Go 并发编程 — sync.Pool 源码级原理剖析 [2] 终结篇
大纲
-
前情提要
-
原理剖析
-
数据结构
-
Get
-
Put
-
runtime
-
思考问题
-
1. 如果不是 Pool.Get 申请的对象,调用了 Put ,会怎么样?
-
2.
Pool.Get出来的对象,为什么要Pool.Put放回 Pool 池,是为了不变成自己讨厌的垃圾吗? -
3. Pool 本身允许复制之后使用吗?
-
总结
前情提要
上次我们从使用层面做了梳理分析,详情见: [Go 并发编程—深入浅出sync.Pool [1] 使用姿势篇] ,得到以下几点小知识:
- sync.Pool 本质用途是增加临时对象的重用率,减少 GC 负担;
- 不能对 Pool.Get 出来的对象做预判,有可能是新的(新分配的),有可能是旧的(之前人用过,然后 Put 进去的);
- 不能对 Pool 池里的元素个数做假定,你不能够;
- sync.Pool 本身的 Get, Put 调用是并发安全的,
sync.New指向的初始化函数会并发调用,里面安不安全只有自己知道; - 当用完一个从 Pool 取出的实例时候,一定要记得调用 Put,否则 Pool 无法复用这个实例,通常这个用 defer 完成;
官方开头声明:
A Pool is a set of temporary objects that may be individually saved and retrieved.
并且还制作了一个演示动画视频来帮助理解,详情见: [Go 并发编程 — 有趣的sync.Pool原理动画] 。
本篇是 sync.Pool 源码级别的分析,属于 sync.Pool 分析完结篇,三次分享梳理循序渐进,配合一起学习效果更好哦。
原理剖析
下面我们从数据结构和实现逻辑来深入剖析下 sync.Pool 的原理。
数据结构
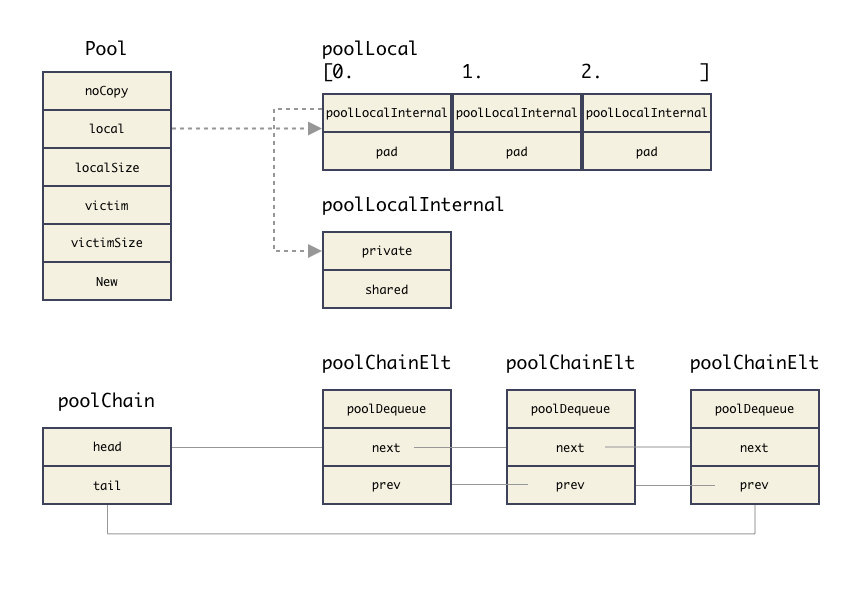
Pool 结构
sturct Pool 结构是给到用户的使用的结构,定义:
type Pool struct {
// 用于检测 Pool 池是否被 copy,因为 Pool 不希望被 copy;
// 有了这个字段之后,可用用 go vet 工具检测,在编译期间就发现问题;
noCopy noCopy
// 数组结构,对应每个 P,数量和 P 的数量一致;
local unsafe.Pointer
localSize uintptr
// GC 到时,victim 和 victimSize 会分别接管 local 和 localSize;
// victim 的目的是为了减少 GC 后冷启动导致的性能抖动,让分配对象更平滑;
victim unsafe.Pointer
victimSize uintptr
// 对象初始化构造方法,使用方定义
New func() interface{}
}有几个注意点:
- noCopy 为了防止 copy 加的打桩代码,但这个阻止不了编译,只能通过
go vet检查出来; local和localSize这两个字段实现了一个数组,数组元素为poolLocal结构,用来管理临时对象;victim和victimSize这个是在poolCleanup流程里赋值了,赋值的内容就是local和localSize。victim 机制是把 Pool 池的清理由一轮 GC 改成 两轮 GC,进而提高对象的复用率,减少抖动;- 使用方只能赋值 New 字段,定义对象初始化构造行为;
poolLocal 结构
该结构是管理 Pool 池里 cache 元素的关键结构,Pool.local 指向的就是这么一个类型的数组,这个结构值得注意的一点是使用了内存填充,对齐 cache line,防止 false sharing 性能问题的技巧。
Pool 里面该结构数组是按照 P 的个数分配的,每个 P 都对应一个这个结构。
// Pool.local 指向的数组元素类型
type poolLocal struct {
poolLocalInternal
// 把 poolLocal 填充至 128 字节对齐,避免 false sharing 引起的性能问题
pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte
}
// 管理 cache 的内部结构,跟每个 P 对应,操作无需加锁
type poolLocalInternal struct {
// 每个 P 的私有,使用时无需加锁
private interface{}
// 双链表结构,用于挂接 cache 元素
shared poolChain
}poolChain
我们可以稍微看下 poolChain 结构,这个纯粹是一个连接件,本身空间也就两指针,占用内存 16 Byte。
type poolChain struct {
