今日头条 ANR 优化实践系列 - 告别 SharedPreference 等待
简述
前面系列文章(详见文末)中介绍了安卓系统 ANR 设计原理以及我们在实际工作中对 ANR 进行监控得到的方案,基于常规的监控治理方案,ANR 问题得到了有效的抑制,但是有些系统组件的设计初衷与开发人员在实际使用过程中实际使用的背离,导致的冲突问题亟待解决,当前文章针对实际开发过程中滥用 sp 导致的 ANR 问题,如何从系统层面跳过 Google 设计缺陷,规避 ANR 问题。
Google 在设计之初为了方便开发者,实现了一套轻量级的数据持久化方案——SharedPreference(以下简称 sp),因为其简便的 API,方便的使用方式,得到开发者的青睐,对其依赖越来越重。在应用版本不断迭代的过程中发现 Google 说的轻量级的数据存储是有原因的,越是重量级的应用出现的 ANR 问题越严重。本文从源码层面分析在加载和写入过程中,导致 ANR 问题的原因以及相关的优化解决方案。
SP 导致 ANR 原因分析
经常会遇到两类关于 SharedPreference 问题,以下分别介绍导致这两类 ANR 问题的原因和优化方案。
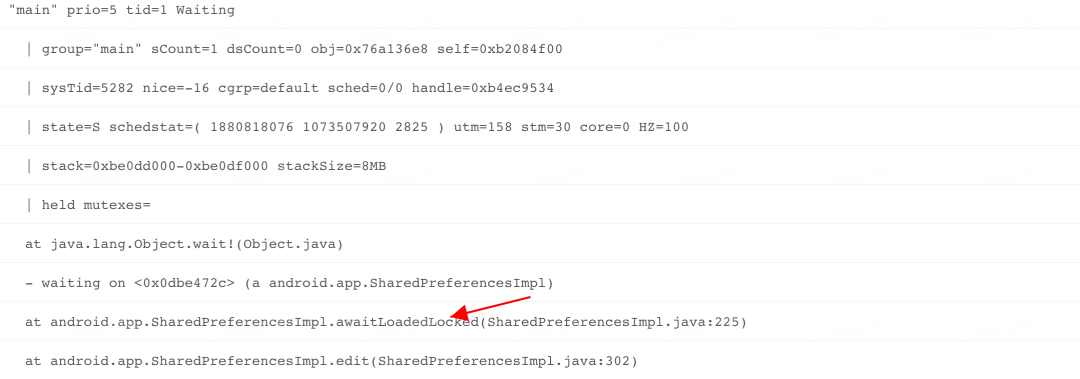
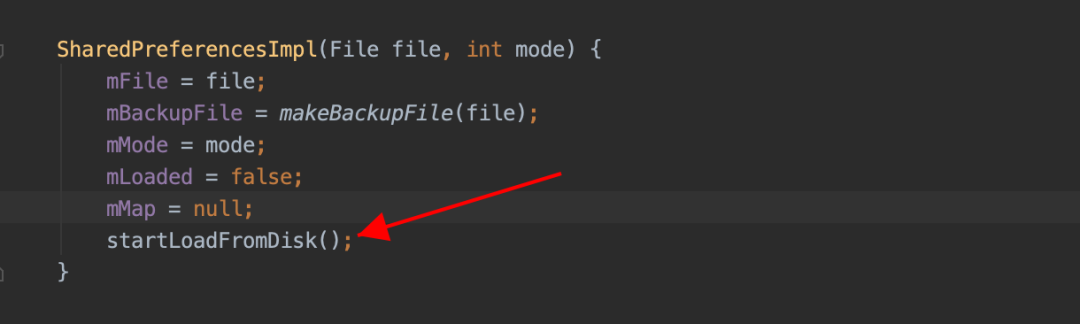
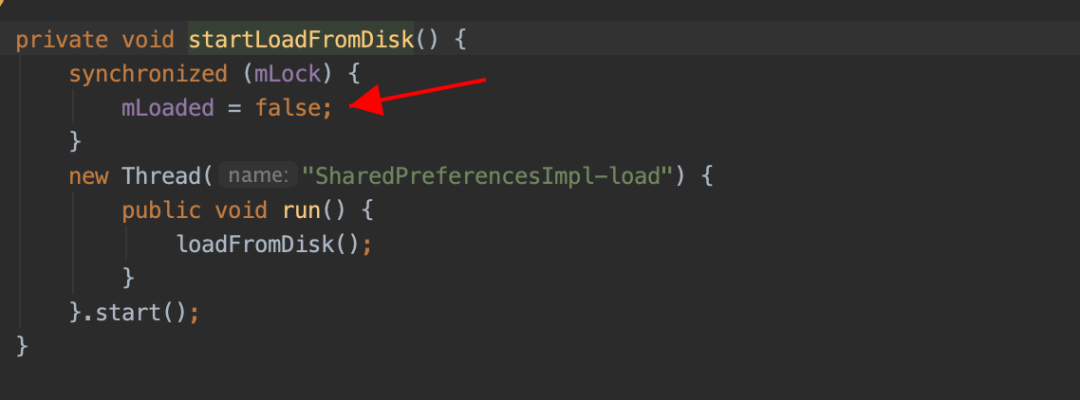
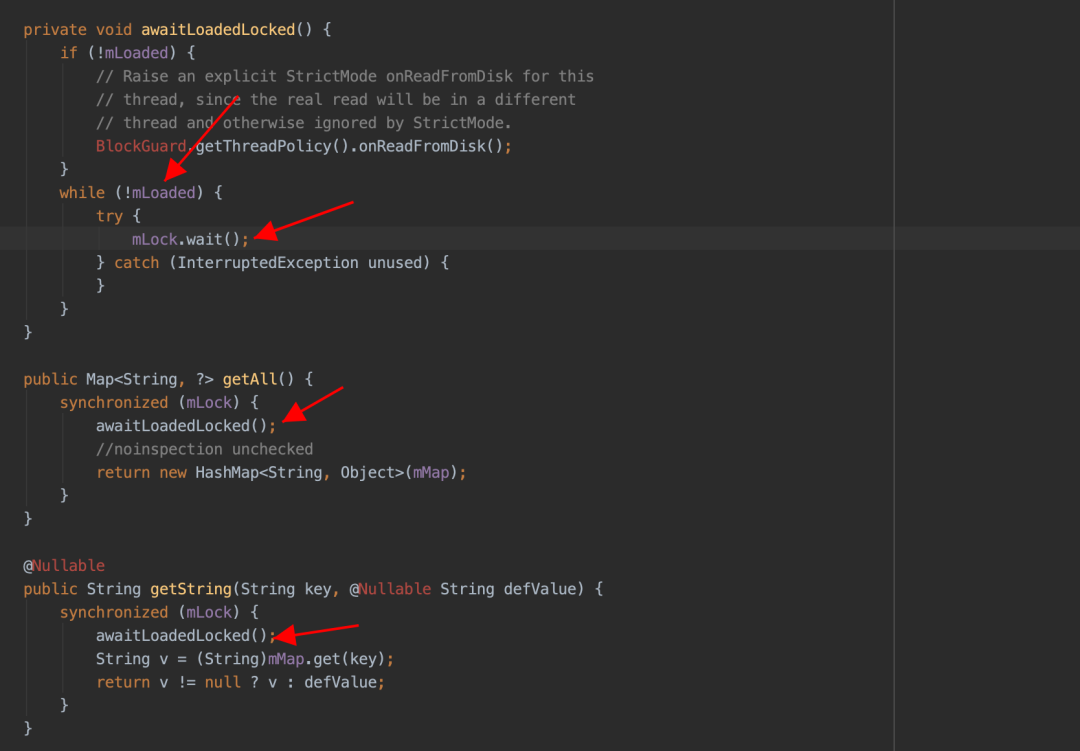
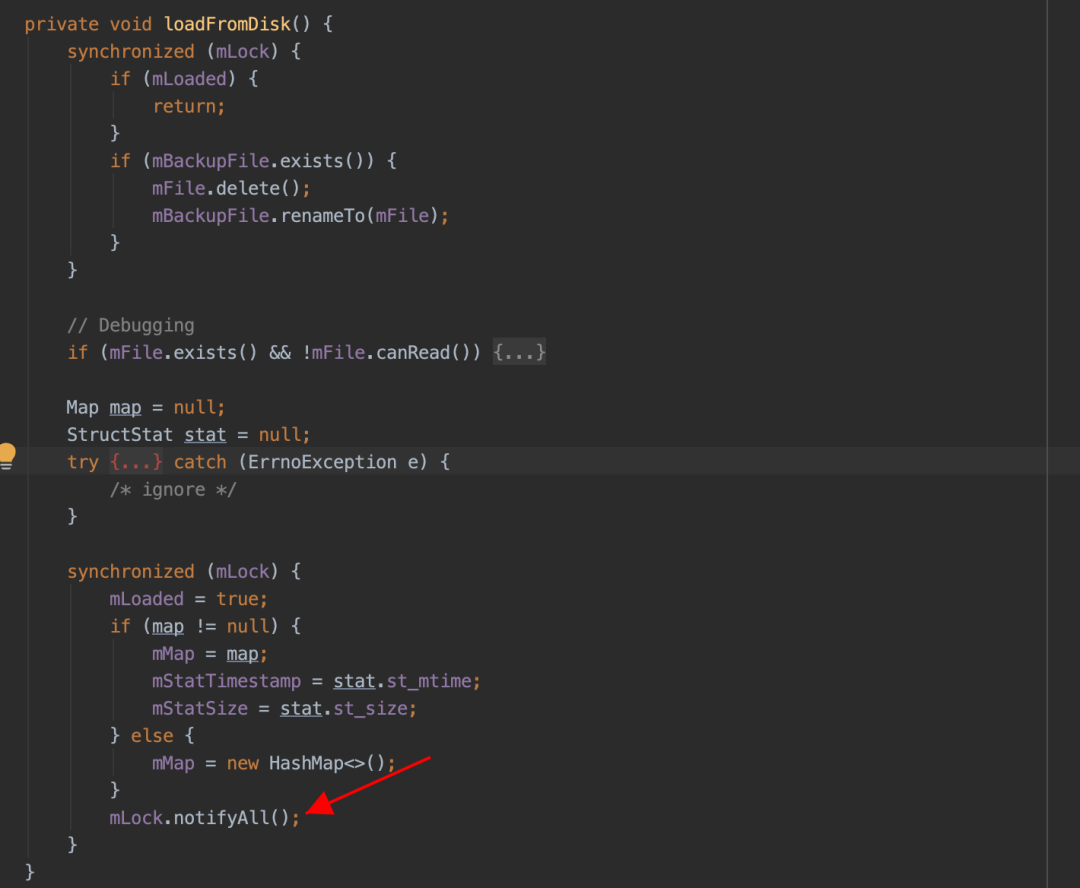
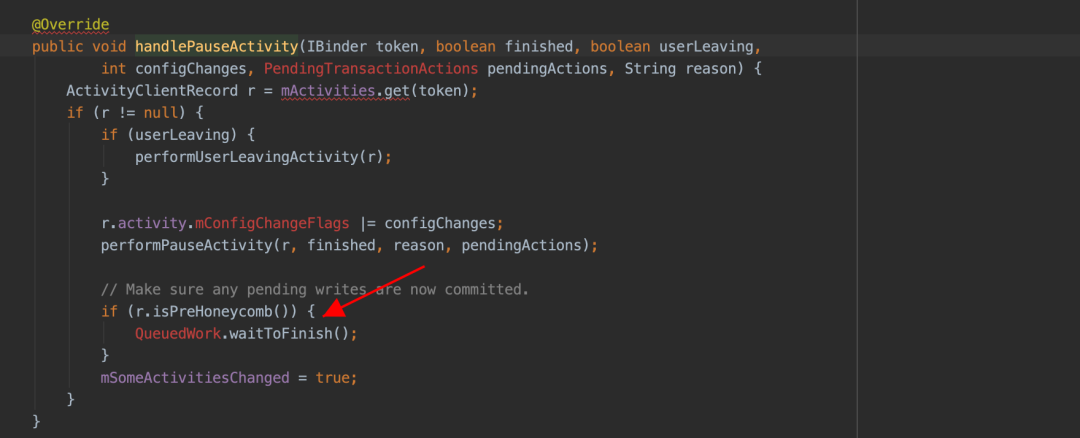
