基于 Node.js Addon 和 v8 字节码的 Electron 代码保护解决方案
背景
我们有一个项目使用了 Electron 开发桌面应用,使其能够在 Windows / Mac 两端上跨平台运行,因此核心逻辑都是通过 JavaScript 编写的,黑客非常容易对我们的应用进行解包、修改逻辑破解商业化限制、重新打包,去再分发破解版。
虽然我们已经对应用做了数字签名,但是这还远远不够。要想真正解决问题,除了把所有商业化逻辑做到服务端,我们还需要对代码进行加固,避免解包、篡改、二次打包、二次分发。
方案对比
主流方案
-
Uglify / Obfuscator
-
介绍:通过对 JS 代码进行丑化和混淆,尽可能降低其可读性。
-
特征:
容易解包、容易阅读、容易篡改、容易二次打包 -
优势:接入简单。
-
劣势:代码格式化工具和混淆反解工具都能对代码进行一定程度的复原。丑化通过修改变量名,可能会引起代码无法运行。混淆通过调整代码结构,对代码性能有较大的影响,也可能引起代码无法执行。
-
Native 加解密
-
介绍:将 Webpack 的构建产物 Bundle 通过 XOR 或者 AES 等方案进行加密,封装进 Node Addon,然后在运行时通过 JS 进行解密。
-
特征:
解包有成本、容易阅读、容易篡改、容易二次打包 -
优势:有一定的保护作用,可以阻拦小白。
-
劣势:对于熟悉 Node 和 Electron 的黑客来说,解包非常容易。但是如果应用支持 DevTools,则可以直接通过 DevTools 看到源代码然后再分发。如果应用不支持 DevTools,只要把 Node Addon 拷贝到一个支持 DevTools 的 Electron 下执行,还是能看到源代码。
-
ASAR 加密
-
介绍:将 Electron ASAR 文件进行加密,并修改 Electron 源代码,在读取 ASAR 文件之前对其解密后再运行。
-
特征:
难以解包、容易阅读、容易篡改、容易二次打包 -
优势:有较强的保护作用,可以阻拦不少黑客。
-
劣势:需要重新构建 Electron,初期成本高昂。但是黑客可以通过强制开启 Inspect 端口或者应用内 DevTools 读取到源代码、或者通过 Dump 内存等方式解析出源代码,并且将源代码重新打包分发。
-
v8 字节码
-
介绍:通过 Node 标准库里的 vm 模块,可以从 Script 对象中生成其缓存数据(参考[1])。该缓存数据可以理解为 v8 的字节码,该方案通过分发字节码的形式来达到源代码保护的目的。
-
特征:
容易解包、难以阅读、难以篡改、容易二次打包 -
优势:生成的字节码,不仅几乎不可读,而且难以篡改。且不保存源代码。
-
劣势:对构建流程具有较大侵入性,没有便捷的解决方案。字节码里还是可以读到字符串等数据,可以进行篡改。
方案介绍
关于 v8 字节码
官方的几句话介绍:https://v8.dev/blog/code-caching
扩展阅读:
- bytenode/bytenode[2]
- 理解 V8 的字节码「译」[3]
- 通过字节码保护 Node.js 源码之原理篇[4]
我们可以理解,v8 字节码是 v8 引擎在解析和编译 JavaScript 后产物的序列化形式,它通常用于浏览器内的性能优化。所以如果我们通过 v8 字节码运行代码,不仅能够起到代码保护作用,还对性能有一定的提升。
我们在此不对 v8 字节码作为过多的阐述,可以通过阅读上述两篇文章去了解通过 v8 字节码进行代码保护的技术背景和实现方案。
v8 字节码的局限性
在代码保护上的局限
v8 字节码不保护字符串,如果我们在 JS 代码中写死了一些数据库的密钥等信息,只要将 v8 字节码作为字符串阅读,还是能直接看到这些字符串内容的。当然,简单一点的方法就是使用 Binary 形式的非字符串密钥。
另外,如果直接将上面技术方案中生成的二进制文件进行略微修改,还是可以非常容易地再分发。比如把 isVip 对应的值写死为 true,或者是把自动更新 URL 改成一个虚假的地址来禁用自动更新。为了避免这些情况,我们希望在这一层之上做更多的保护,让破解成本更加高。
对构建的影响
v8 字节码格式的和 v8 版本和环境有关,不同版本或者不同环境的 v8,其字节码产物不一样。Electron 存在两种进程,Browser 进程和 Renderer 进程。两种进程虽然 v8 版本一样,但是由于注入的方法不同,运行环境不同,因此字节码产物也有区别。在 Browser 进程中生成的 v8 字节码不能在 Renderer 进程中运行,反之也不行。当然,在 Node.js 中生成的字节码也是无法在 Electron 上运行的。因此,我们需要在 Browser 进程中构建用于 Browser 进程的代码,在 Renderer 进程中构建用于 Renderer 进程的代码。
