基于DAG的任务编排框架/平台
最近在做的工作比较需要一个支持任务编排工作流的框架或者平台,这里记录下实现上的一些思路。
任务编排工作流
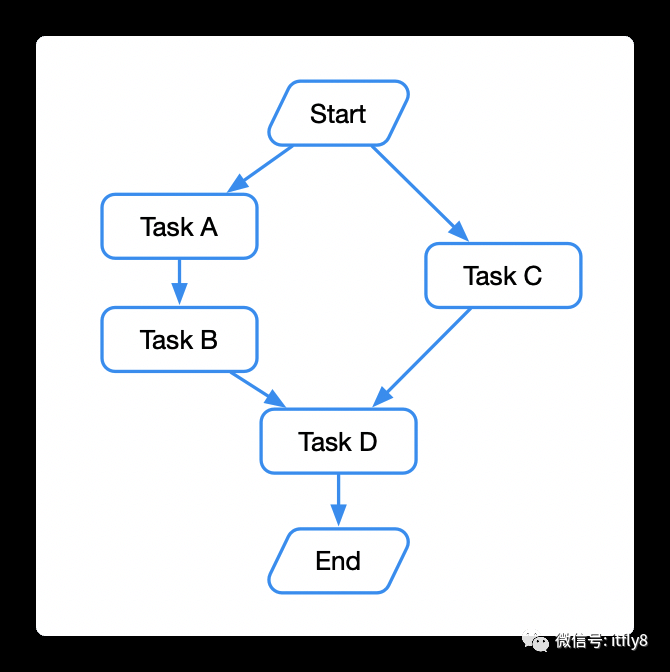
任务编排是什么意思呢,顾名思义就是可以把"任务"这个原子单位按照自己的方式进行编排,任务之间可能互相依赖。复杂一点的编排之后就能形成一个 workflow 工作流了。我们希望这个工作流按照我们编排的方式去执行每个原子 task 任务。如下图所示,我们希望先并发运行 Task A 和 Task C,Task A 执行完后串行运行 Task B,在并发等待 Task B 和 C 都结束后运行 Task D,这样就完成了一个典型的任务编排工作流。
DAG 有向无环图
首先我们了解图这个数据结构,每个元素称为顶点 vertex,顶点之间的连线称为边 edge。像我们画的这种带箭头关系的称为有向图,箭头关系之间能形成一个环的成为有环图,反之称为无环图。显然运用在我们任务编排工作流上,最合适的是 DAG 有向无环图。
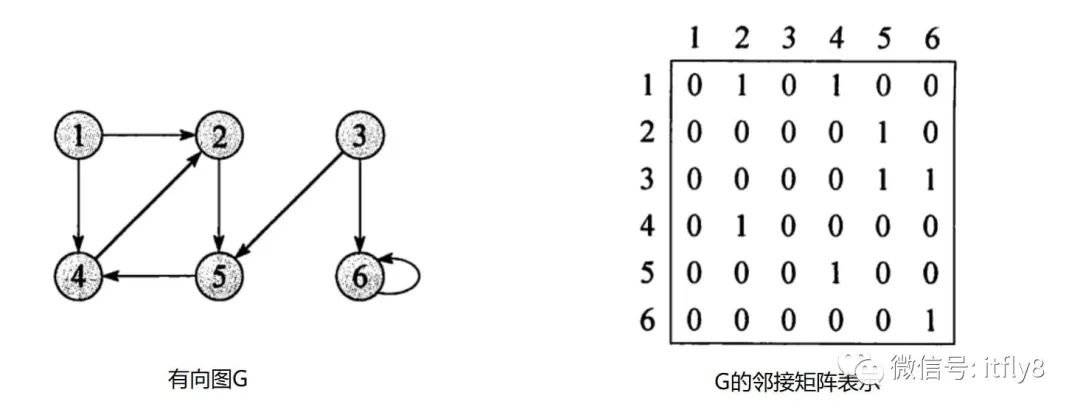
我们在代码里怎么存储图呢,有两种数据结构:邻接矩阵和邻接表。
下图表示一个有向图的邻接矩阵,例如 x->y 的边,只需将 Array[x][y]标识为 1 即可。
此外我们也可以使用邻接表来存储,这种存储方式较好地弥补了邻接矩阵浪费空间的缺点,但相对来说邻接矩阵能更快地判断连通性。
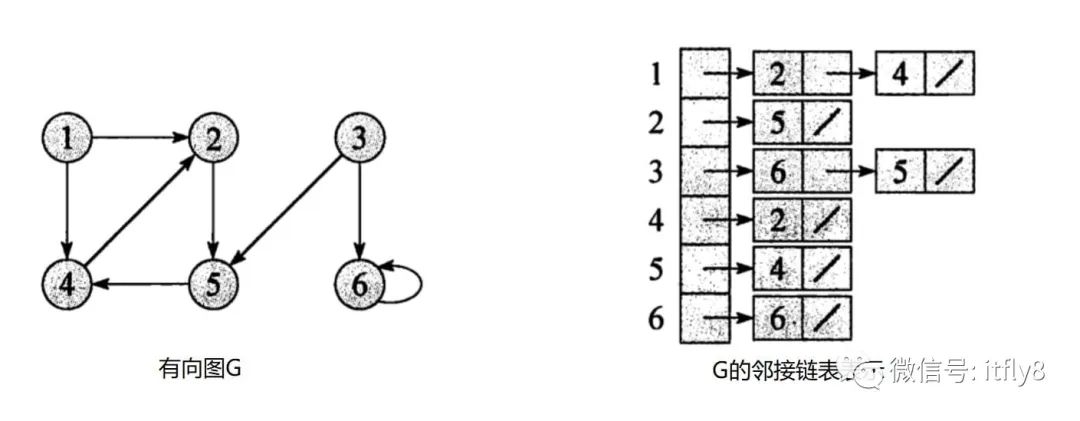
一般在代码实现上,我们会选择邻接矩阵,这样我们在判断两点之间是否有边更方便点。
一个任务编排框架
了解了 DAG 的基本知识后我们可以来简单实现一下。
了解JUC包的可能快速想到CompletableFuture,这个类对于多个并发线程有复杂关系耦合的场景是很适用的,如果是一次性任务,那么使用CompletableFuture完全没有问题。但是作为框架或者平台来说,我们还需要考虑存储节点状态、重试执行等逻辑,对于这些CompletableFuture是不能满足的。
我们需要更完整地考虑与设计这个框架。首先是存储结构,我们的 Dag 表示一整个图,Node 表示各个顶点,每个顶点有其 parents 和 children:
//Dag
public final class DefaultDag<T, R> implements Dag<T, R> {
private Map<T, Node<T, R>> nodes = new HashMap<T, Node<T, R>>();
...
}//Node