head *poolChainElt
tail *poolChainElt
}所以关键还是链表的元素,链表元素的结构是 poolChainElt,这个结构体长这样:
type poolChainElt struct {
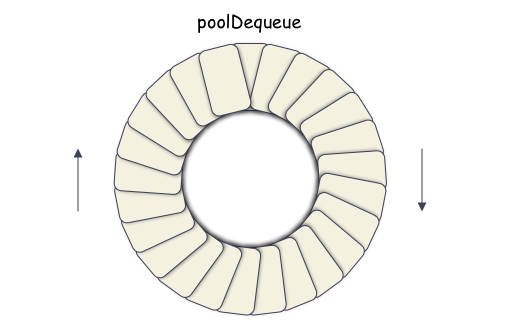
// 本质是个数组内存空间,管理成 ringbuffer 的模式;
poolDequeue
// 链表指针
next, prev *poolChainElt
}
type poolDequeue struct {
headTail uint64
// vals is a ring buffer of interface{} values stored in this
// dequeue. The size of this must be a power of 2.
vals []eface
}poolChainElt 是双链表的元素点,里面其实是一段数组空间,类似于 ringbuffer,Pool 管理的 cache 对象就都存储在 poolDequeue 的 vals[] 数组里。
Get
func (p *Pool) Get() interface{} {
// 把 G 锁住在当前 M(声明当前 M 不能被抢占),返回 M 绑定的 P 的 ID
// 在当前的场景,也可以认为是 G 绑定到 P,因为这种场景 P 不可能被抢占,只有系统调用的时候才有 P 被抢占的场景;
l, pid := p.pin()
// 如果能从 private 取出缓存的元素,那么将是最快的路径;
x := l.private
l.private = nil
if x == nil {
// 从 shared 队列里获取,shared 队列在 Get 获取,在 Put 投递;
x, _ = l.shared.popHead()
if x == nil {
// 尝试从获取其他 P 的队列里取元素,或者尝试从 victim cache 里取元素
x = p.getSlow(pid)
}
}
// G-M 锁定解除
runtime_procUnpin()
// 最慢的路径:现场初始化,这种场景是 Pool 池里一个对象都没有,只能现场创建;
if x == nil && p.New != nil {
x = p.New()
}
// 返回对象
return x
}Get 的语义就是从 Pool 池里取一个元素出来,这里的重点是:元素是层层 cache 的,由最快到最慢一层层尝试。最快的是本 P 对应的列表里通过 private 字段直接取出,最慢的就是调用 New 函数现场构造。
尝试路径:
- 当前 P 对应的
local.private字段; - 当前 P 对应的
local的双向链表; - 其他 P 对应的
local列表; - victim cache 里的元素;
New现场构造;
runtime_procPin
runtime_procPin 是 procPin 的一层封装,procPin 实现如下:
func procPin() int {
_g_ := getg()
mp := _g_.m
mp.locks++
return int(mp.p.ptr().id)
}procPin 函数的目的是为了当前 G 被抢占了执行权限(也就是说,当前 G 就在当前 M 上不走了),这里的核心实现是对 mp.locks++ 操作,在 newstack 里会对此条件做判断,如果
if preempt {
// 已经打了抢占标识了,但是还需要判断条件满足才能让出执行权;
if thisg.m.locks != 0 || thisg.m.mallocing != 0 || thisg.m.preemptoff != "" || thisg.m.p.ptr().status != _Prunning {
gp.stackguard0 = gp.stack.lo + _StackGuard
gogo(&gp.sched) // never return
}
}Pool.pinSlow
这个函数必须提一下,这个函数做了非常重要的事情,一般是 Pool 第一次调用 Get 的时候才会走进来(注意,是每个 P 的第一次 Get 调用,但是只有一个 P 上的 G 才能干成事,因为有 allPoolsMu 锁互斥)。
func (p *Pool) pinSlow() (*poolLocal, int) {
// G-M 先解锁
runtime_procUnpin()
// 以下逻辑在全局锁 allPoolsMu 内
allPoolsMu.Lock()
defer allPoolsMu.Unlock()
// 获取当前 G-M-P ,P 的 id
pid := runtime_procPin()
s := p.localSize
l := p.local
if uintptr(pid) < s {
