了解 HTTP/1.x 的 keep-alive 吗?它与 HTTP/2 多路复用的区别是什么?
引言
本文分为以下三部分循序渐进走进 HTTP/1.x 的 keep-alive 与 HTTP/2 多路复用:
- HTTP/1.x keep-alive 是什么
- HTTP/2 多路复用
- HTTP/1.x keep-alive 与 HTTP/2 多路复用区别
下面正式开始吧
HTTP/1.x keep-alive 是什么
在[一文走进 TCP 与 HTTP 中] ,我们介绍过,HTTP 协议是建立在 TCP 协议上的应用层协议, HTTP 协议最初是一个非常简单的协议,通信方式也是采取简答的请求-应答的模式,即:客户端与服务器端的的每次请求都需要创建 TCP 连接,服务器响应后断开 TCP 连接,再请求再创建断开。
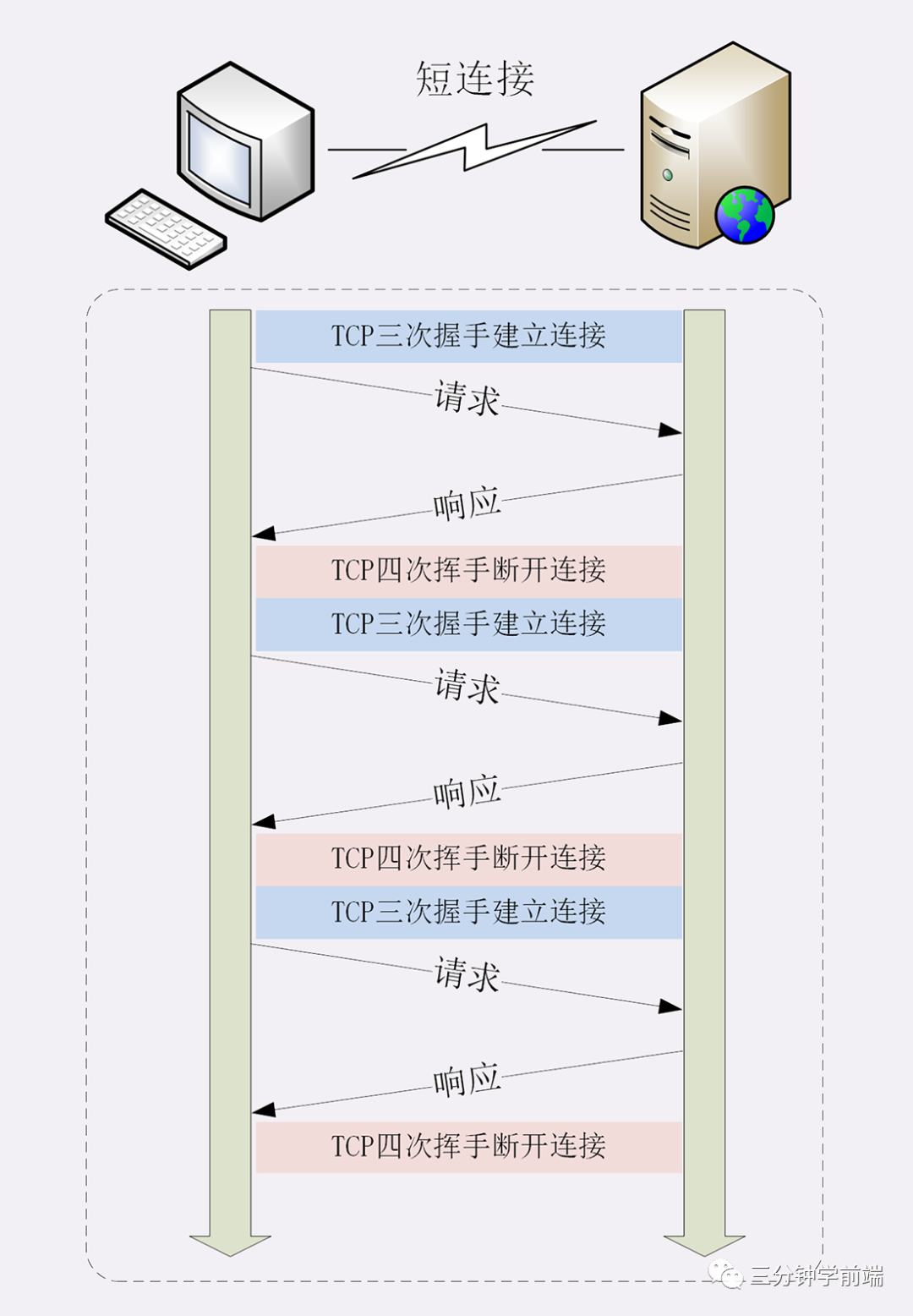
TCP连接的新建成本很高,因为客户端和服务器建立连接时需要“三次握手”,发送 3 个数据包,需要 1 个 RTT;关闭连接是“四次挥手”,4 个数据包需要 2 个 RTT,并且开始时发送速率较慢(slow start),随着网页加载的外部资源越来越多,这个问题就愈发突出了
