关于Dubbo随便问八个问题
1、RPC
1.1 RPC 定义
互联网公司的系统有成千上万个大大小小的服务组成,服务各自部署在不同的机器上,服务间的调用需要用到网络通信,服务消费方每调用一个服务都要写一坨网络通信相关的代码,不仅复杂而且极易出错。还要考虑新服务依赖老服务时如何调用老服务,别的服务依赖新服务的时候新服务如何发布方便他人调用。如何解决这个问题呢?业界一般采用RPC远程调用的方式来实现。
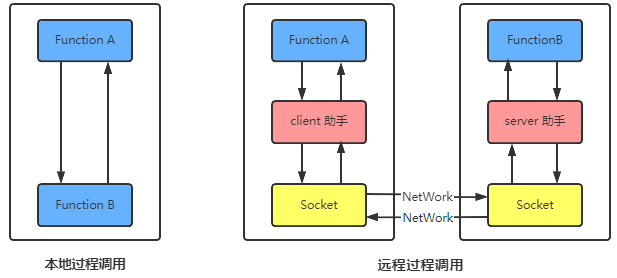
RPC:
Remote Procedure Call Protocol 既 远程过程调用,一种能让我们像调用本地服务一样调用远程服务,可以让调用者对网络通信这些细节无感知,比如服务消费方在执行 helloWorldService.sayHello("sowhat") 时,实质上调用的是远端的服务。这种方式其实就是RPC,RPC思想在各大互联网公司中被广泛使用,如阿里巴巴的dubbo、当当的Dubbox 、Facebook 的 thrift、Google 的grpc、Twitter的finagle等。
1.2 RPC demo
说了那么多,还是实现一个简易版的RPC demo吧。
1.2.1 公共接口
public interface SoWhatService {
String sayHello(String name);
} 1.2.2 服务提供者
接口类实现
public class SoWhatServiceImpl implements SoWhatService
{
@Override
public String sayHello(String name)
{
return "你好啊 " + name;
}
} 服务注册对外提供者
/**
* 服务注册对外提供者
*/
public class ServiceFramework
{
public static void export(Object service, int port) throws Exception
{
ServerSocket server = new ServerSocket(port);
while (true)
{
Socket socket = server.accept();
new Thread(() ->
{
try
{
//反序列化
ObjectInputStream input = new ObjectInputStream(socket.getInputStream());
//读取方法名
String methodName =(String) input.readObject();
//参数类型
Class<?>[] parameterTypes = (Class<?>[]) input.readObject();
//参数
Object[] arguments = (Object[]) input.readObject();
//找到方法
Method method = service.getClass().getMethod(methodName, parameterTypes);
//调用方法
Object result = method.invoke(service, arguments);
// 返回结果
ObjectOutputStream output = new ObjectOutputStream(socket.getOutputStream());
output.writeObject(result);
} catch (Exception e)
{
e.printStackTrace();
}
}).start();
}
}
}服务运行
public class ServerMain
{
public static void main(String[] args)
{
//服务提供者 暴露出接口
SoWhatService service = new SoWhatServiceImpl();
try
{
ServiceFramework.export(service, 1412);
} catch (Exception e)
{
e.printStackTrace();
}
}
}1.2.3 服务调用者
动态代理调用远程服务
/**
* @author sowhat
* 动态代理调用远程服务
*/
public class RpcFunction
{