return indexLocal(l, pid), pid
}
if p.local == nil {
// 首次,Pool 需要把自己注册进 allPools 数组
allPools = append(allPools, p)
}
// P 的个数
size := runtime.GOMAXPROCS(0)
// local 数组的大小就等于 runtime.GOMAXPROCS(0)
local := make([]poolLocal, size)
atomic.StorePointer(&p.local, unsafe.Pointer(&local[0])) // store-release
atomic.StoreUintptr(&p.localSize, uintptr(size)) // store-release
return &local[pid], pid
}pinSlow 主要做以下几个事情:
- 首次
Pool需要把自己注册进allPools数组; Pool.local数组按照runtime.GOMAXPROCS(0)的大小进行分配,如果是默认的,那么这个就是 P 的个数,也就是 CPU 的个数;
runtime_procUnpin
这个是对应 runtime_procPin 配套的函数,声明该 M 可以被抢占,字段 m.locks-- 。
func procUnpin() {
_g_ := getg()
_g_.m.locks--
}Put
Put 方法非常简单,因为是后置处理,该做的都在前面做好了,而清理动作又是在 runtime 的后台流程·,所以这里只是把元素放置到队列里就完成了。
// Put 一个元素进池子;
func (p *Pool) Put(x interface{}) {
if x == nil {
return
}
// G-M 锁定
l, _ := p.pin()
if l.private == nil {
// 尝试放到最快的位置,这个位置也跟 Get 请求的顺序是一一对应的;
l.private = x
x = nil
}
if x != nil {
// 放到双向链表中
l.shared.pushHead(x)
}
// G-M 锁定解除
runtime_procUnpin()
}但是也要注意一个小点,就是 Put 也会调用 p.pin() ,所以 Pool.local 也可能会在这里创建。
runtime
全局变量
每一个 Pool 结构都加到了全局队列里,在 src/sync/pool.go 文件里,定义了几个全局变量:
var (
// 互斥用
allPoolsMu Mutex
// 全局的 Pool 数组,所有的 Pool 都在这里有注册地址;
allPools []*Pool
// 配合 victim 机制用的;
oldPools []*Pool
)后台流程
init
初始化的时候注册清理函数。
func init() {
runtime_registerPoolCleanup(poolCleanup)
}在 Golang GC 开始的时候 gcStart 调用 clearpools() 函数就会调用到 poolCleanup 函数。也就是说,每一轮 GC 都是对所有的 Pool 做一次清理。
poolCleanup
这个是定期执行的,在 sync package init 的时候注册,由 runtime 后台执行,内容就是批量清理 allPools 里的元素。
func poolCleanup() {
// 清理 oldPools 上的 victim 的元素
for _, p := range oldPools {
p.victim = nil
p.victimSize = 0
}
// 把 local cache 迁移到 victim 上;
// 这样就不致于让 GC 把所有的 Pool 都清空了,有 victim 再兜底以下,这样可以防止抖动;
for _, p := range allPools {
p.victim = p.local
p.victimSize = p.localSize
p.local = nil
p.localSize = 0
}
// 清理一波所有的 allPools
oldPools, allPools = allPools, nil
}victim 把回收动作由一次变为了两次,这样更抗造一点。每次清理都是只有上次 cache 的对象才会被真正清理掉,当前的 cache 对象只是移到回收站(victim)。
知识小结:
- 每轮 GC 开始都会调用
poolCleanup函数; - 使用两轮清理过程来抵抗波动,也就是 local cache 和 victim cache 配合;
思考问题
原理上面已经剖析的非常清晰了,现在我们思考一些与众不同的问题:
1. 如果不是 Pool.Get 申请的对象,调用了 Put ,会怎么样?
