同事问我,SQL 语句明明命中了索引,为什么执行很慢?
sql索引失效问题,是一个让非常头疼的问题,本文从实战的角度,分享了如何定位和优化索引问题,非常值得一看,值得借鉴。
我们都知道,业务开发涉及到数据库的SQL操作时,一定要 review 是否命中索引。否则,会走 全表扫描,如果表数据量很大时,会慢的要死。
假如命中了索引呢?是不是就不会有慢查询?
殊不知,我们习以为常的常识有时也会误导我们!
人生好难!
聊这个话题,要有一定技术基础,需了解 B+ 树的存储结构
如果不是很清楚的话,先看下之前一篇文章,有详细介绍
[面试题:mysql 一棵 B+ 树可以存多少条数据?]
1、工作准备:建表,造数据
首先创建一张 user 表,并创建一个 id的主键索引,和一个 user_name 的普通索引。
CREATE TABLE `user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`user_name` varchar(128) NOT NULL DEFAULT '' COMMENT '用户名',
`age` int(11) NOT NULL COMMENT '年龄',
`address` varchar(128) COMMENT '地址',
PRIMARY KEY (`id`),
key `idx_user_name` (user_name),
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户表';启动程序,往 <span style="font-size: 16px;">user 表中插入 10000 条数据。
@GetMapping("/insert_batch")
public Object insertBatch(@RequestParam("batch") int batch) {
for (int j = 1; j <= batch; j++) {
List<User> userList = new ArrayList<>();
for (int i = 1; i <= 100; i++) {
User user = User.builder().userName("Tom哥-" + ((j - 1) * 100 + i)).age(29).address("上海").build();
userList.add(user);
}
userMapper.insertBatch(userList);
}
return "success";
}2、慢查询
在分析原因前,我们先来了解 mysql 慢查询是什么?如何定义的?
慢查询定义:
MySQL的慢查询日志是MySQL提供的一种日志记录,用来记录在MySQL中响应时间超过阀值的语句,具体指运行时间超过long_query_time值的SQL,则会被记录到慢查询日志中。
慢查询相关参数:
- slow_query_log:是否开启慢查询日志,1表示开启,0表示关闭。
- log-slow-queries:旧版(5.6以下版本)MySQL数据库慢查询日志存储路径。可以不设置该参数,系统则会默认给一个缺省的文件host_name-slow.log
- slow-query-log-file:新版(5.6及以上版本)MySQL数据库慢查询日志存储路径。可以不设置该参数,系统则会默认给一个缺省的文件host_name-slow.log
- long_query_time:慢查询阈值,当查询时间高于设定的阈值时,记录到日志
- log_queries_not_using_indexes:未使用索引的查询也被记录到慢查询日志中(可选项)
默认情况下slow_query_log的值为OFF,表示慢查询日志是禁用的,可以通过设置slow_query_log的值来开启,如下所示:
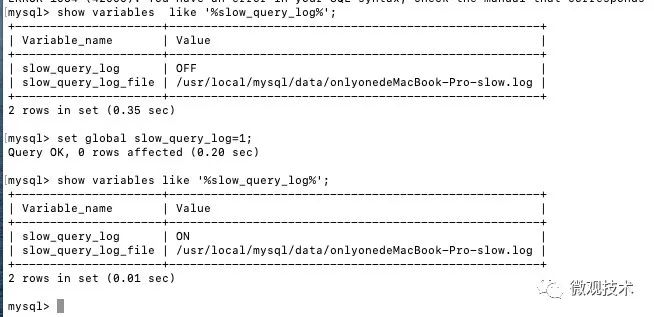
使用set global slow_query_log=1 开启了慢查询日志只对当前数据库生效,如果MySQL重启后则会失效。如果要永久生效,必须修改配置文件 my.cnf
long_query_time的默认值为10 秒,支持二次修改。线上我们一般会设置成1秒,如果业务对延迟敏感的话,我们根据需要设置一个更低的值。

3、开始实验
首先看下以下几种场景的SQL语句执行时,索引的命中情况。
1、执行explain select * from user;,发现 key 这列为NULL,说明了没有命中索引,走了全表扫描。

