对象存储 ListObject 有啥值得思考的?
大纲
-
如何列举桶中对象
-
怎么列举对象?
-
“列举对象”是否真的很简单?
-
总结
如何列举桶中对象
云存储服务对业务提供基础的数据上传、下载能力,以简单易用作为重点,但有些时候,我们有列举需求。列举是什么意思?比如我们往一个 bucket 里面上传了一些对象,但是我们不知道名字,那么只能让存储系统来告诉你,这个 bucket 里对象的列表。“列举”这是一个简单的需求,但是也有隐形的约束或者前提需要明确。对象存储一把应对的场景是海量对象(上亿级甚至更多),这种前提下,提供的列举功能就不再简单了。
怎么列举对象?
列举对象(List Object)也叫 GET Bucket,用于列出该存储桶内的部分或者全部对象。该 API 的请求者需要对 Bucket 有读权限。
请求参数
OSS,COS,S3 等公有云厂商对于请求参数基本都是一致的:
- prefix :对象匹配前缀,用于限定响应中只匹配该前缀的key 的对象,非必选;
- delimiter :字符分隔符(这个没啥重要的,只是数据展示的一个部署),非必选;
- encoding-type :指定编码方式,默认是 url encode 的编码方式,非必选;
- marker :起始对象键标记(用来找到其实位置的锚点),非常重要;
- max-keys :单次 LIstObject 请求返回最大的条目数量,默认值一般是 1000;
这 5 个参数是公有云厂商 ListObject 接口都会提供的,也是 S3 协议的一部分,基本上不会有其他偏差(发现 COS 的 max-keys 默认值是 1000,OSS 的默认值是 100)。delimiter,encodeing-type 这两个参数不会影响数据内容,只是数据展示的一个选项,所以重点说下 prefix,marker,max-keys 这三个参数。为什么单独说这三个参数,因为这三个参数会影响到你返回的数据内容
prefix
这个理解相对简单,其实就是一个字符串匹配,比如我只想获取到 test_ 开头的对象,那么就可以通过这个参数匹配。prefix 允许你对对象做一个简单的过滤。
举个例子,我的一个 bucket 下面有下面这 6 个对象,可以用 prefix = path1/ 只过滤出所有 path1/ 前缀的对象。
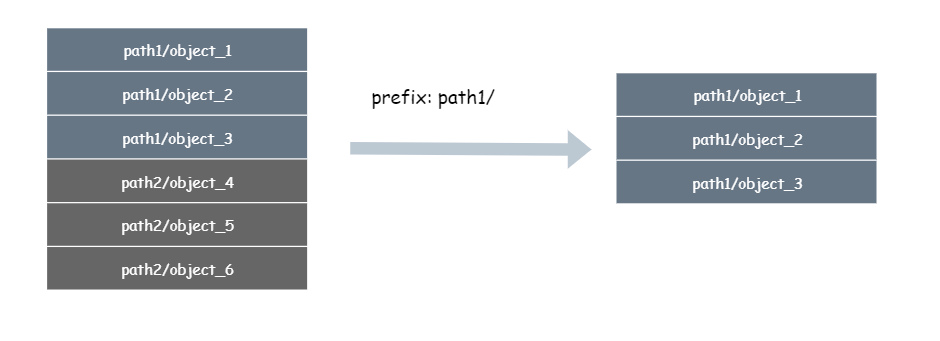
(旁白:对象的 key 就是 path1/object_1 哈,不要理解错了,key 里面是可以有 '/' 字符的)
marker
这个是一个锚点,指定 marker 就是指定列举桶中对象起始位置,marker非必需,默认为空从第一个 key 开始。指定 maker 的时候,从匹配位置的下一个对象开始列举。
举个栗子,我基于上面 prefix 的例子,再加上 marker ,列举的结果如下:
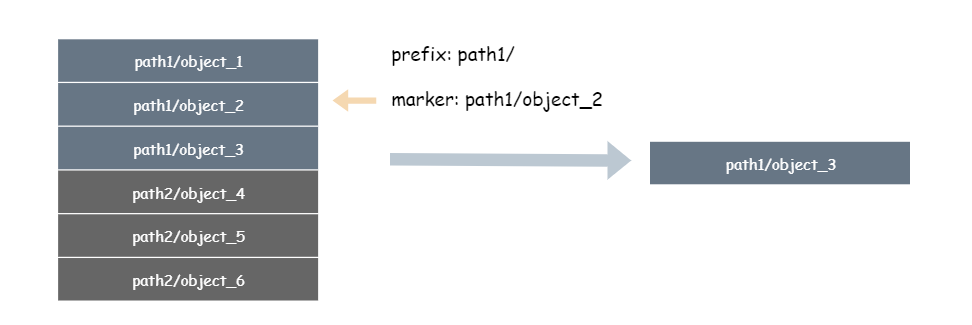
marker 是要和 max-keys 来配合使用的,来达到一个分页的功能。
max-keys
max-keys 指定当前次列举返回满足条件的对象数量。max-keys<=1000(默认为1000),以下图为例业务只列举 1 个对象
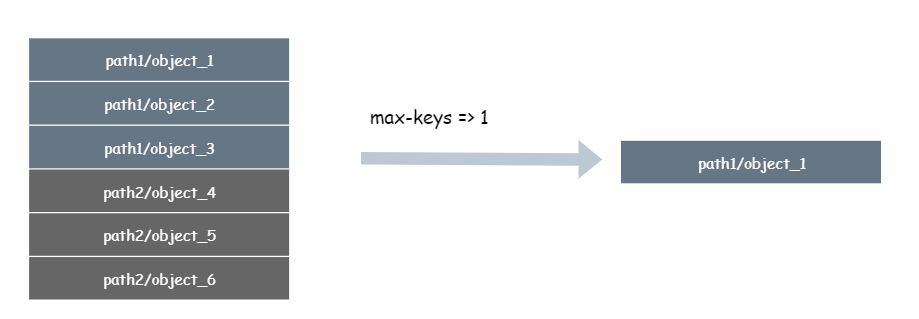
以上三个参数含义很简单,但是其实有个隐藏的知识点,划重点:ListObject 列举的对象是字典序排序。一定是有这个前提,marker,max-keys 这两个参数才是正常工作的。大家可以思考下为啥?
