设计稿(UI视图)自动生成代码方案的探索

设计稿(UI视图)转代码是前端工程师日常不断重复的工作,这部分工作复杂度较低但工作占比较高,所以提升设计稿转代码的效率一直是前端工程师追求的方向之一。 此前,前端工程师尝试过将业务组件模块化构建成通用视图库,并通过拖拽、拼接等形式搭建业务模块,从而实现视图复用,降低设计稿转代码的研发成本。但随着业务的发展和个性化的驱动,通用视图库无法覆盖所有应用场景,本文提出了一种设计稿自动生成代码的方案。
1 背景
设计稿(UI视图)转代码是前端工程师日常不断重复的工作,这部分工作复杂度较低但工作占比较高,所以提升设计稿转代码的效率一直是前端工程师追求的方向之一。此前,前端工程师尝试过将业务组件模块化构建成通用视图库,并通过拖拽、拼接等形式搭建业务模块,从而实现视图复用,降低设计稿转代码的研发成本。但随着业务的发展和个性化的驱动,通用视图库无法覆盖所有应用场景,本文提出了一种设计稿自动生成代码的方案。
目前,业内主流的代码生成方案有两种,一种是通过训练神经网络,从图片或草图直接生成代码,以微软sketch2json为代表;另一种是基于[Sketch] 源文件,从中解析出图层信息转化成DSL并生成代码,以imgCook为代表。
经过实践,我们发现第一种方案基于神经网络的代码生成算法虽然简单粗暴,但复杂层布局的准确率较低、可解释程度不高导致后续无法持续优化。方案二中Sketch源文件信息量丰富、算法自定义程度高、优化空间大。因此,我们调研了业界基于[Sketch] 的代码自动生成方案(已对外公布或者开源),发现了一些不足并尝试解决,下面从算法准确率、代码可读性、研发流程覆盖度等方面做一下对比(该对比结果仅考察业界方案对我们自己业务的适用性,实际结果可能存在差异):

- 算法准确率方面:淘宝imgCook支持基于AI的组件识别,不支持成组布局,准确率中等(从官网了解到可以识别循环布局,但不能识别出测试样本中的循环布局),58 Picasso仅支持原始组件的识别,复杂组件生成错误较多,不支持成组/悬浮/循环布局,准确率较低。
- 代码可读性方面:淘宝imgCook在生成布局时,测试样本中图层重叠区域使用到了基于根布局的绝对定位方式,不符合RD预期,可读性一般,而我们的方案使用相对定位方式,可读性较好。
- 研发流程覆盖度方面:淘宝imgCook从RD视角构建了一个IDE,支持在IDE中完成样式调整、逻辑绑定;而我们的方案从产研协作视角出发,支持数据、逻辑、埋点的可视化配置及上线。
2 方案介绍
如图所示,配置平台主要分成三块包括:设计稿转视图树(UI2DSL)、视图树转代码(DSL2Code)、以及业务信息绑定,下面简单介绍一下每一块的作用。

- 设计稿转DSL视图树(UI2DSL):将设计稿转化成平台无关的DSL视图树。
- 视图树转代码(DSL2Code):将DSL视图树转化成基于Flex布局的[MTFlexBox] 静态代码。
- 业务信息绑定:提供可视化配置工具,支持MTFlexBox静态代码绑定后台数据、业务逻辑、以及曝光/点击等埋点逻辑。
2.1 设计稿转视图树(UI2DSL)
UI2DSL主要经历以下四个步骤:

2.1.1 设计稿导入
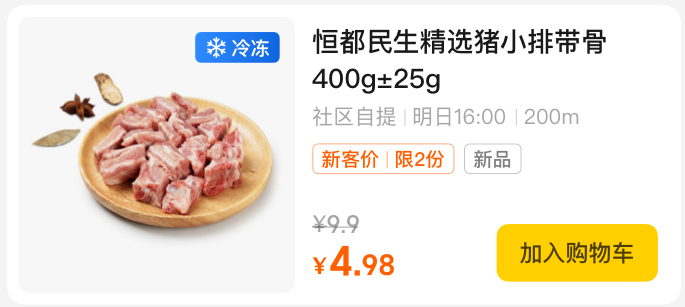
在日常开发过程中,我们接触比较多的组件有按钮、标题、进度条、评分组件等,但是Sketch数据源中并没有这些组件只有图层信息,图层是设计师在设计UI视图时用到的视图控件。组件与图层的对应关系是一对多的关系,图层在Sketch数据源中的表现形式如下图中的JSON数据结构所示,描述了图层的坐标、大小等信息,后续布局生成就是基于对图层的切割来实现的。
[
{
"class_name":"MSTextLayer",
"font_face":"PingFangSC-Medium",
"font_size":13.44,
"height":36.5,
"index":8,
"line_height":18.24,
"name":"恒都民生精选猪小排带骨400g±25g",
"object_id":"EF55F482-A690-4EC2-8A6E-6E7D2C6A9D91",
"opacity":0.9000000357627869,
"text":"恒都民生精选猪小排带骨400g±25g",
"text_align":"left",
"text_color":"#FF000000",
"type":"text",
"width":171.8,
"x":164.2,
"y":726.7
},
//......