public static <T> T refer(Class<T> interfaceClass, String host, int port) throws Exception
{
return (T) Proxy.newProxyInstance(interfaceClass.getClassLoader(), new Class<?>[]{interfaceClass},
new InvocationHandler()
{
@Override
public Object invoke(Object proxy, Method method, Object[] arguments) throws Throwable
{
//指定 provider 的 ip 和端口
Socket socket = new Socket(host, port);
ObjectOutputStream output = new ObjectOutputStream(socket.getOutputStream());
//传方法名
output.writeObject(method.getName());
//传参数类型
output.writeObject(method.getParameterTypes());
//传参数值
output.writeObject(arguments);
ObjectInputStream input = new ObjectInputStream(socket.getInputStream());
//读取结果
Object result = input.readObject();
return result;
}
});
}
}调用方法
public class RunMain
{
public static void main(String[] args)
{
try
{
//服务调用者 需要设置依赖
SoWhatService service = RpcFunction.refer(SoWhatService.class, "127.0.0.1", 1412);
System.out.println(service.sayHello(" sowhat1412"));
} catch (Exception e)
{
e.printStackTrace();
}
}
}2、Dubbo 框架设计
2.1 Dubbo 简介
Dubbo 是阿里巴巴研发开源工具,主要分为2.6.x 跟 2.7.x 版本。是一款分布式、高性能、透明化的 RPC 服务框架,提供服务自动注册、自动发现等高效服务治理方案,可以和Spring 框架无缝集成,它提供了6大核心能力:
1. 面向接口代理的高性能RPC调用
2. 智能容错和负载均衡
3. 服务自动注册和发现
4. 高度可扩展能力
5. 运行期流量调度
6. 可视化的服务治理与运维
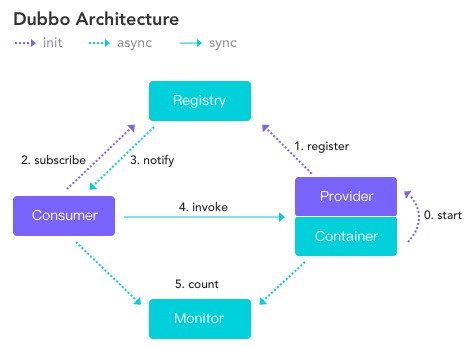
- 服务提供者 Provider 启动然后向 Registry 注册自己所能提供的服务。
- 服务消费者 Consumer 向Registry订阅所需服务,Consumer 解析Registry提供的元信息,从服务中通过负载均衡选择 Provider调用。
- 服务提供方 Provider 元数据变更的话Registry会把变更推送给Consumer,以此保证Consumer获得最新可用信息。
注意点:
- Provider 跟 Consumer 在内存中记录调用次数跟时间,定时发送统计数据到Monitor,发送的时候是短连接。
- Monitor 跟 Registry 是可选的,可直接在配置文件中写好,Provider 跟 Consumer进行直连。
- Monitor 跟 Registry 挂了也没事, Consumer 本地缓存了 Provider 信息。
- Consumer 直接调用 Provider 不会经过 Registry。Provider、Consumer这俩到 Registry之间是长连接。
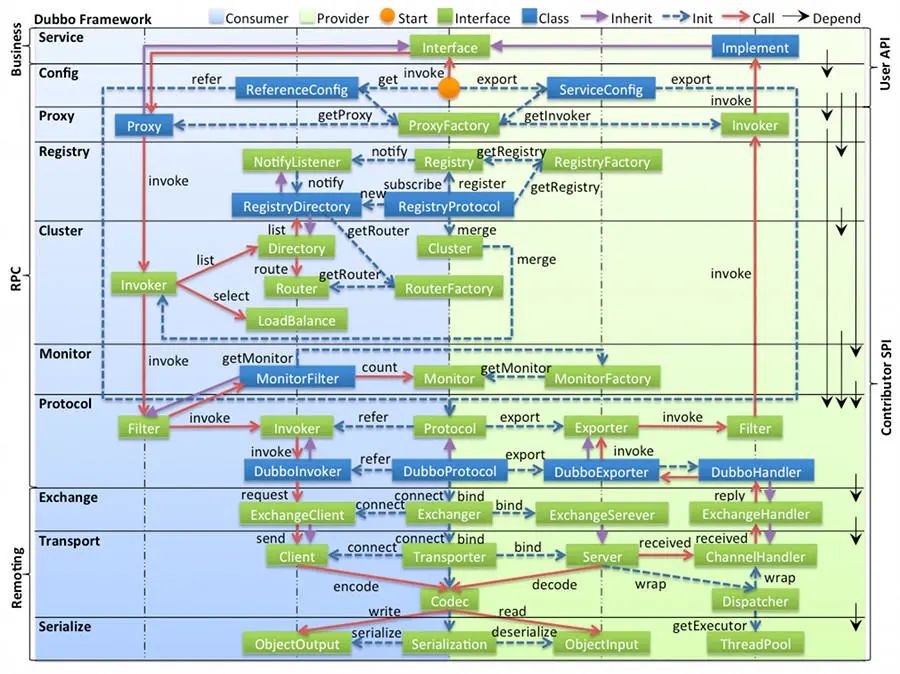
2.2 Dubbo框架分层

- Busines层:由用户自己来提供接口和实现还有一些配置信息。
- RPC层:真正的RPC调用的核心层,封装整个RPC的调用过程、负载均衡、集群容错、代理。
- Remoting层:对网络传输协议和数据转换的封装。
如果每一层再细分下去,一共有十层。
