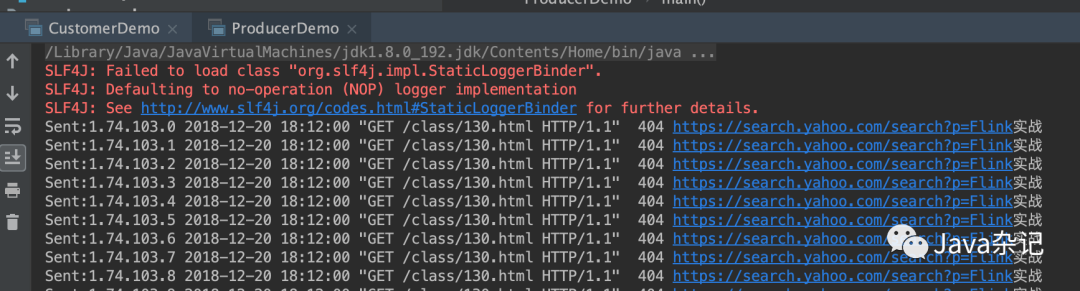
使用Java调用kafka入门
1.安装kafka

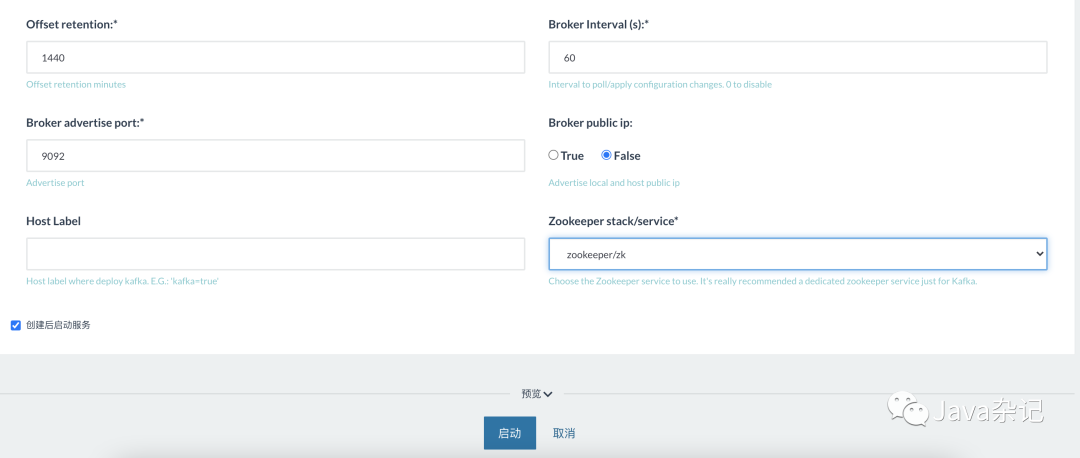
选择zk服务,点击启动,验证
telnet {ip} 9092#是否能够telnet通
创建topic
kafka-topics --zookeeper master01:2181 --create --topic liuhaihua --partitions 1 --replication-factor 1
2.引入pom
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>search-parent</artifactId>
<groupId>cn.maxap</groupId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>kafka</artifactId>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.0</version>
</dependency>
</dependencies>
</project>3.消费者
package cn.liuhaihua.kafka;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
public class CustomerDemo {
public static void main(String[] args) throws InterruptedException {
Properties properties = new Properties();
properties.put("bootstrap.servers", "10.42.139.232:9092");
properties.put("group.id", "group-2");
//session.timeout.ms:消费者在被认为死亡之前可以与服务器断开连接的时间,默认是3s 。
properties.put("session.timeout.ms", "30000");
//消费者是否自动提交偏移量,默认值是true,避免出现重复数据和数据丢失,可以把它设为 false。
properties.put("enable.auto.commit", "false");
properties.put("auto.commit.interval.ms", "1000");
//auto.offset.reset:消费者在读取一个没有偏移量的分区或者偏移量无效的情况下的处理
//earliest:在偏移量无效的情况下,消费者将从起始位置读取分区的记录。
//latest:在偏移量无效的情况下,消费者将从最新位置读取分区的记录
properties.put("auto.offset.reset", "earliest");
properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// max.partition.fetch.bytes:服务器从每个分区里返回给消费者的最大字节数
//fetch.max.wait.ms:消费者等待时间,默认是500。
// fetch.min.bytes:消费者从服务器获取记录的最小字节数。
// client.id:该参数可以是任意的字符串,服务器会用它来识别消息的来源。
// max.poll.records:用于控制单次调用 call () 方住能够返回的记录数量
//receive.buffer.bytes和send.buffer.bytes:指定了 TCP socket 接收和发送数据包的缓冲区大小,默认值为-1
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer(properties);
kafkaConsumer.subscribe(Arrays.asList("liuhaihua"));
while (true) {
ConsumerRecords<String, String> records = kafkaConsumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, value = %s", record.offset(), record.value());
System.out.println("=====================>");
