我从来不理解 “压缩算法”,直到有人这样向我解释它
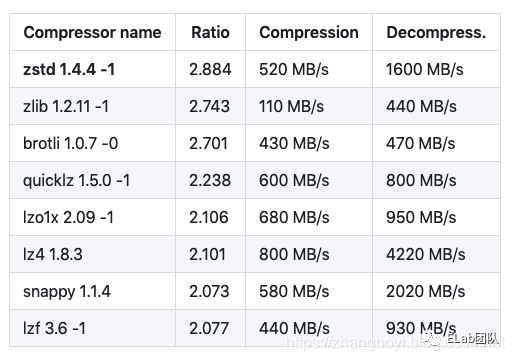
大家对于压缩应该并不陌生,几乎每天都跟压缩打交道
常见的压缩软件:7-zip,WinRAR,2345好压
常见的压缩格式:.zip,.rar,.tar.gz
压缩软件有很多,但是都是同一个目的,为了减小文件占用的存储空间
除了上面这些压缩格式,像.jpg,.mp3,.avi这些,也都是有着压缩的作用,只不过跟上面.zip这些相比,它们执行的是有损压缩
1 有损压缩
有损压缩是利用了人类对图像或声波中的某些频率成分不敏感的特性,允许压缩过程中损失一定的信息,虽然不能完全恢复原始数据,但是所损失的部分对理解原始图像的影响缩小,却换来了大得多的压缩比,有损压缩广泛应用于语音,图像和视频数据的压缩。
也就是说,当一个文件进行有损压缩后,他就会永远丢失一部分的数据,无论如何都没办法再将这个被有损压缩的文件百分百还原到他原来的样子,既然有损压缩会永远丢失数据,我们为什么还需要有损压缩呢?
因为有损压缩后可以获得更高的性价比,我们完全可以接受丢失的部分数据,这些丢失的数据并不会对我们的使用产生什么影响


比如我们几乎每天聊天都会用到的表情包,就是有损压缩的功劳,这些表情包一旦出现马赛克就再也无法还原,但却拥有更好的可用性和传播性
2 无损压缩
是利用数据的统计冗余进行压缩,压缩后可完全恢复原始数据而不引起任何失真,但压缩率是受到数据统计冗余度的理论限制,一般为2:1到5:1,这类方法广泛用于文本数据,程序和特殊应用场合的图像数据(如指纹图像,医学图像等)的压缩。
无损压缩的入门难度并不算很高,但是想要搞好它却非常难,而且不同的压缩算法能够实现的压缩率和压缩的速度也有比较大的差别
发展到今天的无损压缩算法,能把文件压缩到原来的30%-40%已经是很厉害的了,而且压缩比例越高,解压也就越麻烦
计算机里,文件是由各种不同的代码组成的,而压缩的基本原理就是通过寻找规律,从而简化代码里字符的排列组合,于是就出现了各种各样的压缩算法
比如:游程编码,字典算法,哈夫曼编码。。。
举个例子:
有下面一组数据
bbbbbbyytttttedddaaannccccccceee
想要对它进行压缩,大家是不是看一眼就知道要怎么做了

6b3y5t1e3d3a2n7c4e
可以用重复的次数加上字符本身来进行压缩,这段本身要占34位字符的数据就被压缩成了只有18个字符位的数据,减少了16个字符的位置
这种最简单的压缩方式就是游程编码(Run Length Encoding,RLE)但是这个算法有个很大的缺点,如果没有成堆出现的重复字符,在经过游程编码压缩后,最坏的情况,压缩后的文件甚至是压缩前大小的两倍
字典算法将文件中出现频率比较高的单词拿出来,生成一个字典列表(类似key-value的键值对),再用特殊的代码来表示这个单词
比如说,你有个朋友叫 ’沃德天·沃卫申么·拉末帅·夫斯基‘
如果你每提一次他的名字就得说一遍的话,那这不令人烦躁?
可以起个绰号:00,下次提到他的名字的时候用00就完事了,压缩后的长度少了很多
当然这不是目前人类能想到的最优解
哈夫曼编码(Huffman Coding)1952年,还在读博士的哈夫曼,在完成《信息论》期末作业的时候,顺便~在字典算法的基础上做了优化,他认为,越是经常出现的东西,越应该用简短的字符来替换表示它,所以就诞生了压缩领域的经典算法——哈夫曼编码压缩。
简单的讲,就是越经常出现的内容,越要用少的内容来描述它,占位也就越少,而不常见的内容,描述的长度也就相对越长,占位也就越多
举个例子,有下面一组数据
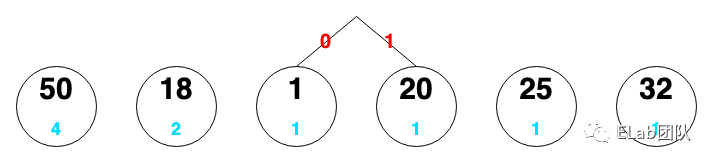
1,50,20,50,50,18,50,25,32,18
如果要对这组数据使用哈夫曼编码进行压缩,首先根据这些数字出现的次数排列
50,18,1,20,25,32
把它们看成一个个节点,节点下面的蓝色是该数字出现的次数