- 接口服务层(Service):该层与业务逻辑相关,根据 provider 和 consumer 的业务设计对应的接口和实现。
- 配置层(Config):对外配置接口,以 ServiceConfig 和 ReferenceConfig 为中心初始化配置。
- 服务代理层(Proxy):服务接口透明代理,Provider跟Consumer都生成代理类,使得服务接口透明,代理层实现服务调用跟结果返回。
- 服务注册层(Registry):封装服务地址的注册和发现,以服务 URL 为中心。
- 路由层(Cluster):封装多个提供者的路由和负载均衡,并桥接注册中心,以Invoker 为中心,扩展接口为 Cluster、Directory、Router 和 LoadBlancce。
- 监控层(Monitor):RPC 调用次数和调用时间监控,以 Statistics 为中心,扩展接口为 MonitorFactory、Monitor 和 MonitorService。
- 远程调用层(Protocal):封装 RPC 调用,以 Invocation 和 Result 为中心,扩展接口为 Protocal、Invoker 和 Exporter。
- 信息交换层(Exchange):封装请求响应模式,同步转异步。以 Request 和Response 为中心,扩展接口为 Exchanger、ExchangeChannel、ExchangeClient 和 ExchangeServer。
- 网络传输层(Transport):抽象 mina 和 netty 为统一接口,以 Message 为中心,扩展接口为 Channel、Transporter、Client、Server 和 Codec。
- 数据序列化层(Serialize):可复用的一些工具,扩展接口为 Serialization、ObjectInput、ObjectOutput 和 ThreadPool。
他们之间的调用关系直接看下面官网图即可。
3、Dubbo SPI 机制
Dubbo 采用 微内核设计 + SPI 扩展技术来搭好核心框架,同时满足用户定制化需求。这里重点说下SPI。
3.1 微内核
操作系统层面的微内核跟宏内核:
- 微内核Microkernel:是一种内核的设计架构,由尽可能精简的程序所组成,以实现一个操作系统所需要的最基本功能,包括了底层的寻址空间管理、线程管理、与进程间通信。成功案例是QNX系统,比如黑莓手机跟车用市场。
- 宏内核Monolithic :把 进程管理、内存管理、文件系统、进程通信等功能全部作为内核来实现,而微内核则仅保留最基础的功能,Linux 就是宏内核架构设计。
Dubbo中的广义微内核:
- 思想是 核心系统 + 插件,说白了就是把不变的功能抽象出来称为核心,把变动的功能作为插件来扩展,符合开闭原则,更容易扩展、维护。比如小霸王游戏机中机体本身作为核心系统,游戏片就是插件。vscode、Idea、chrome等都是微内核的产物。
- 微内核架构其实是一直架构思想,可以是框架层面也可以是某个模块设计,它的本质就是将变化的部分抽象成插件,使得可以快速简便地满足各种需求又不影响整体的稳定性。
3.2 SPI 含义
主流的数据库有MySQL、Oracle、DB2等,这些数据库是不同公司开发的,它们的底层协议不大一样,那怎么约束呢?一般就是定制统一接口,具体实现不管,反正面向相同的接口编程即可。等到真正使用的时候用具体的实现类就好,问题是哪里找用那个实现类呢?这时候就采用约定好的法则将实现类写到指定位置即可。
SPI 全称为 Service Provider Interface,是一种服务发现机制。它约定在ClassPath路径下的META-INF/services文件夹查找文件,自动加载文件里所定义的类。
3.3 SPI demo
接口:
package com.example.demo.spi;
public interface SPIService {
void execute();
}实现类1:
public class SpiImpl1 implements SPIService{
@Override
public void execute() {
System.out.println("SpiImpl1.execute()");
}
}实现类2:
public class SpiImpl2 implements SPIService{
@Override
public void execute() {