}
}
}
}
4.生产者
package cn.liuhaihua.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class ProducerDemo {
public static void main(String[] args){
Properties properties = new Properties();
//broker的地址清单,建议至少填写两个,避免宕机
properties.put("bootstrap.servers", "10.42.139.232:9092");
//acks指定必须有多少个分区副本接收消息,生产者才认为消息写入成功,用户检测数据丢失的可能性
//acks=0:生产者在成功写入消息之前不会等待任何来自服务器的响应。无法监控数据是否发送成功,但可以以网络能够支持的最大速度发送消息,达到很高的吞吐量。
//acks=1:只要集群的首领节点收到消息,生产者就会收到来自服务器的成功响应。
//acks=all:只有所有参与复制的节点全部收到消息时,生产者才会收到来自服务器的成功响应。这种模式是最安全的,
properties.put("acks", "all");
//retries:生产者从服务器收到的错误有可能是临时性的错误的次数
properties.put("retries", 0);
//batch.size:该参数指定了一个批次可以使用的内存大小,按照字节数计算(而不是消息个数)。
properties.put("batch.size", 16384);
//linger.ms:该参数指定了生产者在发送批次之前等待更多消息加入批次的时间,增加延迟,提高吞吐量
properties.put("linger.ms", 1);
//buffer.memory该参数用来设置生产者内存缓冲区的大小,生产者用它缓冲要发送到服务器的消息。
properties.put("buffer.memory", 33554432);
//compression.type:数据压缩格式,有snappy、gzip和lz4,snappy算法比较均衡,gzip会消耗更高的cpu,但压缩比更高
//key和value的序列化
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//client.id:该参数可以是任意的字符串,服务器会用它来识别消息的来源。
//max.in.flight.requests.per.connection:生产者在收到服务器晌应之前可以发送多少个消息。越大越占用内存,但会提高吞吐量
//timeout.ms:指定了broker等待同步副本返回消息确认的时间
//request.timeout.ms:生产者在发送数据后等待服务器返回响应的时间
//metadata.fetch.timeout.ms:生产者在获取元数据(比如目标分区的首领是谁)时等待服务器返回响应的时间。
// max.block.ms:该参数指定了在调用 send()方法或使用 partitionsFor()方法获取元数据时生产者阻塞时间
// max.request.size:该参数用于控制生产者发送的请求大小。
//receive.buffer.bytes和send.buffer.bytes:指定了 TCP socket 接收和发送数据包的缓冲区大小,默认值为-1
Producer<String, String> producer = null;
try {
producer = new KafkaProducer(properties);
for (int i = 0; i < 1000; i++) {
String msg = "1.74.103."+i+"\t"
+"2018-12-20 18:12:00"+"\t"+"\"GET /class/130.html HTTP/1.1\""+"\t"+"404"+"\t"+"https://search.yahoo.com/search?p=Flink实战";
producer.send(new ProducerRecord<String, String>("liuhaihua", msg));
Thread.sleep(500);
System.out.println("Sent:" + msg);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
producer.close();
}
}
}5.运行代码,观察console 输出