网易轻舟对 CIlium 容器网络的探索和实践

2019 年网易轻舟使用 sockmap+sk redirect 来优化轻舟 Service Mesh 的延迟,2020 年开始,我们逐步对 eBPF Service、Cilium NetworkPolicy,Cilium 容器网络进行实践,到 2021 年中旬,网易轻舟对外部客户提供了 Cilium 整体解决方案。
本文会深入介绍 Cilium,并澄清一些认知误区,然后给出网易轻舟是如何使用 Cilium 的。目前国内这方面深入解析材料较少,如果您也正在探究,希望这篇文章能给您带来帮助。
1
eBPF 容器网络探索背景
目前容器网络方案仍然呈现着百花齐放的态势,这主要是由于不同的 CNI 各有优势。开源的原生 CNI 具备较广的使用场景,即插即用。其中支持 overlay 方式的几个方案(openshift-sdn、flannel-vxlan、calico-ipip),能更好地适配 L2/L3 的网络背景,而 underlay 方式的几个方案(calico-bgp、kube-router、flannel-hostgw),则在性能上更趋近于物理网络,在小包场景中性能明显好过 overlay 类型方案。此外,许多主流云厂商基于还会自建 VPC 能力,实现 VPC-based CNI ,这类 CNI 与集群交付场景深度耦合,但也赋予了容器网络 VPC 的属性,具备更强的安全特性。
此外,业界还有大量针对 CNI 或四层负载均衡的优化措施,例如:
- 优化封装协议,基于 vxlan 有更好的兼容性,基于 ipip 协议则能提升一定的带宽能力(部分云厂商如 AWS 并不支持 ipip 协议的包)
- 使用 IPVS 替换 kube-proxy 解决大规模环境里,Service 带宽降低和数据路径下发时间变长
- 使用 eBPF 技术来加速 IPVS,进一步降低延迟,提升 Service 数据路径性能
- 利用 multus 组合 CNI 多网络平面,并利用 SR-IOV 技术做定向硬件加速
- 虚拟网卡时使用 ipvlan 替代 vethpair,提升性能
总的来说,通过方案整合和调优的方式进一步满足了业务发展的需求,但是当前流行的 CNI 支持场景要么是不够通用,要么在高 IO 业务下存在性能问题,要么不具备安全能力,要么因 Kubernetes service 性能问题,集群规模上不去。因此我们想使用 eBPF 技术实现一套无硬件依赖的高性能、高兼容性的容器网络解决方案,这个方案解决的问题如下:
- 解决 kube-proxy 性能问题
- 优化数据路径降低业务端到端的延时解决高 IO 业务的性能瓶颈
- 降低 Service Mesh 路径延迟
- 支持链路加密和高性能安全策略
- 支持无成本集成到主流的容器网络方案
基于 eBPF 技术做的比较好的是 Cilium,所以 2019 年末开始,我们就开始了相关的探索。
2
Cilium 功能解析
Cilium 功能解析,从功能列表,亮点功能,功能限制,三个角度进行阐述。
