OCRunner 第三篇:代码生成
前言
为什么要使用代码生成?
主要是为了后期更好的可维护性,当修改了 RunnerClasses.h 中的类名、属性名或者属性类型后,依然可能使用通用的规则生成序列化代码,不需要手动的去调整代码以适应新的结构。以 oc2mango 的 StackVirtualMachine 分支为例,作者已经将 RunnerClasses.h 中的类修改得面目全非了,结构也调整过了,再使用 BinaryPatchCodeGenerator 生成序列化代码时,只需要简单的调整,就可以解决大改 2000行序列化代码的问题。
BinaryPatchCodeGenerator 介绍
BinaryPatchHelper.h / .m 中的代码,除去**_ORNode, _ListNode, _StringsNode, _StringNode, _PatchNode**和相关函数外,其余代码皆由 BinaryPatchCodeGenerator 根据规则生成。
BinaryPatchCodeGenerator 使用 oc2mangoLib 将 RunnerClasses.h 解析为语法树,根据文件存在的类,生成相应的结构体代码,以及 类和结构体的转换、反转换,结构体数据的序列化、反序列化以及销毁,一共5个函数。并且针对类型为NSUInteger、NSArray、NSString的属性对应转换为 uint32_t、_ListNode 和 _StringNode。
根据语法树 类 -> 结构体 的代码生成
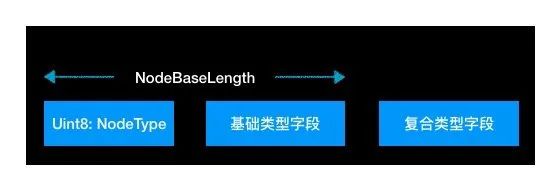
- 根据类在文件中的顺序生成 enum NodeType 的代码,所有结构体的第一个字节为该数据
- enum、NSUInteger类型的属性转换为 uin32_t 类型的结构体成员变量
- NSArray、NSString类型的属性分别转换为 _ListNode、_StringNode 类型的结构体成员变量
- 结构体中基本类型成员变量全部前置: Int,double,BOOL等
- 自动计算结构体中所有基本类型数据的长度,并添加一个相应结构体的基础字段数据长度的全局常量
- 结构体内存对齐值为1
相关函数生成
- 节点对象 -> 结构体的转换函数
- 结构体数据写入 buffer 函数
将语法树写入到缓冲区的思路:对语法树使用前序遍历,我们的目的很简单,将所有的基本类型的数据保存下来。针对每一个节点,调用写入函数,首先使用节点的 BaseLength 常量,将节点结构体的中的基本数据写入缓冲区,针对复合类型节点,调用相应的写入函数即可。 3. 从 buffer 中读取数据,转换为结构体
根据 buffer 的第一字节,判断节点类型,调用反序列化函数,根据节点的 BaseLength 常量,将基本数据拷贝到结构体中,再将自己的子节点循环调用这一过程。 4. 结构体-> 节点对象的转换函数 5. 针对每个节点的结构体的内存销毁函数
再看看我们目标内存布局的图,看着不像前序遍历,但仔细的看一下最终数据的顺序,就能发现我们先保存的是父节点的数据,然后再是左右子节点。
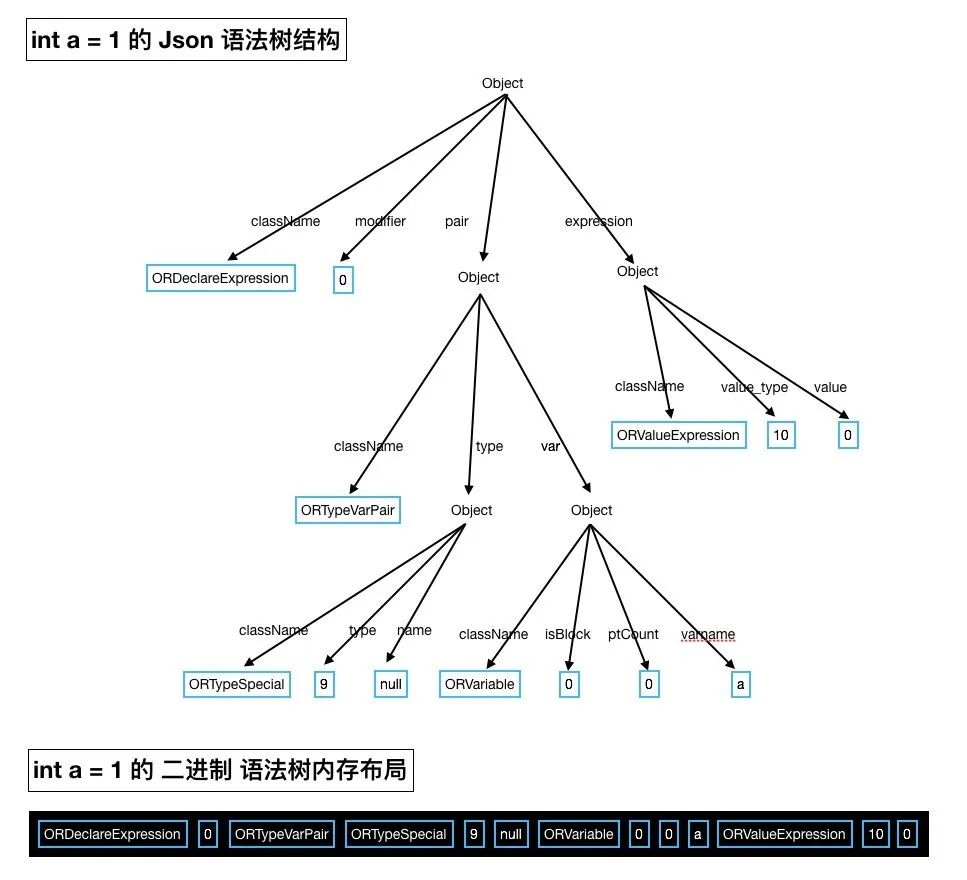
例子1: 类 ORTypeSpecial 生成结构体 _ORTypeSpecial 以及相关函数
@interface ORTypeSpecial: ORNode
@property (nonatomic, assign) TypeKind type;
@property (nonatomic, nullable, copy) NSString * name;
@end
//结构体名:"_" + 类名
//结构体基础类型字段总和长度:"_" + 类名 + "BaseLength"
//字段数量和名字:和类中的属性完全相同
