MySQL索引(深入浅出)
引言
索引的作用就是为了加快搜索,计算机要处理的数据非常复杂,为了快速检索多种多样的数据,聪明的程序员们就发明了各种类型的索引。
常用数据结构
常用来做索引的数据结构有:hash、链表、跳表、B+tree、红黑树、LSM-tree、Trie树等等。有这么多的数据结构,我们在开发一款数据库的时候该如何选择呢?我认为最主要的是考虑以下几个问题:
1.查询的时间复杂度和稳定性
2.插入和删除索引的时间复杂度
3.能否有效减少磁盘IO
hash表,在等值查询的时候,时间复杂度是O(1),表现优异,但是hash表通常是无序的,在做范围查询的时候,就不适合了。
链表,分有序链表和无序链表,无序链表不太适合做索引,因为他的查询效率不高。有序链表在做等值查询的时候平均时间复杂度是O(n),范围查询的表现也非常不错,对磁盘顺序读支持友好。
跳表是相对复杂一点的数据结构,下图是一个跳表的示意图,它的最下层是有序链表如下图的L3,从有序链表中每间隔一部分节点挑选一个节点上移,组成一个新的链表L2,然后重复次动作形成L1。这样的好处是减少查找的时间复杂度,但是带来的问题是,插入和删除的时间复杂度会提高。
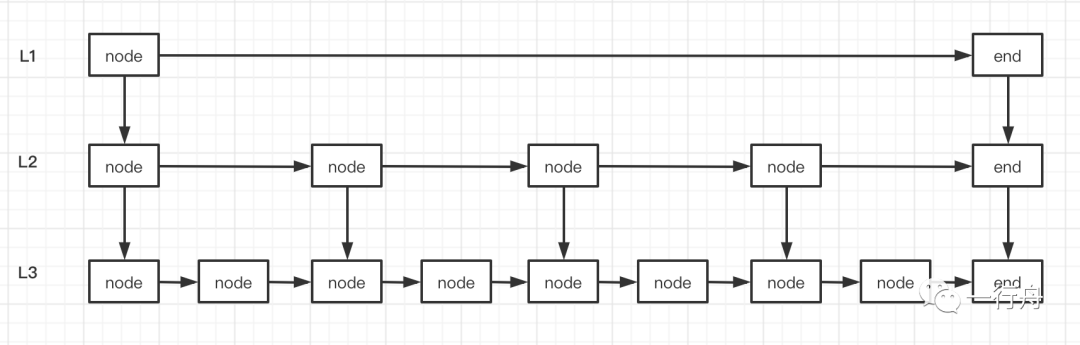
B+树,正是MySQL的InnoDB引擎选用的数据结构,其实B+树和跳表很相似。
InnoDB为什么会选择B+树索引呢?
- 每个节点可以存放多条数据,这样可以有效的控制树的高度。(可以有效的减少磁盘的随机访问次数)
- 只在叶子节点存放记录,可以极大的节省存储空间
- 叶子节点有序(这样在进行范围查询的时候,可以极大的提高效率)
画外音:红黑树、LSM-tree、Trie树都是非常复杂的索引,这里就不展开描述了,后续再找时间详细和大家介绍。
InnoDB的索引
MySQL的索引是在引擎层实现的,我们只介绍下InnoDB引擎下的索引。
根据主键创建的索引,我们称为主键索引或者聚簇索引;非主键创建的索引我们称为非主键索引或者二级索引。
主键索引的特点是:非叶子节点存放主键信息,叶子节点存放整行的数据。二级索引,叶子节点存放主键信息,非叶子节点存放索引信息。你可能会说有些表没有主键,这个你不用担心,即使你不定义主键MySQl也会自动给每一行数据生成一个唯一ID。
每创建一个索引就对应一颗B+树。下面分别是主键索引和二级索引的示意图。
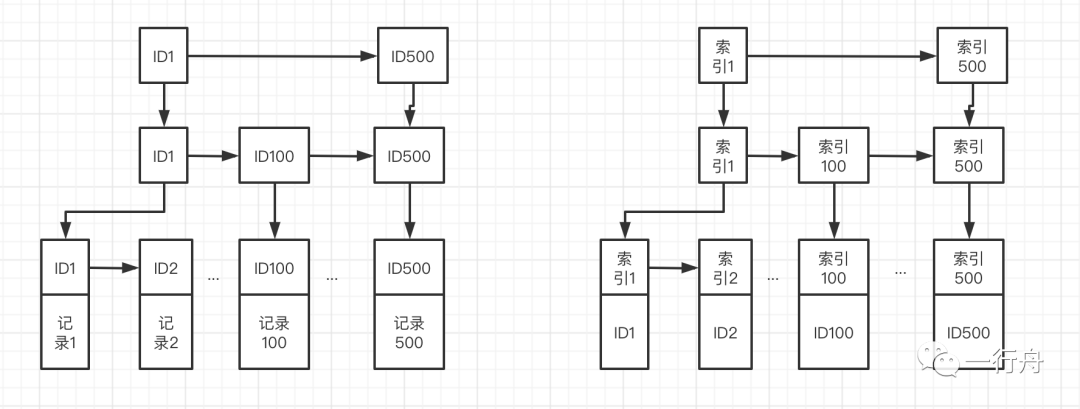
查询语句是如何使用索引的呢?
