你需要了解的有关 Node.js 的所有信息

Node.js 是当前用来构建可扩展的、高效的 REST API's 的最流行的技术之一。它还可以用来构建混合移动应用、桌面应用甚至用于物联网领域。
我真的很喜欢它,我已经使用 Node.js 工作了 6 年。这篇文章试图成为了解 Node.js 工作原理的终极指南。
Node.js 之前的世界
多线程服务器
Web 应用程序是用一个 client/server(客户端/服务器)模式所编写的,其中 client 将向 server 请求资源并且 server 将会根据这个资源以响应。server 仅在 client 请求时做出响应,并在每次响应后关闭连接。
这种模式是有效的,因为对服务器的每一个请求都需要时间和资源(内存、CPU 等)。服务器必须完成上一个请求,才能接受下一个请求。
所以,服务器在一定的时间内只处理一个请求?这不完全是,当服务器收到一个新请求时,这个请求将会被一个线程处理。
简而言之,线程是 CPU 为执行一小段指令所花费的时间和资源。话虽如此,服务器一次要处理多个请求,每个线程一个(也可以称为 thread-per-request 模式)。
注:thread-per-request 意为每一个请求一个线程。
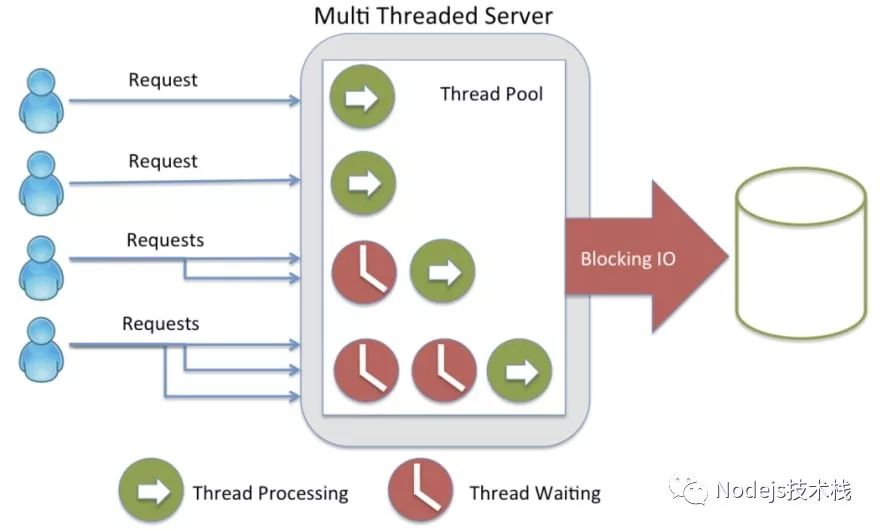
在多线程服务器示例中,服务器同时最多允许 4 个请求(线程)当接下来收到 3 个请求时,这些请求必须等待直到这 4 个线程中的任何一个可用。
解决此限制的一种方法是向服务器添加更多资源(内存,CPU内核等),但这可能根本不是一个好主意...

阻塞 I/O
服务器中的线程数不仅仅是这里唯一的问题。也许你想知道为什么一个线程不能同时处理 2 个或更多的请求?这是因为阻塞了 Input/Output 操作。