(1)功能列表
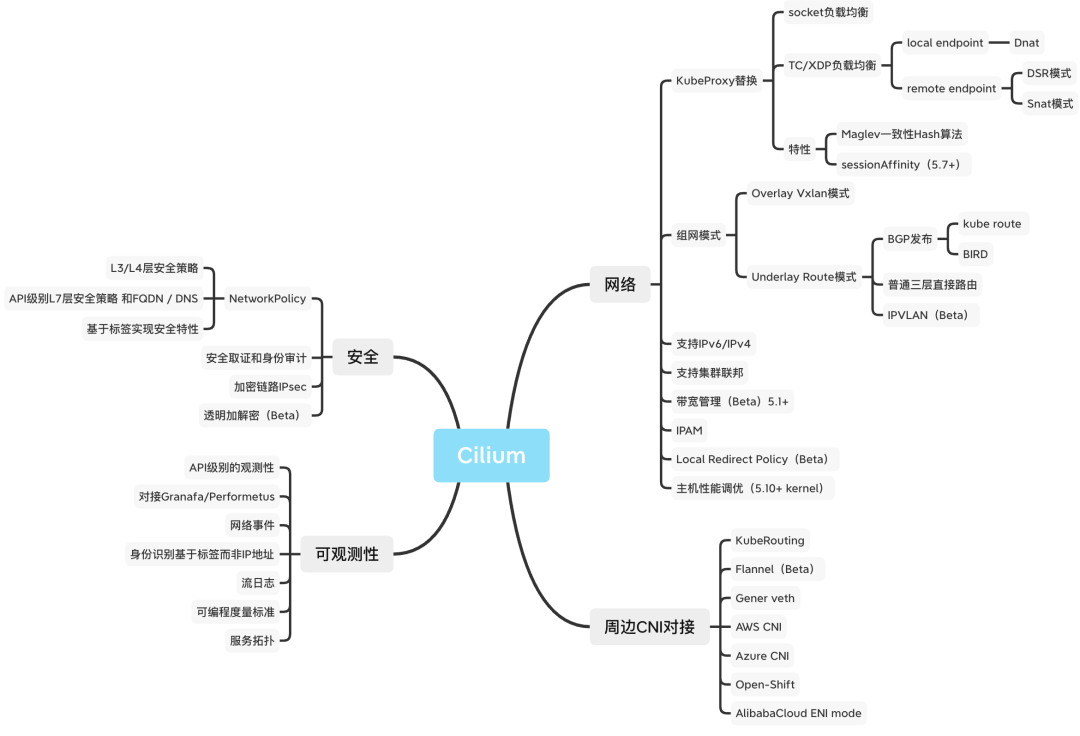
(2)亮点功能
Cilium 支持的功能更像一个容器网络功能的复合体,其具有 Underlay 路由模式、Overlay 模式,也具有链路加密能力,此外其独特能力如下:
- 带宽管理
- 集群联邦
- IPVLAN 模式
- 七层安全策略
- DSR 模式保留源地址,节省带宽,避免 SNAT 端口耗尽问题
- Kubernetes Service 性能调优,支持 Maglev 算法
- XDP 性能调优,高性能南北向 Service
- Local Redirect Policy
- 流量可见性,细粒度流量控制,用于审计
- 高性能更能适配高带宽的网卡(eg: 50G、100G)
从功能范畴看,其亮点功能有安全、性能、功能三个方面,其有一部分亮点能力是 Cilium 社区对容器网络最佳实践的功能支持,有一部分能力是来源于 eBPF 能力的创新,所以 Cilium 是一个复合品;社区思路可以一句话概括为 “在容器网络领域,大家有的功能我也有,而且我性能更好,此外我借助 eBPF 能力从内核侧创新了大部分功能”。
(3)功能限制
Cilium 带来的技术红利让不少国内外公司去实践,国内公司来说,除网易轻舟外,我们看到腾讯、阿里、爱奇艺、携程等同行在生产环境中落地 Cilium。虽然 Cilium 通过 eBPF 给容器网络提供了创新机会,但是也带来了两点问题,这两点问题让绝大部分用户持观望态度。
问题 1: eBPF 相比 iptables 调试难度更大,技术要求较高
iptables 存在内核已经存在几十年了,相关技术栈的开发者多,已经被广泛的接受,而 2014 年 eBPF 概念才被提出,2018 年依托于 eBPF 的容器网络 Cilium 诞生
eBPF 技术研发难度会大些(报错调试日志不明显、整体技术把控的人才少)
从灵活性角度来看,Iptables 配合策略路由只需要几条命令就可以编排数据路径,更简单些,eBPF 需要编写代支持新的数据链路需求复杂度会高些
面临上述问题,但是我们想法是:
Iptables 技术栈的确是更加通用的,但也搞不定某些业务场景,比如:
- 安全性较高的 Kubernetes 集群,需要强流量日志审计的功能的业务
- 存在业务高 IO,低延时业务,或者 Service 规模大,且业务短链接较多,集群规模较大,需要节省南北向网络带宽等业务
我们认为 eBPF 技术栈处于发展期、周边工具在逐步完善中,高复杂度会带来额外的人力成本,如果业务需求强于克服 eBPF 的技术的人力成本,外加上有技术厂商支撑,某些对性能和安全要求较高的场景选型 eBPF 技术问题也不大。
问题 2: 内核版本要求高根据
CIlium 社区,基于 eBPF Kubernetes 容器网络需要内核允许最小版本 4.9,Calico 支持的 eBPF 数据面要求内核至少 5.3 版本。
