缓存击穿导致 golang 组件死锁的问题分享
大纲
-
思路排查
-
Dump 堆栈很重要
-
关键思路
-
终于找到你
-
思路整理
-
发现蛛丝马迹
-
完整的推理流程
-
思考总结
分享一个线上遇到的死锁问题,什么, golang 也会有死锁?
思路排查
Dump 堆栈很重要
线上某个环境发现 S3 上传请求卡住,请求不返回,卡了30分钟,长时间没有发现有效日志。一般来讲,死锁问题还是好排查的,因为现场一般都在。类似于 c 程序,遇到死锁问题都会用 pstack 看一把。golang 死锁排查思路也类似(golang 不适合使用 pstack,因为 golang 调度的是协程,pstack 只能看到线程栈),我们其实是需要知道 S3 程序里 goroutine 的栈状态。golang 遇到这个问题我们有两个办法:
- 方法一:条件允许的话,gcore 出一个堆栈,这个是最有效的方法,因为是把整个 golang 程序的内存镜像 dump 出来,然后用 dlv 分析;
2 . 方法二:如果你提前开启 net/pprof 库的引用,开启了 debug 接口,那么就可以调用 curl 接口,通过 http 接口获取进程的状态信息;
需要注意到,golang 程序和 c 程序还是有点区别,goroutine 非常多,成百上千个 goroutine 是常态,甚至上万个也不稀奇。所以我们一般无法在终端上直接看完所有的栈,一般都是把所有的 goroutine 栈 dump 到文件,然用 vi 打开慢慢分析。
-
调试这个 core 文件,意图从堆栈里找到些东西,由于堆栈太多了,所以就使用
gorouties -t -u这个命令,并且把输出 dump 到文件; -
curl xxx/debug/pprof/goroutine
关键思路
成千上万个 goroutine ,直接显示到终端是不合适的,我们 dump 到文件 test.txt,然后分析 test.txt 这个文件。去查找发现了一些可疑堆栈,那么什么是可疑堆栈?重点关注加锁等待的堆栈,关键字是 *runtime_notifyListWait 、semaphore 、`sync.(Cond).Wait、Acquire` 这些阻塞场景才会用到的,如果业务堆栈上出现这个加锁调用,就非常可疑。**
划重点:
- 留意阻塞关键字
runtime_notifyListWait、semaphore、sync.(*Cond).Wait、Acquire;
2 . 业务堆栈(非 runtime 的一些内部堆栈)
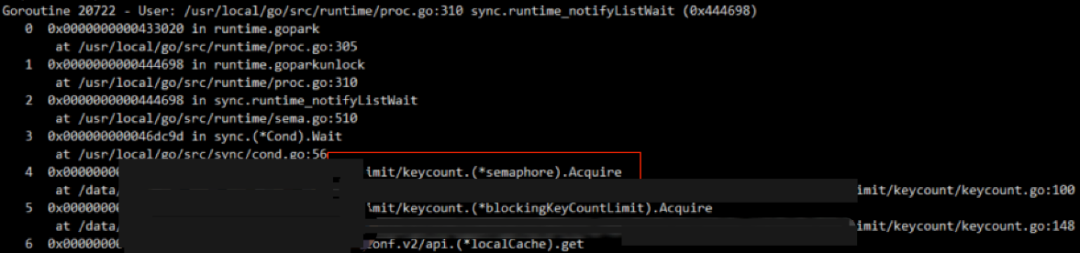
统计分析发现,有 11 个这个堆栈都在这同一个地方,都是在等同一把锁 blockingKeyCountLimit.lock,所以基本确认了阻塞的位置,就是这个地方阻塞到了所有的请求,但是这把锁我们使用 defer 释放的,使用姿势如下:
// do someting
lock.Acquire(key)
defer lock.Release(key)