用户访问 http://yourstore.com/products 服务器将从数据库中获取你的全部产品来呈现一个 HTML 文件,这很简单吧?
但是,后面会发生什么?...
- 1. 当用户访问 /products 时,需要执行特定的方法或函数来满足请求,因此会有一小段代码来解析这个请求的 url 并定位到正确的方法或函数。线程正在工作。✔️
- 2. 该方法或函数以及第一行将被执行。线程正在工作。✔️
- 3. 因为你是一名优秀的开发者,你会保存所有的系统日志在一个文件中,要确保路由执行了正确的方法/函数,你的日志要增加一个字符串 “Method X executing!!”(某某方法正在执行),这是一个阻塞的 I/O 操作。线程正在等待。❌
- 4. 日志已被保存并且下一行将被执行。线程正在工作。✔️
- 5. 现在是时候去数据库并获取所有产品了,一个简单的查询,例如 SELECT * FROM products 操作,但是您猜怎么着?这是一个阻塞的 I/O 操作。线程正在等待。❌
- 6. 你会得到一个所有的产品列表,但要确保将它们记录下来。线程正在等待。❌
- 7. 使用这些产品,是时候渲染模版了,但是在渲染它之前,你应该先读取它。线程正在等待。❌
- 8. 模版引擎完成它的工作,并将响应发送到客户端。线程再次开始工作。✔️
- 9. 线程是自由的(空闲的),像鸟儿一样。️
I/O 操作有多慢?这得需要看情况。
让我们检查以下表格:
| 操作 | CPU 时钟周期数 |
|---|---|
| CPU 寄存器 | 3 ticks |
| L1 Cache(一级缓存) | 8 ticks |
| L2 Cache(二级缓存) | 12 ticks |
| RAM(随机存取存储器) | 150 ticks |
| Disk(磁盘) | 30,000,000 ticks |
| Network(网络) | 250,000,000 ticks |
译者备注:时钟周期也称(tick、clock cycle、clock period 等),指一个硬件在被使用过程中,被划分为多个时间周期,当我们需要比较不同硬件的性能时,就在不同硬件之上测试同一个软件,观察它们的时钟周期时间和周期数,如果时钟周期时间越长、周期数越多,就意味着这个硬件需要的性能较低。
磁盘和网络操作太慢了。您的系统进行了多少次查询或外部 API 调用?
在恢复过程中,I/O 操作使得线程等待且浪费资源。

C10K 问题
早在 2000 年代初期,服务器和客户端机器运行缓慢。这个问题是在一台服务器机器上同时运行 10,000 个客户端链接。
为什么我们传统的 “thread-per-request” 模式不能够解决这个问题?现在让我们做一些数学运算。
本地线程实现为每个线程分配大约 1 MB 的内存,所以 10K 线程就需要 10GB 的 RAM,请记住这仅仅是在 2000 年代初期!!

JavaScript 进行救援?
剧透提醒 !!
Node.js 解决了这个 C10K 问题... 但是为什么?
JavaScript 服务端早在 2000 年代并不是什么新鲜事,它基于 “thread-per-request” 模式在 Java 虚拟机之上有一些实现,例如,RingoJS、AppEngineJS。
但是,如果那不能解决 C10K 问题,为什么 Node.js 可以?好吧,因为它是单线程的。