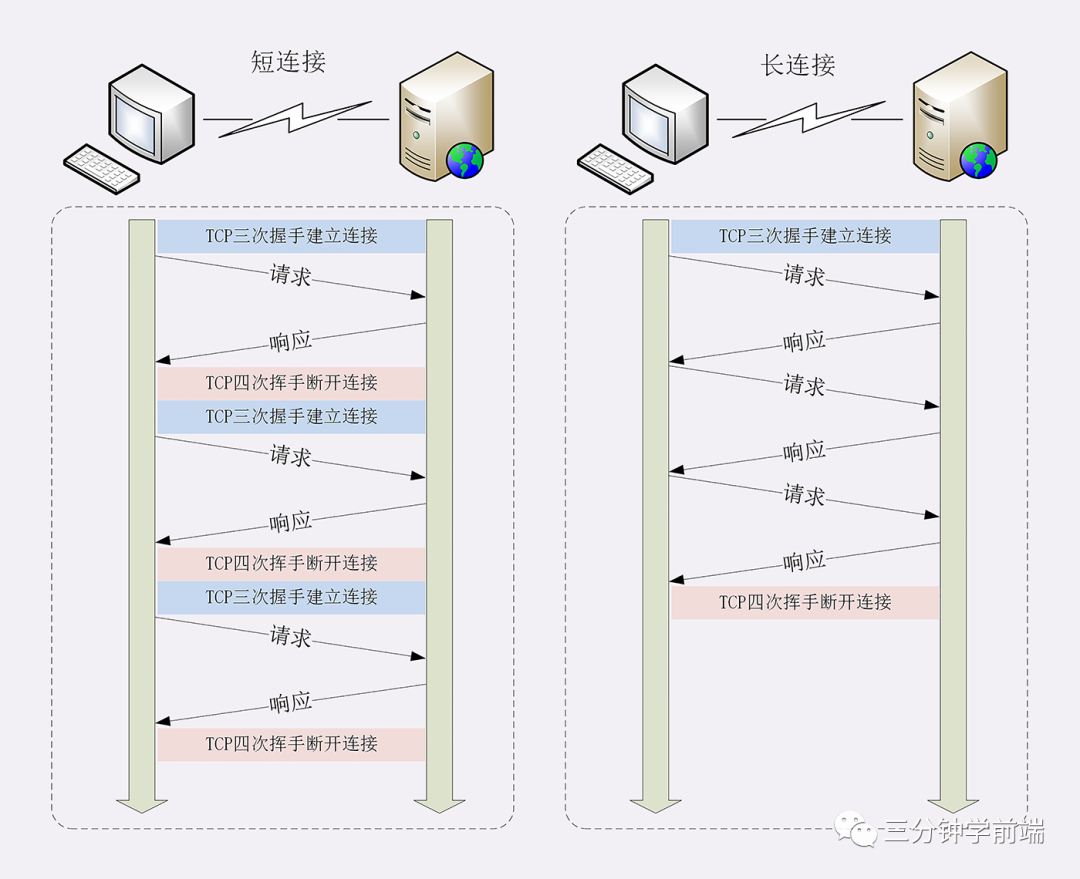
所以 HTTP/1.0 引入了 keep-alive 长连接,HTTP/1.0 中是默认关闭的,可以通过 Connection: keep-alive; 开启 ,HTTP/1.1 默认是开启的,无论加没加 Connection: keep-alive;
所谓长连接,即在 HTTP 请求建立 TCP 连接时,请求结束,TCP 连接不断开,继续保持一段时间(timeout),在这段时间内,同一客户端向服务器发送请求都会复用该 TCP 连接,并重置 timeout 时间计数器,在接下来 timeout 时间内还可以继续复用 TCP 。这样无疑省略了反复创建和销毁 TCP 连接的损耗。
timeout 时间到了之后,TCP会立即断开连接吗?
若两小时(timeout)没有收到客户的数据,服务器就发送一个探测报文段,以后则每隔 75 秒发送一次。若一连发送 10 个探测报文段后仍无客户的响应,服务器就认为客户端出了故障,接着就关闭这个连接。
——摘自谢希仁《计算机网络》
HTTP/2 多路复用
为什么 HTTP/2 引入多路复用?