// 以下为锁内操作;blockingKeyCountLimit 是我们封装针对 key 操作流控的组件。举个例子,如果 limit == 1,key为 "test" 在 g1 上 Acquire 成功,g2 acquire("test") 就会等待,这个可以算是我们优化的一个逻辑。如果 limit == 2,那么就允许两个人加锁到,后面的人都等待。
从代码来看,函数退出一定会释放的,但是偏偏现在锁就卡在这个地方,所以就非常奇怪。我们先找哪个 goroutine 占着这把锁不释放,看看能不能搞清楚怎样导致这里抢不到锁的原因。
通过审查业务代码分析,发现可能的源头函数(这个函数是向后端请求的函数):
api.(*Client).getBytesNolc
确认是 getBytesNolc 这个函数执行的操作,那么大概率就是卡在这个地方了。用这个 getBytesNolc 字符串搜索堆栈,找下是哪个堆栈 ?搜索到这个堆栈 goroutine 19458
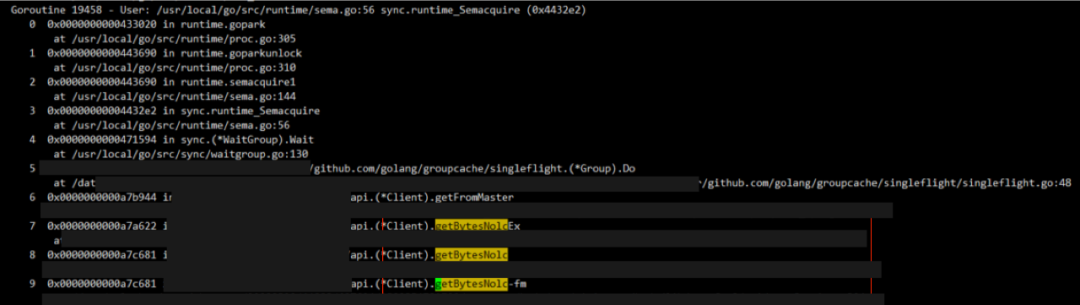
大概率就是第 1 个堆栈了,也就是其他的 11 个 goroutine 都在等这 goroutine 19458 来放锁,仔细看这个堆栈。那么为啥这个堆栈不放锁呢?这里有个细节要注意下,这里是卡到 gihub.com/golang/groupcache/singleflight/singleflight.go:48 这一行:
终于找到你
这是一个开源库,singleflight 实现了缓存防击穿的功能。
简单减少下 singleflight 的功能,这是一个非常有效的工具。在缓存大量失效的场景,如果针对同一个 key ,其实只需要有一个人穿透到后端请求数据,其他人等待他完成,然后取缓存结果即可。这个就是 singleflight 实现的功能。具体实现就是:来了请求之后,把 key 插入到 map 里,后面的请求如果发现同名 key 在 map 里面,那么就等待它完成就好;
截屏显示卡到 c.wg.Wait() 这一行,那么说明 map 里面肯定有已经存在的 key,说明 goroutine 19458 不是第一个人?但是外面还有一个 blockingKeyCountLimit 的互斥呢,按道理其他的人也进不来(因为 limit == 1),这里这么讲来肯定要是源头才对?
思路整理
伪代码显示如下:
func xxx () {
// 大部分协程都卡在这里(11个)
// 这个锁的效果主要是流控,limit 值初始化赋值,可以是 1,也可以是其他;
// locker 为 blockingKeyCountLimit 类型
limitLocker.Acquire( key )
defer limitLocker.Release( key )
// 获取数据
getBytesNolc( key , ...)
}
func getBytesNolc () {
// ...
// 下面就是 singleflight.Group 的用法,防穿透
// 同一时间只允许一个人去后端更新
ret, err = x.Group.Do(id, func() (interface{}, error) {
// 去服务后台获取,更新数据;
})
// ...