System.out.println("SpiImpl2.execute()");
}
}配置路径
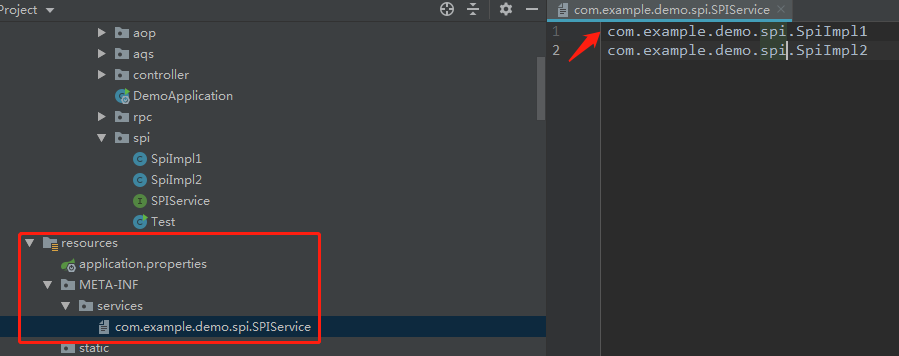
调用加载类
package com.example.demo.spi;
import sun.misc.Service;
import java.util.Iterator;
import java.util.ServiceLoader;
public class Test {
public static void main(String[] args) {
Iterator<SPIService> providers = Service.providers(SPIService.class);
ServiceLoader<SPIService> load = ServiceLoader.load(SPIService.class);
while(providers.hasNext()) {
SPIService ser = providers.next();
ser.execute();
}
System.out.println("--------------------------------");
Iterator<SPIService> iterator = load.iterator();
while(iterator.hasNext()) {
SPIService ser = iterator.next();
ser.execute();
}
}
}3.4 SPI源码追踪
ServiceLoader.load(SPIService.class) 底层调用大致逻辑如下:
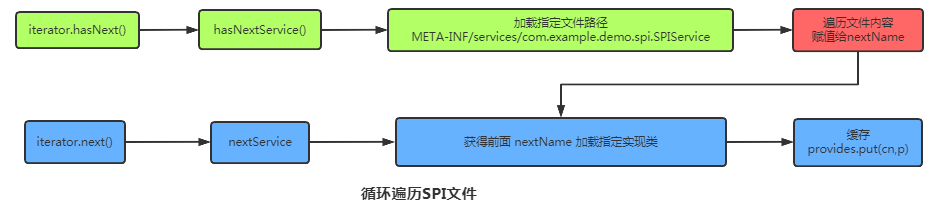
3.5 Java SPI缺点
- 不能按需加载,Java SPI在加载扩展点的时候,会一次性加载所有可用的扩展点,很多是不需要的,会浪费系统资源。
- 获取某个实现类的方式不够灵活,只能通过 Iterator 形式获取,不能根据某个参数来获取对应的实现类。
- 不支持AOP与依赖注入,JAVA SPI可能会丢失加载扩展点异常信息,导致追踪问题很困难。
3.6 Dubbo SPI
JDK自带的不好用Dubbo 就自己实现了一个 SPI,该SPI 可以通过名字实例化指定的实现类,并且实现了 IOC 、AOP 与 自适应扩展 SPI 。
key = com.sowhat.value
Dubbo 对配置文件目录的约定,不同于 Java SPI ,Dubbo 分为了三类目录。
- META-INF/services/ :该目录下 SPI 配置文件是为了用来兼容 Java SPI 。
- META-INF/dubbo/ :该目录存放用户自定义的 SPI 配置文件。
- META-INF/dubbo/internal/ :该目录存 Dubbo 内部使用的 SPI 配置文件。
使用的话很简单 引入依赖,然后百度教程即可。
@Test
void sowhat()
{
ExtensionLoader<SPIService> spiService = ExtensionLoader.getExtensionLoader(SPIService.class); //按需获取实现类对象
SPIService demo1 = spiService.getExtension("SpiImpl1");
demo1.execute();
}3.7 Dubbo SPI源码追踪
ExtensionLoader.getExtension 方法的整个思路是 查找缓存是否存在,不存在则读取SPI文件,通过反射创建类,然后设置依赖注入这些东西,有包装类就包装下,执行流程如下图所示:
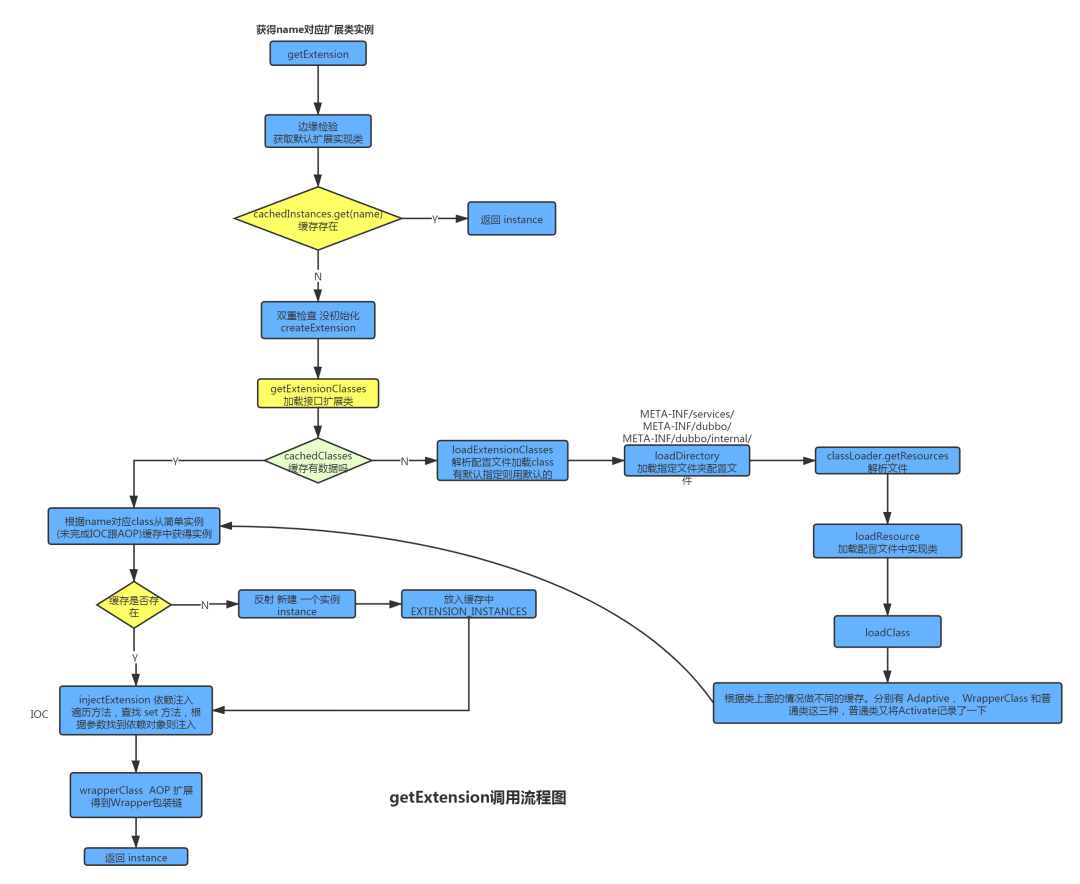
说下重要的四个部分:
1 . injectExtension IOC
查找 set 方法,根据参数找到依赖对象则注入。
2 . WrapperClass AOP
包装类,Dubbo 帮你自动包装,只需要某个扩展类的构造函数只有一个参数,并且是扩展接口类型,就会被判定为包装类。
3 . Activate
Active 有三个属性,group 表示修饰在哪个端,是 provider 还是 consumer,value 表示在 URL参数中出现才会被激活,order 表示实现类的顺序。
3.8 Adaptive 自适应扩展