问题一:sp 文件创建以后,会单独的使用一个线程来加载解析对应的 sp 文件。但是当 UI 线程尝试访问 sp 中内容时,如果 sp 文件还未被完全加载解析到内存,此时 UI 线程会被 block,直到 SP 文件被完全加载到内存中为止。具体 ANR 线程堆栈如下:
public static final int SERVICE_ARGS = 115;
public static final int STOP_SERVICE = 116;
public static final int PAUSE_ACTIVITY = 101;
public static final int STOP_ACTIVITY_SHOW = 103;
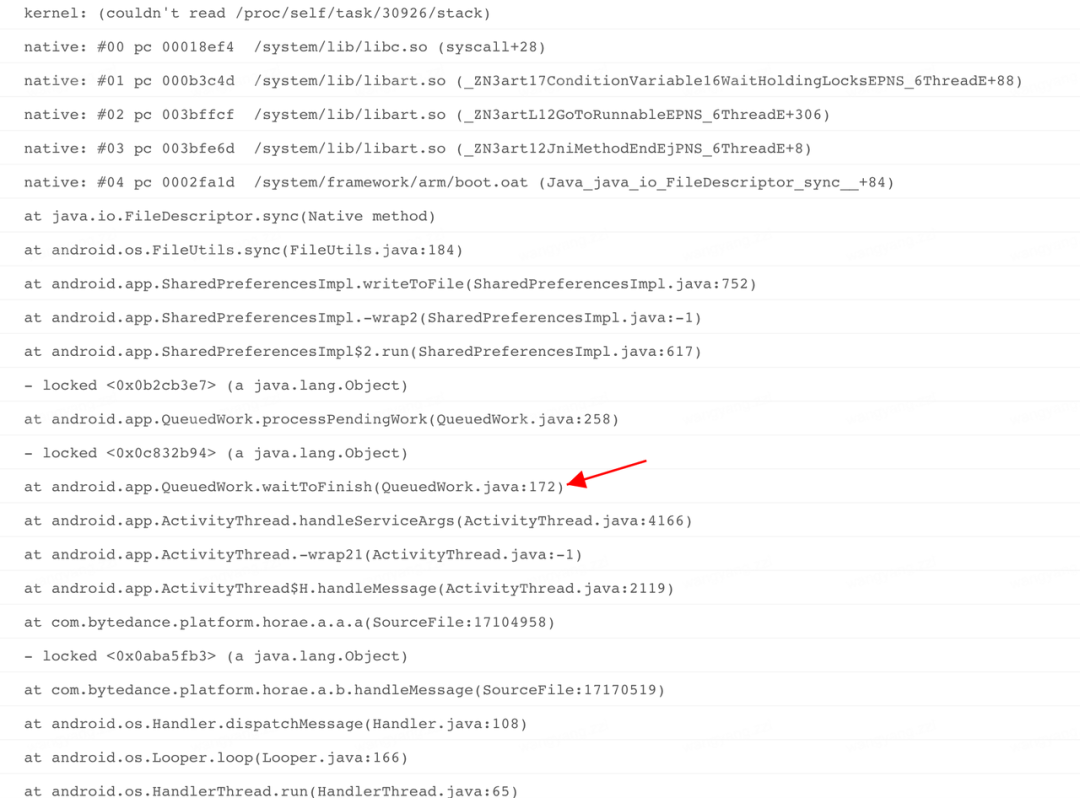