]2.1.2 组件识别
从上面的数据源可以看出,图层有图片、文字、矩形等基本类型,在组件识别这一步图层需要被转化成文字/图片/进度条/评分组件/价格组件/角标等日常开发使用的组件类型。但是,目前我们的进展还停留在只能将图层识别为文字或者图片的阶段,后续我们将接入淘宝开源的[pipcook] 框架,基于神经网络算法进行更加丰富的组件类型识别。
2.1.3 可视化干预
设计稿作为输入源是设计稿自动转代码的基础,这对设计稿的设计规范要求较高。但在实践中,我们发现设计师会利用Sketch中的基本图形(每个图形最终形成数据源中的一个图层)叠加来描述一个组件的视觉效果,因此设计稿中不可避免会出现冗余图层的问题,干扰DSL的生成。
虽然我们也尝试了利用自动化的手段删除冗余图层,但对于算法不能识别的部分(例如:图片上有一个文本图层,但是实际情况中文本是显示在图片里的,这个时候无法从算法层面决定是否删除文本),仍然需要靠人工进行图层删除、合并等,否则无法正常生成DSL。设计稿主要有以下几类问题。
图层未合并

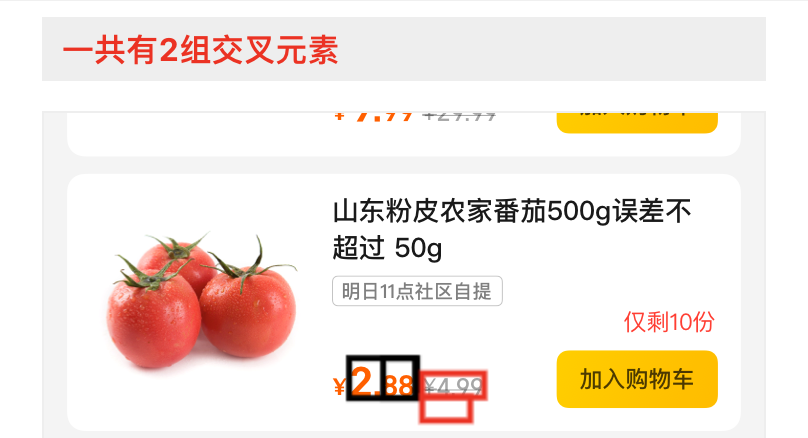
图层位置交叉
复杂背景图层

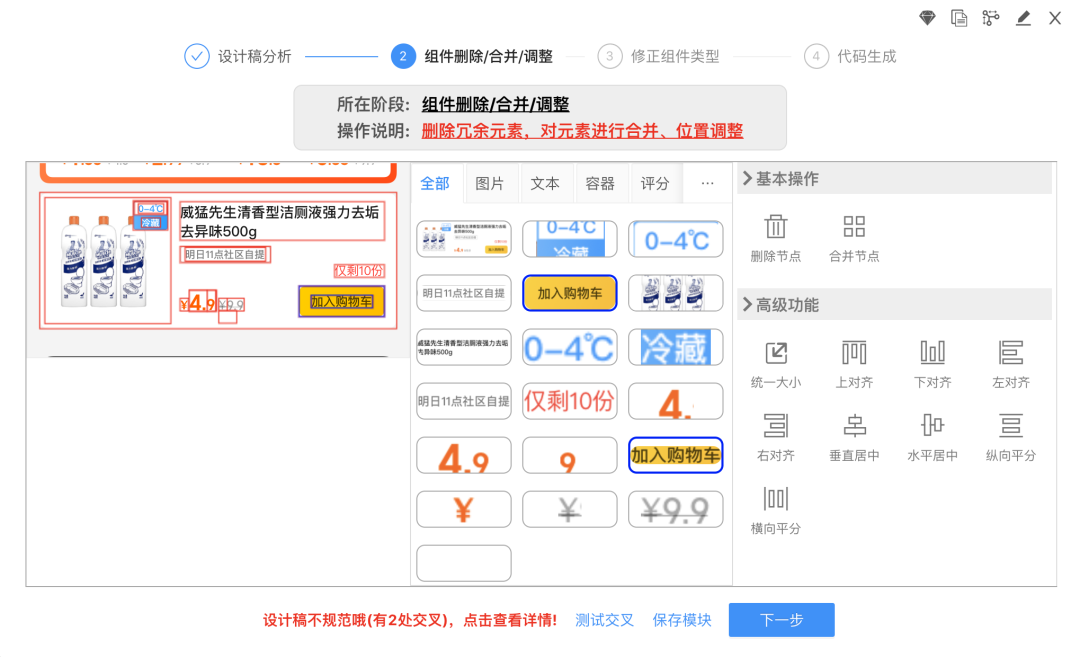
上面提出的问题,通过约束设计师来达到设计稿的规范化,难度较大,所以我们提供了可视化干预工具。下面对上述问题做一个简单的总结:
- 问题一:图层未合并问题肉眼很容易识别出来,利用工具将冗余图层进行快速合并删除即可。
- 问题二:图层交叉问题肉眼不易识别,因此我们提供了检测工具,基于检测工具可以对设计稿中的交叉问题快速修复。
- 问题三:复杂背景问题肉眼不易识别,暂时也没有有效的检测工具,用户可以采用边干预边生成的方式生成DSL。
2.1.4 视图树生成
将扁平的数据源转化为树状结构的DSL,这个过程如果是人脑来做会怎么思考呢?先确定布局的整体结构是行布局或者列布局,然后再确定局部区域应该是什么布局结构,最后组装起来形成视图树。这个过程与递归算法类似,因此我们采用了递归算法作为算法的主框架,同时引入了“横竖切割+布局结构+模型评估”三大利器。