对调试的影响以及支持 Sourcemap
由于我们将构造 vm.Script 所使用的代码都替换成了 dummyCode 进行占位,所以对 sourcemap 会有影响,并且 filename 也不再起作用。所以对调试时定位代码存在一定影响。
对代码大小的影响
对于只有几行的 JS 代码来说,编译为字节码会大大增加文件体积。如果项目中存在大量小体积的 JavaScript 文件,项目体积会有非常大幅度的增长。当然对于几 M 的 JS Bundle 来说,其体积的增量基本可以忽略不计。
更进一步 - 通过 Node Addon 进行(解)混淆和运行
基于上述的局限性,我们将 v8 字节码嵌入到一个 Node.js 可以运行的 Node Addon 之中。并且在这个 Node Addon 里面对嵌入的 v8 字节码进行解混淆、运行。如此一来,不仅保护了 v8 字节码上的各种常量信息,还将整套字节码方案隐藏在了一个 Node Addon 之内。
使用 N-API
为了避免 rebuild,我们需要使用 N-API 作为 Node Addon 的方案,具体优势可以查阅:Node-API | Node.js v15.14.0 Documentation[5]
使用 Rust 与 Neon Bindings
使用 Rust[6] 语言为单纯的技术选型偏好,Rust 相较于 C++ 具有 相对的内存安全、构建工具链便于使用、跨平台能力强大 等特点,所以我们选择了 Rust 作为 Node Addon 的实现方案。
同时,Rust 具备了 include_bytes! 宏,能够直接在编译时,将二进制文件嵌入至构建产生的动态链接库中,相比 C++ 需要实现 codegen 的方案更为简单。
当然,Rust 并不能直接用于编写 Node Addon,而是需要借助 Neon Bindings 进行开发。Neon Bindings 是一个对 Node API 进行 Rust 层封装的库,它把 Node API 隐藏于底层实现中,并向 Rust 开发者暴露简单易用的 Rust API。(Rust Bindings 在之前并不支持 Node API,Node API 的支持进度参考 Quest: N-API Support · Issue #444 · neon-bindings/neon[7])
具体实现
实现上主要是对构建工具流的改造,具体构建流程可以参考该图示:
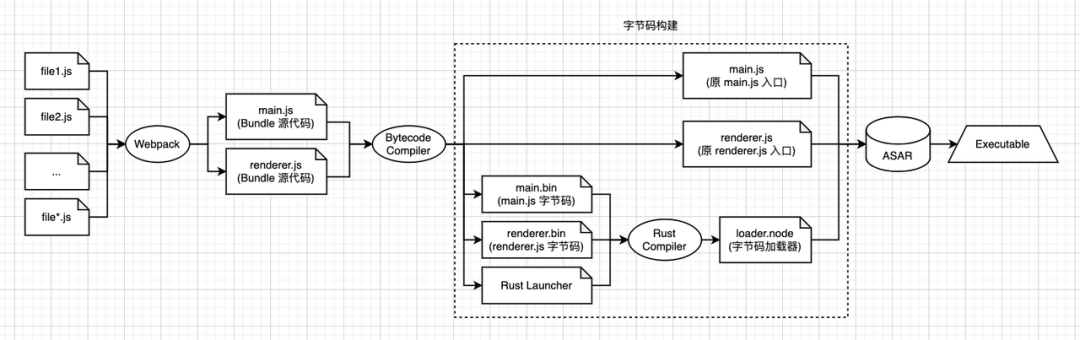
编译字节码
在大多数 Electron 应用的场景下,无论是使用 Webpack 还是其他 Bundler 工具,都会产生两个以上的 Bundle 文件,分别用于主进程和单/多个渲染进程,我们对构建产物的名称进行假定,具体需要结合实际使用场景。我们通过 Bundler 构建出了两个及以上的 Bundle 文件,假设名称分别为:main.js、renderer.js。
完成 Bundle 构建之后,需要对两个 Bundle 编译成字节码。由于我们需要在 Electron 环境下运行这两个 Bundle,因此我们需要在 Electron 环境下完成字节码的生成。对于用于主进程的 Bundle,可以直接在主进程中生成字节码,而对于用于渲染进程的 Bundle,我们需要新起一个浏览器窗口并在其中生成字节码。我们分别创建两个 js 文件:
electron-main.js
// 这个文件可以直接用 electron 命令运行。
const fs = require('fs');
const path = require('path');
const rimraf = require('rimraf');
const { BrowserWindow, app } = require('electron');
const { compile } = require('./bytecode');
async function main() {
// 输入目录,用于存放待编译的 js bundle
const inputPath = path.resolve(__dirname, 'input');
// 输出目录,用于存放编译产物,也就是字节码,文件名对应关系:main.js -> main.bin
const outputPath = path.resolve(__dirname, 'output');