public static final int SLEEPING = 137;由于 Google 官方设计之初是轻量级的数据存储方式,这种等待行为不会有什么问题,但是实际使用过程中由于 sp 过度使用,这个等待的时间被不可控的拉长,直到最后出现 ANR,这种问题越在业务繁重的应用上体现越明显。具体问题堆栈如下,全是系统堆栈,接下来从 waitToFinish 入手分析,剖析这个 ANR 的根源。具体 ANR 堆栈如下:
apply 接口整体的详细设计思路如下图(基于 Android8.0 及以下版本分析):
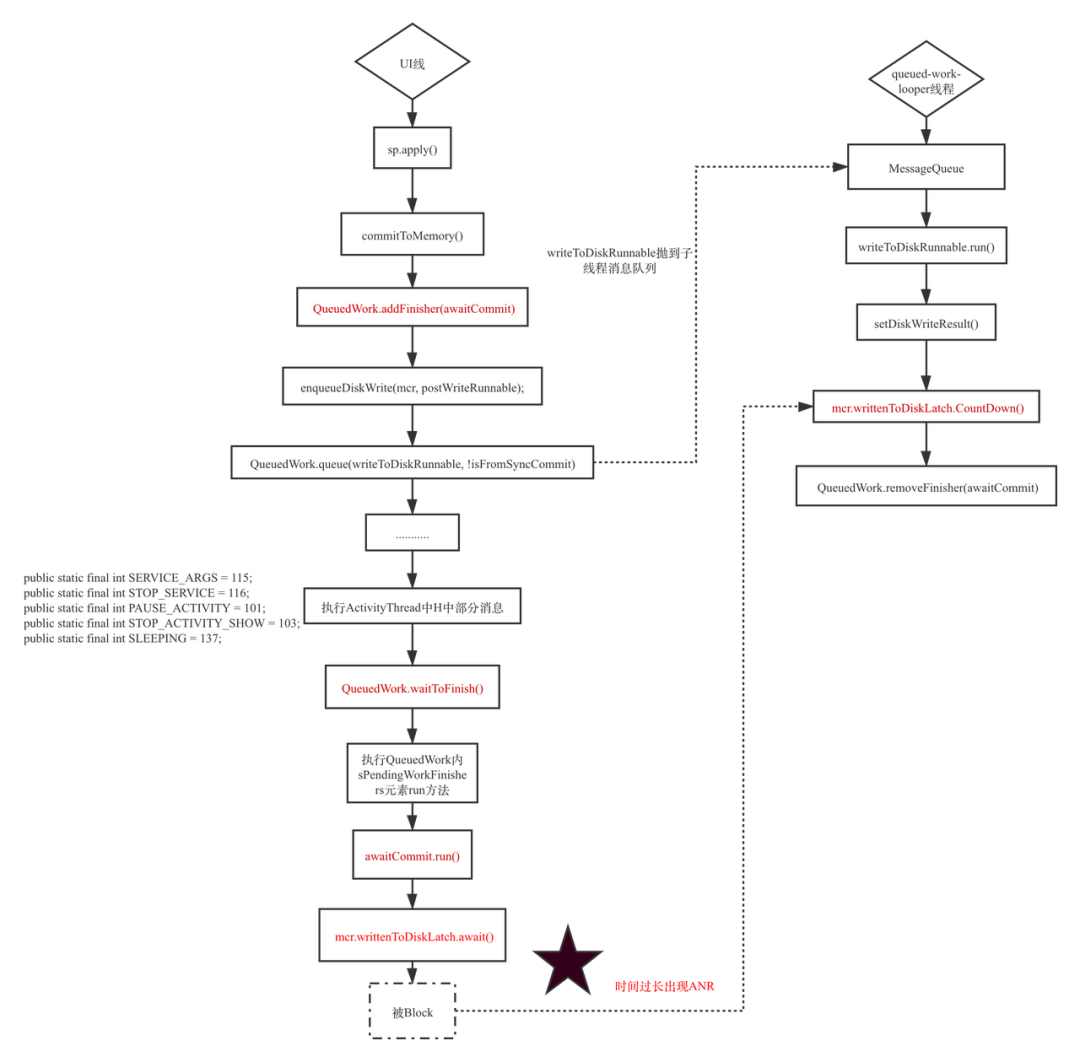
- sp.apply(),写入内存同时得到需要同步写入文件的数据集合 MemoryCommitResult:
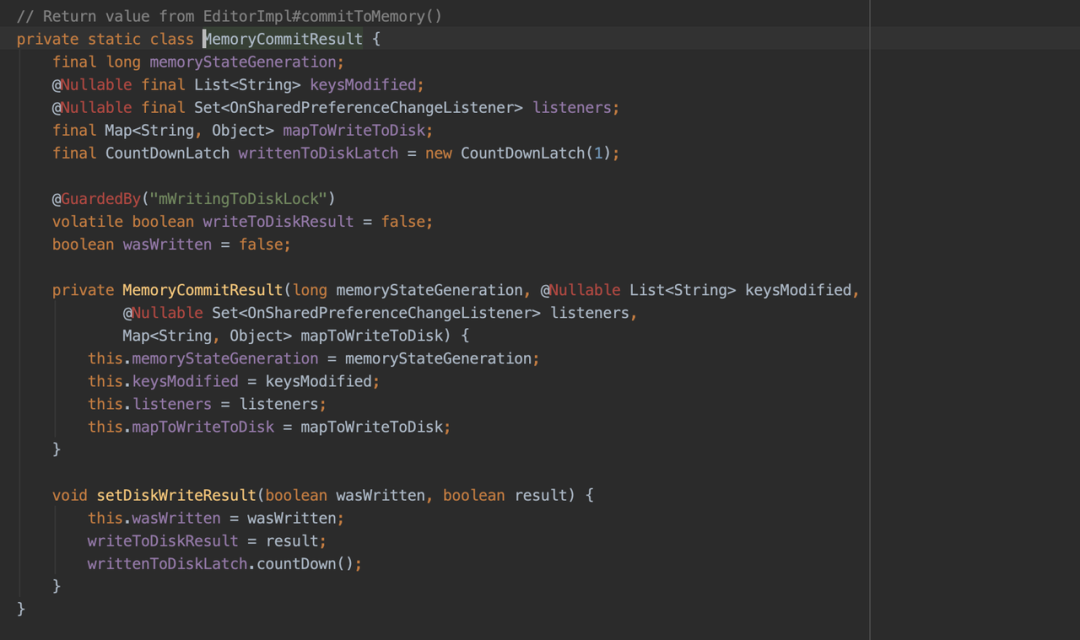

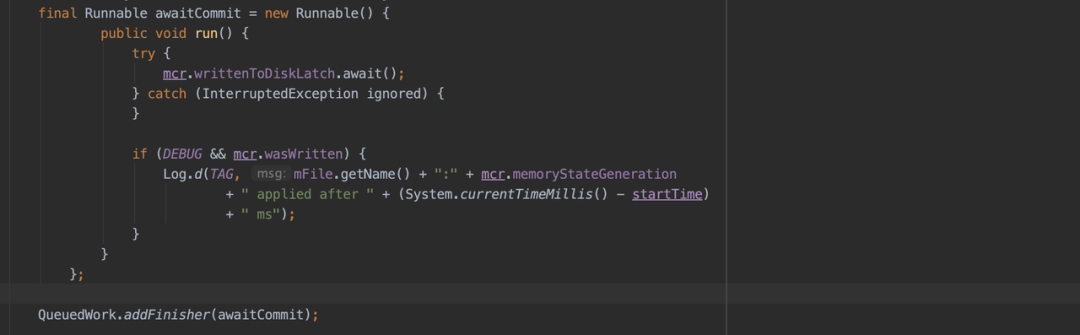