public final class Node<T, R> {
/**
* incoming dependencies for this node
*/
private Set<Node<T, R>> parents = new LinkedHashSet<Node<T, R>>();
/**
* outgoing dependencies for this node
*/
private Set<Node<T, R>> children = new LinkedHashSet<Node<T, R>>();
...
}画两个顶点,以及为这两个顶点连边操作如下:
public void addDependency(final T evalFirstNode, final T evalLaterNode) {
Node<T, R> firstNode = createNode(evalFirstNode);
Node<T, R> afterNode = createNode(evalLaterNode);
addEdges(firstNode, afterNode);
}
private Node<T, R> createNode(final T value) {
Node<T, R> node = new Node<T, R>(value);
return node;
}
private void addEdges(final Node<T, R> firstNode, final Node<T, R> afterNode) {
if (!firstNode.equals(afterNode)) {
firstNode.getChildren().add(afterNode);
afterNode.getParents().add(firstNode);
}
}到现在我们其实已经把基础数据结构写好了,但我们作为一个任务编排框架最终是需要线程去执行的,我们把它和线程池一起给包装一下。
//任务编排线程池
public class DefaultDexecutor <T, R> {
//执行线程,和2种重试线程
private final ExecutorService<T, R> executionEngine;
private final ExecutorService immediatelyRetryExecutor;
private final ScheduledExecutorService scheduledRetryExecutor;
//执行状态
private final ExecutorState<T, R> state;
...
