Golang 最细节篇之 — Reader 和 ReaderAt 的区别
大纲
- Golang 关于 Read 的两个接口定义
- C 语言 libc 库关于 read 的接口
- Golang 里 Read 和 ReadAt 的区别
- 那么,会出什么样的坑呢?
- 总结
概述
分享一个细节语义问题引发的思考。关于 Golang Read,ReadAt 这两个接口,不知道大家有没有仔细品过这两个接口的区别。golang 里面有两个关于 Read 的 interface ,就是 Reader 和 ReaderAt ,这两个接口的定义在标准库 io 的 io.go 文件中,如下:
Golang 关于 Read 的两个接口定义
Reader interface 定义
type Reader interface {
Read(p []byte) (n int, err error)
}ReaderAt interface 定义
type ReaderAt interface {
ReadAt(p []byte, off int64) (n int, err error)
}从 interface 接口来看,我们看到的区别是:
- Reader 传入参数只有一个 p( 用来装读到的数据的 buffer ),返回参数是 n(读了多少数据),err(返回的错误码);
- ReaderAt 传入参数是两个,一个 ( 装读到的数据 buffer ),off(读取的偏移位置),返回值 n(表示读到了多少数据),err(错误码);
也就是说,Read 读数据的时候只需要给一个 buffer 就行了,偏移在内部维护,ReadAt 可以让你从指定的位置读数据,偏移自维护。这个是两个接口的最明显的区别,现在我的问题是:真的只有这样吗?
C 语言 libc 库关于 read 的接口
思考这个问题之前,我们看下 c 语言相关的接口,关于 libc 库,我们有 3 个读的接口,分别是 read,readv,pread。这三个接口的传入参数略有不同,定义如下(可以用 man 2 read 自行查看手册):
#include <sys/types.h>
#include <sys/uio.h>
#include <unistd.h>
ssize_t
pread(int d, void *buf, size_t nbyte, off_t offset);
ssize_t
read(int fildes, void *buf, size_t nbyte);
ssize_t
readv(int d, const struct iovec *iov, int iovcnt);简述含义:
- pread 读取数据,特点是可以指定偏移位置读取;
- 传入参数:d(文件句柄),buf(内存 buffer),nbyte (buffer 的大小,这个需要正确设置,否则容易越界),offset(文件读取的开始偏移);
- 返回值:返回读取的数据大小;
2 . read 读取数据;
- 传入参数:filedes(文件句柄),buf(内存 buffer 地址),nbytes(内存 buffer 大小);
- 返回值:读取数据的大小;
3 . readv 读取数据,特点是可以用离散的内存块来装数据;
- 传入参数:d(文件句柄),iov(离散的内存块地址,抽象成向量的概念),iovcnt(内存向量数量);
通过以上的接口,我们注意到:
- 由于 c 对于动态数组这个类型,没有严格的检查,语言级别无法检查内存越界等情况,所以,对于数组做参数传入的时候,都是 一个地址,一个长度 这样配套的传入的,比如(buf,nbyte),(iov,iovcnt)都是如此;
2 . 返回值方面,3个函数的返回值语义是一致的,函数返回值表示读到的数据大小,类型是 ssize_t 类型;
a. 如果读成功,那么 返回值 > 0,表示读到了多少数据;
b. 如果读到了 EOF,那么 >返回值 == 0 ;
c. 如果是其他错误,那么 返回值 < 0,这个时候要配合线程变量 errno 来解释;
在接口 man 的描述里,我们注意到这么一段话:
DESCRIPTION
read() attempts to read nbyte bytes of data from the object referenced by the descriptor fildes into the buffer pointed to by buf. readv() performs the same action, but scatters the input data into the iovcnt buffers specified by the members of the iov array: iov[0], iov[1], ..., iov[iovcnt-1]. pread() performs the same function, but reads from the specified position in the file without modifying the file pointer.