}图示显示当前的现状:
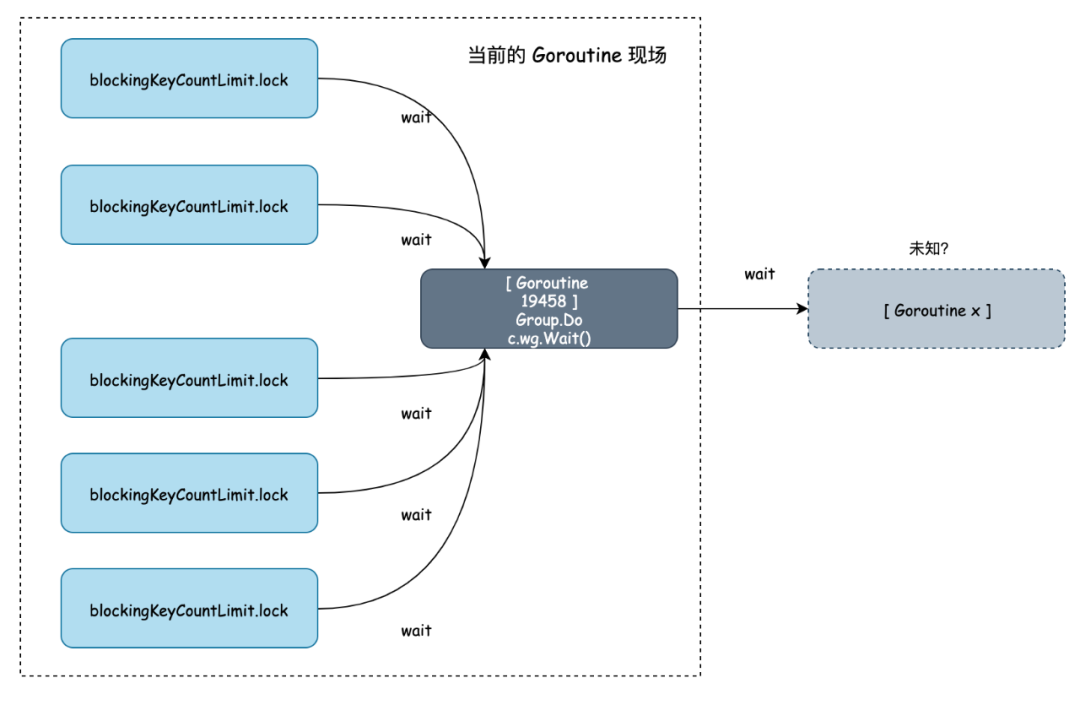
现状小结:
- 大量的协程都在等
blockingKeyCountLimit这把锁释放; - 协程
goroutine 19458持有blockingKeyCountLimit这把锁; - 协程
goroutine 19458却在等一个相同 key 名字的任务的完成( singleflight 一个防击穿的库,同一时间相同 key 只允许放到一个后端去执行),却永远没等到,协程因此呈现死锁;
当前的疑问就是第一个 key 的任务为啥永远完不成,堆栈也找不到了,去哪里了?
发现蛛丝马迹
我们再仔细审一下 singleflight 的代码:
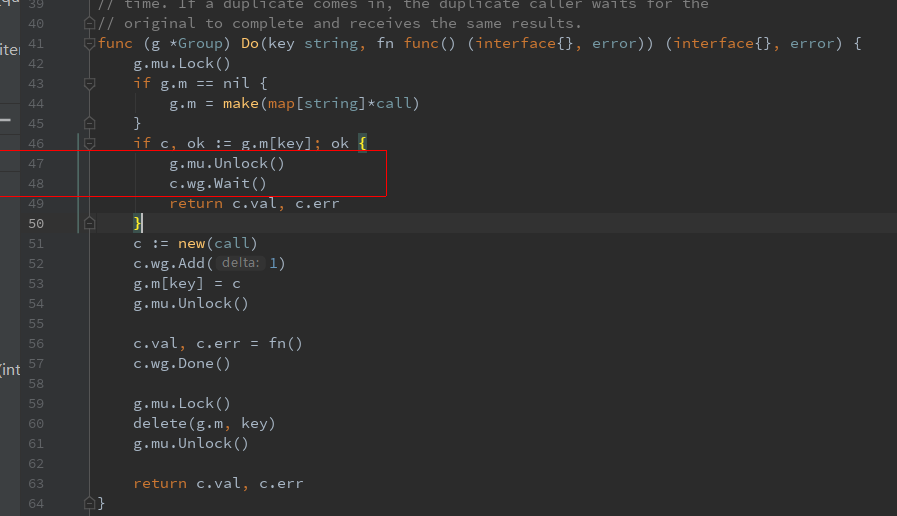
func (g *Group) Do(key string, fn func() (interface{}, error)) (interface{}, error) {
g.mu.Lock()
if g.m == nil {
g.m = make(map[string]*call)
}
// 如果找到同名 key 已经存在;
if c, ok := g.m[key]; ok {
g.mu.Unlock()
// 等待者走到这个分支:等待第一个人执行完成,最后直接返回它的结果就行了;
c.wg.Wait()
return c.val, c.err
}
// 如果同名 key 不存在(第一个人走到这个分支)
c := new(call)
c.wg.Add(1)
// map 里放置 key
g.m[key] = c
g.mu.Unlock()
// 执行任务
c.val, c.err = fn()
// 唤醒所有的等待者
c.wg.Done()
g.mu.Lock()
// 删除 map 里的 key
delete(g.m, key)
g.mu.Unlock()
return c.val, c.err
}发现有个线索,我们的 S3 服务程序一个 http 请求对应一个协程处理,为了提高服务端进程的可用性,在框架里会捕捉 panic,这样确保单个协程处理不会影响到其他的请求。基于这个前提,我们假设:如果 fn() 执行异常,panic 掉了,那么就不会走 delete(g.m, key) 的代码,那么 key 就永远都残留在 map 里面,而进程却又还活着。恍然大悟。
完整的推理流程
- 第一个协程 g1 来了,加了