面临上述问题,我们经历是,前两年内核版本的限制属于很大的阻力,当前于网易轻舟支撑容器云平台来说,5.4 内核逐步在铺开使用了,因为我们需要更强的 eBPF 能力进行监控和更完整干净的 CGROUPv2 特性,我们希望对业务更细粒度的分资源优先级,更强的资源隔离能力(IO 隔离),防止业务之间互相影响,增强容器平台的可用性。而 5.4 内核作为基础内核跑 Cilium eBPF 功能够用。
3
Cilium
数据面看完 CIlium 功能后,我们看下这些功能的数据面是如何实现的,因此后文,会先深入解析 Cilium 数据面的实现,并揭露其高性能的原因,最后再澄清一些常常被误解的说法。
(1)数据面路径首先我们知道:
- Cilium 数据面和 Kernel 版本有一定关系,不同内核支持的数据面路径不同,上层的数据面实现也有一定差异。
- Cilium 数据面和功能开关有一定关系,不同的功能开关的开启和关闭,会影响数据路径的转发行为。
因此,选定 Kernel5.4,Kernel5.10 来进行探讨,同时打开 kube-proxy 卸载,目前只开启 IPv4 协议,其它数据面采用 CIlium 的默认值,选择 Cilium1.10 版本,下文主要以图示和说明的方式进行表述, 因篇幅限制,选择路由模式、VETH 接口类型进行探讨。
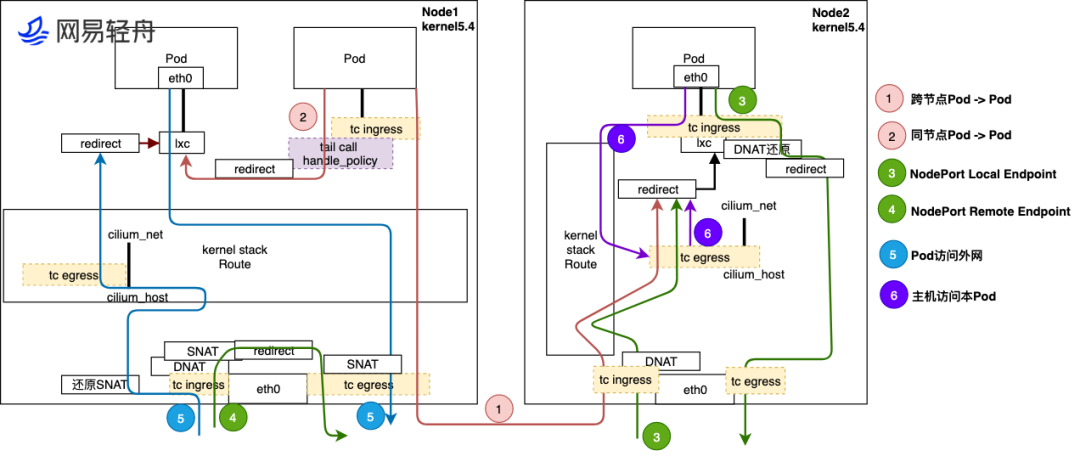
1. 跨节点 Pod -> Pod
Pod 发出流量后,经过宿主机的 veth lxc 接口的 tc ingress hook 的 eBPF 程序处理后,送给 kernel stack 进行路由查找,然后经过物理口 eth0 的 tc egress 发出到达 Node2 的 eth0
Node2 接收流量后,先经过 Node2 物理口 eth0 的 tc ingress hook 的 eBPF 处理,然后送给 kernel stack 进行路由查找,发给 cilium_host 接口,流量经过 cilium_host 的 tc egress hook 点后,最后 redirect 到目的 Pod 的宿主机 lxc 接口上,最终送给目的 pod。
2. 同节点 pod->pod
pod 发出流量后,流量会发给本 Pod 宿主机 lxc 接口的 tc ingress hook 的 eBPF 程序处理,eBPF 最终会查找目的 Pod,确定位于同一个节点,直接通过 redirect 方法将流量直接越过 kernel stack,送给目的 Pod 的 lxc 口,最终将流量送给目的 Pod。
3. 访问 NodePort Local Endpoint
Client->NodePort,流量从 Node2 的 eth0 口进入,经过 tc ingress hook eBPF Dnat 处理后,继续将流量发给 kernel,kernel 查路由转发给 cilium_host 接口,cilium_host 接口的 tc ingress 收到流量后直接 redirect 流量到目的 pod 的宿主机 lxc 接口上,最终送给目的 pod。