这是因为:
- HTTP/1.x 虽然引入了 keep-alive 长连接,但它每次请求必须等待上一次响应之后才能发起,
- 所以,在 HTTP/1.1 中提出了管道机制(默认不开启),下一次的请求不需要等待上一个响应来之后再发送,但这要求服务端必须按照请求发送的顺序返回响应,当顺序请求多个文件时,其中一个请求因为某种原因被阻塞时,在后面排队的所有请求也一并被阻塞,这就是队头阻塞 (Head-Of-Line Blocking)
- 人们采取了很多方法去解决,例如使用多个域名、引入雪碧图、将小图内联等,但都没有从根本上解决问题
HTTP/2 是怎么做的喃?
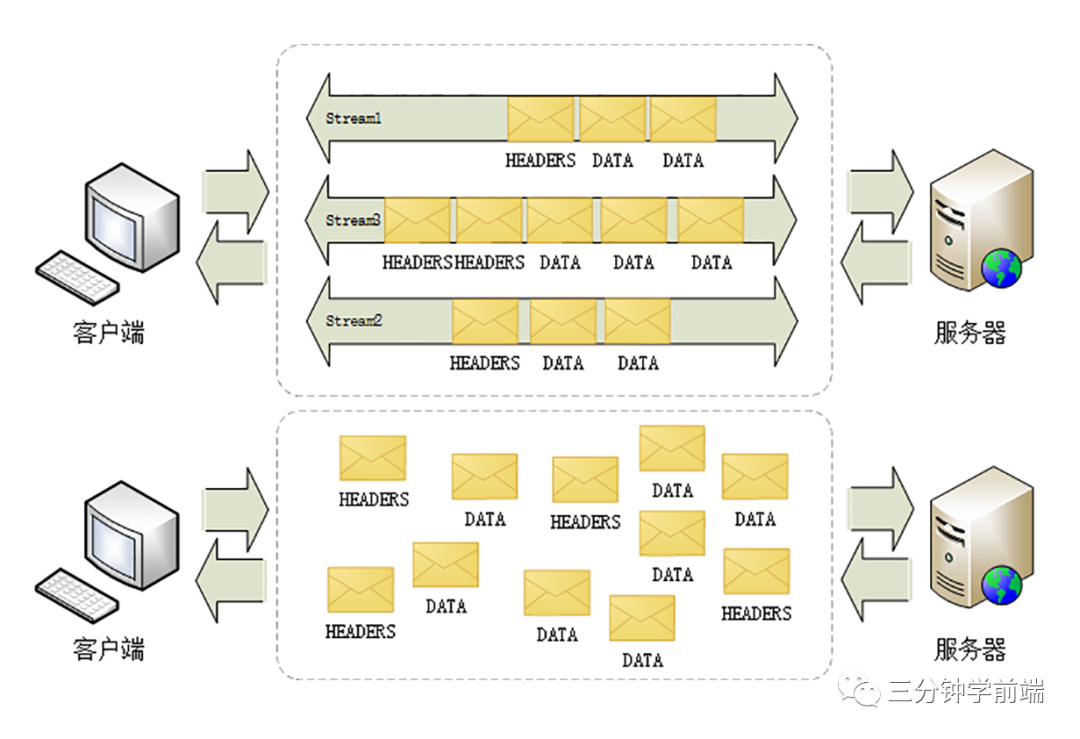
- 首先它引入了 帧(frame)和流(stream),因为 HTTP/1.x 是基于文本的,因为是文本,就导致了它必须是个整体,在传输是不可切割的,只能整体去传
- 既然,HTTP/2 是基于二进制流的,它就可以把 HTTP 消息分解为独立的帧,交错发送,然后在另一端通过帧中的标识重新组装,这就是多路复用
- 这就实现了在同一个TCP连接中,同一时刻可以发送多个请求和响应,且不用按照顺序一一对应,即使某个请求任务耗时严重,也不会影响到其它连接的正常执行
HTTP/1.x keep-alive 与 HTTP/2 多路复用区别
总结一下,HTTP/1.x keep-alive 与 HTTP/2 多路复用区别:
- HTTP/1.x 是基于文本的,只能整体去传;HTTP/2 是基于二进制流的,可以分解为独立的帧,交错发送
- HTTP/1.x keep-alive 必须按照请求发送的顺序返回响应;HTTP/2 多路复用不按序响应
- HTTP/1.x keep-alive 为了解决队头阻塞,将同一个页面的资源分散到不同域名下,开启了多个 TCP 连接;HTTP/2 同域名下所有通信都在单个连接上完成
- HTTP/1.x keep-alive 单个 TCP 连接在同一时刻只能处理一个请求(两个请求的生命周期不能重叠);HTTP/2 单个 TCP 同一时刻可以发送多个请求和响应