blockingKeyCountLimit锁,然后准备穿透到后端,调用函数getBytesNolc获取数据,并走进了singlelight,添加了一个 key:x, 准备干活;
a . 干活发生了一些不可预期的异常(后面发现是配置的异常),nil 指针引用之类的, panic 堆栈了,panic 导致后面 delete key 操作没有执行;
b . 虽然 g1 现在 panic 了,但是由于在函数 func xxx 里面 blockingKeyCountLimit 是 defer 执行的,所以这把锁还是,但是 singlelight 的 key 还存在,于是残留在 map 里面;
c . 但是由于我们服务程序为了高可用是 recover 了 panic 的,单个请求的失败不会导致整个进程挂掉,所以进程还是好好的;
2 . 第二个 goroutine 19458 协程来了,blockingKeyCountLimit 加锁,然后走到 singlelight 的时候,发现有 key: x 了,于是就等待;
a . 并且等待的是一个永远得不到的锁,因为 g1 早就没了;
3 . 后续的 11 个 协程来了,于是被 blockingKeyCountLimit 阻塞住,并且永远不能释放;
实锤:后续基于这个猜想,再去搜索一遍日志,发现确实是有一条 panic 相关的日志。这个时间点后面的请求全部被卡住。
思考总结
一般来讲 c 语言写程序容易出现死锁问题,因为各种异常逻辑可能会导致忘记放锁,从而导致抢一个永远都不可能得到的锁。golang 为了解决这个问题,一般是用 defer 机制来实现,使用姿势如下:
func test () {
mtx.Lock()
defer mtx.Unlock()
/* 临界区 */
}golang 的 defer 机制是一个经过经验沉淀下来的有效功能。我们必须要合理使用。defer 实现原理是和所在函数绑定,保证函数 return 的时候一定能调用到( panic 退出也能),所以 golang 加锁放锁的有效实践是写在相邻的两行。
其实思考下,singleflight 作为一个通用开源库,其实可以把 delete map key 放到 defer 里,这样就能保证 map 里面的 key 一定是可以被清理的。
还有一点,其实 golang 是不提倡异常-捕捉这样的方式编程,panic 一般不让随便用,如果真是严重的问题,挂掉就挂掉,这个估计还好一些。当然这是要看场景的,还是有一些特殊场景的,毕竟 golang 都已经提供了 panic-recover 这样的一个手段,就说明还是有需求。这个就跟 unsafe 库一样,你只有明确知道自己的行为影响,才去使用这个工具,否则别用。