也就是说,这三个函数的语义可以说是完全一致的,他们最底层执行的都是一样的函数,只不过传入的参数略有不同而已。
- 功能上,一个是最平常的 read,一个是可以让我们从指定偏移读数据的 pread,一个是让我们可用离散内存块存储数据的 readv ,除此之外语义是一样的。
- 关于返回值的解释,读成功的时候,返回值大于0,读到 EOF 的时候,返回值等于 0,读到错误的时候,返回值小于0,可以通过线程变量 errno 进一步获取详细的错误码。
Golang 里 Read 和 ReadAt 的区别
类比 libc,C 的 read,pread 这两个接口对应的是 Golang 的 Read 和 ReadAt 这两个接口,C 的 read,pread 除了传入参数有区别,其他语义是完全一致的。那么 Golang 呢?
答案当然是有巨坑(细节)的区别,不然也不会特意分享出来。下面我们先再去 Golang 标准库 io 看下接口定义:
Reader
ReaderAt
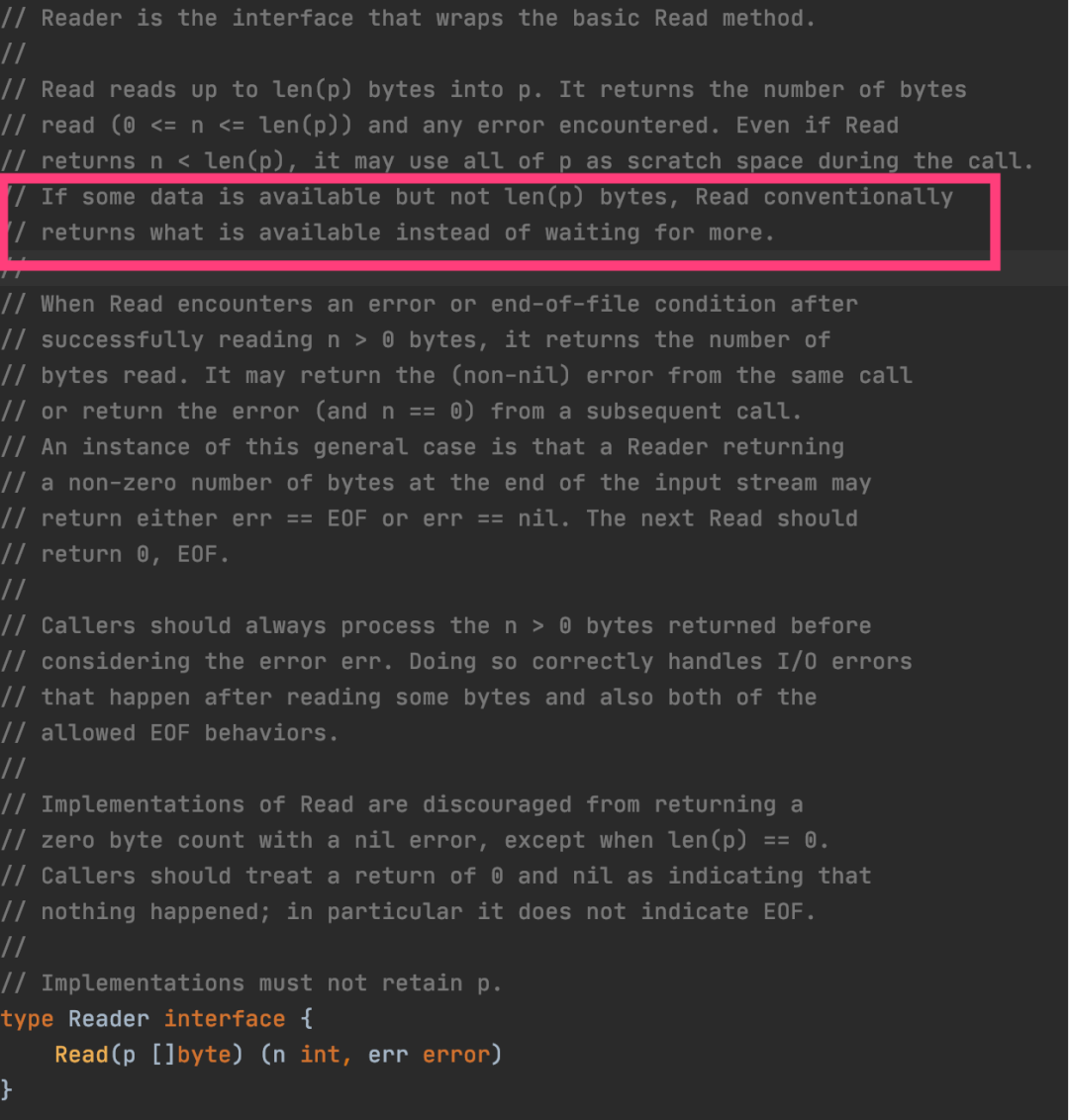
在我标红的两个地方就是最核心的区别(大家细品),Golang 里面 Read 接口对于读的结果有这么几种情况:
- 读成功了,数据完全填充 buffer ,读到了用户预期的数据大小,这个时候 n == len(p),err == nil,p 里都是用户有用的数据;
2 . 读失败了,err != nil ,这个时候 err 会标示出对应的错误;
3 . 读到 EOF 了,err == EOF,n 表示读到的有用数据大小,p 部分被填充;
4 . 第四种最坑(最细节),这个也是 Read 特意说明的(我截屏标红的), golang 允许当数据还没全部准备好的时候,返回部分数据,这个时候 err == nil; 也就是说,Read 接口允许:没有读满预期的 buffer,也不是 EOF 的情况,err == nil,这种情况是 Golang Read 接口语义的一部分;