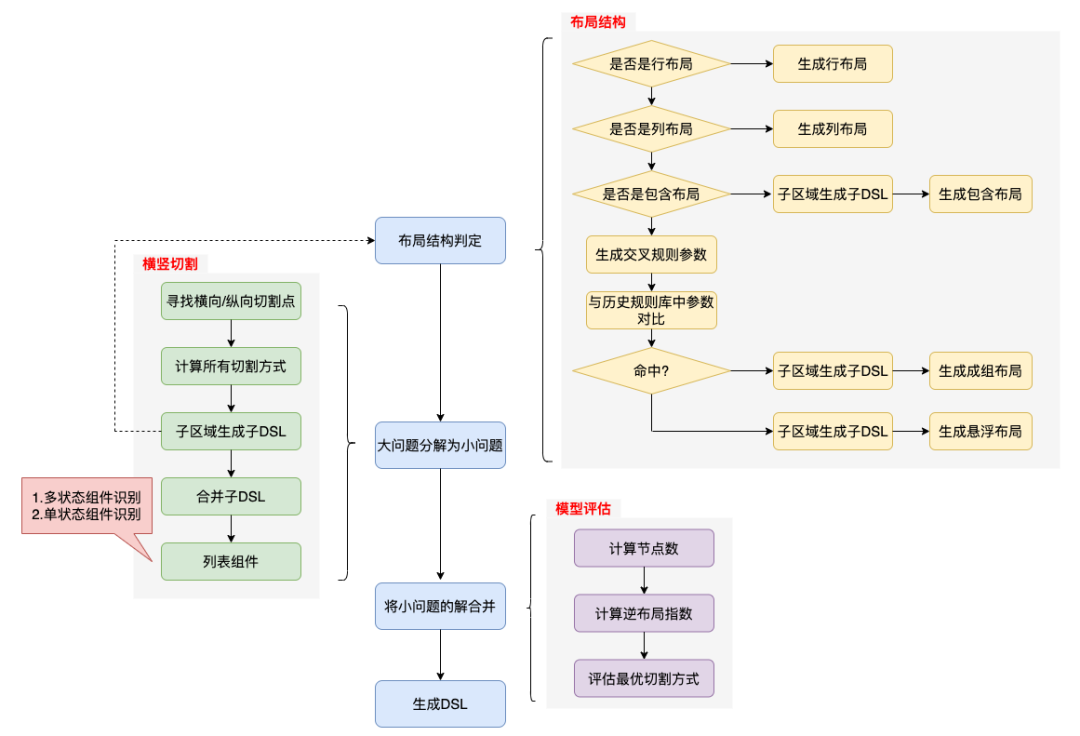
生成DSL时采用了整分的思路,即将大布局不断的切分成小布局,下面以动画的形式看一下简化过的DSL生成过程:
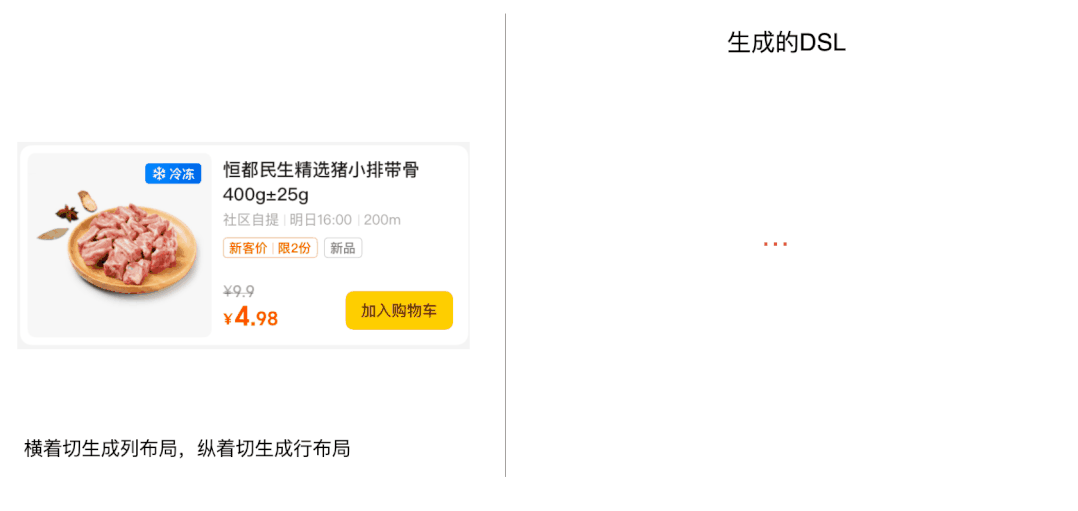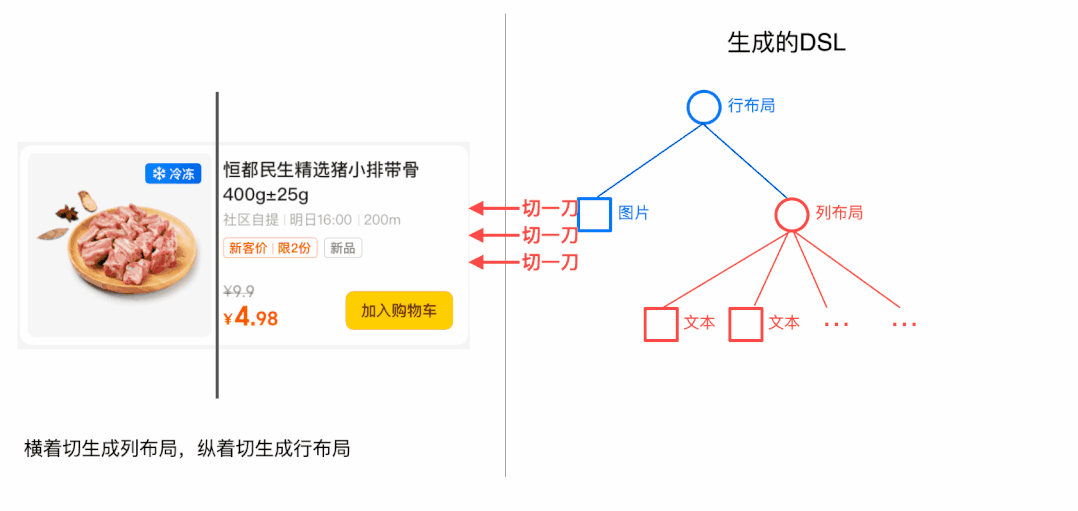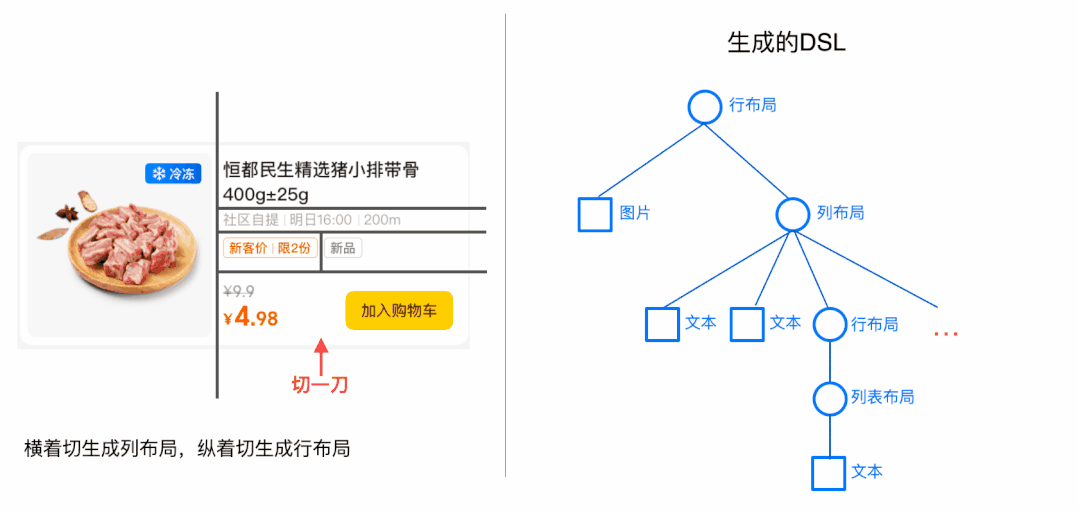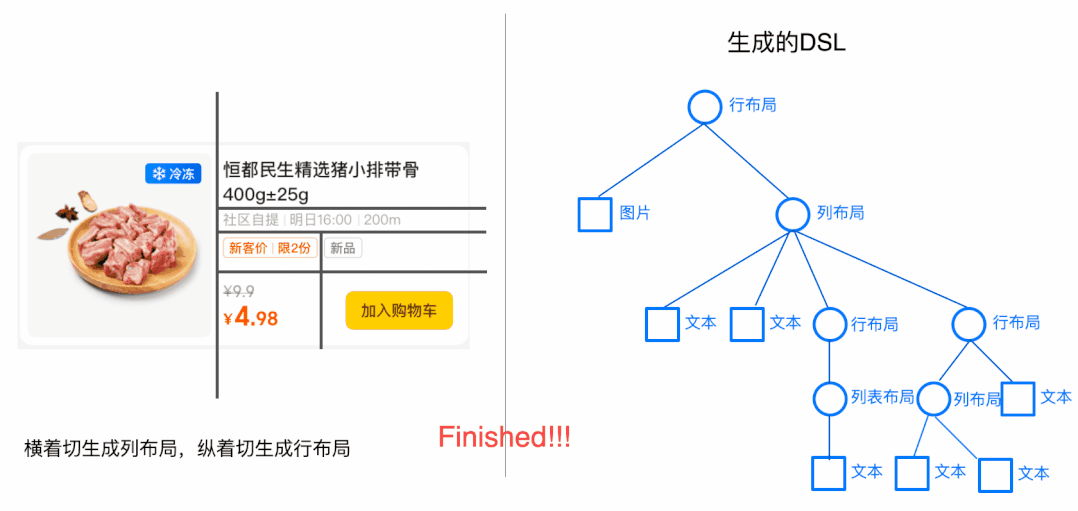
这里还要注意一个问题,当有3个切割点时,我们选择了直接将子区域切割成4个子区域,实际上我们可以只选择1个切割点进行切割,也可以选择2个切割点进行切割,当有N个切割点时,实际上存在(N的阶乘+1)种切割方式,具体选择哪种切割方式,我们会在利器三中讨论。
利器二:布局结构
