter&utm_campaign=2017-02-13
[4]What every JavaScript developer should know about Unicode: https://dmitripavlutin.com/what-every-javascript-developer-should-know-about-unicode/
[5]JavaScript’s internal character encoding: UCS-2 or UTF-16?: https://mathiasbynens.be/notes/javascript-encoding
[6]Mathias Bynens: RegExp.prototype.unicode | JSConf EU 2015: https://www.youtube.com/watch?v=raJcug_vW0c
[7]Unicode In JavaScript : https://juejin.im/post/6844904066221359111
[8]Unicode property escapes | MDN: https://github.com/tc39/proposal-regexp-unicode-property-escapes
[9]JavaScript has a Unicode problem: https://mathiasbynens.be/notes/javascript-unicode
[10]UNICODE EMOJI Standard: http://unicode.org/reports/tr51/
[11]字符编码笔记:ASCII, Unicode和UTF-8: http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html