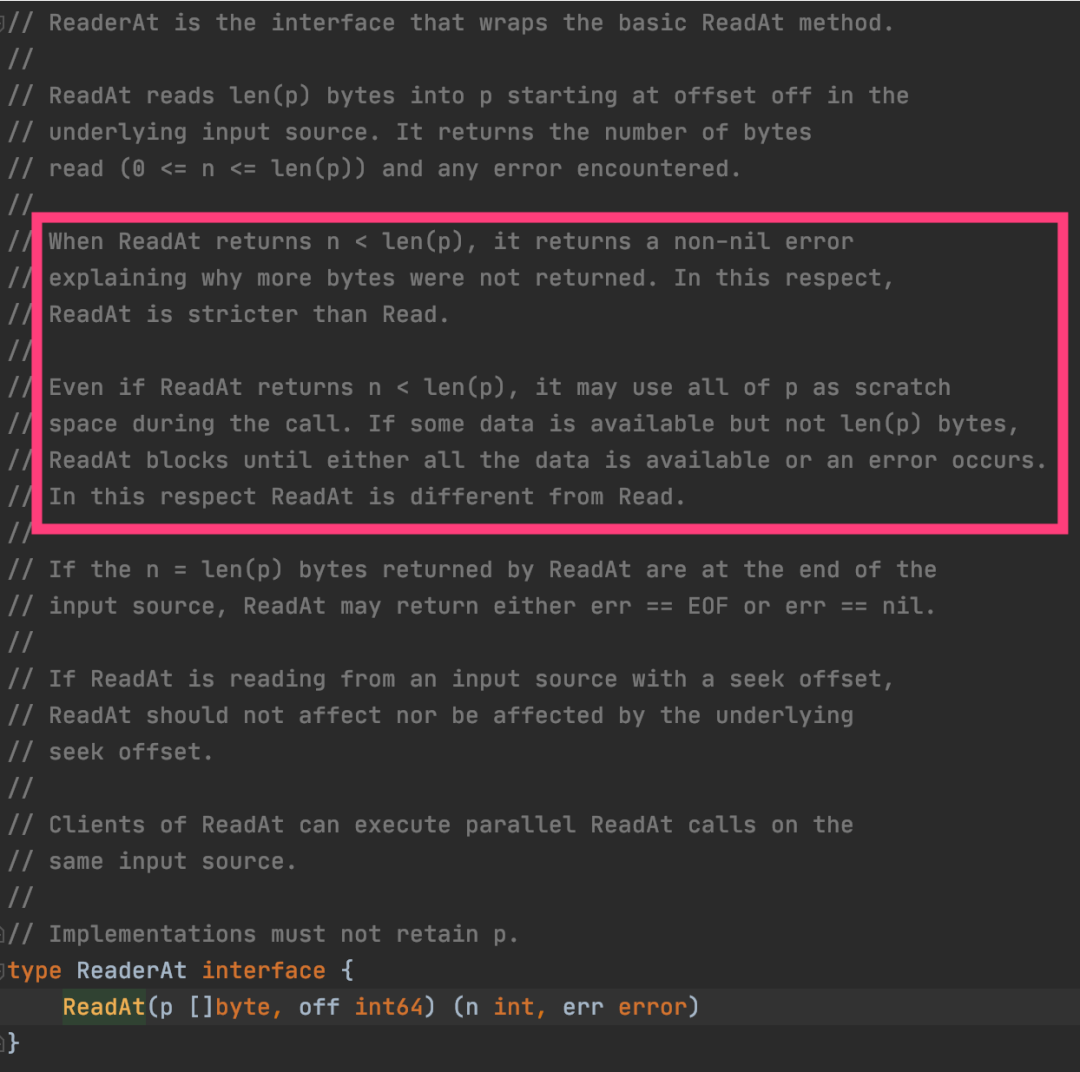
而对于 ReadAt 接口,Golang 的 interface 也特意说明了,这个接口比 Read 更严格,不允许第四种情况的发生。也就是说,ReadAt 读数据的结果,只有三种:
- 那么就是读成功,读满 buffer,这个时候 n==len(p),err==nil;
- 要么就是读到 EOF,这个时候没有读满 buffer,只读到了部分有效数据,n<len(p),err==EOF,n 指明有效数据的大小;
- 要么就是读失败,这个时候 err 表示错误码;
ReadAt 绝对不允许出现,没有读满 buffer,又非 EOF,又没有 err 的情况发生,这个是接口语义明确规定的,这是一个非常细节的区别。
那么,会出什么样的坑呢?
这么小的细节,可能带来的是非常严重的问题,因为这个是数据相关的问题,对于存储来说,数据正确性是生命的底线。那么可能带来什么问题呢?下面举个栗子。
Golang 的 interface 应用非常方便,非常容易让你一层层封装逻辑。那么在封装的过程中,一定要保持语义。举一个标准库的栗子,标准库里有一个 LimitedReader 的封装,构造的时候传入一个 N 参数,来保证读取数据的一个上限,什么意思?也就是经过这一个封装,Read 读取最大的数据量不会超过 limit 的设置。我们来看他的实现:
type LimitedReader struct {
R Reader // underlying reader
N int64 // max bytes remaining
}
func (l *LimitedReader) Read(p []byte) (n int, err error) {
if l.N <= 0 {
return 0, EOF
}
if int64(len(p)) > l.N {
// 经过这一层,就非常有可能出现我们之前提到的第四种情况,并且是个常态;