因为,如果对象 key 不排序,那么 marker 锚点将无从谈起,自然分页功能也无法实现。
响应格式
我在本地搭建了一个对象存储系统用于测试,演示下请求和响应格式,工具使用 s3curl ,s3curl 的好处就是能把 http 的请求和响应包完整的打印出来,能让我们看到 s3 的协议格式:
命令:
root@ubuntu:~/# s3curl --id=mock -- http://127.0.0.1:20000/qiyabucket -v|xmllint -format -
响应:
# 以下是 s3curl 命令格式
root@ubuntu:~/# s3curl --id=mock -- http://127.0.0.1:20000/qiyabucket -v|xmllint -format -
# 以下是 S3 请求
> GET /qiyabucket HTTP/1.1
> Host: 127.0.0.1:20000
> User-Agent: curl/7.47.0
> Accept: */*
> Date: Sat, 31 Oct 2020 10:19:45 +0000
> Authorization: AWS PjFtQJWfvKrSLYkSlV-keCKWzmXzSK1Zp3R9S5MV:ZpK77CdhcR3wMGAZbP4fDLsayu4=
>
# 以下是 S3 响应;
< HTTP/1.1 200 OK
< Vary: Origin,Access-Control-Request-Method,Access-Control-Request-Headers
< x-amz-request-id: qBgAALuUmUl0DEMW
< Date: Sat, 31 Oct 2020 10:19:45 GMT
< Content-Length: 491
< Content-Type: text/plain; charset=utf-8
<
<?xml version="1.0"?>
<ListBucketResult xmlns="http://s3.amazonaws.com/doc/2006-03-01/">
<Name>qiyabucket</Name>
<Delimiter/>
<Prefix/>
<Marker/>
<MaxKeys>1000</MaxKeys>
<IsTruncated>false</IsTruncated>
<Contents>
<Key>object1</Key>
<ETag>"6021a1469375b00fab2d51732f7e9d0e"</ETag>
<Size>46625</Size>
<LastModified>2020-10-31T10:19:43.000Z</LastModified>
<StorageClass>STANDARD</StorageClass>
<Owner>
<ID>260637563</ID>
<DisplayName>260637563</DisplayName>
</Owner>
</Contents>
</ListBucketResult>“列举对象”是否真的很简单?
至此,我们就了解了 ListObject 这个接口的使用方法,那么这个接口为啥值得注意呢?
我们注意到,前面在说明 marker 参数的时候,提到一个隐形前提条件:对象列表输出必须有序 ,再基于海量的前提假设,那么这个接口就不简单了。为啥不简单?
举个例子,如果你的 bucket 里面有 1 亿个对象,你要实现个 marker ,prefix 的功能,你要怎么做?比如下面的参数,我们想要从 'test/object_1' 这个位置,列举出 'test/' 前缀的对象,只列举 100 个对象:
prefix = test/
marker = test/object_1
max-keys = 100最简单的实现思路,ListObject 请求来了,把 1亿 的对象元数据加载到内存,然后对这 1亿个对象做一遍排序,然后找到 'test/object_1' 这个对象的位置,从这个位置的下一个开始,输出100个对象。。。你就完成了一次 100 个对象的列举额。
说的文字很简单,那可是 1 亿个对象呀,我只要 100个对象,却要对 1 亿个对象做排序,这个代价是非常大的。
所以,列举对象不简单。
ListObject 的思考
首先,我们站在几个角度思考这个List Object 这个简单的需求:
站在用户的角度:
在海量对象场景业务往往不会频繁的列举桶中对象,只有个别场景可能会用到列举(比如有些文件网关的一些实现,文件系统有 ls 的实现),列举 API 的调用占比不足万分之一。
基于这个现实假定,我们可以做出一些对应的策略,比如让用户来承受这个代价,比如向用户收费,流控,性能慢等等,这是个权衡。
站在存储系统的角度:
列举必然是一个高代价的操作,所以公有云服务商一般会把这个代价平摊给用户,并且在性能和数据一致性方面做权衡。
举个例子,比如:
- 比如 List Object 次数做控制,也就是系统本身做流控自我保护起来,并且 Api 单价比其他接口要贵;
- 服务文档里也会明确说明,数据可能存在短暂不一致的窗口(比如数据上传完之后,不能立马列举出来);
腾讯云 COS
腾讯云的这个文档提示就说明了他们对于这一块是做了选择的。这里很可能是系统内部为了 List 接口的性能而实现成一个异步化的操作。

阿里云没看到这个提示,就不大知道他们的策略了。这些东西都是技术上都可以实现的东西,但是可能你选择了一个方向,就会牺牲掉一个方面。
总结
ListObject 是一个简单的用户需求,但是却有着不简单的实现。最本质的原因就是海量对象和排序的要求导致的。