// 清理并重新创建输出目录
rimraf.sync(outputPath);
fs.mkdirSync(outputPath);
// 读取原始 js 并生成字节码
const code = fs.readFileSync(path.resolve(inputPath, 'main.js'));
fs.writeFileSync(path.resolve(outputPath, 'main.bin'), compile(code));
// 启动一个浏览器窗口用于渲染进程字节码的编译
await launchRenderer();
}
async function launchRenderer() {
await app.whenReady();
const win = new BrowserWindow({
webPreferences: {
// 我们通过 preload 在 renderer 执行 js,这样就不需要一个 html 文件了。
preload: path.resolve(__dirname, './electron-renderer.js'),
enableRemoteModule: true,
nodeIntegration: true,
}
});
win.loadURL('about:blank');
win.show();
}
main();electron-renderer.js
// 这个文件是在 electorn-main.js 创建的浏览器窗口中运行的。
const fs = require('fs')
const path = require('path')
const { remote } = require('electron')
const { compile } = require('./bytecode');
async function main() {
const inputPath = path.resolve(__dirname, 'input')
const outputPath = path.resolve(__dirname, 'output')
const code = fs.readFileSync(path.resolve(inputPath, 'renderer.js'))
fs.writeFileSync(path.resolve(outputPath, `renderer.bin`), compile(code));
}
// 执行完成后需要关闭浏览器窗口,以便通知主进程编译已完成
main().then(() => remote.getCurrentWindow().close())接着我们需要实现 bytecode.js,也就是编译字节码的逻辑:
bytecode.js
const vm = require('vm');
const v8 = require('v8');
// 这两个参数非常重要,保证字节码能够被运行。
v8.setFlagsFromString('--no-lazy');
v8.setFlagsFromString('--no-flush-bytecode');
function encode(buf) {
// 这里可以做一些混淆逻辑,比如异或。
return buf.map(b => b ^ 12345);
}
exports.compile = function compile(code) {
const script = new vm.Script(code);
const raw = script.createCachedData();
return encode(raw);
};关于混淆:为了不影响应用的启动速度,不建议使用 AES 等过于复杂的加密算法。因为即便是使用了 AES,字节码构建产物还是可以通过各种方式(内存 Dump、Hook 等)获取。这里对字节码进行混淆,是为了提到破解成本,以避免破解者直接从 Node Addon Binary 的二进制数据中提取各种常量。
有上述几个文件之后,我们就可以直接通过 electron ./electron-main.js 命令,对 input 文件夹里面的 main.js 和 renderer.js 进行字节码编译。产物将会生成在 output 文件夹下。
编译时会创建一个可见的 BrowserWindow,如果不希望它可见,在创建 BrowserWindow 的参数中设置为 hide: true 即可。
封装 Native Addon
我们使用了 Rust 去开发 Node Addon。