回程流量从 Pod 出来,经过 veth 宿主机侧接口口 lxc 的 tc ingress hook eBPF 反 Dnat 处理,该 eBPF 程序直接将流量从定向到物理口,该过程不经过 kernel,最终在经过物理口的 tc egress hook 点后发给 Client。
4. 访问 NodePort Remote EndPoint
Client 访问 NodePort,流量发给 Node1 接口 eth0 ,经过 tc ingress hook eBPF 先进行 Dnat 将目的地址变成目的 Pod 的 IP 和 Port,后进行 Snat 将源地址变成 Node1 物理口的 IP 和 Port,最后将流量 redirect 到 Node1 的 eth0 物理口上,流量会经过 tc egress hook 点后发出。
5.Pod 访问外网
Pod 发出流量后,经过宿主机的 veth 的 lxc 口的 tc ingress hook 的 eBPF 程序处理后,送给 kernel stack 进行路由查找,确定需要从 eth0 发出,因此流量回发给物理口 eth0,而经过物理口 eth0 的 tc egress eBPF 程序做个 Snat,将源地址转换成 Node 节点的物理接口的 IP 和 Port 发出。
从外网回来的反向流量,经过 Node 节点物理口 eth0 tc ingress eBPF 程序进行 Snat 还原,然后将流量发给 kernel 查路由,流量流到 cilium_host 接口后,经过 tc egress eBPF 程序,直接识别出是发给 Pod 的流量,将流量直接 redirect 到目的 Pod 的宿主机 lxc 接口上,最终反向流量回到 Pod。
6. 主机访问 Pod
主机访问 Pod 流量使用 cilium_host 口发出,所以在 tc egress hook 点 eBPF 程序直接 redirect 到目的 Pod 的宿主机 lxc 接口上,最终发给 Pod。
反向流量,从 Pod 发出到宿主机的接口 lxc,经过 tc ingress hook eBPF 识别送给 kernel stack,回到宿主机上。
针对于 XDP 情况没有标注到上面流程中,其实 XDP 过程和 tc ingress 处理方式一致,XDP Hook 要比 tc ingress 更靠近收包流程,这个时候 skb 还没有形成,因此性能更高,使用 xdp 特别适合 NodePort、HostPort、External IP 等这种南北向 Service 流量加速,从社区测试结果看,大概 3-4 倍 PPS 提升。
上面介绍是基于 5.4 内核的,在 5.10 内核以后,Cilium 新增了 eBPF Host-Routing 功能,该功能更加速了 eBPF 数据面性能,新增了 bpf_redirect_peer 和 bpf_redirect_neigh 两个 redirect 方式,bpf_redirect_peer 可以理解成 bpf_redirect 的升级版,其将数据包直接送到 veth pair Pod 里面接口 eth0 上,而不经过宿主机的 lxc 接口,这样实现的好处是少进入一次 cpu backlog queue 队列,该特性引入后,路由模式下,Pod -> Pod 性能接近 Node -> Node 性能,同时 Cilium 数据面路径发生了较大的变化,如下图,具体变化直接对比看图即可,篇幅有限,重点说明两点变化:
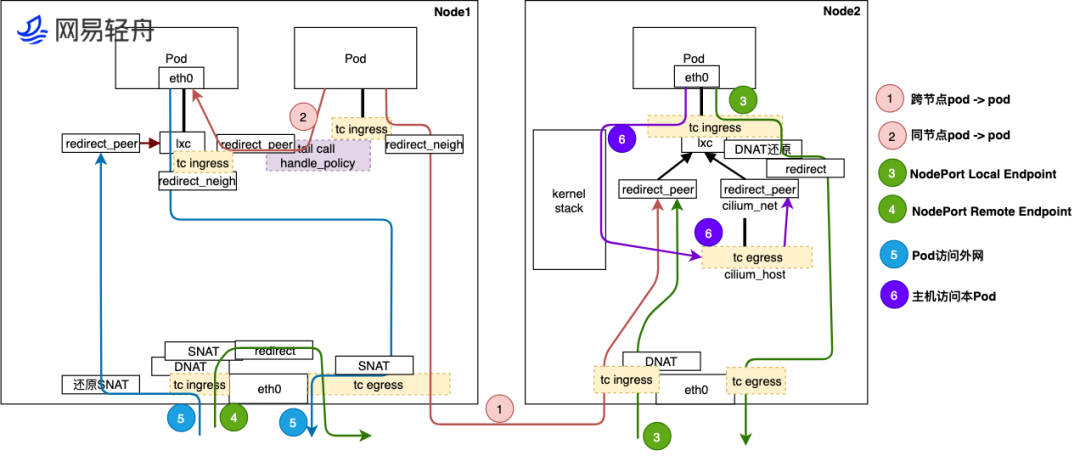
1. 除了 host->Pod 外,所有路径都是经过接口跳着走的,最大变化是不再经过 Kernel 转发处理,也意味着来回流量路径不再经过 kernel 的 Netfilter 框架,kernel tc 等模块,大大提升了转发性能;
2.redirect_peer 特性专用于 veth pair 类型接口,因为流量被直接重定向到 Pod 里面的接口,所以在宿主机 lxc 口上无法抓到进入 Pod 的流量,因 tcpdump 抓包点在 tc ingress hook 之前,所以可以抓到出 Pod 未经过 eBPF 处理的流量。
(2)高性能的原因
高性能可分为如下两个方面
数据路径延迟低,带宽高
数据路径低延迟,高带宽原因是,其采用技术创新短路传统了 Kernel 框架,减少了数据包转发所需的指令。这些技术包括,eBPF 夹持下的 redirect、redirect_peer、redirect_neigh、XDP、sockmap、sk redirect 等技术。
Kubernetes service 数据面性能高,Service 规模扩大,控制面下发时间变化不大。
Kubernetes service 数据面性能高,分为集群内访问的 socket LB 技术,该技术使得不需要做数据包 skb 更改,直接将容器平台内部访问 service 流量转变成直接访问 Pod 效果,访问 Pod 路径也是经过加速的。南北向 Service(NodePort、external IP、HostPort)性能高的原因是其支持 Native XDP 加速,外加上路径跳转优化,对于 Remote Pod 的 Service 场景,还支持了 DR 模式,从逻辑上减少一跳路径。
Kubernetes service 控制面下发性能,这块主要采用了 eBPF map 技术,该技术实质会采用 Hash 方法,摆脱了变动 Service 就要全量下发 iptables 的问题,因此控制面下发时间随着 Service 规模的变大,策略更新延时变化不大。
(3)概念澄清
IPtables 实现 Service 的性能高低是要看场景的
基于 Iptables 实现的 Service,KubeCon Talk “Scale Kubernetes to Support 50,000 Services” 有一个特定的测量结果:
这是 Kubernetes 服务转发的瓶颈,部署 5,000 个 Services(40k rules)时吞吐量降低了约 30%,而部署 10,000 个服务则降低了 80%(性能相差 6 倍)。同样 5,000 个 Services(40k rules)的规则更新花费了 11 分钟。