我们先构造一张curriculum(课程表):其中id是主键, teacher是二级索引
| id | name | teacher |
|---|---|---|
| 1 | 思维 | t1 |
| 3 | 英语 | t3 |
| 5 | AI | t5 |
| 7 | 绘画 | t7 |
下面分别介绍下使用索引的几种场景
1.SELECT * FROM curriculum WHERE id >=3 AND id <6。
这一条语句就是根据主键索引寻找[3,6)的扫描区间内的记录。
- InnoDB根据主键索引,迅速找到id=3的记录,符合条件
- 沿着B+树叶子节点的链表继续往后查找,找到id=5的记录,符合条件
- 沿着B+树叶子节点的链表继续往后寻找,找到id=7的记录,超出搜索区间,结束查找
2.SELECT * FROM curriculum WHERE teacher >='t3' AND teacher <'t6'
这一条语句就是根据二级索引寻找[t3,t6)的扫描区间内的记录。
- InnoDB根据teacher二级索引,迅速找到teacher=t3的记录对应的主键id=3,
- 根据主键ID在主键索引树上找到整条记录的数据
- 沿着二级索引B+树叶子节点的链表继续往后寻找,找到teacher=t5的记录对应的主键id=5
- 根据主键ID在主键索引树上找到整条记录的数据
- 沿着二级索引B+树叶子节点的链表继续往后寻找,找到teacher=t7的记录,超出搜索区间,结束查找。
根据二级索引找到主键,然后再去主键索引树查找的过程,我们通常成为“回表”。在实际的业务场景中,我们应该尽量减少回表的次数,过多的回表次数会影响查询性能。这也是MySQL的server层在选择是否使用某个索引时的一个评估点。
3. SELECT teacher FROM curriculum WHERE teacher >='t3' AND teacher <'t6';
这条语句指定了查询列:teacher,此时查找过程中就不用回表了,在二级索引中就能直接查询到所需要的数据。这条语句的执行过程我们就不列举了,把上一条语句执行过程的回表操作去掉就可以了。这种在二级索引中就能查询到所需要数据的方式我们通常称为”索引覆盖“。
有时候我们会根据多个列建立索引,称为联合索引。联合索引会按照索引创建时,指定的列依次排序后,组织成一颗B+树。
比如还是curriculum表,我们建立一个teacher和name的联合索引t_n_index(这里注意一下顺序)。此时,索引树优先按照teacher排序,在teacher相同时,按照name排序。
执行语句:
SELECT * FROM curriculum WHERE teacher >='t3' AND teacher <'t6' name='英语' force index(t_n_index);
此时我们的查询条件里多了name='英语',查询步骤是这样。
- InnoDB根据t_n_index索引,迅速找到teacher=t3的索引节点
- 根据此索引节点,判断name的值是否为'英语',刚好name='英语',记录符合条件
- 根据找到的索引节点,id=3,“回表”到主键索引树中查找对应记录
- 沿着t_n_index索引树叶子节点的链表继续往后寻找,找到teacher=t5的索引节点, t5<t6符合条件
- 根据此索引节点,判断name的值是否为'英语',name='AI',不符合要求,不需要回表
- 沿着二级索引B+树叶子节点的链表继续往后寻找,找到teacher=t7的记录,超出搜索区间,结束查找。
这里在根据teacher搜索区间查找记录的同时,会根据name的值是否符合要求决定是否需要“回表”的操作称为“索引下推”。
因为联合索引对字段的排序规则,索引会优先按照靠前的列排序。此时需要注意一点,我们的curriculum表即有teacher列的索引,又有t_n_index索引,其实是重复的,因为t_n_index索引是优先按照teacher列排序的,可以删除teacher索引。
默认情况下执行order by语句是需要把符合条件的记录拉到内存中进行排序的,如果排序的内容过多还需要借助临时文件。但是如果能刚好命中索引的话,就完全不需要排序了。比如:SELECT * FROM curriculum WHERE teacher >='t3' AND teacher <'t6' order by teacher,name; order by的字段和顺序完全命中了t_n_index索引,此时直接查询,返回记录就OK了。
前面说到的都是查询的过程中,索引带来的好处。为了维护索引还会带来一些额外的开销。
首先存储索引需要占用磁盘空间,在更新记录时也需要同时更新索引数据。而且因为索引是有序,如果我们插入的数据无序,就需要往排好序的索引中间插入记录,因为MySQL在磁盘中存储的索引数据都是按页存储的,如果此时刚好一页的数据放不下了,就需要把这一页的部分数据转移,我们称这种现象叫页分裂。更可怕的是,如果数据移动之后刚好下一页数据也放不下,页分裂还会带来连锁反应。
总结:
1.因为主键是二级索引的叶子节点,所以主键要尽可能小
2.因为无序的插入容易导致页分列,所以主键索引应该尽量有序
3.因为索引覆盖可以减少回表,所以我们写select语句时,尽量明确指定需要的字段(当然还可以减少数据传输的大小)
4.因为联合索引的顺序问题,我们在创建索引时,要避免一些重复的索引。
当然还有很多其他需要注意的地方,我们后面再慢慢补充学习。
参考资料:
《高性能MySQL》
《MySQL是怎样运行的》
MySQL官网(https://dev.mysql.com/doc/refman/5.7/en/)