后续存在不少直接在 Rust 中执行 JS 逻辑的操作,其中所涉及了一些引用 Node 模块、构造对象等操作,可以参考 Neon Bindings 文档:Introduction | Neon[8]。
引用 Node 模块
我们知道在 Node 中引用模块需要依赖 require 方法,但是 require 方法并不存在于 Global 对象中,而是存在于模块代码执行的作用域之中,我们需要了解 Node CommonJS 的实现机制:
(function (exports, require, module, __filename, __dirname) {
/* 模块文件代码 */
});每个文件都会被包裹在上面的匿名函数中,我们可以看到,module、require、exports、__filename、__dirname 全部都是以局部变量暴露给模块的,因此 Global 对象是不会持有这些内容的。
因此我们无法直接在 Node Addon 中获取 require 等方法,所以 JS 侧在执行 Node Addon 时,必须将 module 对象透传至 Node Addon 中,Rust 侧才能通过调用 Module 的 require 方法去引用其他模块:
require("./loader.node").load({
type: "main",
module // 透传当前模块的 Module 对象
})上面这段代码会直接替换 main.js 中原来的内容,而在 Rust 中,需要实现这么一个方法去方便 Require 操作的进行:
fn node_require(&mut self, id: &str) -> NeonResult<Handle<'a, JsObject>> {
let require_fn: Handle<JsFunction> = self.js_get(self.module, "require")?;
let require_args = vec![self.cx.string(id)];
let result = require_fn.call(&mut self.cx, self.module, require_args)?.downcast_or_throw(&mut self.cx)?;
Ok(result)
}字节码的嵌入和获取
我们在字节码编译完成之后,通过 JS 生成了下面的 Rust 代码,以让 Rust 能够将编译出来的字节码嵌入至动态链接库中,并且能够直接读取:
pub fn get_module_main() -> &'static [u8] {
include_bytes!("[...]/output/main.bin")
}
pub fn get_module_renderer() -> &'static [u8] {
include_bytes!("[...]/output/renderer.bin")
}而 Rust 内读取字节码,只需要根据 JS 对 Node Addon 中的函数调用时传入的 type 字段,做一个 match pattern 判断,再调用对应的二进制数据获取方法即可:
enum LoaderProcessType {
Main,
Renderer
}
let process_type = match process_type_str.value(&mut cx).as_str() {
"main" => LoaderProcessType::Main,
"renderer" => LoaderProcessType::Renderer,
_ => panic!("ERROR")
};
match process_type {
LoaderProcessType::Main => gen_main::get_module(),
LoaderProcessType::Renderer => gen_renderer::get_module()
};Fix Code 生成和替换
在初始化时,我们首先需要生成 Fix Code。Fix Code 是 4 个字节的二进制数据,实际上是 v8 Flags Hash,v8 在运行字节码前会进行校验,如果不一致会导致 cachedDataRejected。为了让字节码能够在当前环境中正常运行,我们需要获取当前环境的 v8 Flags Hash。
我们通过 Rust 调用 vm 模块执行一段无意义的代码,取得 Fix Code:
fn init_fix_code(&mut self) -> NeonResult<()> {