但是 Iptables 是线性规则匹配和规则跳查的,但是这个慢速过程只发生在新建阶段,一旦会话建立好,后续流量走 CT 即可,所以 Service 到达一定规模,对于短链接业务延迟会有较大的影响,从容忍度角度看,这个性能降低的影响,对于某些业务是可容忍的。
此处不讨论 5000 个 Service 是否在生产环境真的需要 11 分钟(这个和环境,endpoint 规模有关),只讨论业务容忍度问题,业务对于 Service 规则更新分钟级别生效的容忍度会差些,因为 Service 规则更新慢会导致经过 Service 流量仍然发给异常的 Pod,导致业务失败。
Kubernetes Service 所带来的性能问题,也不是说一定会成为集群的性能瓶颈,因为如果选择不使用 Kubernetes Service 数据路径,或者甚至不使用 CNI,也就没有这个问题。
Cilium XDP 是有限制的
首先通用的 XDP 性能提升有限,Native XDP 性能较符合预期,但 XDP 使用是有限制的,当前其还无法支持 Bond 口,这块网易轻舟的实践方法是物理机器不做 Bond,直接将两个接口通过 ecmp 等价路由方向做 HA,使用 XDP 对物理口加速南北向的 Service,并选定若干台 Node 节点,直接通过 BGP 将 Service IP 直接发布出去,直接省去了南北向集中式的四层 LB。
4
Cilium 控制面
Cilium 控制面,从控制面框架,数据面下发过程来展开,控制面框架能对 CIlium 控制面有一个全局意识,数据面构建过程可以明确数据面如何搭建的。
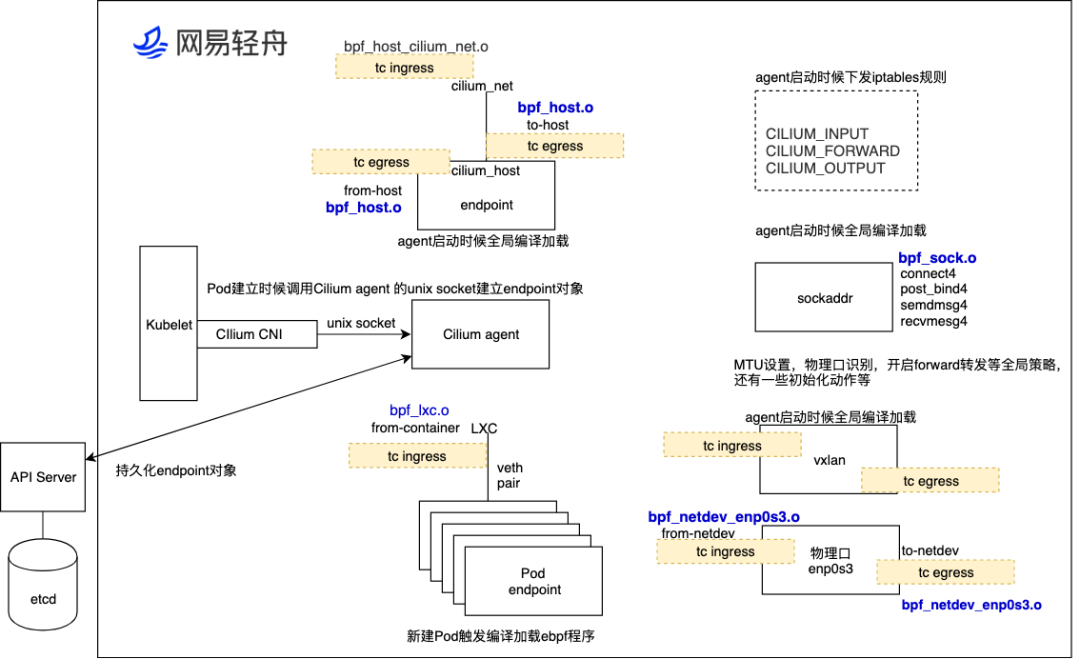
首先明确事情是,CIlium agent 负责所有数据路径 eBPF 加载,网络连通的配置管理,负责将数据面搭建起来,是控制面的核心组件。而 Cilium agent 工作可按照加载时机分为两部分,一部分在于启动时候加载,一部分在于创建 Pod 后或者说读取到 Pod 所对应 endpoint 对象后加载。
启动时候加载的对象一般是数据面骨架,这部分和数据面框架有关,如下
- cilium_host /cilium_net 接口建立,以及 eBPF 程序加载
- 全局 socket LB、vxlan 口、物理口的 eBPF 规则的编译下发,少量的 IPtables 规则的下发
- MTU 设置,物理口识别,开启接口的 Forward 转发、Kernel eBPF 能力探测,并更具探测能力以及预配置选项进行 eBPF 功能开启等
创建 Pod 加载,用于给创建 Pod 编译加载 eBPF 程序,一般用于加载位于宿主机侧 veth 口的 tc ingress