2、执行 explain select * from user where id=10;,发现 key 这列为 PRIMARY,说明使用了主键索引。

3、执行 explain select user_name from user;,发现 key 这列为 idx_user_name,说明使用了二级普通索引。

但是,实验发现,虽然走了二级索引,但是 rows 扫描行为 9968,说明走了全表扫描。性能很差。
本文测试只造了 1W 条数据,如果线上环境有个千万级数据量,那估计要好几秒才能响应结果。
如果请求并发量很高,很容易引发数据库连接无法及时释放,导致客户端无法获取数据库连接而报错。
4、命中索引,依然很慢
我们知道所有的数据都是存储在 B+ 索引树上,当执行 0; 时,发现使用了主键索引。

mysql 优化器根据主键索引找到第一个 id>0 的值,虽然走了索引但其实还是全表扫描。
没命中索引会走全表扫描,命中了索引也可能走全表扫描。

看来是否命中索引,并不是评判 SQL 性能好坏的唯一标准。
其实,还有一个重要指标,那就是 扫描行数。
当一个表很大时,不仅要关注是否有索引,还要关注索引的过滤性是否足够好。
5、回表优化
首先为user表 增加一个 user_name 和 age 的联合索引。
ALTER TABLE `user` ADD INDEX idx_user_name_age ( `user_name`,`age` );
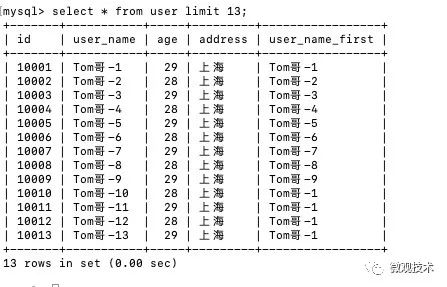
执行 explain select * from user where user_name like 'Tom哥-1%' and age =29;

执行流程:
- ① 首先在
idx_user_name_age索引树,查找第一个以Tom哥-1开头的记录对应的主键id - ② 根据主键id从主键索引树找到整行记录,并根据
age做判断过滤,等于29则留下,否则丢弃。这个过程也称为回表 - ③ 然后,在
idx_user_name_age联合索引树上向右遍历,找到下一个主键id - ④ 再执行第二步
- ⑤ 后面重复执行第三步、第四步,直到
user_name不是以Tom哥-1开头,则结束 - ⑥ 返回所有查询结果
分析:
由于按user_name 的前缀匹配,idx_user_name_age二级索引中的 age 部分并没有发挥作用。导致了大量回表查询,性能较差。
有什么优化策略:
MySQL 5.6 版本引入一个 Index Condition Pushdown Optimization

https://dev.mysql.com/doc/refman/5.6/en/index-condition-pushdown-optimization.html
优化后,执行流程:
- ① 首先在
idx_user_name_age索引树,查找第一个以Tom哥-1开头的索引记录 - ② 然后,判断这个索引记录中的
age是否等于 29。如果是,回表取出整行数据,作为后面的结果返回;如果不是,则丢弃 - ③ 在
idx_user_name_age联合索引树上向右遍历,重复第二步,直到user_name不是以Tom哥-1开头,则结束 - ④ 返回所有查询结果
跟上面的过程差别,在于判断 age 是否等于 29 放在了遍历联合索引过程中进行,不需要回表判断,大大降低了回表的次数,提升性能。
当然这个优化依然没有绕开最左前缀原则,索引的过滤性仍然有提升空间。
这时,我们需要引入一个叫 虚拟列 的概念。
修改表结构:
ALTER TABLE `user` add user_name_first varchar(12) generated always as
(left(user_name,6)) , add index(user_name_first,age);
执行explain select * from user where user_name_first like 'Tom哥-1%' and age =29;

比较发现,扫描行数 row 变小了,证明优化有效果。
6、写在最后
slow_query_log 收集到的慢 SQL ,结合 explain 分析是否命中索引,结合扫描行数,有针对性的优化慢 SQL。
但是要注意一点,慢 SQL 日志中也可能有正常的 SQL,可能只是当时CPU等系统资源过载,影响到正常 SQL 的执行速度。
简单来讲,慢查询和索引没有必然联系,一个SQL语句的执行效率最终要看的是扫描行数。另外可以使用虚拟列和联合索引来提升复杂查询的执行效率。