Node.js 和 Event Loop
Node.js
Node.js 是一个构建在 Google Chrome's JavaScript 引擎(V8 引擎)之上的服务端平台,可将 JavaScript 代码编译为机器代码。
Node.js 基于事件驱动、非阻塞 I/O 模型,从而使其轻巧和高效。它不是一个框架,也不是一个库,它是一个运行时。
一个简单的例子:
// Importing native http module
const http = require('http');
// Creating a server instance where every call
// the message 'Hello World' is responded to the client
const server = http.createServer(function(request, response) {
response.write('Hello World');
response.end();
});
// Listening port 8080
server.listen(8080);非阻塞 I/O
Node.js 是非阻塞 I/O,这意味着:
- 主线程不会在 I/O 操作中阻塞。
- 服务器将会继续参加请求。
- 我们将使用异步代码。
让我们写一个例子,在每一次 /home 请求时,服务器将响应一个 HTML 页面,否则服务器响应一个 'Hello World' 文本。要响应 HTML 页面,首先要读取这个文件。
home.html
<html>
<body>
<h1>This is home page</h1>
</body>
</html>index.js
const http = require('http');
const fs = require('fs');
const server = http.createServer(function(request, response) {
if (request.url === '/home') {
fs.readFile(`${ __dirname }/home.html`, function (err, content) {
if (!err) {
response.setHeader('Content-Type', 'text/html');
response.write(content);
} else {
response.statusCode = 500;
response.write('An error has ocurred');
}
response.end();
});
} else {
response.write('Hello World');
response.end();
}
});
server.listen(8080);如果这个请求的 url 是 /home,我们使用 fs 本地模块读取这个 home.html 文件。
传递给 http.createServer 和 fs.readFile 的函数称为回调。这些功能将在将来的某个时间执行(第一个功能将在收到一个请求时执行,第二个功能将在文件读取并且缓冲之后执行)。
在读取文件时,Node.js 仍然可以处理请求,甚至再次读取文件,all at once in a single thread... but how?!
The Event Loop(事件循环)
事件循环是 Node.js 背后的魔力,简而言之,事件循环实际上是一个无限循环,并且是线程里唯一可用的。
事件循环需要经历 6 个阶段,所有阶段的执行被称为 tick。
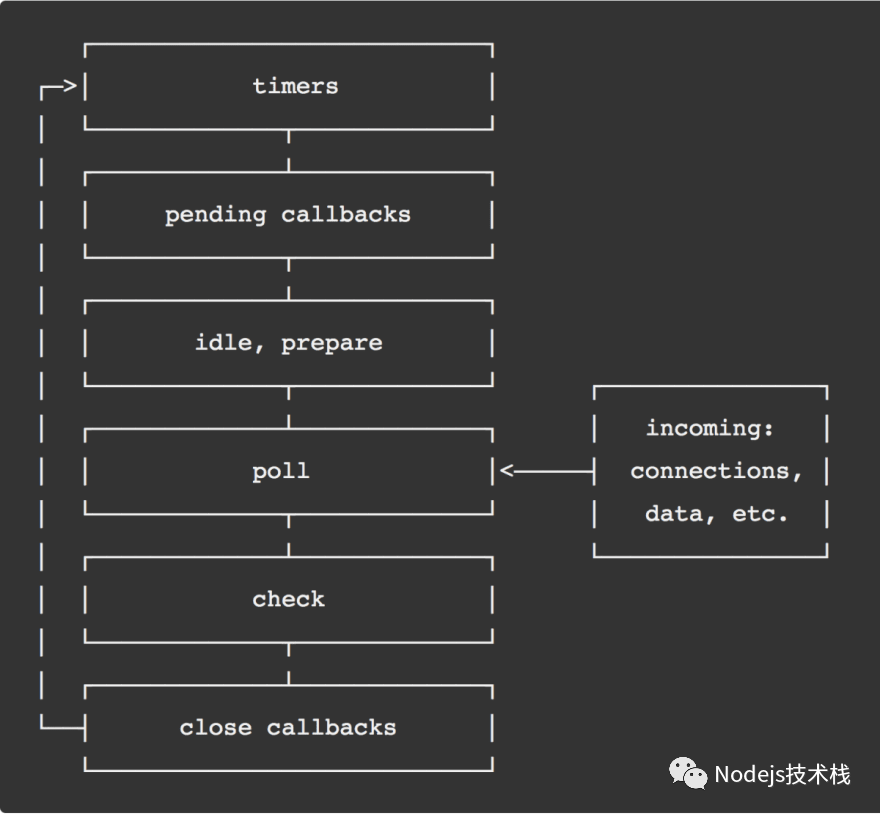
- timers:这个阶段执行定时器 setTimeout() 和 setInterval() 的回调函数。
- pending callbacks:几乎所有的回调在这里执行,除了 close 回调、定时器 timers 阶段的回调和 setImmediate()。
- idle, prepare: 仅在内部应用。
- poll:检索新的 I/O 事件;适当时 Node 将在此处阻塞。
- check:setImmediate() 回调函数将在这里执行。
- close callbacks: 一些准备关闭的回调函数,如:socket.on('close', ...)。
好的,所以只有一个线程并且该线程是一个 EventLoop,但是 I/O 操作由谁来执行呢?
注意 !!!
当 Event Loop 需要执行 I/O 操作时,它将从一个池(通过 Libuv 库)中使用系统线程,当这个作业完成时,回调将排队等待在 “pending callbacks” 阶段被执行。