尽管 Google 官方在 Android 8.0 及以后版本对 sp 写入逻辑进行优化,期望是在上述步骤 6 中 UI 线程不是傻傻的等,而是帮助子线程一起写入,但是由于是保守协助,并没有很好的解决这个问题。
解决方案
问题一:针对加载很慢的问题,一般使用的比较多的是采用预加载的方式来触发到这个 sp 文件的加载和解析,这样在真正使用的时候大概率 sp 已经加载解析完毕了;真正需要处理的是核心场景的 sp 一定不能太大,Google 官方的声明还是有必要遵守一下,轻量级的数据持久化存储方式,不要存太多数据,避免文件过大,导致前期的加载解析耗时过久。
问题二:至于 Google 为什么要这么设计,提出了自己的几个猜想:
- Google 希望做到数据可能尽可能及时的写入文件,但是这样等待没有任何意义,主线程直接等待并不会提升写入的效率;
- 期望 sp 实时写入文件,以方便跨进程的时候可以实时的访问到 sp 内的文件,这种异步写入方式本身就没办法确保实时性;
- 可能是在组件发生状态切换的时候,这个时候如果进程内没有啥组件,进程的优先级可能降低,存在进程会在系统资源吃紧的时候被系统干掉,这种概率极低,几乎可以忽略不计;
- 感觉最大的可能性就是 Google 官方当时是为了从 commit 无缝的切换到 apply,依然模拟原来的 commit 行为,只是将原来的每次写入文件一次改成多次 commit 行为最后一次性 apply 在主线程等待所有的写入行为一次性全部写入。
通过以上假设,发现这里的主线程等待子线程写入根本没有什么意义,因此希望可以通过一些必要的手段跳过这种无用的等待行为,在研究了所有的 SharedPreference 相关的逻辑后找到以下入手点。以下是 8.0 以下版本的优化策略,8.0 及以上版本处理方式类似:

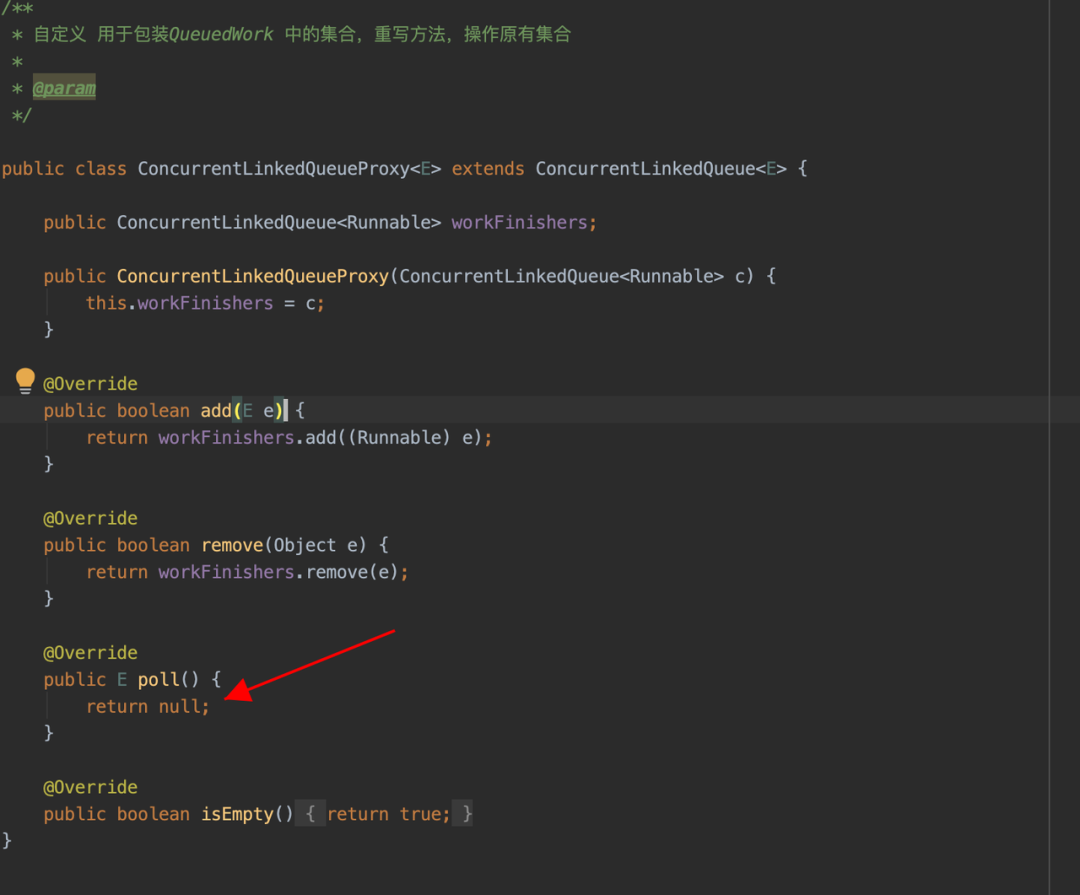
方案收益
通过在字节系多个产品的验证,方案稳定有效,相应堆栈导致的 ANR 问题消灭殆尽,ANR 收益明显,相应的界面跳转等场景流畅性得到了明显的改善。
展望
Google 新增加了一个新 Jetpack 的成员 DataStore,主要用来替换 SharedPreferences, DataStore 应该是开发者期待已久的库,DataStore 是基于 Flow 实现的,一种新的数据存储方案。详细介绍网上有很多参考资料。
优化实践更多参考
- [今日头条 ANR 优化实践系列(1)-设计原理及影响因素]
- [今日头条 ANR 优化实践系列(2)-监控工具与分析思路]
- [今日头条 ANR 优化实践系列(3)-实例剖析集锦]
- [今日头条 ANR 优化实践系列(4)- Barrier 导致主线程假死]