let vm = self.node_require("vm")?;
let vm_script: Handle<JsFunction> = self.js_get(vm, "Script")?;
let code = self.cx.string("\"\"");
let script = vm_script.construct(&mut self.cx, vec![code])?;
let cache: Handle<JsBuffer> = self.js_invoke(script, "createCachedData", Vec::<Handle<JsValue>>::new())?;
let buf: Vec::<u8> = self.buf_to_vec(cache)?;
self.fix_code = Some(buf);
Ok(())
}接着将待运行的字节码的 12~16 字节替换成刚刚获取的 4 字节 Fix Code:
data[12..16].clone_from_slice(&fix_code[12..16]);
假源码生成
接着需要在 Rust 中解析字节码的 8~12 位,得到 Source Hash 并算出代码长度。接着生成一个等长的任意字符串,作为假源码,以欺骗过 v8 的源代码长度校验。
let mut len = 0usize;
for (i, b) in (&data[8..12]).iter().enumerate() {
len += *b as usize * 256usize.pow(i as u32)
};
self.eval(&format!(r#"'"' + "\u200b".repeat({}) + '"'"#, len - 2))?;此处之所以直接调用 Eval 去生成二进制数据,是因为 Rust 的字符串转换为 JsString 存在不小的开销,所以还是直接在 JS 中生成会比较高效。Eval 的实现本质上还是调用 vm 模块的 runInThisContext 方法。
解混淆
在运行字节码之前,我们需要通过异或运算去解混淆:
<pre data-tool="mdnice编辑器" style="margin-top: 10px;margin-bottom: 10px;">```
buf.into_iter().enumerate().map(|(_, b)| b ^ <span style="color: #d19a66;line-height: 26px;">12345).collect()<br></br>
#### 运行字节码
接着,就要运行字节码了。
首先,为了能够正常运行之前生成的字节码,还需要对 v8 的一些参数进行设置,对齐编译环境的配置:
fn configure_v8(&mut self) -> NeonResult<()> {
let v8 = self.node_require( "v8")?;
let set_flag: Handle
接着我们还是需要在 Rust 中调用 vm 模块去运行字节码,即使用 Rust 执行下面的一段 JS 逻辑(原 Rust 代码过长就不贴了):
const vm = require('vm');
const script = vm.Script(dummyCode, { cachedData, // 这个就是字节码 filename, lineOffset: 0, displayErrors: true }); script.runInThisContext({ filename, lineOffset: 0, columnOffset: 0, displayErrors: true });
### 运行原理
最后,我们的构建产物的目录结构如下:
dist ├─ loader.node - Node Addon,里面包含了混淆过的所有字节码数据,基本不可读。 ├─ main.js - 主进程代码入口,只有一行加载代码 ├─ renderer.js - 渲染进程代码入口,只有一行加载代码 └─ index.html - HTML 文件,用于加载 renderer.js
运行应用时,以 `main.js` 为入口,完整的运行流程如下:
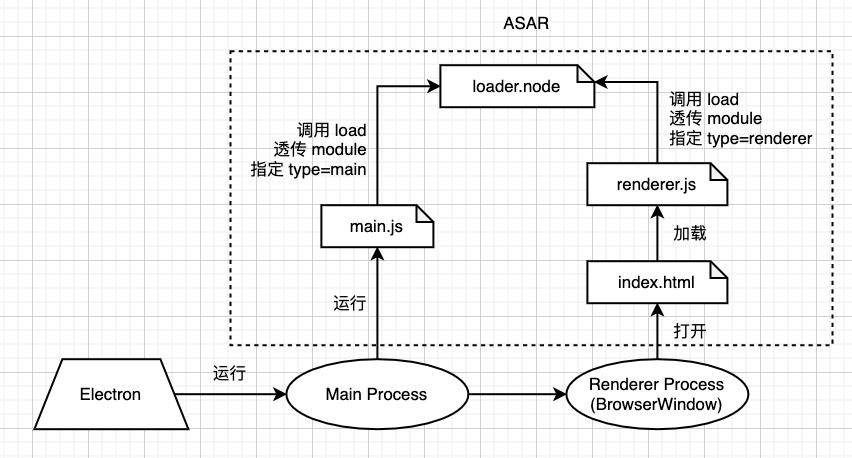
其中,loader.node 里存储了所有的字节码数据,并且包含了加载字节码的逻辑。main.js 和 renderer.js 都会直接去引用 loader.node,并且传入 type 参数去指定需要加载的字节码。
常见疑问
----
- ##### 对构建流程有何影响?