p = p[0:l.N]
}
n, err = l.R.Read(p)
l.N -= int64(n)
return
}那么你能找到 LimitedReaderAt 的实现吗?标准库里是没有的(可以思考下,为啥没有?),如果你要自己实现这么一个功能,那么是绝对不能照搬上面的实现的,否则就违反了 ReadAt 的语义。ReaderAt 规定:在没有读满 buffer 的时候,要么就是 EOF 的场景,要么就是其他 err!=nil 的场景,所以 ReadAt 的实现,封装之后一般要加一个循环处理,在没有读满,要继续处理,直到读满,或者报错。
那么有人想问了,如果没有遵守这个接口语义,可能会出什么事?可能没啥事,也可能出大事。举个例子,如果你 ReadAt 照搬了 Read 的语义,在没有读满的时候,也不报错,那么可能会导致调用者误用了错误的数据,比如下面:
// buffer 是一个 4K 的 slice 结构,off 是偏移
_, err := S.ReadAt(buffer, off)
if err != nil {
// 出错处理
}
// 把 buffer 的 4K 数据当作全部有效的数据处理 。。。。。上面这种代码就是出大事了。所以,理解其中区别了吗?
Golang 的 interface 非常灵活,对于我们做存储的来说,最核心的就是 IO ,也就是Read/Write,Golang 在标准库里定义的 interface 语义一定要看仔细了,保证语义的一致性才能保证逻辑的正确性。
总结
- Golang 的 Read 和 ReadAt 两个接口语义具有根本性区别,不同于 libc 关于 read 和 pread 的语义;
- Golang 的 ReadAt 语义相比于 Read 接口更严格,要么成功,要么失败,失败必须有对应 err 说明;
- 如果你封装了 ReadAt 接口,千万记得保证 ReadAt 的语义,否则就可能出现不可预期的事故;