每个图层都是一个矩形,为了生成布局结构只能依赖矩形的上下左右坐标信息。因此,对布局结构进行分类时,我们根据矩形与矩形之间的位置关系(相交、相离和包含关系)做了以下分类。
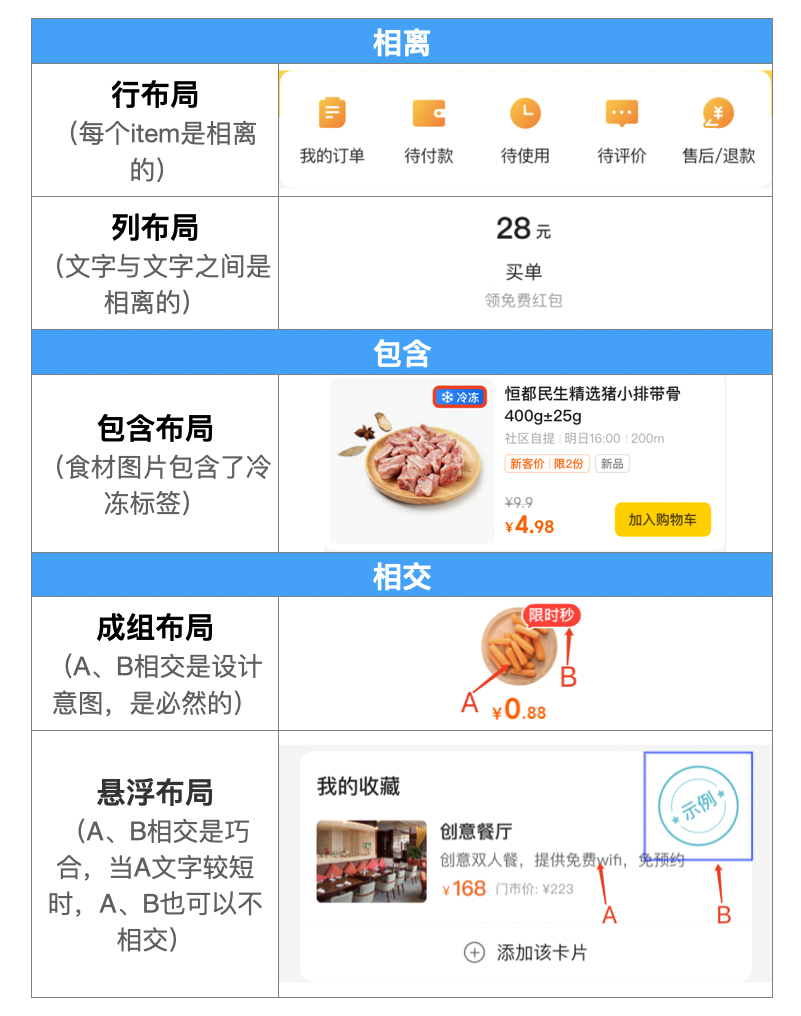
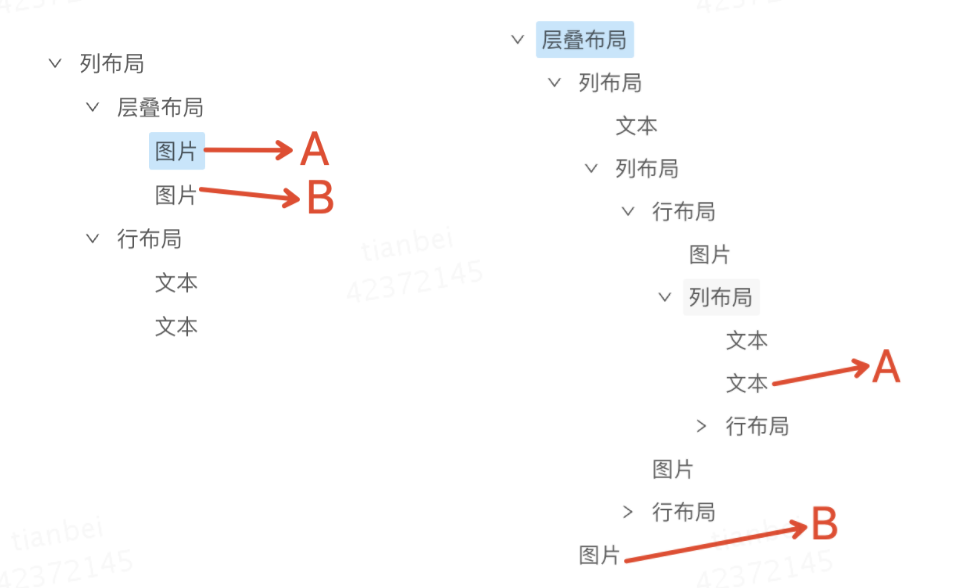
上图中,相离、包含比较好理解,为什么两个图层相交的时候,会有成组和悬浮两种类型的布局结构呢?我们看下上述成组布局、悬浮布局两个设计稿中分别标出了相交的元素A、B,它们在位置上的相对关系是一样的,都是A、B两个图层对应的矩形框发生了交叉。但是我们希望理想态的DSL视图树却有所差异,如下图所示:
- 成组布局中:A、B逻辑上是一个整体,交叉是必然的,最终DSL中A、B被层叠布局包含,层叠布局中没有其他元素。
- 悬浮布局中:A、B逻辑上不是整体,只是碰巧交叉了,最终DSL中A、B分别在不同的层级中。
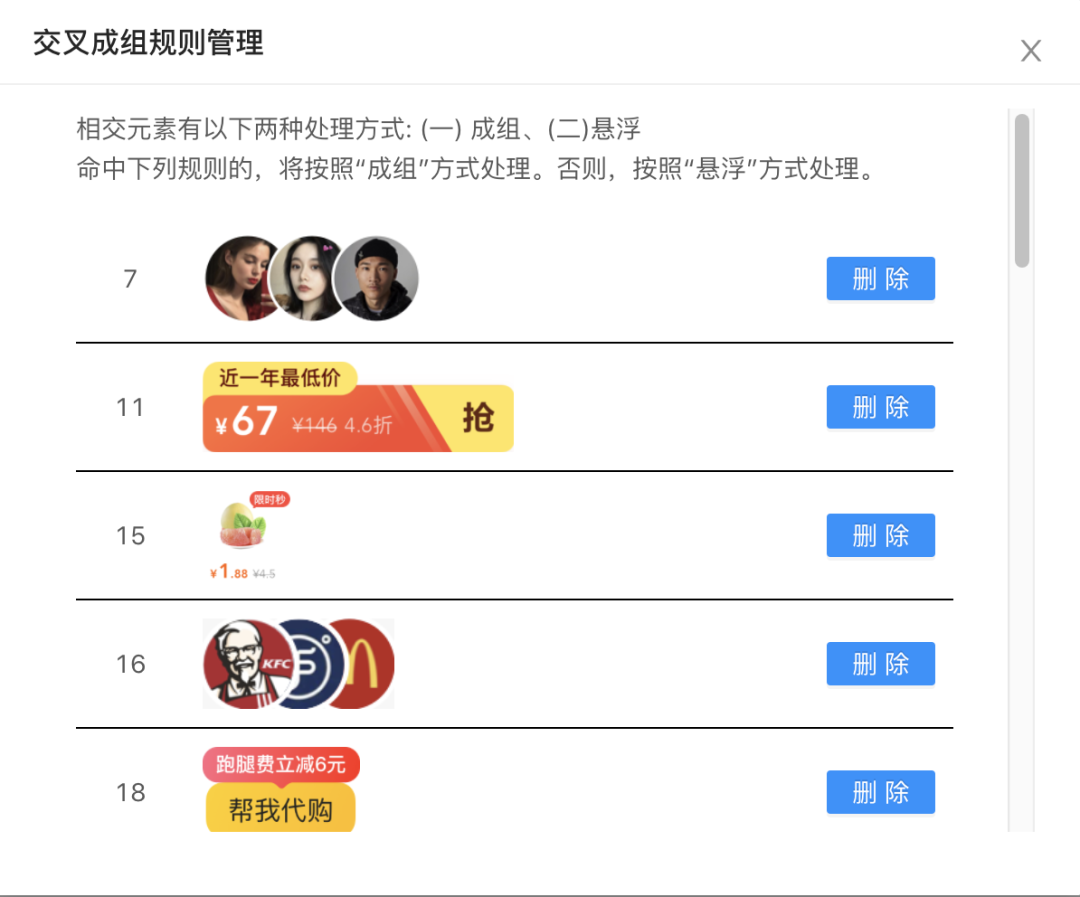