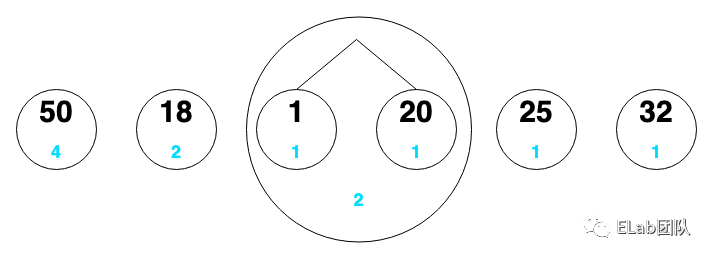
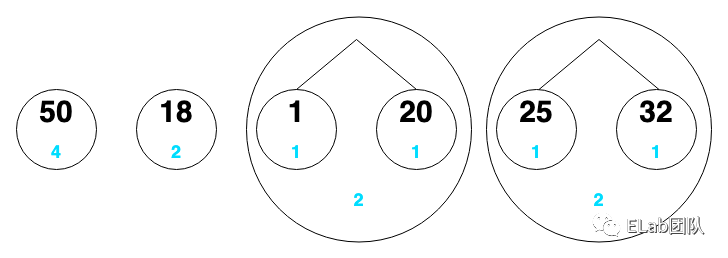
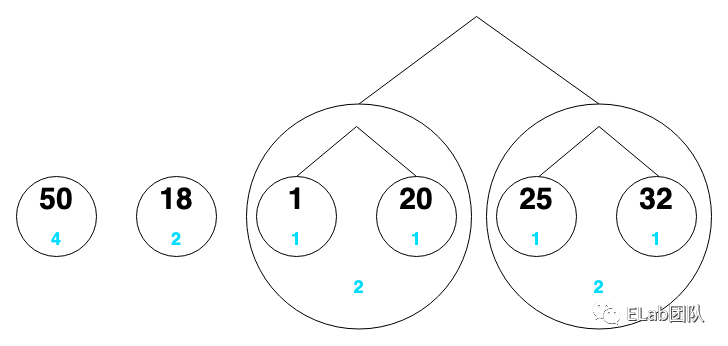
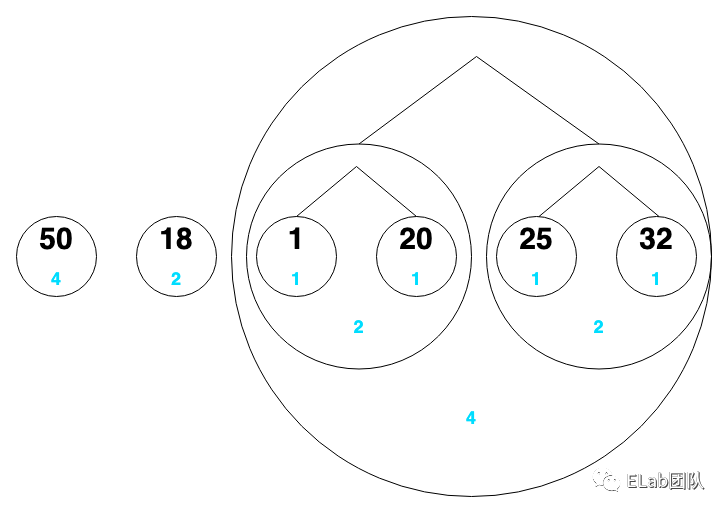
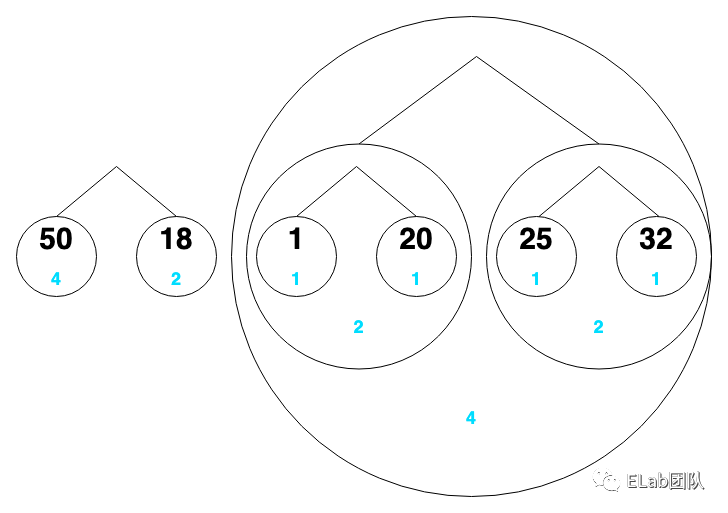
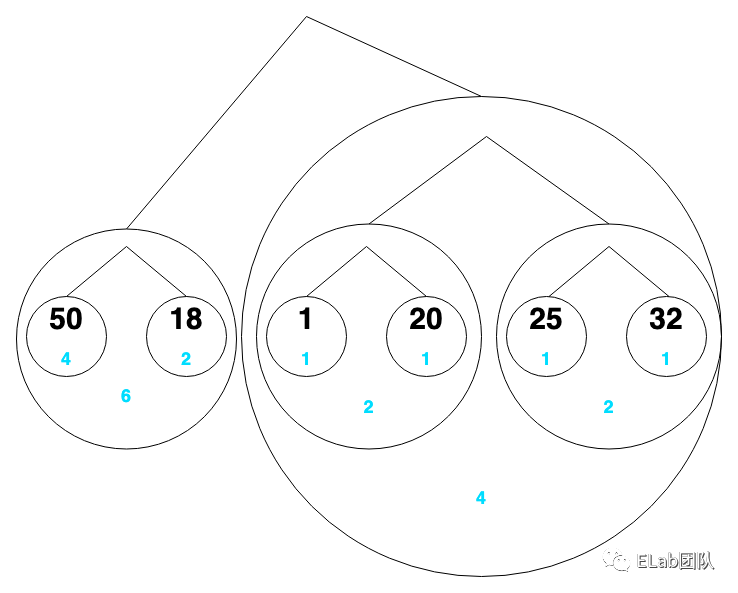
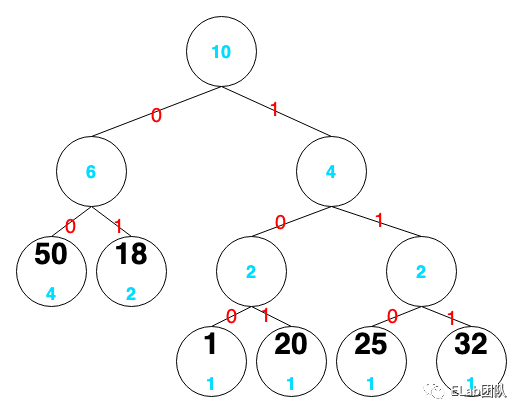
- 50:00
- 18:01
- 1:100
- 20:101
- 25:110
- 32:111
1,50,20,50,50,18,50,25,32,18
上面这组数据在经过哈夫曼编码压缩后就变成了
100,00,101,00,00,01,00,110,111,01
将原始数据转成二进制进行比较
1,110010,10100,110010,110010,10010,110010,11001,100000,10010
明显节省了很多空间
其实每种压缩算法都有各自的优势,而我们日常中接触的压缩文件,大部分都是多种压缩算法共同努力的结果
3 压缩炸弹
压缩炸弹:一个很小很小非常小,只有几十kb大的压缩文件,在被解压后却像炸弹一样,无限套娃,炸出几百万GB的源文件
一个叫42.zip的文件,初始大小就只有42kb,用解压密码42完全解压之后,足足有4.5PB那么大,
被解压后,这个42.zip会出现16个压缩包,每个压缩包里面又有16个相同的压缩包,循环5次之后,就会得到16的5次方,也就是1048576个文件,而这些最终的文件每个都有4.3GB那么大,所以最终能得到1048576*4.3GB约等于4.5PB,普通的电脑肯定是扛不住的
附上42.zip的下载链接(谨慎使用) https://unforgettable.dk/
还有更猛的
droste.zip
它更小,只有28kb大,但是它一旦被解压,就会无限套娃一样,解压出一份一模一样的压缩文件出来,再自动解压,又出来一个一模一样的,就这样一直重复下去。。。硬盘就直接炸了
这个文件的原理就是把自己当作结果输出出来