需求:根据配置来进行 SPI 扩展的加载后不想在启动的时候让扩展被加载,想根据请求时候的参数来动态选择对应的扩展。实现:Dubbo用代理机制实现了自适应扩展,为用户想扩展的接口 通过JDK 或者 Javassist 编译生成一个代理类,然后通过反射创建实例。实例会根据本来方法的请求参数得知需要的扩展类,然后通过 ExtensionLoader.getExtensionLoader(type.class).getExtension(name)来获取真正的实例来调用,看个官网样例。
public interface WheelMaker {
Wheel makeWheel(URL url);
}
// WheelMaker 接口的自适应实现类
public class AdaptiveWheelMaker implements WheelMaker {
public Wheel makeWheel(URL url) {
if (url == null) {
throw new IllegalArgumentException("url == null");
}
// 1. 调用 url 的 getXXX 方法获取参数值
String wheelMakerName = url.getParameter("Wheel.maker");
if (wheelMakerName == null) {
throw new IllegalArgumentException("wheelMakerName == null");
}
// 2. 调用 ExtensionLoader 的 getExtensionLoader 获取加载器
// 3. 调用 ExtensionLoader 的 getExtension 根据从url获取的参数作为类名称加载实现类
WheelMaker wheelMaker = ExtensionLoader.getExtensionLoader(WheelMaker.class).getExtension(wheelMakerName);
// 4. 调用实现类的具体方法实现调用。
return wheelMaker.makeWheel(URL url);
}
}查看Adaptive注解源码可知该注解可用在类或方法上,Adaptive 注解在类上或者方法上有不同的实现逻辑。
7.8.1 Adaptive 注解在类上
Adaptive 注解在类上时,Dubbo 不会为该类生成代理类,Adaptive 注解在类上的情况很少,在 Dubbo 中,仅有两个类被 Adaptive 注解了,分别是 AdaptiveCompiler 和 AdaptiveExtensionFactory,表示拓展的加载逻辑由人工编码完成,这不是我们关注的重点。
7.8.2 Adaptive 注解在方法上
Adaptive 注解在方法上时,Dubbo 则会为该方法生成代理逻辑,表示拓展的加载逻辑需由框架自动生成,大致的实现机制如下:
- 加载标注有 @Adaptive 注解的接口,如果不存在,则不支持 Adaptive 机制;
- 为目标接口按照一定的模板生成子类代码,并且编译生成的代码,然后通过反射生成该类的对象;
- 结合生成的对象实例,通过传入的URL对象,获取指定key的配置,然后加载该key对应的类对象,最终将调用委托给该类对象进行。
@SPI("apple")
public interface FruitGranter {
Fruit grant();
@Adaptive
String watering(URL url);
}
---
// 苹果种植者
public class AppleGranter implements FruitGranter {
@Override
public Fruit grant() {
return new Apple();
}
@Override
public String watering(URL url) {
System.out.println("watering apple");
return "watering finished";
}
}
---
// 香蕉种植者
public class BananaGranter implements FruitGranter {
@Override
public Fruit grant() {
return new Banana();
}
@Override
public String watering(URL url) {