不会有任何异常(是不是惊呆了),Pool 池里能接纳任意来源,任意类型的对象。就算不是 Pool.Get 出来的对象,也能正常调用 Pool.Put,而一旦你做了这个事情之后,Pool 池里的就不是单一的对象元素了,而是一个杂货铺了。
原因解析:
- 首先,
Put(x interface{})接口没有对 x 类型做判断和断言; - 其次,
Pool.Put内部也没有对类型做断言和判断,无法追究元素是否是来自于 Get 的接口;
所以,在上一篇剖析 Pool 使用姿势文章的中,在调用 Pool.Get 出来元素之后,我有一行类型断言就是这个意思:
buffer := bufferPool.Get()
_ = buffer.(*[]byte)注意这个很重要,因为 sync.Pool 框架支持存放任何类型,本质上可以是一个杂货铺,所以 Get 出来和 Put 进去的对象类型要业务自己把控。
2. Pool.Get 出来的对象,为什么要 Pool.Put 放回 Pool 池,是为了不变成自己讨厌的垃圾吗?
首先,从使用姿势来说,Pool.Get 和 Pool.Put 一定要配套使用,通常使用 defer Pool.Put 这种形式保证释放元素进池子。
你想过建议 Get,Put 配套使用的原因吗?如果不配套是会变成不可回收的垃圾吗?
首先,这个说法是错误的,虽然 Pool.Get,Pool.Put 通常是配套使用的,但是也绝对不是硬性要求,PoolGet 出来的元素使用完之后,就算不调用 Pool.Put 放进池子也不会成为垃圾,而是自然再没有人用到这个对象的时候,GC 会释放他。
举个极限的例子,如果我使用 Pool 的姿势上做下改动,每次都 Pool.Get ,一次都不调用 Pool.Put ,那么会有什么情况发生?
答案是:没啥情况发生,程序照常运行。只不过 Pool 每次 Get 的时候,都要执行 New 函数来构造对象而已,Pool 也失去了最本质的功能而已:复用临时对象。调用 Pool.Put 调用的本质目的就是为了对象复用。
3. Pool 本身允许复制之后使用吗?
不允许,但是你可以做的到。什么意思?
如果你在代码里 copy 了一个 Pool 池,你的代码 go build 是可以编译通过的,但是可能会导致内泄露的问题。在结构体 struct Pool 的实现中中已经明确说了,不允许 copy 。以下为官方原话:
// A Pool must not be copied after first use.
在 struct Pool 有一个字段 Pool.noCopy 明确限制你不要 copy,但是这个只有运行 go vet 才能检查出来(所以大家的代码编译之前一定要 go vet 做一次静态检查,可以避免非常多的问题)。
$:~/pool$ go vet test_pool.go
# command-line-arguments
./test_pool.go:26:20: assignment copies lock value to bufferPool2: sync.Pool contains sync.noCopy思考下,为什么要 Pool 禁止 copy ?
因为 Copy 之后,对于同一个 Pool 里面 cache 的对象,我们有了两个指向来源,原 Pool 清空之后,copy 的 Pool 没有清理掉,那么里面的对象就全都泄露了。并且 Pool 里面的无锁设计的基础是多个 Goroutine 不会操作到同一个数据结构,Pool 拷贝之后则不能保证这点。类似 sync.WaitGroup, sync.Cond 首字段都用了 noCopy 结构,所以这两个结构体也是不能 copy 使用的。
所以,Pool 千万不要 copy 使用,编译之前一定要 go vet 检查代码。
总结
以上知识点做个总结:
- Pool 本质是为了提高临时对象的复用率;
- Pool 使用两层回收策略(local + victim)避免性能波动;
- Pool 本质是一个杂货铺属性,啥都可以放。把什么东西放进去,预期从里面拿出什么类型的东西都需要业务使用方把控,Pool 池本身不做限制;
- Pool 池里面 cache 对象也是分层的,一层层的 cache,取用方式从最热的数据到最冷的数据递进;
- Pool 是并发安全的,但是内部是无锁结构,原理是对每个 P 都分配 cache 数组(
poolLocalInternal数组),这样 cache 结构就不会导致并发; - 永远不要 copy 一个 Pool,明确禁止,不然会导致内存泄露和程序并发逻辑错误;
- 代码编译之前用
go vet做静态检查,能减少非常多的问题; - 每轮 GC 开始都会清理一把 Pool 里面 cache 的对象,注意流程是分两步,当前 Pool 池 local 数组里的元素交给 victim 数组句柄,victim 里面 cache 的元素全部清理。换句话说,引入 victim 机制之后,对象的缓存时间变成两个 GC 周期;
- 不要对 Pool 里面的对象做任何假定,有两种方案:要么就归还的时候 memset 对象之后,再调用
Pool.Put,要么就Pool.Get取出来的时候 memset 之后再使用; - 本篇文章配合动画演示一起学习效果更佳哦;