别看上面那两个文件压缩比例很高,但实际上信息熵很少,因为里面全是大量刻意重复的数据,而压缩就是一个消除冗余的过程,所以这种文件也就能压缩到非常小了
那有没有压缩比例高,但又不是刻意重复数据的文件呢?
在2000年左右制作的一部3D影片“彗星撞地球”,就展示了惊人的压缩比
《彗星撞地球》百度网盘资源(谨慎使用):https://pan.baidu.com/s/1sj8Z7p7
如果直接放出来的话,差不多有15G,而它被压缩完之后只有64KB,少了250000倍
影片的制作人Warez,用一个只有64kb的.exe文件就实现了,在解压运行的时候可以调用显卡、cpu还有内存,进行实时渲染,将影片当场一帧一帧地渲染出来
像这样的压缩方式,还运用到某些游戏中,像赛博朋克2077这种,所以需要一台配置足够好的电脑才能跑得起来
回到上面讲到的42.zip和droste.zip这类文件,它们的作用是什么?
在2000年左右,这些压缩文件实际上是用来攻击别人计算机的
一些电脑病毒的制造者,专门利用杀毒软件会扫描压缩文件内部的特性,会把压缩炸弹带着病毒一起发到目标的电脑上
压缩炸弹本身又很小,非常好传输,但实际扫描起来却非常花时间,病毒就趁着杀毒软件逐个扫描4.5PB的文件时候侵犯电脑

相关链接:
https://blog.csdn.net/weixin_30783913/article/details/97260476
https://www.cnblogs.com/zhouie/p/10702591.html
https://blog.csdn.net/fanyun_01/article/details/80211799