System.out.println("watering banana");
return "watering success";
}
}调用方法实现:
public class ExtensionLoaderTest {
@Test
public void testGetExtensionLoader() {
// 首先创建一个模拟用的URL对象
URL url = URL.valueOf("dubbo://192.168.0.1:1412?fruit.granter=apple");
// 通过ExtensionLoader获取一个FruitGranter对象
FruitGranter granter = ExtensionLoader.getExtensionLoader(FruitGranter.class)
.getAdaptiveExtension();
// 使用该FruitGranter调用其"自适应标注的"方法,获取调用结果
String result = granter.watering(url);
System.out.println(result);
}
}通过如上方式生成一个内部类。大致调用流程如下:

4、Dubbo 服务暴露流程
4.1 服务暴露总览
Dubbo框架是以URL为总线的模式,运行过程中所有的状态数据信息都可以通过URL来获取,比如当前系统采用什么序列化,采用什么通信,采用什么负载均衡等信息,都是通过URL的参数来呈现的,所以在框架运行过程中,运行到某个阶段需要相应的数据,都可以通过对应的Key从URL的参数列表中获取。URL 具体的参数如下:
protocol:指的是 dubbo 中的各种协议,如:dubbo thrift http username/password:用户名/密码 host/port:主机/端口 path:接口的名称 parameters:参数键值对
protocol://username:password@host:port/path?k=v
服务暴露从代码流程看分为三部分:
- 检查配置,最终组装成 URL。
- 暴露服务到到本地服务跟远程服务。
- 服务注册至注册中心。
服务暴露从对象构建转换看分为两步:
- 将服务封装成Invoker。
- 将Invoker通过协议转换为Exporter。
4.2 服务暴露源码追踪
- 容器启动,Spring IOC 刷新完毕后调用 onApplicationEvent 开启服务暴露,ServiceBean 。
- export 跟 doExport 来进行拼接构建URL,为屏蔽调用的细节,统一暴露出一个可执行体,通过ProxyFactory 获取到 invoker。
- 调用具体 Protocol 将把包装后的 invoker 转换成 exporter,此处用到了SPI。
- 然后启动服务器server,监听端口,使用NettyServer创建监听服务器。
- 通过 RegistryProtocol 将URL注册到注册中心,使得consumer可获得provider信息。

5、Dubbo 服务引用流程
Dubbo中一个可执行体就是一个invoker,所以 provider 跟 consumer 都要向 invoker 靠拢。通过上面demo可知为了无感调用远程接口,底层需要有个代理类包装 invoker。
服务的引入时机有两种:
1 . 饿汉式:
通过实现 Spring 的 InitializingBean 接口中的 afterPropertiesSet 方法,容器通过调用 ReferenceBean的 afterPropertiesSet 方法时引入服务。
2 . 懒汉式(默认):
懒汉式是只有当服务被注入到其他类中时启动引入流程。
服务引用的三种方式:
- 本地引入:服务暴露时本地暴露,避免网络调用开销。
- 直接连接引入远程服务:不启动注册中心,直接写死远程Provider地址 进行直连。
- 通过注册中心引入远程服务:通过注册中心抉择如何进行负载均衡调用远程服务。
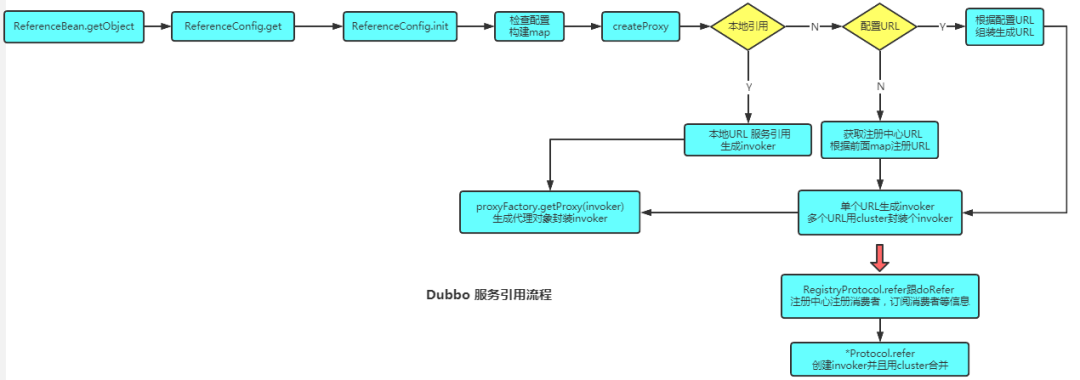
服务引用流程:
- 检查配置构建map ,map 构建 URL ,通过URL上的协议利用自适应扩展机制调用对应的 protocol.refer 得到相应的 invoker ,此处
- 想注册中心注册自己,然后订阅注册中心相关信息,得到provider的 ip 等信息,再通过共享的netty客户端进行连接。
