Linus Torvalds 命名 [ 冰封荒原 ] 版 Linux 内核的思考
大纲
-
奇闻轶事
-
什么是单点故障?
-
怎么解决?
-
问题来了
-
怎么保持一致性?
-
一致性的分类
-
Write-All-Read-One
-
Quorum
-
Raft 算法
-
总结
奇闻轶事
Linux 作者 Linus Torvalds 在 5.12 合并窗口开启两周之后发布了 Kernel 5.12-rc1 版本,在邮件列表里 Linus Torvalds 爆料自己经历了六天没有电的生活。
“So I was actually without electricity for six days of the merge window, and was seriously considering just extending the merge window to get everything done,”
上个月中旬,美国德州和俄勒冈州波特兰遭遇罕见的严寒天气和暴风雪,持续多天的停电,Linux 作者就生活在波特兰。因为这次经历,他为 5.12 起了代号 Frozen Wasteland(冷冻荒原)。Linux 5.12 的正式版本预计会在四月底或五月初发布。
听起来算是一个 IT 界的轶事,这次事件也同样反应了一个存在于 Linus Torvalds 的单点故障问题。
什么是单点故障?
百度百科的解释:
英文:single point of failure,缩写SPOF,是指系统中一点失效,就会让整个系统无法运作的部件,换句话说,单点故障即会整体故障。
在我们存储系统的架构里来,如果有单点故障了会导致什么后果?
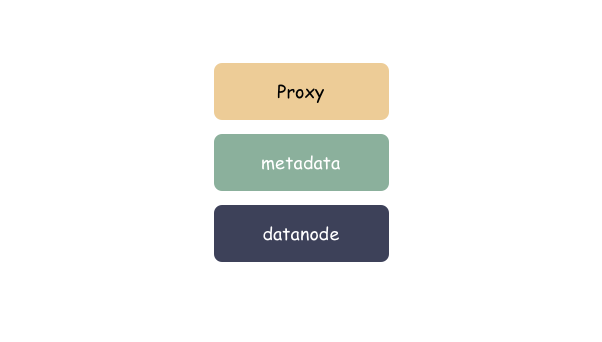
云存储一般的系统架构分为三大块:
- 客户端 proxy:负责协议解析
- 元数据服务 metadata:负责存储对象元数据
- 数据节点 datanode:负责存储对象数据
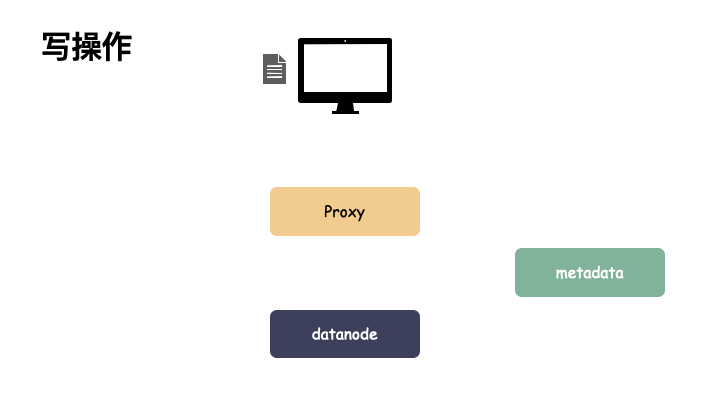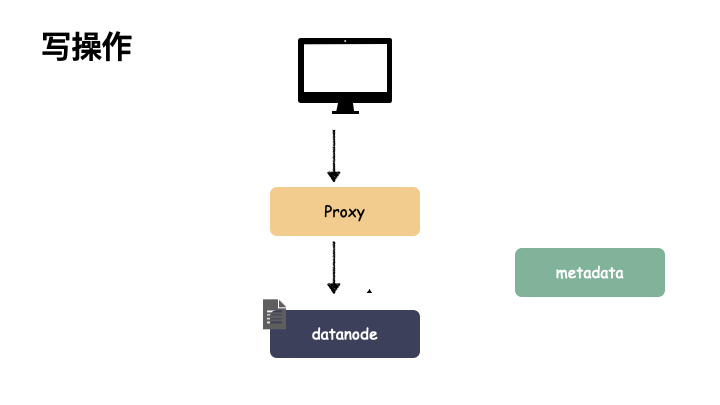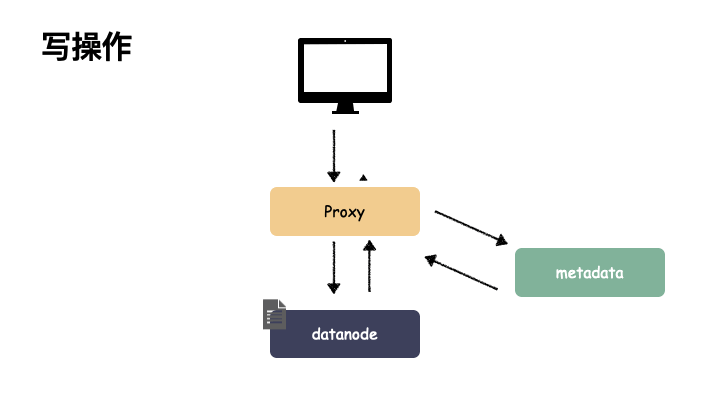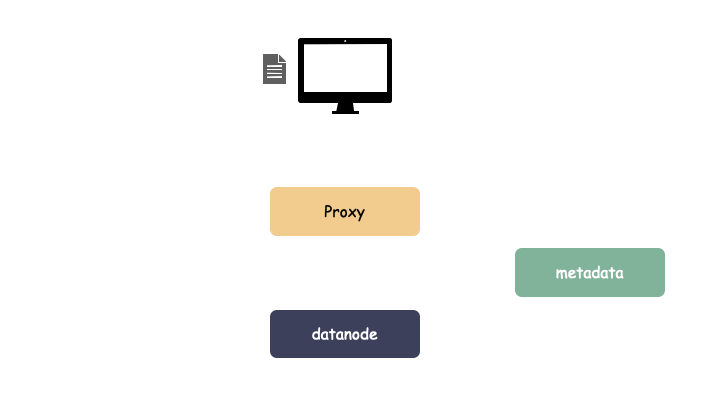
写操作:
读操作:
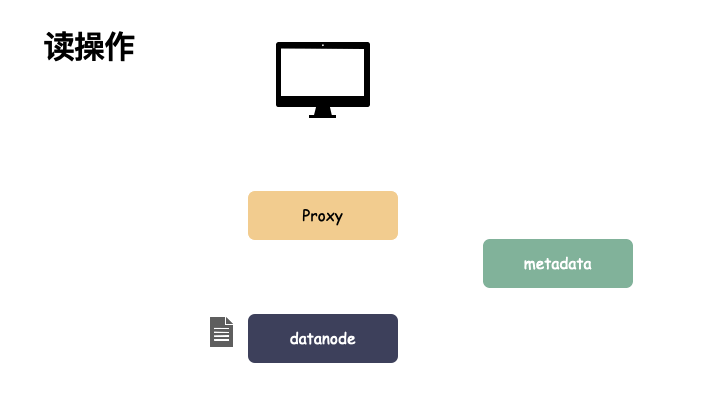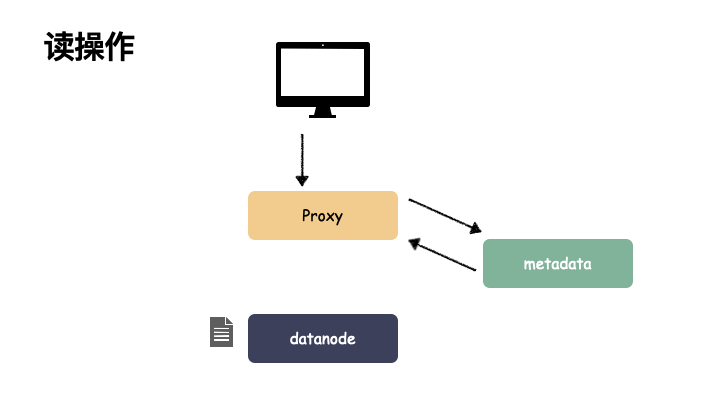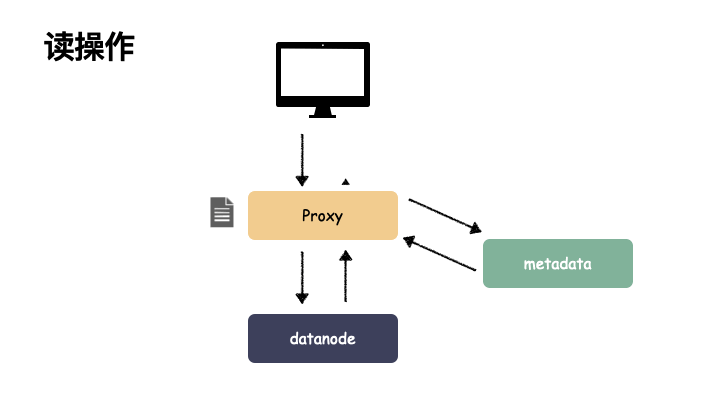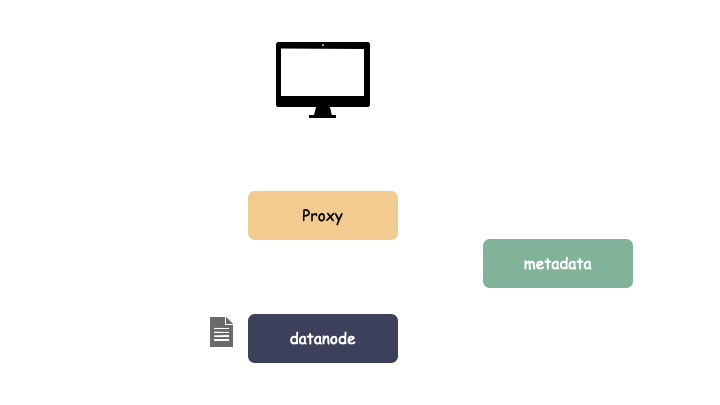
假如,我们系统架构全都是单组件,我们来看看当出现单点故障之后:
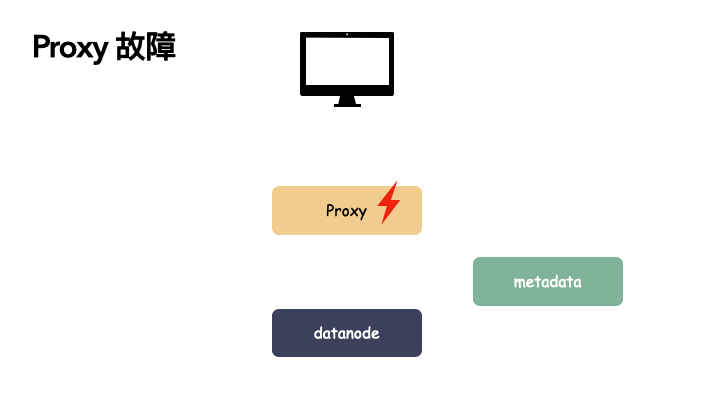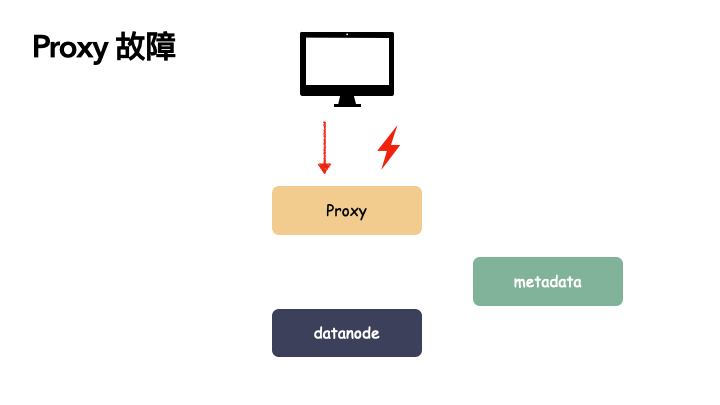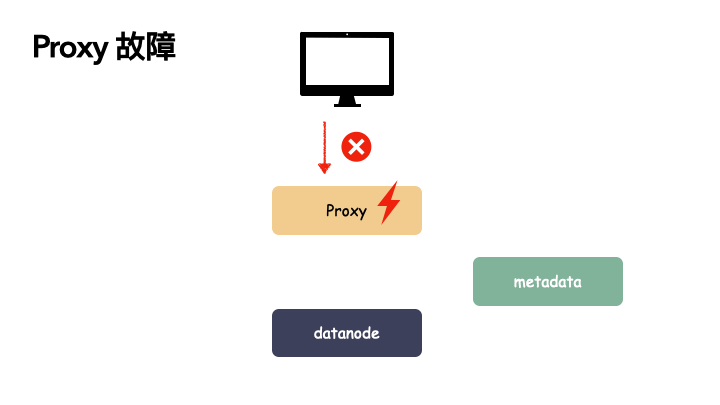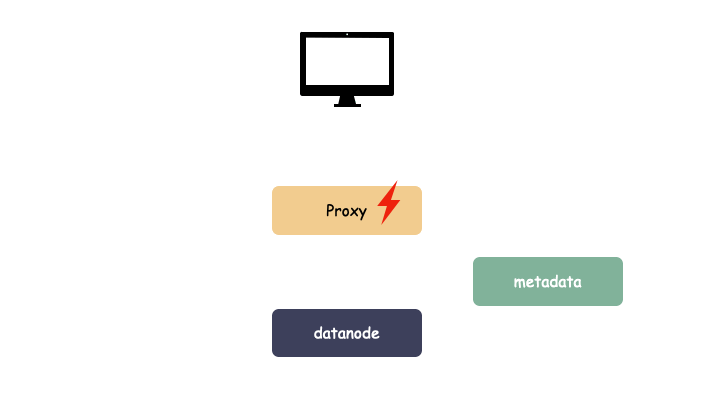
客户端 proxy 单点故障:
由于 proxy 是负责与用户交互的门户。如果 proxy 出现故障,则会导致用户功能异常,可用性掉 0 。读写服务全都提供不了,但由于 proxy 是无状态的节点,本身不带状态,所以不影响数据的可靠性,只要故障能恢复或者新部署一个 proxy 组件都是可以恢复对外功能的。
元数据服务 metadata 单点故障:
metadata 节点存储的是对象元数据,是重要的数据。如果这个组件单点了,那就不再只是可用性的问题了,如果这个节点不能恢复,metadata 数据丢失,相当于用户数据丢失,基本上一切付之东流,从头再来了。
metadata 故障会导致读失败(已经存储进去的数据读不到)。

也会导致写故障,写不下去数据。
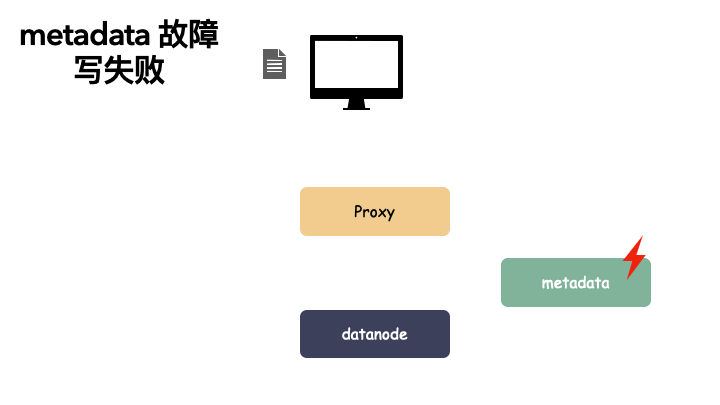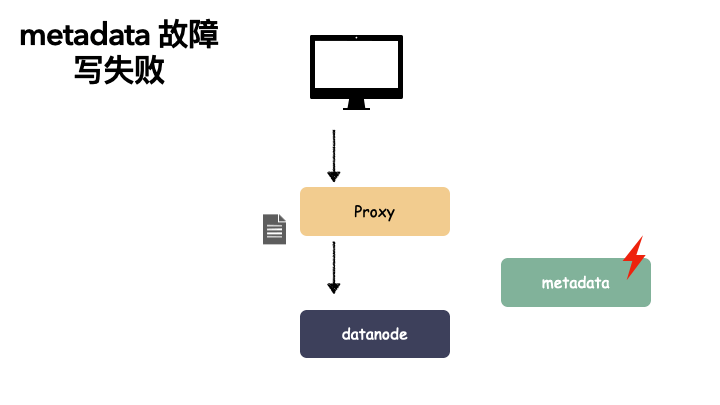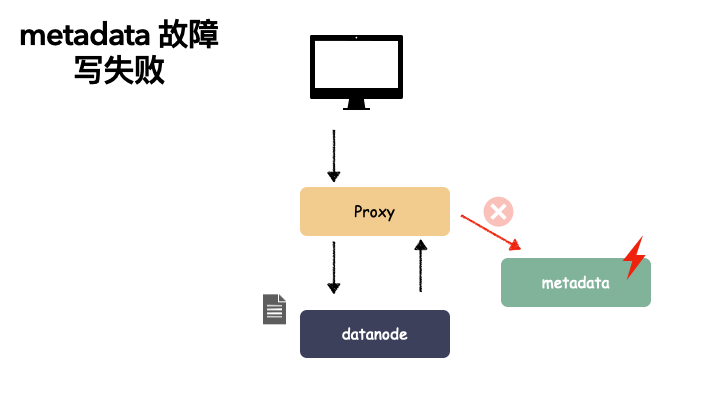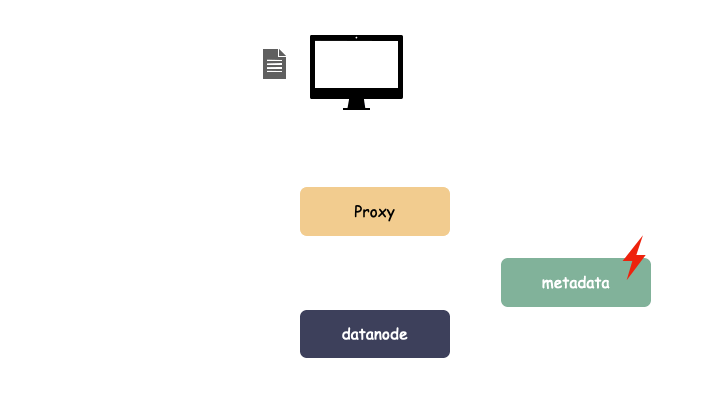
数据节点 datanode 单点故障:
datanode 存储的是对象数据,如果这个故障,相当于用户数据丢失了。常言道数据就是生命,所以你可以瑟瑟发抖了。

所以从上面表现来看,特别是我们做数据存储服务的,无论是有状态还是无状态的组件,单点故障都是不可容忍的故障。
怎么解决?
那么怎么解决呢?解决的思路非常简单,千千万万的架构都用一句话概括:冗余。冗余简单理解就是用多个组件,数据搞多个副本。
那我们接下来看不同的组件冗余带来的不同的考量。
proxy 用多个组件:
由于有多个 proxy,其中一个故障,另一个组件还能提供服务,并且由于 proxy 节点只做协议解析,不存储状态,所以不影响关键路径。以下是写操作的演示:
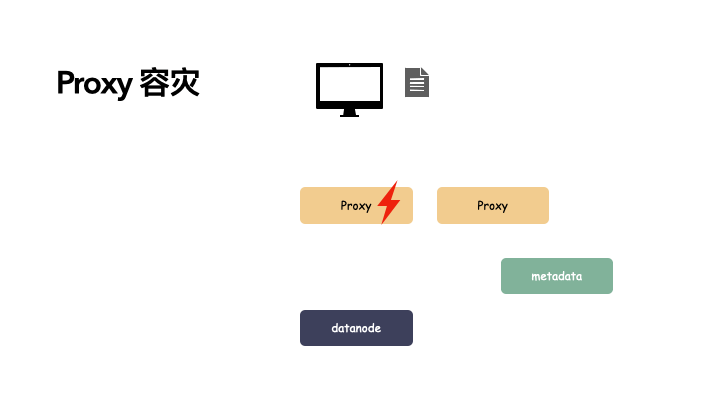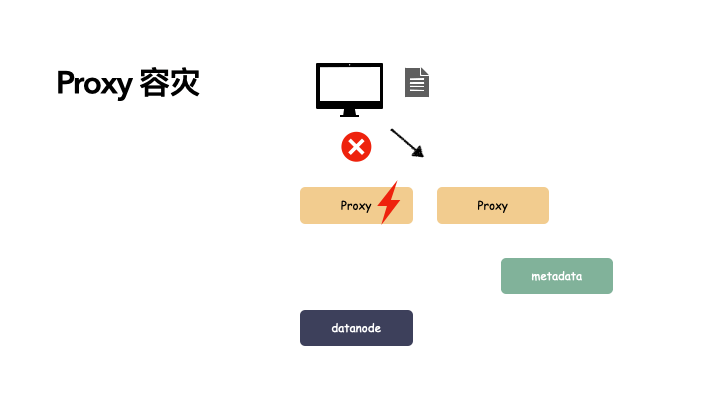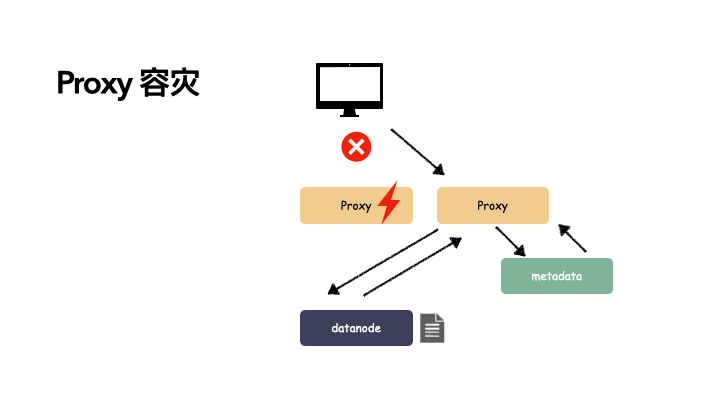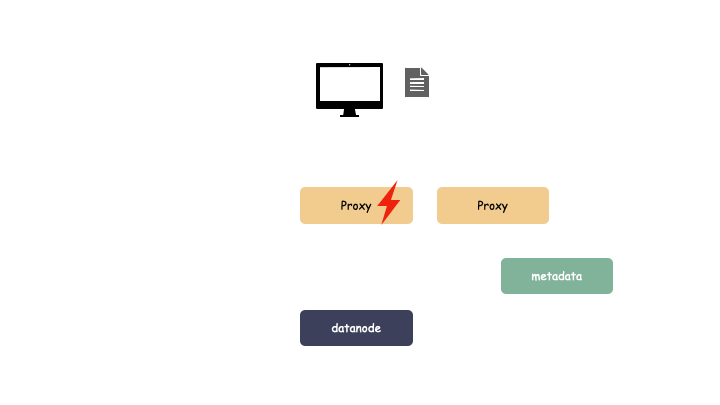
而这种无状态的节点冗余要解决的就是故障自动剔除和服务发现,一般引入一些类似于 consul 或者 ectd 这样的组件来管理。
metadata 和 datanode 多个节点:
metadata 和 datanode 必须提一点,由于这两个节点是存储状态的,所以多节点不仅是要对组件(逻辑)的冗余,还有数据副本的冗余。以下,我们看一个荆棘丛生的数据读取过程:
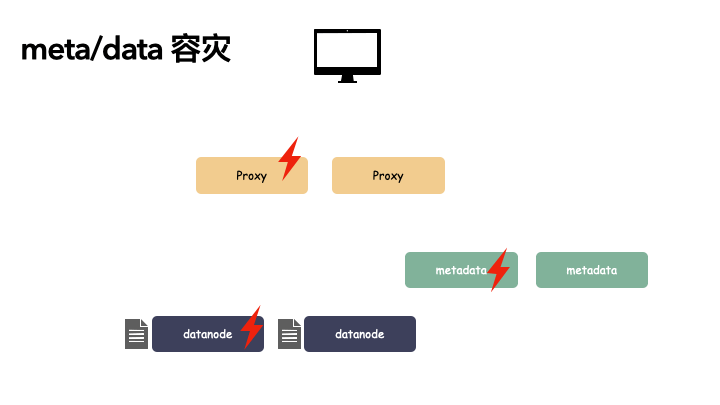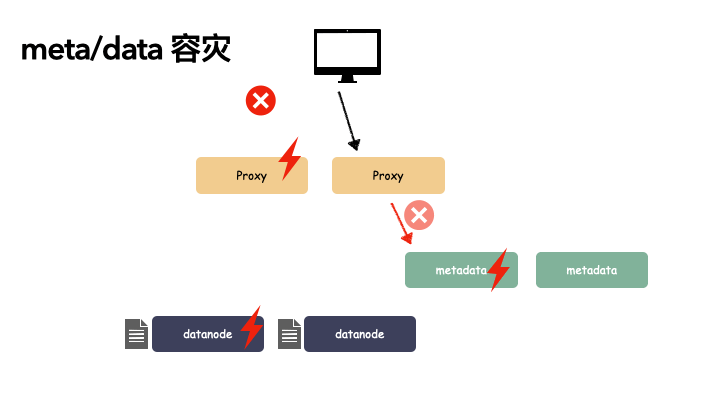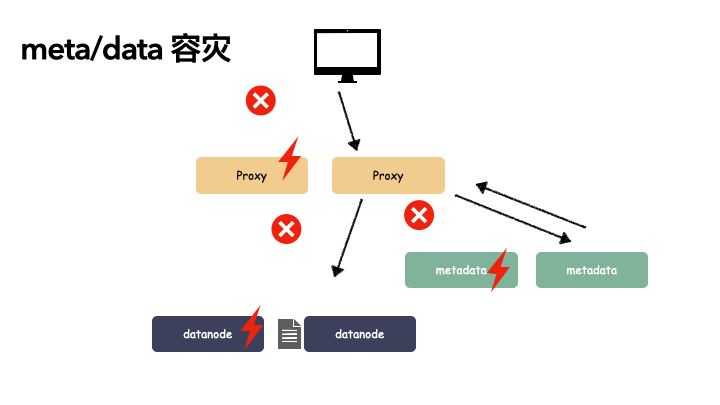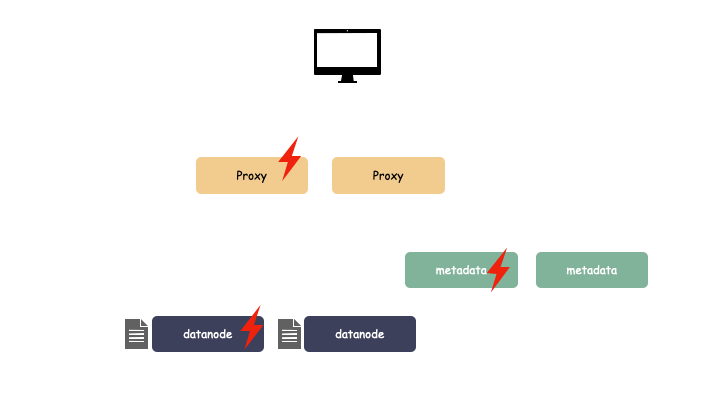
我们对 proxy,metadata,datanode 都做了一个冗余备份,上图我们也看到在如此恶劣的条件下,我们还是把数据读了上来。
一般来讲,带状态的组件可以用下面的等式:
组件 = 逻辑 + 状态输入
这种节点冗余要考虑两方面:
- 逻辑组件的冗余:多个的组件(二进制进程);
- 状态:这个也就是数据,数据做冗余,也就是我们说的副本,常见冗余方式有两种:多副本、纠删码;
这两部分都要做冗余,由于有多个节点,其中一个跪了,另一个节点也能提供服务。
- 组件有多个,一个故障了,还有其他节点做决策,并且提供写入;
- 数据有多个副本,一个故障丢了,还有其他副本提供读;
问题来了
我们现在知道了一个容灾的灵丹妙药就是冗余,但是就像人多了一样,意见很难统一,如果每个节点都不拘束,按照各自的意愿搞事情,那系统就要乱了,错乱的数据可能比数据丢失的后果还严重,因为你给了别人错的数据相当于欺骗,会造成更严重的后果。
多个节点怎么才能对外是一个整体(也就是说看起来必须是一个人来做决策),怎么来解决这个矛盾?
这里就谈到分布式系统下数据冗余最难的一个问题:一致性。
多个节点的时候,你可以让所有节点都来做决策,但是对外最终是要一致的声音。一致性:通俗话说,就是决策和承诺要对外保持始终一致。
怎么保持一致性?
说到分布式系统下数据的一致性就不得不提 CAP 理论了,CAP 理论提到,一致性、可用性、分区容错 只能 3 者取 2 ,你不能都要。
按照现实的场景来说,网络分区是现实必然发生的事情,这个是你没得选,分区容错一定要保证的是事情,所以你只能在 C 和 A 里面选。如果你要保证数据一致性,那么必然牺牲可用性。
举个例子:以下有 3 个副本,3 个数据副本位置都写成功才算是真正的 3 个副本数据一致了。这个时候可靠性是最高的,但可用性最差。
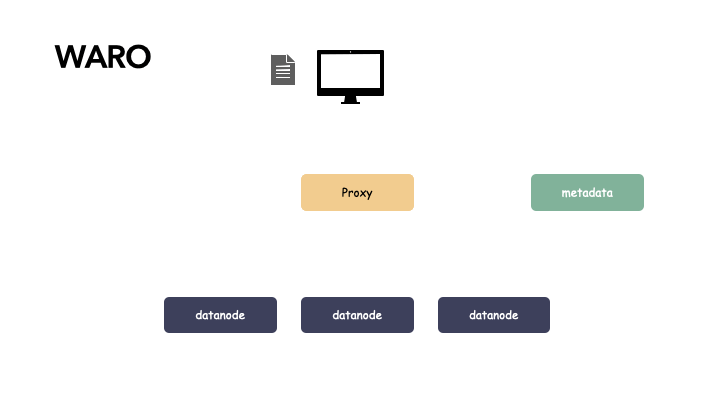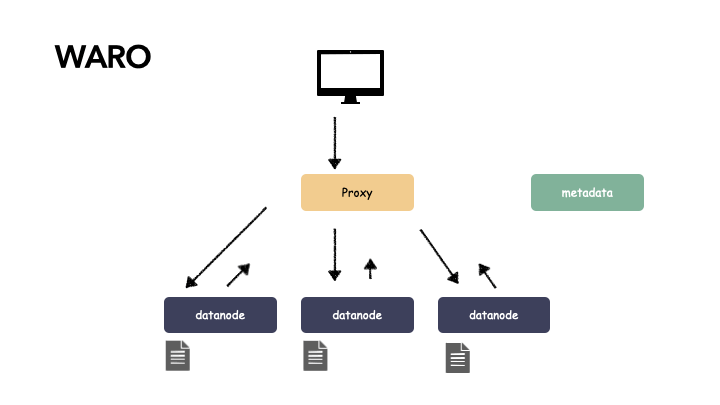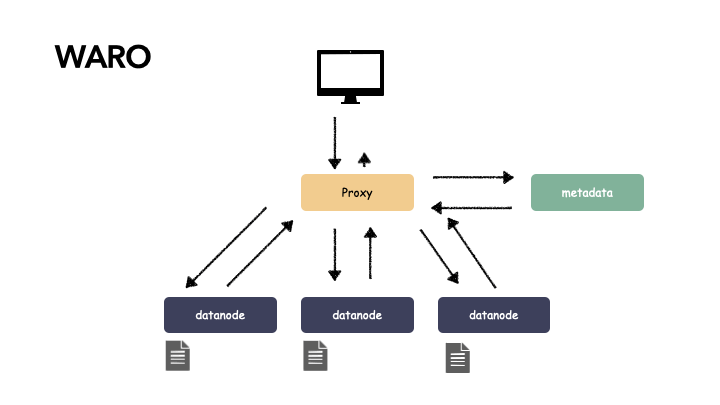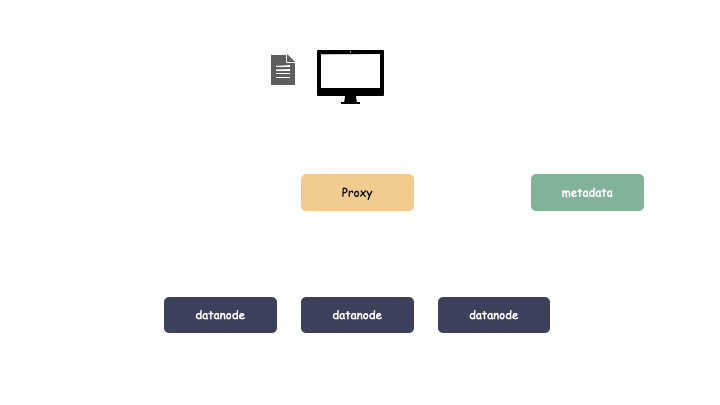
为什么?因为你要保证 3 个地方都成功,这往往是比较难并且慢的。原因大概有两点:
原因一
冗余就是多个数据副本,多个副本是为了增加可靠性,避免数据单点,所以往往多个副本物理上不会放在一起,比如:不会放在一个机柜,因为这个机柜坏了,就全没了嘛,也不会放在一个机房,因为你会想,这个机房炸了怎么办?甚至不放在一个地域(跨地域复制)。
极限的情况,你甚至想放在两个不同的宇宙(哈哈哈,一个宇宙毁灭还有另一个)。
玩笑归玩笑,物理上尽可能隔离的考量都是为了避免故障的牵连,但是问题又来了,同一份数据的副本放的越远,同步要消耗的代价就越高。
原因二
从概率学来讲,数量越多,整体失败的概率越大,怎么说?
假设一个节点故障的概率是 10%,如果你有 10 个节点,那么就是 100 % 会有一个节点故障。
在以上图示,我们已经做到了系统内部的数据完全一致,但是可用性却非常差,所以往往我们又会想,怎么才能可用性呢?
所以,你看到了吗?不是不能做到一致性,而是我们想要的太多,所以才导致一致性问题的复杂。下面我们简单看下一致性的分类,我们从两个视角来观察一致性。
一致性的分类
我们有两个视角,解释一致性
- 一个是用户的视角;
- 一个是系统的视角;
用户的视角,一致性主要指的是并发访问时更新过的数据如何获取的问题。
系统的视角,则是更新如何复制分布到整个系统,以保证数据完全一致。
从客户端角度,多进程并发访问时,更新过的数据在不同进程如何获取的不同策略,决定了不同的一致性。比如,对于数据库来说,
- 要求更新过的数据一定能被后续的访问都能看到,这是强一致性;
- 能容忍后续的部分或者全部访问不到,则是弱一致性;
- 经过一段时间后要求能访问到更新后的数据,则是最终一致性,而最终一致性本质上是弱一致性的特例。
从系统内部组件的角度来讲,笔者一般只做两种区分:
- 数据完全一致
- 数据不完全一致
从系统角度,如何尽快将更新后的数据分布到整个系统,降低达到最终一致性的时间窗口,是提高系统的可用度和用户体验则是重要的考量因素。
系统角度来说,一致性问题的根源都在于复制行为。所有的一致性问题都跟你的复制策略有关,更新复制有两大类策略:
- 最简单的 Write-All-Read-One 策略,简称 WARO,也就是常说的所有写成功才算对用户成功;
- Quorum 策略机制,也就是大部分写成功就认为成功的一种策略,这个是牺牲系统可靠性来换取可用性的一种机制;
下面我们看一下这两种的优缺点。
Write-All-Read-One
对于多副本冗余的系统来说,写的时候,所有的副本节点写都成功才算成功(write all),读的时候就可以随便读一个副本即可(read one)。这个就很容易理解,因为有这么个假设存在:只要写成功了,那么多副本的数据就是一致的,你随便读哪个都是正确的数据(不考虑静默或其他问题,静默导致的问题用数据自校验解决)。
现在我们想一个问题,为什么 WARO 的模式下,在读的时候可以随便读任一副本的数据?
关键在于:我们读的是写成功的数据,这个是 Write-All 这个前提保证的。
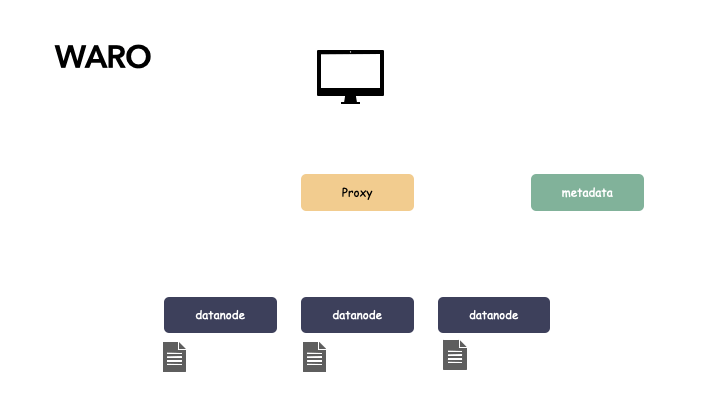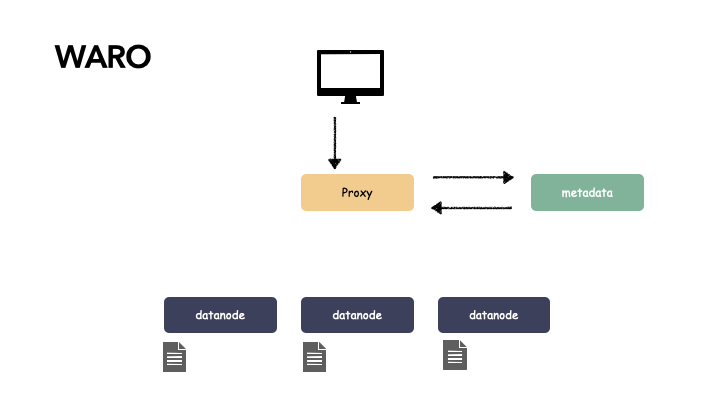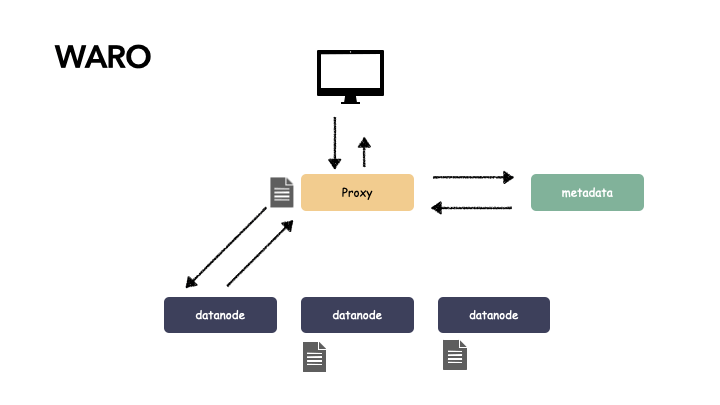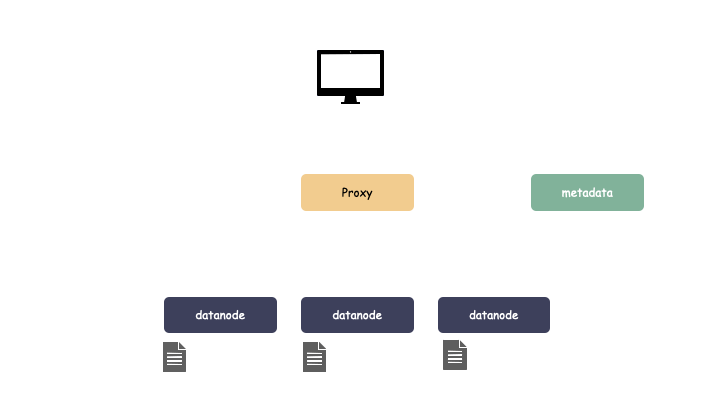
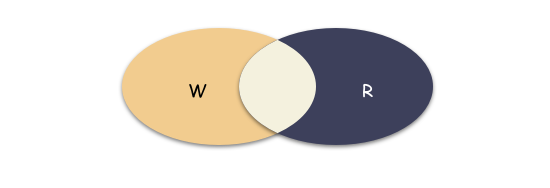
思考下 WARO 的优缺点:
优点:
- 实现简单,无需考虑复杂的异常处理,读的时候高效;
缺点:
- 写的可用性不大好,由于更新写操作需要在所有的 N 个副本都成功,写操作才算成功,所以一旦有一个副本异常,写失败,则更新操作不可用。对于更新服务来说,虽然系统有 N 个副本,但系统却无法容忍任何一个副本异常;
- 读的可用性挺好的,N 个副本中,只要有一个副本正常提供服务,系统就可以提供读服务,换句话说,系统可以容忍 N-1 个副本异常;
所以,我们看到 WARO 读写可用性的区别,更新服务的可用性最低,系统虽然使用了多副本,但是更新操作的可用性等效于没有副本(换句话说,多副本并没有带来可用性的提升)。
能优化这个吗?可以的,还是 CAP 理论,WARO 保证了数据的高度一致性,但是牺牲了写更新的可用性,我们的优化思路就是把可用性适当上调,数据的一致性就会下降,也就演变成我们的 Quorum 机制。Quorum 就是提高写更新可用性的一种机制。
Quorum
Quorum 定义
WARO 牺牲写更新的可用性,带来了系统的简洁性,也是读的可用性达到了副本机制的最高状态。我们把 WARO 条件放宽,不要求 Write-All,从而使得读写服务的可用性之间做个折中,这个就是 Quorum。
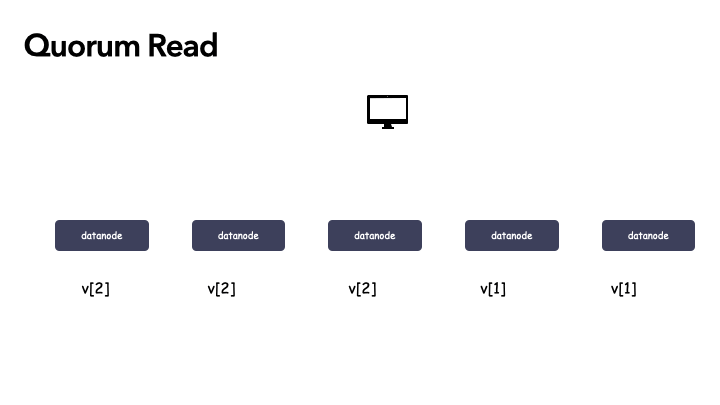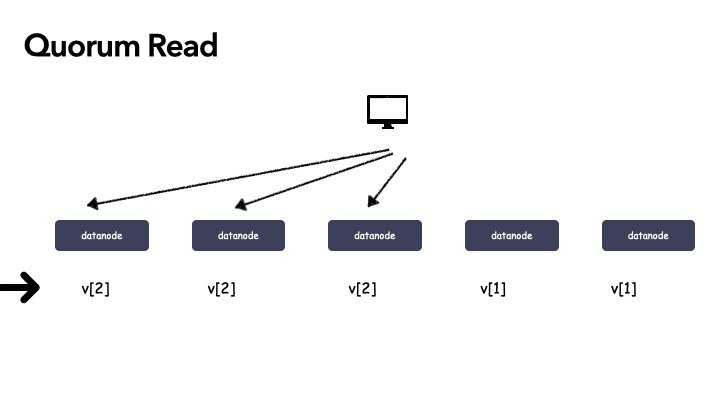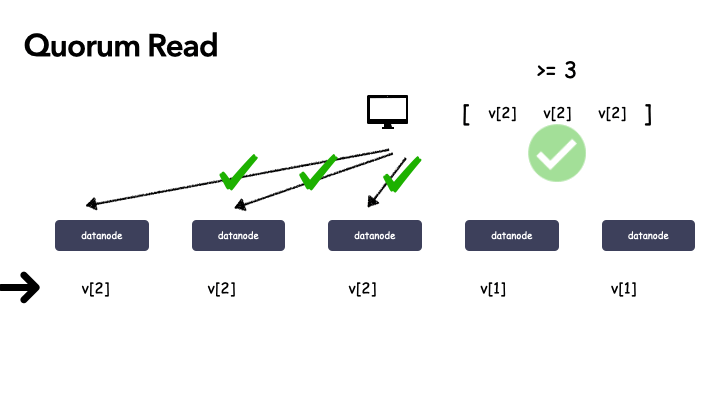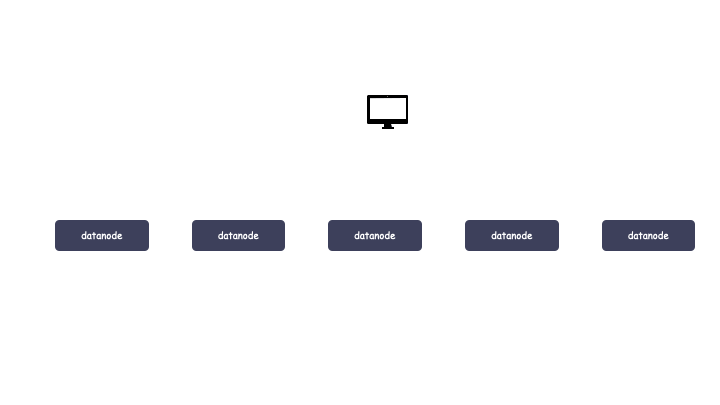
在 Quorum 机制中,当某次写更新操作 w[i] 在 N 个副本中的 W 个副本都成功,则就称该更新操作为“成功递交的更新操作”,对应的数据为“成功递交的数据” v[i]。
- 令 R > N - W,由于更新操作 w[i] 在 W 个副本上成功,所以在读取数据时,最多需要读取 R 个副本则一定能读到 w[i] 更新后的数据 v[i]。
- 如果某次更新 w[i] 在 W 个副本上成功,由于 W+R > N,任意 R 个副本组成的集合一定与成功的 W 个副本组成的集合有交集,所以读取 R 个副本一定能读到 w[i] 更新后的数据 v[i]。
原理图示:
仔细体会下上面的描述,这个推演是这么来的:
- 由于 WARO 模式下更新操作条件太严苛,我们想提高更新操作的可用性,于是适当放宽,允许更新操作的时候 N 个中有失败的,成功 W 个也没关系,照样返回成功,这样写的可用性就上来了;
a . 虽然数据可靠性短时间的内会处于一个不完整的状态,但是带来的是可用性的提升;
2 . 由于引入 Quorum 机制后,更新操作成功的时候,N 个副本不一定都是最新成功的数据,所以我们读的时候就不能自由的读任意副本,而是一定要读到成功的数据才行,于是才有了每次读都要读 R 个副本,并且 R+W 要满足 > N 才行,因为这样才能保证你读到的 R 个副本里一定有包含正确的数据;
a . 保证了 R+W > N 这个条件,才能保证读的副本集合和写的副本集合有交集;
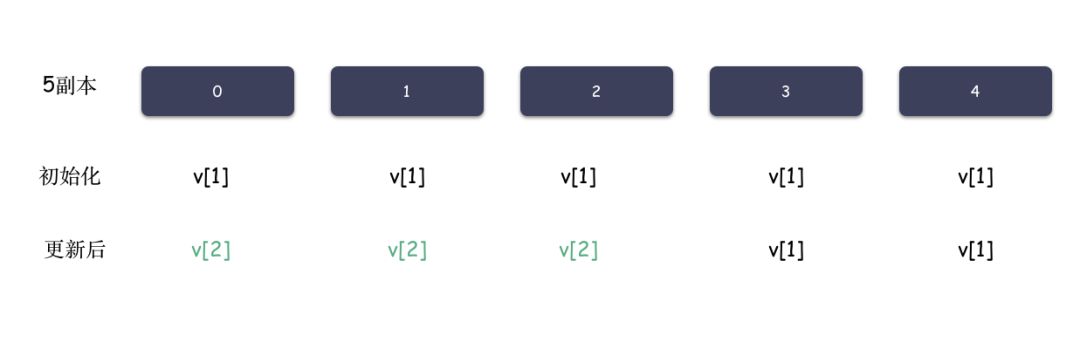
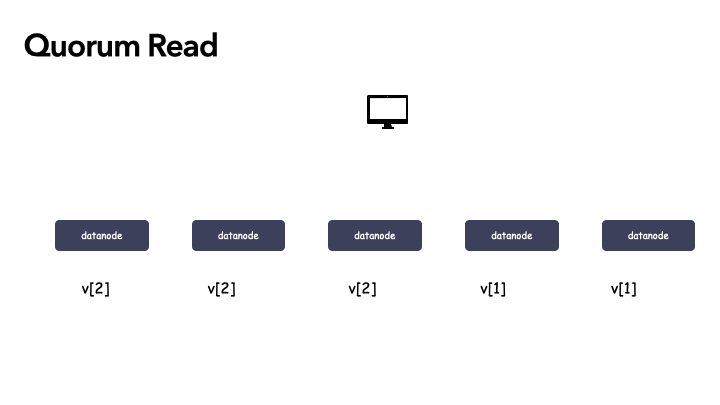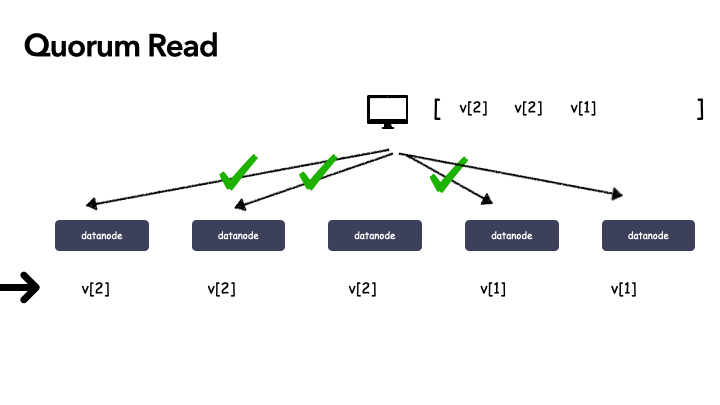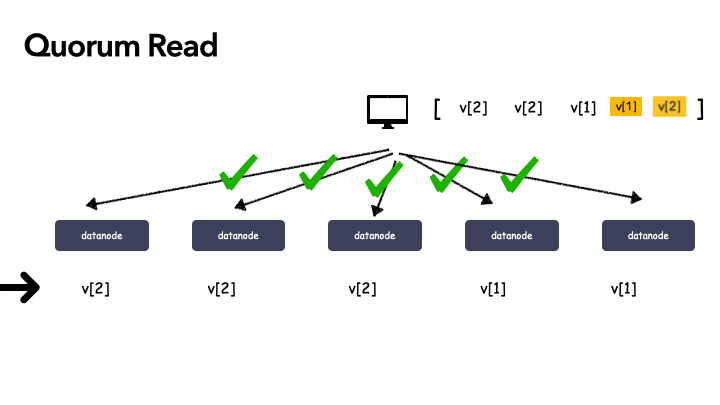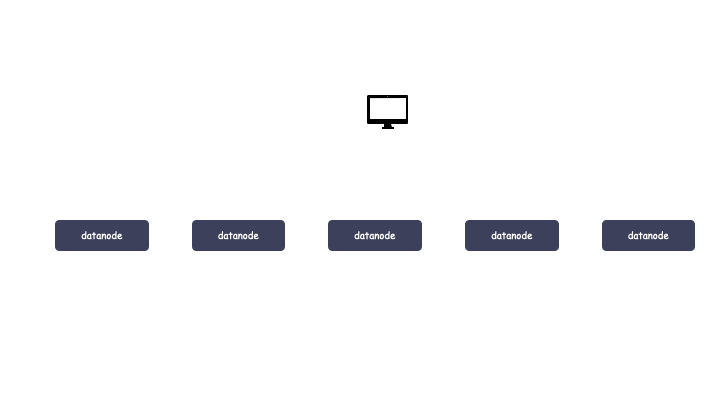
举例子,系统是 5 副本的,令 W=3,R=3,最初 5 个副本数据都一致,都是 v1,某次更新操作 w2 在前 3个副本成功,副本情况变成(v2 v2 v2 v1 v1)。此时,任意 3 个副本组成的集合中一定包含 v2。
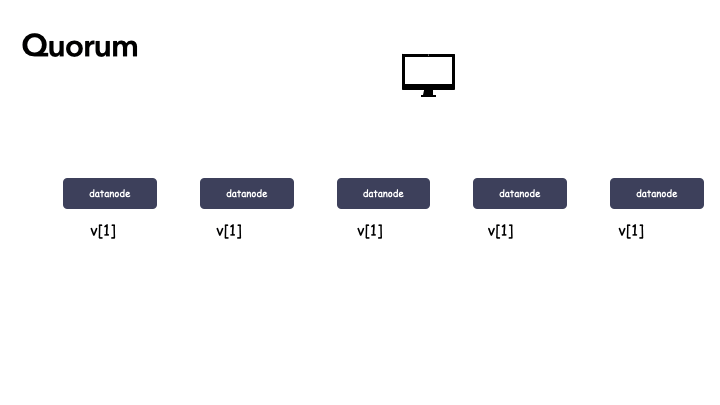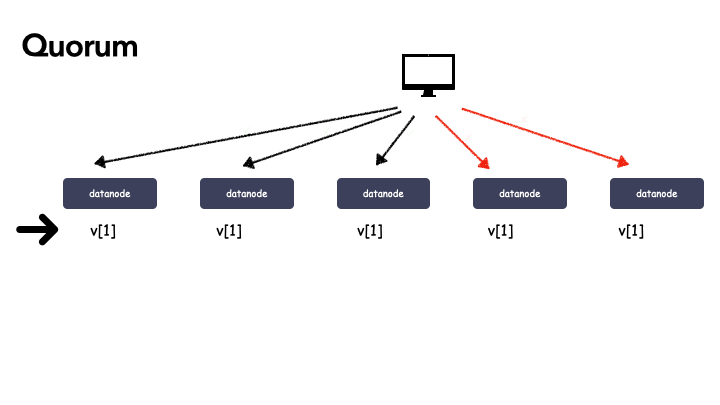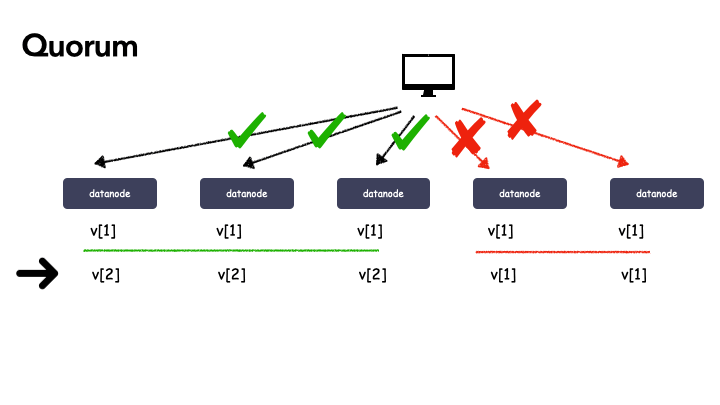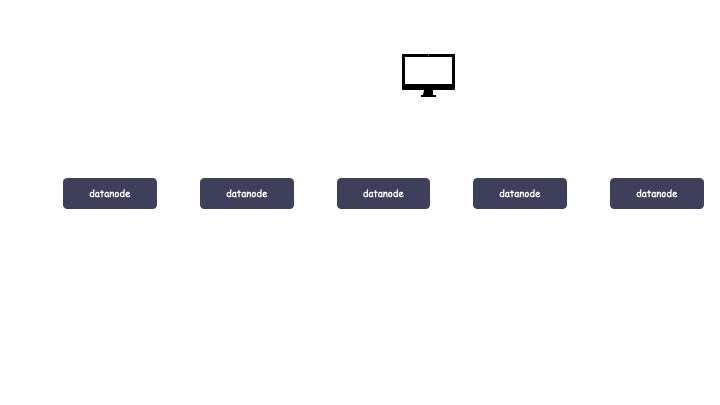
其实,上述定义中,令 W=N,R=1,其实就等价 WARO,所以这么来讲,WARO 是 Quorum 机制的一种特例。
思考一个问题:你读 R 个副本数据上来,虽然一定包含了正确的数据,但是你怎么甄别出来正确的数据?记得不要代入你的上帝视角哈。
针对这个问题,我们有个很重要的结论:只依赖 quorum 机制是无法保证数据的强一致性的。因为就算你读到了正确的数据,假如没有其他手段辅助的话,你也是无法甄别出正确的数据的。
举个例子:
- 5 副本的系统,令 W = 3,R=3,初始化值都是 v1,则为 [v1, v1, v1, v1, v1 ]
- 一次写更新之后,系统状态变成 [v2, v2, v2, v1, v1]
- 由于 R=3,根据 qurom 的规则,我们只需要读到 3 份副本数据,就能读到正确的值。穷举下,那么 R =3 ,读到的副本列表有三种情况:
- [v2, v2, v1]
- [v2, v2, v2]
- [v2, v1, v1]
我们看到 无论哪种,v2 都在列表里,我们站在上帝视角,自然知道这个就是正确的数据, 但是对于这三种场景,你需要怎么处理才能确保每次都识别出正确的数据是 v2 呢?
其实只有第二种情况 [v2, v2, v2],你才能断定 v2 是正确的,因为列表里全都是 v2。
第一种情况 [v2, v2, v1] 和 第三种情况 [v2, v1, v1] 你都还需要其他进一步的手段,你才能识别出正确的数据。比如第一种情况 [ v2, v2, v1 ] 你会取哪个值作为正确的值?v2?因为 v2 是多数?但是第三种情况下 v1 还是多数呢。
这种情况需要进行一些额外的操作来确认正确的副本,而且最终可能还无法区分。
如何确定最新递交的值?
Quorum 机制说明,只需要成功更新 N 个副本中的 W 个,在读取 R 个副本时,满足 W+R > N 的条件时,一定可以读到最新的成功的数据。但由于有更新失败的情况存在,仅仅读到 R 个副本却不一定能确定哪个是正确的数据。
还是以这个举例:假定 N=5,W=3,R=3 的系统,初始化为 [v1, v1, v1, v1, v1],成功一次更新之后,某时刻状态为 [v2, v2, v2, v1, v1] ,也就是前三个副本更新成功,由于 W=3,满足条件,那么本次算成功的更新。
这个时候,读取任何 3 个副本,一定能读到 v2,情况也不多,只有三种情况,我们穷举下:
- [v2, v2, v2]
- [v2, v2, v1]
- [v2, v1, v1]
我们无法判断究竟是 v1,还是v2是最新的成功递交的数据?
我们可以头脑风暴下;
方法一,每次写副本成功,再写一份元数据记录本次请求,比如把成功的版本 v2 记录下来,这样你就有办法知道数据正确的是哪个版本了。
方法二,或者,我们对读取条件做进一步加强:
- 限制递交的更新操作必须严格递增,即只有再前一个更新操作成功才可以递交后一个更新操作,从而成功递交的数据版本号必须是连续递增的;
- 读取 R 个副本,对于 R 个副本中版本号最高的数据,
- 若已存在 W 个,则认为该数据为最新的成功递交的数据
- 若存在个数少于 W 个,假设是 X 个,则继续读取其他副本,直到成功读取到 W 个该版本的副本,则该数据为最新的成功递交的数据;
- 若在所有副本中,该数据的个数还不满足 W 个,则 R 中版本号第二大的为最新的成功递交的副本;
所以我们再思考下,这三种情况:
情况一:[v2, v2, v2]
3 个副本都是 v2 ,v2版本的个数 >=3,那么 v2 就是最新成功的版本
情况二:[v2, v2, v1]
2 个数据是 v2,一个是 v1,那么还需要继续读,有两种情况:
1 . [v2, v2, v2, v1] :v2的个数 >=3 ,所以断定 v2 是最新成功递交的数据;
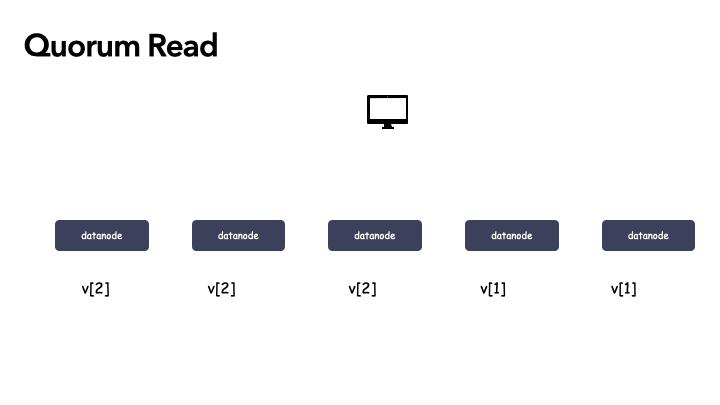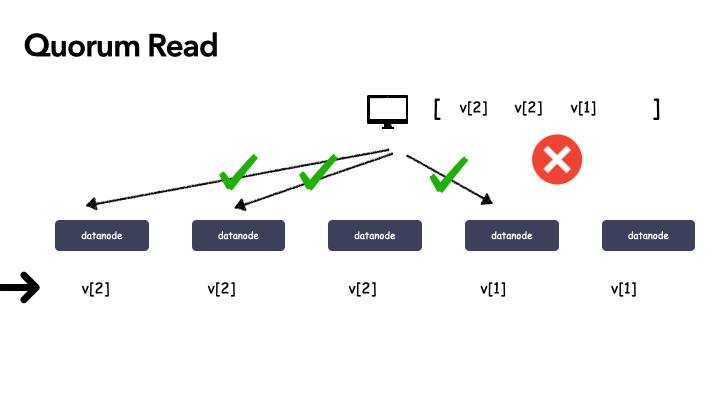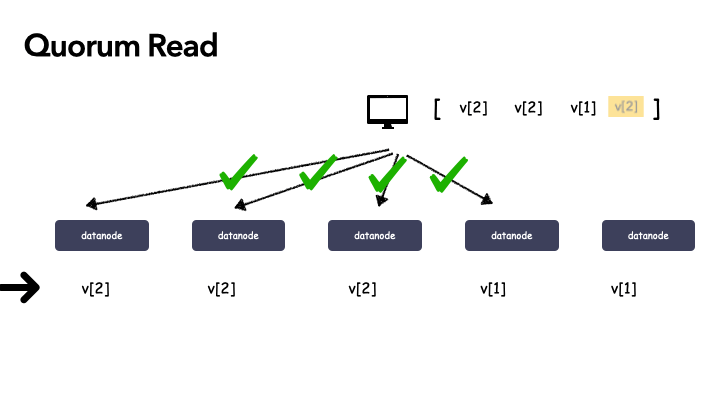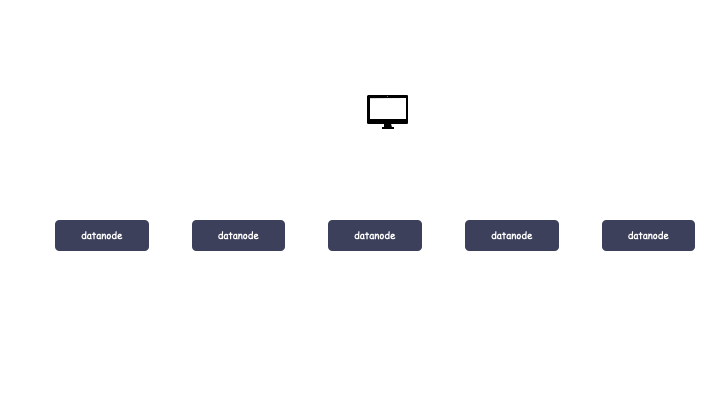
2 . [v2, v2, v1, v1] :这种情况还需要继续读,因为v2, v1的个数都还不满足 >= 3,需要继续读;
- [v2, v2, v2, v1, v1] :这个时候,终于可以断定,v2 就是成功递交的那个最新数据
情况三:[v2, v1, v1]
这个情况和情况 2 类似,也是继续读,直到某个数据版本个数满足条件 >= 3
如果这个继续读的过程失败,或者超时了,那么就无法判断了。
Raft 算法
Quorum 能不能解决一致性问题?
答案是可以,但是必须有特定的策略配合。Quorum 的核心要解决的问题是:怎么识别最新的数据?只要顺利解决这个问题,那么就解决 Quorum 的问题,也实现数据可证明的对外强一致性的语义。
当前,已经被数据严格证明的 paxos 算法,还有类 paxos 算法,都是解决了这个问题的。工程上实践最多的是 raft 算法,这个也是类 paxos 算法,因为比较简单,比如 Golang 的 etcd ,有兴趣可以去看开源算法。
raft 官方链接:https://raft.github.io/

而 raft 本质上就是一个 quorum 算法,raft 把一致性的算法问题简化分解成 3 个子问题:
- leader 选举;
- 日志复制;
- 安全性保证;
三个子问题本质上是三个重点:
- 重点一:冗余的多个节点是区分主从角色。也就是 leader - follower,leader 才能对外提供写;
- 重点二:数据复制的形式以 log 的形式。并且只能由 leader 发送给 follower ;
- 重点三:必须保证选出来的 leader 一定是正确、可靠的。这个怎么理解?通俗的话说就是,你策略怎么选我不管,但是一定要时时刻刻保证 leader 对外的承诺是强一致的,不能出尔反尔(比如,承诺了数据存好了,之后却丢了);
raft 解决了通用 quorum 的问题:也就是无法识别正确的数据是哪个的问题。raft 对外保证 leader 上一定是正确的数据,那么自然节点怎么成为 leader 将是最核心的的考量,这个就是算法的安全性来保证的。
好,我们再来思考一个问题,既然 leader 这么重要,但这里本质上引入了一个单点角色,一旦出现没有 leader 的场景,比如现有 leader 故障了,系统处于待选举的中间状态的时候,在这个时间窗内,系统是必须停服的,对外无法提供服务,而这也是众多 raft 算法需要考量最多的一个方面,怎么减少停服的时间间隔。但是由于这个所谓的 leader 是可以通过共识算法选举出来的,所以不算真正的单点故障,因为总是能恢复。
今天我们从单点故障漫游容灾,再到一致性的实现,再谈到了 Raft 算法,今天就点到为止。Raft 算法之后会用一个更精彩的完整篇幅来学习,如果你喜欢本篇文章的动画可以留言,以后在合适的地方会尝试用更丰富直观的表达形式来分享知识。
总结
做个简单的总结
- 虽然停电了 6 天,Linus 还是如约给大家带来了 Linux 5.12-rc1(Frozen Wasteland) 版本,膜拜大神;
- 分布式系统架构里基本上是不能容许单点故障,无论是从可用性还是可靠性来说;
- 冗余是解决容灾的不二法宝,但是随之而来的一致性则是要解决另一个问题;
- 一切都逃不过 CAP 理论,WARO 策略就是最简单的强一致性策略。困难的不是得不到数据一致性,而是你既想要数据一致性又想要可用性;
- Quorum 机制是权衡数据一致性和可用性的最佳实践,paxos 算法的正确性已经被数学严格推导证明,raft 则是 paxos 算法的最常见的工程实现;
~完~