为了控制 eBPF 程序的编译和加载,Cilium 使用自己的 Cilium endpoint 进行管理,Pod 建立过程中,Kubelet 会调用 Cilium cni 创建 Pod veth 口,其中 Cilium cni 会通过 unix socket 调用 cilium agent 来创建 endpoint 对象,这些对象含有丰富相关信息(eg mac 地址、接口名称、加载策略名称、policy 规则等),这些对象会通过 API Server 被下发到 etcd 中记录起来,Cilium agent 根据这些对象编译加载 eBPF 程序。
为了适配支持不同内核,Cilium agent 会自己探测是否开启某功能,如果默认内核不支持则起自动回退到能支持的内核特性,为了更大的功能灵活性,Cilium eBPF 有设计了许多数据面的配置开关,非常零碎,这些配置选项通过 cilium-config map 管理,Cilium agent 会将此 map 挂载成路径,同时根据配置的开关,动态形成 eBPF 程序的编译宏,通过该编译宏来编译 eBPF 程序,进而生效和关闭某些数据面功能。
5
网易轻舟 Cilium 的实践
阅读上文后心中会有一个整体框架,再看网易轻舟对 CIlium 实践思路,以及实践过程中遇到的一些问题和解决办法,就比较清晰了。
(1)网易轻舟基于 CIlium 的实践思路
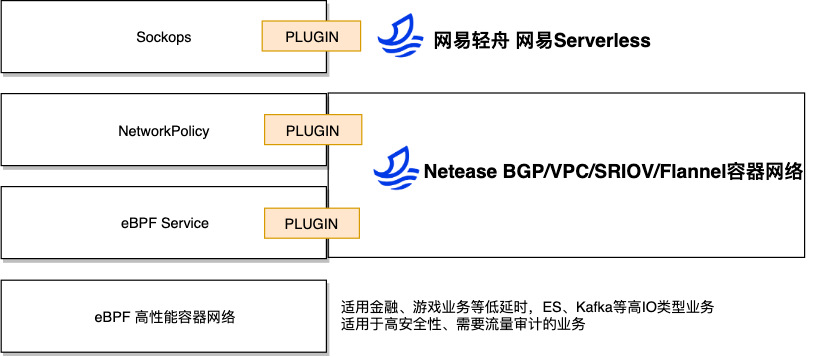
简单概括我们的实践思路就是 “3+1”,其中“3”指 3 个插件,“1” 指 1 个 Cilium eBPF 容器网络 CNI,我们的思考是:
- Sockops 主要是加速轻舟服务网格产品、轻舟 Serverless 产品的 Sidecar 场景,降低服务网格延时 9%,QPS 提升 20%,提升轻舟 Serverless 产品 Knative QueueProxy 和业务容器之间的访问 QPS 20%
- NetworkPolicy 插件,支持插入主流的 CNI 和 Netease 容器网络,该插件主要是使用 eBPF 实现安全策略,性能相比较与 IPtables 更好,同时配合轻舟 Hubble 组件来做集群的流量审计,主要用于金融业务。
- eBPF Service 插件,该插件用于替换 kube-proxy,适用于有 kube-proxy 性能需求的业务场景,当前该组件我们优先支持了 Cluster IP,南北向的 Service 和容器网络类型关联度较大,我们只支持了 5.10 内核的路由场景。
一开始我们想直接推动老的集群使用使用 Cilium 容器网络,但是发现这块难度较大,因为并不是所有的业务都需要高性能的容器网络,从 0-1 的替换也不合适,但是我们的业务方对不同的功能特性是有需求的,所以我们将相关功能抠出来插入到当前容器网络场景,满足业务需求。
对于新的 Kubernetes 集群,我们推动使用 CIlium 容器网络,2021 年上半年,我们将 Cilium CNI 落地了到了大规模使用 Kafka 和 ES 的高 IO 场景的新业务集群,我们使用 kernel5.4,并且将 eBPF Host-Routing 所需要的 bpf_redirect_peer 和 bpf_redirect_neigh eBPF helper 移植到 Kernel5.4。