}
//执行状态
public class DefaultExecutorState<T, R> {
//底层图数据结构
private final Dag<T, R> graph;
//已完成
private final Collection<Node<T, R>> processedNodes;
//未完成
private final Collection<Node<T, R>> unProcessedNodes;
//错误task
private final Collection<ExecutionResult<T, R>> erroredTasks;
//执行结果
private final Collection<ExecutionResult<T, R>> executionResults;
}可以看到我们的线程包括执行线程池,2 种重试线程池。我们使用 ExecutorState 来保存一些整个任务工作流执行过程中的一些状态记录,包括已完成和未完成的 task,每个 task 执行的结果等。同时它也依赖我们底层的图数据结构 DAG。
接下来我们要做的事其实很简单,就是 BFS 这整个 DAG 数据结构,然后提交到线程池中去执行就可以了,过程中注意一些节点状态的保持,结果的保存即可。
还是以上图为例,值得说的一点是在 Task D 这个点需要有一个并发等待的操作,即 Task D 需要依赖 Task B 和 Task C 执行结束后再往下执行。这里有很多办法,我选择了共享变量的方式来完成并发等待。遍历工作流中被递归的方法的伪代码如下:
private void doProcessNodes(final Set<Node<T, R>> nodes) {
for (Node<T, R> node : nodes) {
//共享变量 并发等待
if (!processedNodes.contains(node) && processedNodes.containsAll(node.getParents())) {
Task<T, R> task = newTask(node);
this.executionEngine.submit(task);
...
ExecutionResult<T, R> executionResult = this.executionEngine.processResult();
if (executionResult.isSuccess()) {
state.markProcessingDone(processedNode);
}
//继续执行孩子节点
doExecute(processedNode.getChildren());
...
}
}
}这样我们基本完成了这个任务编排框架的工作,现在我们可以如下来进行示例图中的任务编排以及执行:
DefaultExecutor<String, String> executor = newTaskExecutor();
executor.addDependency("A", "B");
executor.addDependency("B", "D");
executor.addDependency("C", "D");
executor.execute();任务编排平台化
好了现在我们已经有一款任务编排框架了,但很多时候我们想要可视化、平台化,让使用者更加无脑。
框架与平台最大的区别在哪里?是可拖拽的可视化输入么?我觉得这个的复杂度更多在前端。而对于后端平台来讲,与框架最大的区别是数据的持久化。
对于 DAG 的顶点来说,我们需要将每个节点 Task 的信息给持久化到关系数据库中,包括 Task 的状态、输出结果等。而对于 DAG 的边来说,我们也得用数据库来存储各 Task 之间的方向关系。此外,在遍历执行 DAG 的整个过程中的中间状态数据,我们也得搬运到数据库中。
首先我们可以设计一个 workflow 表,来表示一个工作流。接着我们设计一个 task 表,来表示一个执行单元。task 表主要字段如下,这里主要是 task_parents 的设计,它是一个 string,存储 parents 的 taskId,多个由分隔符分隔。
task_id
workflow_id
task_name
task_status
result
task_parents依赖是上图这个例子,对比框架来说,我们首先得将其存储到数据库中去,最终可能得到如下数据:
task_id workflow_id task_name task_status result task_parents
1 1 A 0 -1
2 1 B 0 1
3 1 C 0 -1
4 1 D 0 2,3可以看到,这样也能很好地存储 DAG 数据,和框架中代码的输入方式差别并不是很大。
接下来我们要做的是遍历执行整个 workflow,这边和框架的差别也不大。首先我们可以利用select * from task where workflow_id = 1 and task_parents = -1来获取初始化节点 Task A 和 Task C,将其提交到我们的线程池中。
接着对应框架代码中的doExecute(processedNode.getChildren());,我们使用select * from task where task_parents like %3%,就可以得到 Task C 的孩子节点 Task D,这里使用了模糊查询是因为我们的 task_parents 可能是由多个父亲的 taskId 与分隔号组合而成的字符串。查询到孩子节点后,继续提交到线程池即可。
别忘了我们在 Task D 这边还有一个并发等待的操作,对应框架代码中的
if (!processedNodes.contains(node) && processedNodes.containsAll(node.getParents()))。这边我们只要判断select count(1) from task where task_id in (2,3) and status != 1的个数为 0 即可,
即保证 parents task 全部成功。
另外值得注意的是 task 的重试。在框架中,失败 task 的重试可以是立即使用当前线程重试或者放到一个定时线程池中去重试。而在平台上,我们的重试基本上来自于用户在界面上的点击,即主线程。
至此,我们已经将任务编排框架的功能基本平台化了。作为一个任务编排平台,可拖拽编排的可视化输入、整个工作流状态的可视化展示、任务的可人工重试都是其优点。