CPU 密集型任务问题
Node.js 似乎很完美,你可以用它来构建任何你想要的东西。
让我们构建一个 API 来计算质数。
质数又称素数。一个大于 1 的自然数,除了 1 和它自身外,不能被其他自然数整除的数叫做质数;
primes.js
function isPrime(n) {
for(let i = 2, s = Math.sqrt(n); i <= s; i++)
if(n % i === 0) return false;
return n > 1;
}
function nthPrime(n) {
let counter = n;
let iterator = 2;
let result = [];
while(counter > 0) {
isPrime(iterator) && result.push(iterator) && counter--;
iterator++;
}
return result;
}
module.exports = { isPrime, nthPrime };index.js
const http = require('http');
const url = require('url');
const primes = require('./primes');
const server = http.createServer(function (request, response) {
const { pathname, query } = url.parse(request.url, true);
if (pathname === '/primes') {
const result = primes.nthPrime(query.n || 0);
response.setHeader('Content-Type', 'application/json');
response.write(JSON.stringify(result));
response.end();
} else {
response.statusCode = 404;
response.write('Not Found');
response.end();
}
});
server.listen(8080);primes.js 是质数功能实现,isPrime 检查给予的参数 N 是否为质数,如果是一个质数 nthPrime 将返回 n 个质数
index.js 创建一个服务并在每次请求 /primes 时使用这个库。通过 query 传递参数。
获取 20 前的质数,我们发起一个请求 http://localhost:8080/primes?n=2
假设有 3 个客户端访问这个惊人的非阻塞 API:
- 第一个每秒请求前 5 个质数。
- 第二个每秒请求前 1,000 个质数
- 第三个请求一次性输入前 10,000,000,000 个质数,但是...
当我们的第三个客户端发送请求时,客户端将会被阻塞,因为质数库会占用大量的 CPU。主线程忙于执行密集型的代码将无法做其它任何事情。
但是 Libuv 呢?如果你记得这个库使用系统线程帮助 Node.js 做一些 I/O 操作以避免主线程阻塞,那你是对的,这个可以帮助我们解决这个问题,但是使用 Libuv 库我们必须要使用 C++ 语言编写。
值得庆祝的是 Node.js v10.5 引入了工作线程。
工作线程
如文档所述:
工作线程对于执行 CPU 密集型的 JavaScript 操作非常有用。它们在 I/O 密集型的工作中用途不大。Node.js 的内置的异步 I/O 操作比工作线程效率更高。
修改代码
现在修复我们的初始化代码:
primes-workerthreads.js
const { workerData, parentPort } = require('worker_threads');
function isPrime(n) {
for(let i = 2, s = Math.sqrt(n); i <= s; i++)
if(n % i === 0) return false;
return n > 1;
}
function nthPrime(n) {
let counter = n;
let iterator = 2;
let result = [];
while(counter > 0) {
isPrime(iterator) && result.push(iterator) && counter--;
iterator++;
}
return result;
}
parentPort.postMessage(nthPrime(workerData.n));index-workerthreads.js
const http = require('http');
const url = require('url');
const { Worker } = require('worker_threads');
const server = http.createServer(function (request, response) {
const { pathname, query } = url.parse(request.url, true);
if (pathname === '/primes') {
const worker = new Worker('./primes-workerthreads.js', { workerData: { n: query.n || 0 } });
worker.on('error', function () {
response.statusCode = 500;
response.write('Oops there was an error...');
response.end();
});
let result;
worker.on('message', function (message) {
result = message;
});
worker.on('exit', function () {
response.setHeader('Content-Type', 'application/json');
response.write(JSON.stringify(result));
response.end();
});
} else {
response.statusCode = 404;
response.write('Not Found');
response.end();
}
});
server.listen(8080);index-workerthreads.js 在每个请求中将创建一个 Worker 实例,在一个工作线程中加载并执行 primes-workerthreads.js 文件。当这个质数列表计算完成,这个 message 消息将会被触发,接收信息并赋值给 result。由于这个 job 已完成,将会再次触发 exit 事件,允许主线程发送数据给到客户端。
primes-workerthreads.js 变化小一点。它导入 workerData(从主线程传递参数),parentPort 这是我们向主线程发送消息的方式。
现在让我们再次做 3 个客户端例子,看看会发生什么:
主线程不再阻塞 !!!!!
它的工作方式与预期的一样,但是生成工作线程并不是最佳实践,创建新线程并不便宜。一定先创建一个线程池。
结论
Node.js 是一项功能强大的技术,值得学习。
我的建议总是很好奇,如果您知道事情的进展,您将做出更好的决定。
伙计们,到此为止。希望您对 Node.js 有所了解。