- 当有多个 URL 时,先遍历构建出 invoker 然后再由 StaticDirectory 封装一下,然后通过 cluster 进行合并,只暴露出一个 invoker 。
- 然后再构建代理,封装 invoker 返回服务引用,之后 Comsumer 调用的就是这个代理类。
- oneway:不关心请求是否发送成功。
- Async异步调用:Dubbo天然异步,客户端调用请求后将返回的 ResponseFuture 存到上下文中,用户可随时调用 future.get 获取结果。异步调用通过唯一ID 标识此次请求。
- Sync同步调用:在 Dubbo 源码中就调用了 future.get,用户感觉方法被阻塞了,必须等结果后才返回。
6、Dubbo 调用整体流程
调用之前你可能需要考虑这些事:
- consumer 跟 provider 约定好通讯协议,dubbo支持多种协议,比如dubbo、rmi、hessian、http、webservice等。默认走dubbo协议,连接属于单一长连接,NIO异步通信。适用传输数据量很小(单次请求在100kb以内),但是并发量很高。
- 约定序列化模式,大致分为两大类,一种是字符型(XML或json 人可看懂 但传输效率低),一种是二进制流(数据紧凑,机器友好)。默认使用 hessian2作为序列化协议。
- consumer 调用 provider 时提供对应接口、方法名、参数类型、参数值、版本号。
- provider列表对外提供服务涉及到负载均衡选择一个provider提供服务。
- consumer 跟 provider 定时向monitor 发送信息。
调用大致流程:
- 客户端发起请求来调用接口,接口调用生成的代理类。代理类生成RpcInvocation 然后调用invoke方法。
- ClusterInvoker获得注册中心中服务列表,通过负载均衡给出一个可用的invoker。
- 序列化跟反序列化网络传输数据。通过NettyServer调用网络服务。
- 服务端业务线程池接受解析数据,从exportMap找到invoker进行invoke。
- 调用真正的Impl得到结果然后返回。

- oneway:不关心请求是否发送成功,消耗最小。
- sync同步调用:在 Dubbo 源码中就调用了 future.get,用户感觉方法被阻塞了,必须等结果后才返回。
- Async 异步调用:Dubbo天然异步,客户端调用请求后将返回的 ResponseFuture 存到上下文中,用户可以随时调用future.get获取结果。异步调用通过唯一ID标识此次请求。
7、Dubbo集群容错负载均衡
Dubbo 引入了Cluster、Directory、Router、LoadBalance、Invoker模块来保证Dubbo系统的稳健性,它们的关系如下图:
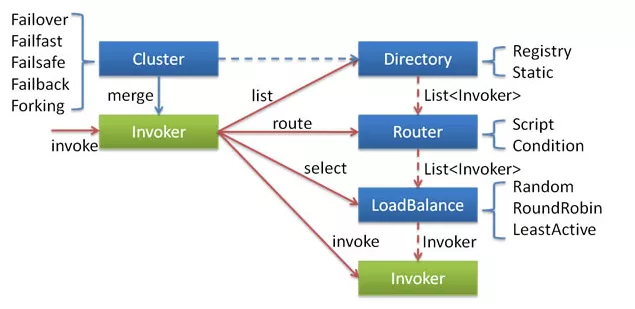
- 服务发现时会将多个多个远程调用放入Directory,然后通过Cluster封装成一个Invoker,该invoker提供容错功能。
- 消费者代用的时候从Directory中通过负载均衡获得一个可用invoker,最后发起调用。
- 你可以认为Dubbo中的Cluster对上面进行了大的封装,自带各种鲁棒性功能。
7.1 集群容错
集群容错是在消费者端通过Cluster子类实现的,Cluster接口有10个实现类,每个Cluster实现类都会创建一个对应的ClusterInvoker对象。核心思想是让用户选择性调用这个Cluster中间层,屏蔽后面具体实现细节。
| Cluster | Cluster Invoker | 作用 |
|---|---|---|
| FailoverCluster | FailoverClusterInvoker | 失败自动切换功能,默认 |
| FailfastCluster | FailfastClusterInvoker | 一次调用,失败异常 |
| FailsafeCluster | FailsafeClusterInvoker | 调用出错则日志记录 |
| FailbackCluster | FailbackClusterInvoker | 失败返空,定时重试2次 |
| ForkingCluster | ForkingClusterInvoker | 一个任务并发调用,一个OK则OK |
| BroadcastCluster | BroadcastClusterInvoker | 逐个调用invoker,全可用才可用 |