考虑到AI模型也是对规则的抽象,我们先搭建一套自定义识别规则。成组布局其位置信息是有规律可循的,例如:角标经常出现在右上角,标签经常出现在左上角,头像经常横向或者纵向交叉等,因此我们针对图层之间的位置关系构建了交叉模型,如下图所示:


利器三:模型评估
在介绍横竖切割时,可以看到当存在多个切割点时,对所有切割点同时进行了切割,但实际上算法在切割时复杂度会更高,当有三个切割点时,实际上有5种切割方式,每种切割方式都会生成一个DSL。既然有5种切割方式,那么到底应该选择哪一种DSL呢?模型评估算法就是用来解决这个问题的。
目前模型评估算法有两个指标:布局节点数和逆布局指数。
- DSL中布局节点数越少,切割方式越好。
- 逆布局指数用来评估DSL中的行列布局的合理程度,其中逆布局指数越大越不合理,反之,逆布局指数越小,切割方式越好。
以下图为例,看下视图不同切割方式下对应的模型评估方式:

2.1.5 列表布局
上一节介绍了基本的布局结构,虽然说这些布局结构已经可以描述所有的UI布局,但是与RD的编码习惯还是有一些差异。

在试验过程中,我们发现列表布局分为两种:单状态列表组件和多状态列表组件。上图中每一个item的布局结构都是一样的,我们称为单状态列表组件,再来看一下多状态列表组件(如下图所示),每个item有多种状态(选中态和非选中态),并且不同状态的布局结构不一致。

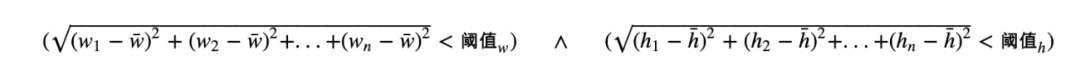
2.2 视图树转代码(DSL2Code)
DSL视图树只是生成代码的中间产物,还需要对DSL进行代码还原,DSL2Code主要包括两个步骤:属性推断、属性信息调整。
2.2.1 属性推断
属性推断包括两个部分:样式属性和结构属性。样式属性包括字体、背景色、圆角等可以直接通过数据源信息中获取得到的属性;结构属性包括大小、内外边距、主辅轴对齐等结构信息,这些信息无法从数据源中直接获取,所以结构信息的推断是这部分工作的重点。
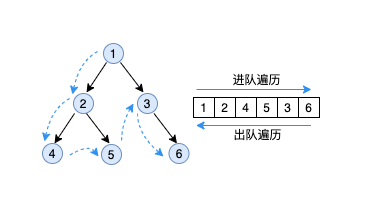