typedef struct {
_ORNodeFields
uint32_t type;
_StringNode * name;
}_ORTypeSpecial;
// BaseLength
static uint32_t _ORTypeSpecialBaseLength = 5;
// 对象->结构体
_ORTypeSpecial *_ORTypeSpecialConvert(ORTypeSpecial *exp, _PatchNode *patch, uint32_t *length);
// 结构体 -> 对象
ORTypeSpecial *_ORTypeSpecialDeConvert(_ORTypeSpecial *node, _PatchNode *patch);
// 结构体 -> bytes
void _ORTypeSpecialSerailization(_ORTypeSpecial *node, void *buffer, uint32_t *cursor);
// bytes -> 结构体
_ORTypeSpecial *_ORTypeSpecialDeserialization(void *buffer, uint32_t *cursor, uint32_t bufferLength);
// free
void _ORTypeSpecialDestroy(_ORTypeSpecial *node);下列约定,主要用于序列化和反序列化的代码生成。
节点序列化约定:
每个节点结构体的序列化函数(转换为 bytes ),使用 BaseLength 值,将所有的基础类型的数据写入buffer。子节点的序列化同样使用这个规则。
- 每个结构体需实现自身的序列化函数
void \(structName)Serailization(\(structName) *node, void *buffer, uint32_t *cursor)
- 将所有基础类型数据写入内存时,采用如下方式
memcpy(buffer + *cursor, node, \(structName)BaseLength);
*cursor += \(structName)BaseLength;- 针对复合类型字段,需要严格按照结构体成员的顺序写入内存。
typedef struct {
_ORNodeFields
_ORNode * type;
_ORNode * var;
}_ORTypeVarPair;
static uint32_t _ORTypeVarPairBaseLength = 1;
void _ORTypeVarPairSerailization(_ORTypeVarPair *node, void *buffer, uint32_t *cursor){
memcpy(buffer + *cursor, node, _ORTypeVarPairBaseLength);
*cursor += _ORTypeVarPairBaseLength;
_ORNodeSerailization((_ORNode *)node->type, buffer, cursor);
_ORNodeSerailization((_ORNode *)node->var, buffer, cursor);
}- 使用统一的入口,将结构体的基础类型数据写入内存,根据类型对应的结构体,使用该结构体的序列化函数
void _ORNodeSerailization(_ORNode *node, void *buffer, uint32_t *cursor){
if (node->nodeType == ORNodeType) {
memcpy(buffer + *cursor, node, \(_ORNodeLength));
*cursor += \(_ORNodeLength);
}else if
...
//各个节点类型判断,根据类型使用相应的序列化函数
}节点反序列化约定:
每个节点结构体的反序列化函数(bytes -> 结构体),使用 BaseLength 值,从 buffer 中读取所有的基础类型的数据,然后复制到结构体中。子节点的反序列化同样使用这个规则。
- 每个结构体需实现自身的反序列化函数
\(structName) *\(structName)Deserialization(void *buffer, uint32_t *cursor, uint32_t bufferLength)
- 从内存中将所有的基本类型数据保存到结构体时,采用如下方式
\(structName) *node = malloc(sizeof(\(structName)));
memcpy(node, buffer + *cursor, \(structName)BaseLength);- 针对复合类型字段,需要严格按照结构体成员的顺序从内存中读取。
typedef struct {
_ORNodeFields
_ORNode * type;
_ORNode * var;
}_ORTypeVarPair;
static uint32_t _ORTypeVarPairBaseLength = 1;
_ORTypeVarPair *_ORTypeVarPairDeserialization(void *buffer, uint32_t *cursor, uint32_t bufferLength){
_ORTypeVarPair *node = malloc(sizeof(_ORTypeVarPair));
memcpy(node, buffer + *cursor, _ORTypeVarPairBaseLength);
*cursor += _ORTypeVarPairBaseLength;
node->type =(_ORNode *) _ORNodeDeserialization(buffer, cursor, bufferLength);
node->var =(_ORNode *) _ORNodeDeserialization(buffer, cursor, bufferLength);
return node;
}- 使用统一的入口,将结构体的基础类型数据写入内存,根据类型对应的结构体,使用该结构体的序列化函数
_ORNode *_ORNodeDeserialization(void *buffer, uint32_t *cursor, uint32_t bufferLength){
_NodeType nodeType = ORNodeType;
if (*cursor < bufferLength) {
nodeType = *(_NodeType *)(buffer + *cursor);
}
...
//各个节点类型判断,根据类型使用相应的反序列化函数
}自定义的结构体
_ORNode
所有节点结构体都继承自**_ORNode** 结构体,在内存中,第一个字节的数据,始终是类型字段 nodeType: _NodeType 枚举列表。
#define _ORNodeFields \
uint8_t nodeType;
//继承是使用预编译实现
typedef struct {
_ORNodeFields
}_ORNode;
static uint32_t _ORNodeLength = 1;_StringsNode
与 Json 补丁中的字符串表类似,但 _StringsNode 结构体不再是一个数组,它拥有一块内存,用来存储所有的字符串,同时它还有这块内存的大小的字段。
typedef struct {
_ORNodeFields
uint32_t cursor;
char *buffer;
}_StringsNode;
static uint32_t _StringsNodeBaseLength = 5;_StringNode
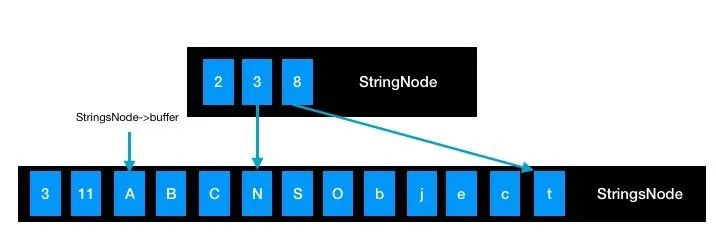
与 _StringsNode 相配合使用,用于在 _StringsNode->buffer 中定位并获取相应长度的字符串。
// StringNode是对NSString的转换。
typedef struct {
_ORNodeFields
uint32_t offset;
uint32_t strLen;
}_StringNode;
static uint32_t _StringNodeBaseLength = 9;使用**_StringNode**获取字符串,如下代码:
StringNode node = { StringNodeType, 3, 8 };
StringsNode table = {StringsNodeType, 11, "ABCNSObject"};
NSString *result = stringsNodeGetString(table, node);
result = @"NSObject";在内存中的操作,如图所示:
_ListNode
// _ListNode是对NSArray的转换。
typedef struct {
_ORNodeFields
uint32_t count;
_ORNode **nodes;
}_ListNode;
static uint32_t _ListNodeBaseLength = 5;_PatchNode
// _PatchNode是对ORPatchFile的转换。
typedef struct {
_ORNodeFields
BOOL enable;
_StringsNode *strings;
_StringNode *appVersion;
_StringNode *osVersion;
_ListNode *nodes;
}_PatchNode;
static uint32_t _PatchNodeBaseLength = 2;其他所有结构体相关代码,皆由 BinaryPatchCodeGenerator 使用之前的规则生成
大小端问题
经测试,macos和iOS均是小端模式,放心使用即可。