- 对构建流程的影响,主要是在 Bundle 构建之后、Electron Builder 打包之前,插入了一层字节码编译和 Node Addon 编译。
- ##### 对构建性能的影响?
- 启动 Electron 进程和 BrowserWindow 用于字节码的编译,需要消耗 2s 左右。编译字节码时,对于 10M 左右的 Bundle,得益于 v8 超高的 JavaScript 解析效率,字节码生成的时间在 150ms 左右。最后将字节码封装进 Node Addon,由于 Rust 的构建比较慢,可能需要 5s~10s。
- 整体来说,这套方案对构建时间会有 10s~20s 的延长。如果是在 CI/CD 上进行构建,由于失去了 cargo 缓存,额外算上 cargo 下载依赖的额外耗时,时间可能会延长到 1 分钟左右。
- ##### 对代码组织和编写的影响?
- 目前发现字节码方案对代码的唯一影响,是 `Function.prototype.toString()` 方法无法正常使用,原因是源代码并不跟随字节码分发,因此取不到函数的源代码。
- ##### 对程序性能是否有影响?
- 对于代码的执行性能没有影响。对于初始化耗时,有 30% 左右的提升(在我们的应用中,Bundle 大小为 10M 左右,初始化时间从 550ms 左右降低到了 370ms)。
- ##### 对程序体积的影响?
- 对于只有几百 KB 的 Bundle 来说,字节码体积会有比较明显的膨胀,但是对于 2M+ 的 Bundle 来说,字节码体积没有太大的区别。
- ##### 代码保护强度如何?
- 目前来说,还没有现成的工具能够对 v8 字节码进行反编译,因此该方案还是还是比较可靠且安全的。但是受限于字节码本身的原理,开发反编译工具的难度并不高,在未知的将来,字节码加固的方案普及之后,v8 字节码应该会像 Java/C# 那样能够被工具反编译,到时候我们就应该继续探索其他代码保护方法。
- 因此,我们额外地通过 Node Addon 层对字节码进行了混淆,能够在字节码保护的基础上隐藏代码运行逻辑,不仅增大了解包难度,还增大了代码篡改、二次分发的难度。
### 参考资料
\[1\]参考: *https://nodejs.org/api/vm.html#vm\_script\_createcacheddata*
\[2\]bytenode/bytenode: *https://github.com/bytenode/bytenode*
\[3\]理解 V8 的字节码「译」: *https://zhuanlan.zhihu.com/p/28590489*
\[4\]通过字节码保护 Node.js 源码之原理篇: *https://zhuanlan.zhihu.com/p/359235114*
\[5\]Node-API | Node.js v15.14.0 Documentation: *https://nodejs.org/dist/latest-v15.x/docs/api/n-api.html*
\[6\]Rust: *https://www.rust-lang.org/*
\[7\]Quest: N-API Support · Issue #444 · neon-bindings/neon: *https://github.com/neon-bindings/neon/issues/444*
\[8\]Introduction | Neon: *https://neon-bindings.com/docs/intro*
- - - - - -