(2)实践过程中遇到的问题和解决办法举例
Cilium Chaining 的适配问题
CIlium Chaining 方式做 kube-proxy 卸载,低于 5.10 的 Kernel 内核情况下,对于南北向类型的 Service 来说,NodePort 流量不通,这个问题是由于 Node ->Pod 经过 kernel 转发,Pod -> Node 直接走 eBPF redirect 到物理口,导致了来回路径不一致,导致三次握手的 ACK 数据包被内核的 iptables 状态检查( --ctstate INVALID -j DROP)丢弃,而 5.10 内核没有该问题, 因为 5.10 内核是从接口之间来回跳转的,不会经过 kernel 转发路径,我们的做法是通过高版本内核来解决此问题。
数据链路还不够灵活
在私有云场景,其数据链路的需求是多种多样的,业务 Pod 某些流量有定制的数据路径要求,但是 eBPF 程序往往需要做额外的开发才能支持,这对业务来说都是时间成本,因此我们抽象了此种场景,支持将目标流量直接打上 mark 送给 Kernel,Kernel 协议栈通过 IPtables 和策略路由配合起来快速实现业务定制路径,通过此种方法满足业务快速迭代的需求,而后我们再根据通用性程度选择是否完全通过 eBPF 技术实现。
网络问题定位困难
CIlium 场景下,特别是使用 eBPF 后,其数据包流量是来回跳转的,针对于非常特殊场景,有时候走内核,有时候不走内核,非常容易导致网络不通,所以我们通过 eBPF 做了一个 tcp packet 抓取工具,该工具通过 kprobe 到内核关键收发包函数和 iptables ,来进行流量抓取,同时丰富了 eBPF 数据包 trace 点,配合 Hubble 来快速定位网络问题。
生产环境内核版本低
Sockops 的支持
我们在 2019 年开始使用 socket 短路方式降低服务网格延迟,但是当时内核 4.19.87 还没有完全支持 sockmap+sk redirect,所以我们将内核 patch 回合了一些,达到我们的使用需求,这里额外说明的是,针对于 Sockops 功能,特别是用于 Service Mesh 场景,该场景下我们采用 127.0.0.1 进行业务容器和 Sidecar 的互通,Cilium 的实现的 local redirect policy 默认情况下是没有做 NS 隔离的,这样做会导致数据面冲突,所以对于 sock_key 我们额外加入了 NS 信息,这样同的 NS 内部,sock 重定向业务的五元组相同也不会出现冲突。
高版本内核特性和合入
为了使用高性能数据路径,我们将 bpf_redirect_peer 和 bpf_redirect_neigh patch 移植到 kernel5.4,开启 eBPF Host-Routing 功能。