| AvailableCluster | AvailableClusterInvoker | 哪个能用就用那个 |
| MergeableCluster | MergeableClusterInvoker | 按组合并返回结果 |
7.2 智能容错之负载均衡
Dubbo中一般有4种负载均衡策略。
- RandomLoadBalance:加权随机,它的算法思想简单。假设有一组服务器 servers = [A, B, C],对应权重为 weights = [5, 3, 2],权重总和为10。现把这些权重值平铺在一维坐标值上,[0, 5) 区间属于服务器 A,[5, 8) 区间属于服务器 B,[8, 10) 区间属于服务器 C。接下来通过随机数生成器生成一个范围在 [0, 10) 之间的随机数,然后计算这个随机数会落到哪个区间上。默认实现。
- LeastActiveLoadBalance:最少活跃数负载均衡,选择现在活跃调用数最少的提供者进行调用,活跃的调用数少说明它现在很轻松,而且活跃数都是从 0 加起来的,来一个请求活跃数+1,一个请求处理完成活跃数-1,所以活跃数少也能变相的体现处理的快。
- RoundRobinLoadBalance:加权轮询负载均衡,比如现在有两台服务器 A、B,轮询的调用顺序就是 A、B、A、B,如果加了权重,A 比B 的权重是2:1,那现在的调用顺序就是 A、A、B、A、A、B。
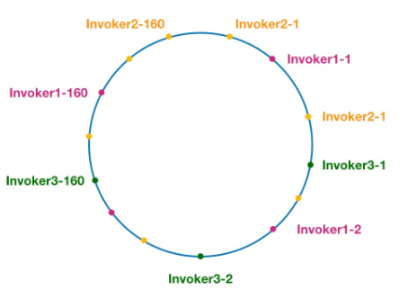
- ConsistentHashLoadBalance:一致性 Hash 负载均衡,将服务器的 IP 等信息生成一个 hash 值,将hash 值投射到圆环上作为一个节点,然后当 key 来查找的时候顺时针查找第一个大于等于这个 key 的 hash 值的节点。一般而言还会引入虚拟节点,使得数据更加的分散,避免数据倾斜压垮某个节点。如下图 Dubbo 默认搞了 160 个虚拟节点。
7.3 智能容错之服务目录
关于 服务目录Directory 你可以理解为是相同服务Invoker的集合,核心是RegistryDirectory类。具有三个功能。
- 从注册中心获得invoker列表。
- 监控着注册中心invoker的变化,invoker的上下线。
- 刷新invokers列表到服务目录。
7.4 智能容错之服务路由
服务路由其实就是路由规则,它规定了服务消费者可以调用哪些服务提供者。条件路由规则由两个条件组成,分别用于对服务消费者和提供者进行匹配。比如有这样一条规则:
host = 10.20.153.14 => host = 10.20.153.12
该条规则表示 IP 为 10.20.153.14 的服务消费者只可调用 IP 为 10.20.153.12 机器上的服务,不可调用其他机器上的服务。条件路由规则的格式如下:
[服务消费者匹配条件] => [服务提供者匹配条件]
如果服务消费者匹配条件为空,表示不对服务消费者进行限制。如果服务提供者匹配条件为空,表示对某些服务消费者禁用服务。
8、设计RPC
通读下Dubbo的大致实现方式后其实就可以依葫芦画瓢了,一个RPC框架大致需要下面这些东西:
- 服务的注册跟发现的搞一个吧,你可以用ZooKeeper或者Redis来实现。
- 接下来consumer发起请求的时候你的面向接口编程啊,用到动态代理来实现调用。
- 多个provider提供相同服务你的用到LoadBalance啊。
- 最终选择一个机器后你的约定好通信协议啊,如何进行序列化跟反序列化呢?
- 底层就用现成的高性能Netty框架 NIO模式实现呗。
- 服务开启后的有monitor啊。
PS :
感觉没啥特别好写的,因为人Dubbo官方文档啥都有,你说你英文看不懂,那中文总该看得懂了吧。
参考
Dubbo面试题:https://sowhat.blog.csdn.net/article/details/71191035 Adaptive讲解:https://blog.csdn.net/weixin_33967071/article/details/92608993 Dubbo视频:https://b23.tv/KVk0xo Dubbo demo:https://mp.weixin.qq.com/s/FPbu8rFOHyTGROIV8XJeTA doExportUrlsFor1Protocol详解:https://www.cnblogs.com/hzhuxin/p/7993860.html