结构信息推断算法同样使用递归算法作为主框架,通过一次递归对所有元素进行两次遍历来完成结构信息的推断。如下图所示,在对DSL所有节点进行递归遍历时,把所有元素依次加入队列中,递归完成后,再把所有节点依次移出队列,这样一进一出便对所有元素完成了两次遍历,我们把这两次遍历称为进队遍历和出队遍历。
2.2.2 属性信息调整
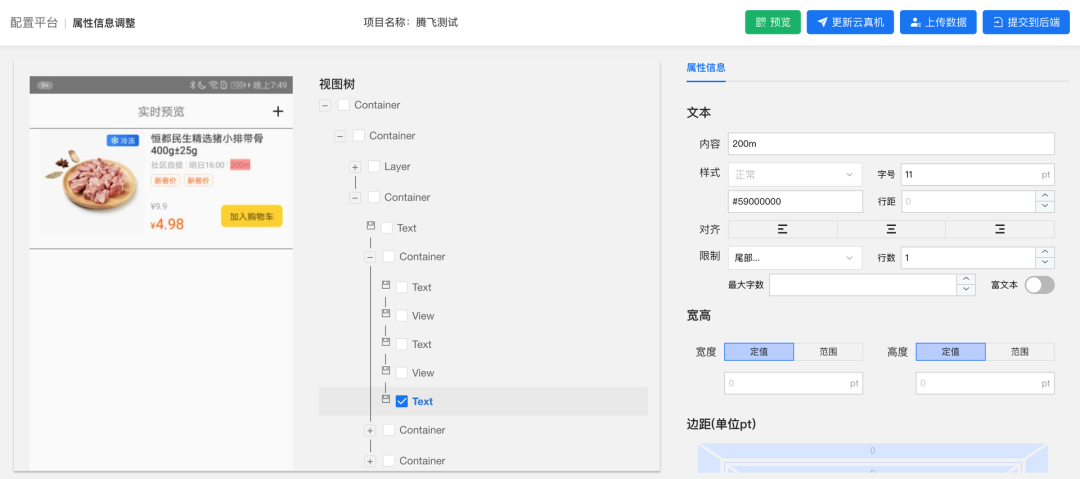
由于输入源是基于设计稿呈现的静态效果图,设计稿中每个元素缺失了真实的业务含义,同样的展示效果在不同的业务场景中会有不同的属性要求,对于这部分内容,我们无法从输入源中进行准确推断。为此,我们提供了可视化的属性信息调整功能来辅助代码生成,页面效果如下图所示,在这个页面可以对DSL中的所有节点属性进行查看和修改调整。
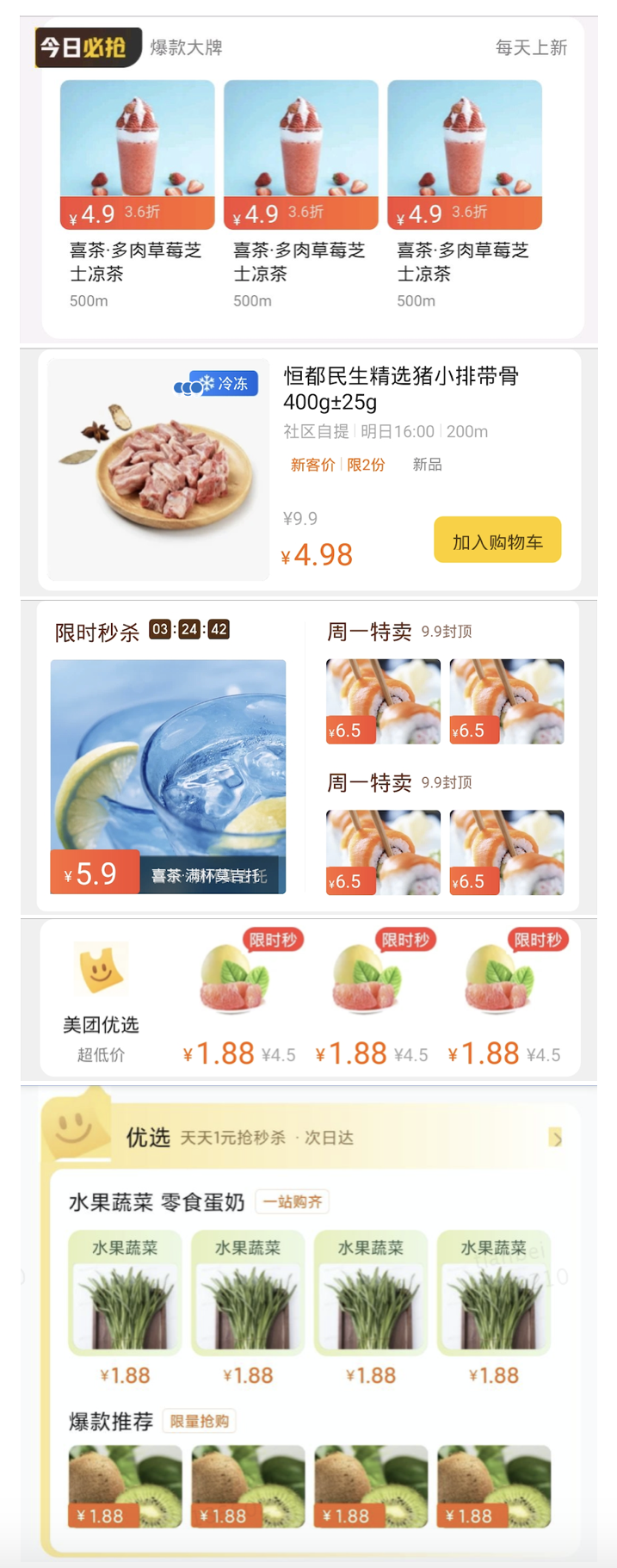
3 成果展示
下面是设计稿直接生成代码未经修改展示后的手机屏幕截图,可以看到取得了不错的还原效果: