golang 垃圾回收(二)屏障技术
- 什么是屏障?
- golang 涉及到的三个屏障技术
- 原理分析
- 示例分析代码
- 先看逃逸分析
- 写屏障真实的样子
什么是屏障?
承接上篇概述,下面讨论什么是写屏障?先说结论:
- 内存屏障只是对应一段特殊的代码
- 内存屏障这段代码在编译期间生成
- 内存屏障本质上在运行期间拦截内存写操作,相当于一个 hook 调用
golang 涉及到的三个屏障技术
- 插入写屏障
- 删除写屏障
- 混合写屏障(旁白:其实本质上是两个,混合写屏障就是插入写屏障和删除写屏障的混合)
这三个名词什么意思?区别在哪里?
最本质的区别就是:我们说了,内存屏障其实就是编译器帮你生成的一段 hook 代码,这三个屏障的本质区别就是 hook 的时机不同而已。
原理分析
声明下,下面的例子使用的是 go1.13.3。
示例分析代码
一直说,写屏障是编译器生成的,先形象看下代码样子:
1 package main
2
3 type BaseStruct struct {
4 name string
5 age int
6 }
7
8 type Tstruct struct {
9 base *BaseStruct
10 field0 int
11 }
12
13 func funcAlloc0 (a *Tstruct) {
14 a.base = new(BaseStruct) // new 一个BaseStruct结构体,赋值给 a.base 字段
15 }
16
17 func funcAlloc1 (b *Tstruct) {
18 var b0 Tstruct
19 b0.base = new(BaseStruct) // new 一个BaseStruct结构体,赋值给 b0.base 字段
20 }
21
22 func main() {
23 a := new(Tstruct) // new 一个Tstruct 结构体
24 b := new(Tstruct) // new 一个Tstruct 结构体
25
26 go funcAlloc0(a)
27 go funcAlloc1(b)
28 }这里例子,可以用来观察两个东西:
- 概述篇提到的逃逸分析
- 编译器插入内存屏障的时机
先看逃逸分析
为什么先看逃逸分析?
因为只有堆上对象的写才会可能有写屏障,这又是个什么原因呢?因为如果对栈上的写做拦截,那么流程代码会非常复杂,并且性能下降会非常大,得不偿失。根据局部性的原理来说,其实我们程序跑起来,大部分的其实都是操作在栈上,函数参数啊、函数调用导致的压栈出栈啊、局部变量啊,协程栈,这些如果也弄起写屏障,那么可想而知了,根本就不现实,复杂度和性能就是越不过去的坎。
继续看逃逸什么意思?就是内存分配到堆上。golang 可以在编译的时候使用 -m 参数支持把这个可视化出来:
$ go build -gcflags "-N -l -m" ./test_writebarrier0.go
# command-line-arguments
./test_writebarrier0.go:13:18: funcAlloc0 a does not escape
./test_writebarrier0.go:14:17: new(BaseStruct) escapes to heap
./test_writebarrier0.go:17:18: funcAlloc1 b does not escape
./test_writebarrier0.go:19:18: funcAlloc1 new(BaseStruct) does not escape
./test_writebarrier0.go:23:13: new(Tstruct) escapes to heap
./test_writebarrier0.go:24:13: new(Tstruct) escapes to heap先说逃逸分析两点原则:
- 在保证程序正确性的前提下,尽可能的把对象分配到栈上,这样性能最好;
a . 栈上的对象生命周期就跟随 goroutine ,协程终结了,它就没了
2 . 明确一定要分配到堆上对象,或者不确定是否要分配在堆上的对象,那么就全都分配到堆上;
a . 这种对象的生命周期始于业务程序的创建,终于垃圾回收器的回收
我们看到源代码,有四次 new 对象的操作,经过编译器的“逃逸分析”之后,实际分配到堆上的是三次:
- 14 行 —— 触发逃逸(分配到堆上) a . 这个必须得分配到堆上,因为除了这个 goroutine 还要存活呢
2 . 19 行 —— 无 (分配到栈上) a . 这个虽然也是 new,单就分配到栈上就行,因为 b0 这个对象就是一个纯粹的栈对象
3 . 23 行 —— 触发逃逸 (分配到堆上) a . 这个需要分配到堆上,因为分配出来的对象需要传递到其他协程使用
4 . 24 行 —— 触发逃逸 (分配到堆上)
- 这次必须注意下,其实站在我们上帝视角,这次的分配其实也可以分配到栈上。这种情况编译器就简单处理了,直接给分配到堆上。这种就属于编译器它摸不准的,那么分配到堆上就对了,反正也就性能有点影响,功能不会有问题,不然的话你真分配到栈上了,一旦栈被回收就出问题了
写屏障真实的样子
再看下编译器汇编的代码:
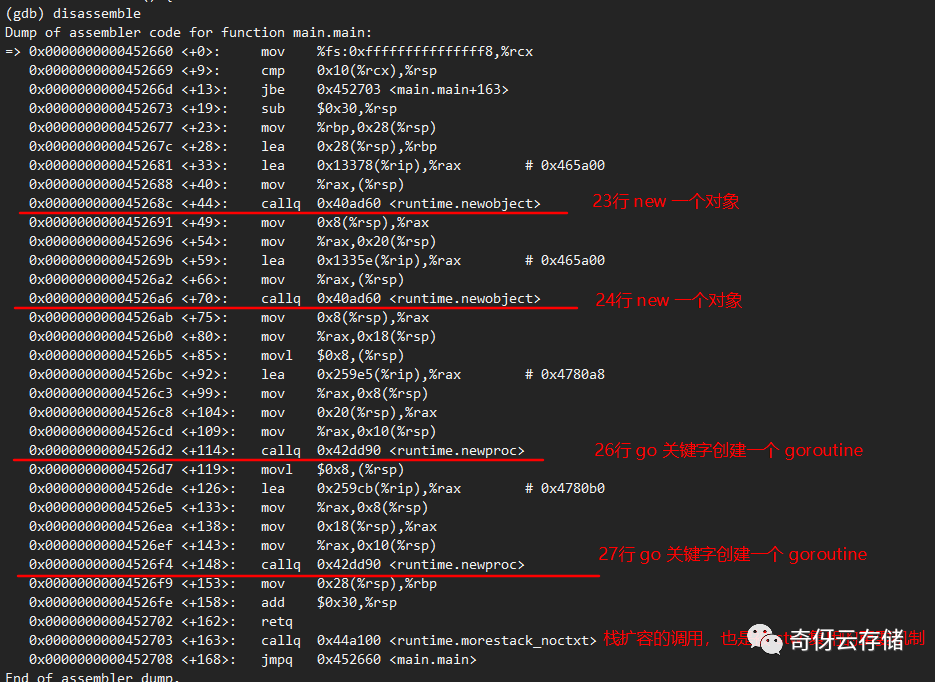
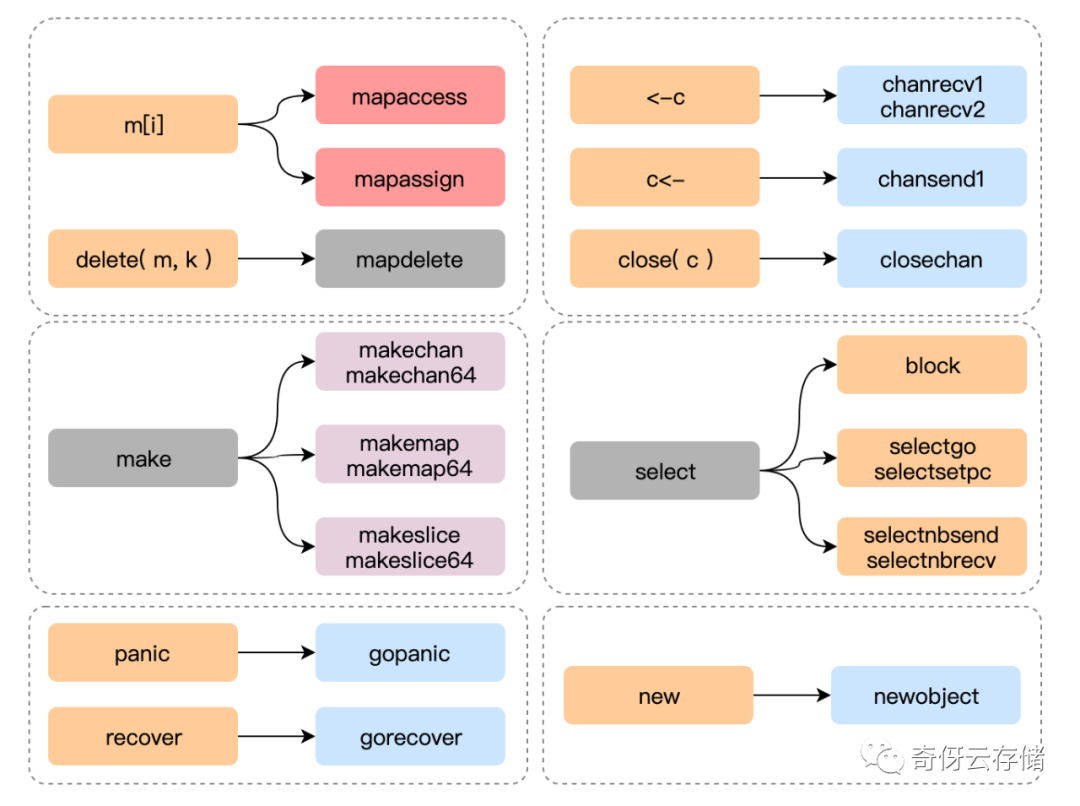
从这个地方我们需要知道一个事情,go 的关键字语法呀,其实在编译的时候,都会对应到一个特定的函数,比如 new 这个关键字就对应了 newobject 函数,go 这个关键字对应的是 newproc 函数。贴一张比较完整的图:
从这个汇编代码我们也确认了,23,24行的对象分配确实是在堆上。我们再看下函数 funcAlloc0 和 funcAlloc1 这两个。
main.funcAlloc0
13 func funcAlloc0 (a *Tstruct) {
14 a.base = new(BaseStruct) // new 一个BaseStruct结构体,赋值给 a.base 字段
15 }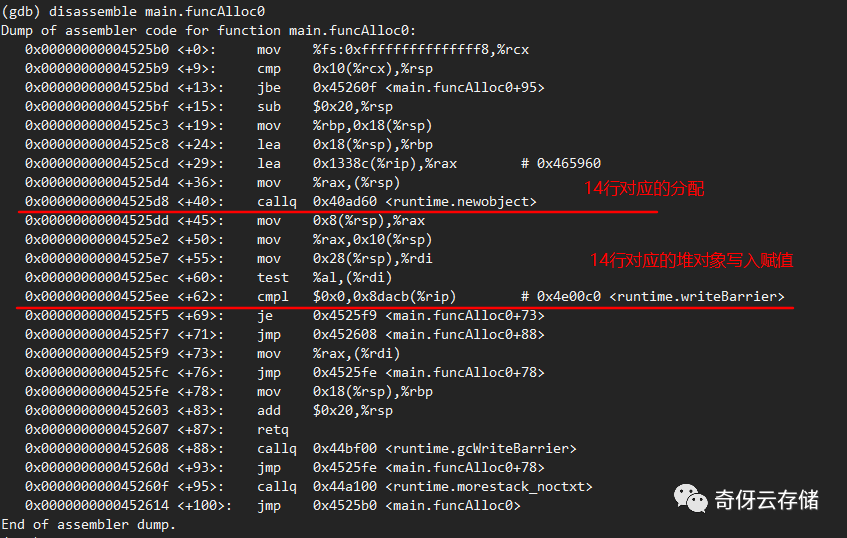
简单的注释解析:
(gdb) disassemble
Dump of assembler code for function main.funcAlloc0:
0x0000000000456b10 <+0>: mov %fs:0xfffffffffffffff8,%rcx
0x0000000000456b19 <+9>: cmp 0x10(%rcx),%rsp
0x0000000000456b1d <+13>: jbe 0x456b6f <main.funcAlloc0+95>
0x0000000000456b1f <+15>: sub $0x20,%rsp
0x0000000000456b23 <+19>: mov %rbp,0x18(%rsp)
0x0000000000456b28 <+24>: lea 0x18(%rsp),%rbp
0x0000000000456b2d <+29>: lea 0x1430c(%rip),%rax # 0x46ae40
0x0000000000456b34 <+36>: mov %rax,(%rsp)
0x0000000000456b38 <+40>: callq 0x40b060 <runtime.newobject>
# newobject的返回值在 0x8(%rsp) 里,golang 的参数和返回值都是通过栈传递的。这个跟 c 程序不同,c 程序是溢出才会用到栈,这里先把返回值放到寄存器 rax
0x0000000000456b3d <+45>: mov 0x8(%rsp),%rax
0x0000000000456b42 <+50>: mov %rax,0x10(%rsp)
# 0x28(%rsp) 就是 a 的地址:0xc0000840b0
=> 0x0000000000456b47 <+55>: mov 0x28(%rsp),%rdi
0x0000000000456b4c <+60>: test %al,(%rdi)
# 这里判断是否开启了屏障(垃圾回收的扫描并发过程,才会把这个标记打开,没有打开的情况,对于堆上的赋值只是多走一次判断开销)
0x0000000000456b4e <+62>: cmpl $0x0,0x960fb(%rip) # 0x4ecc50 <runtime.writeBarrier>
0x0000000000456b55 <+69>: je 0x456b59 <main.funcAlloc0+73>
0x0000000000456b57 <+71>: jmp 0x456b68 <main.funcAlloc0+88>
# 赋值 a.base = xxxx
0x0000000000456b59 <+73>: mov %rax,(%rdi)
0x0000000000456b5c <+76>: jmp 0x456b5e <main.funcAlloc0+78>
0x0000000000456b5e <+78>: mov 0x18(%rsp),%rbp
0x0000000000456b63 <+83>: add $0x20,%rsp
0x0000000000456b67 <+87>: retq
# 如果是开启了屏障,那么完成 a.base = xxx 的赋值就是在 gcWriteBarrier 函数里面了
0x0000000000456b68 <+88>: callq 0x44d170 <runtime.gcWriteBarrier>
0x0000000000456b6d <+93>: jmp 0x456b5e <main.funcAlloc0+78>
0x0000000000456b6f <+95>: callq 0x44b370 <runtime.morestack_noctxt>
0x0000000000456b74 <+100>: jmp 0x456b10 <main.funcAlloc0>
End of assembler dump.所以,从上面简单的汇编代码,我们印证得出几个小知识点:
- golang 传参和返回参数都是通过栈来传递的(可以思考下优略点,有点是逻辑简单了,也能很好的支持多返回值的实现,缺点是比寄存器的方式略慢,但是这种损耗在程序的运行下可以忽略);
- 写屏障是一段编译器插入的特殊代码,在编译期间插入,代码函数名字叫做
gcWriteBarrier; - 屏障代码并不是直接运行,也是要条件判断的,并不是只要是堆上内存赋值就会运行
gcWriteBarrier代码,而是要有一个条件判断。这里提前透露下,这个条件判断是垃圾回收器扫描开始前,stw 程序给设置上去的;
a . 所以平时对于堆上内存的赋值,多了一次写操作;
伪代码如下:
if runtime.writeBarrier.enabled {
runtime.gcWriteBarrier(ptr, val)
} else {
*ptr = val
}说到 golang 传参数只用栈这点,这里就再深入挖掘一点,golang ABI(Application Binary Interface)标准就是这样的,传参数用栈,返回值也用栈。但是巧了,刚好,就有一些特例,我们今天遇到的 runtime.gcWriteBarrier 就是个特例,gcWriteBarrier 就故意违反了这个惯例,这里引用一段这汇编文件的注释:
// gcWriteBarrier performs a heap pointer write and informs the GC. // // gcWriteBarrier does NOT follow the Go ABI. It takes two arguments: // - DI is the destination of the write // - AX is the value being written at DI // It clobbers FLAGS. It does not clobber any general-purpose registers, // but may clobber others (e.g., SSE registers).
这里为了减少 GC 导致性能的损耗,使用了 rdi ,rax ,这两个寄存器来传参数:
- rdi :堆内存写入的地址
- rax :赋的值
我们继续看下 runtime·gcWriteBarrier 函数干啥的,这个函数是用纯汇编写的,举一个特定cpu集合的例子,在 asm_amd64.s 里的实现。这个函数只干两件事:
- 执行写请求
- 处理 GC 相关的逻辑
下面简单理解下 runtime·gcWriteBarrier 这个函数:
TEXT runtime·gcWriteBarrier(SB),NOSPLIT,$120
get_tls(R13)
MOVQ g(R13), R13
MOVQ g_m(R13), R13
MOVQ m_p(R13), R13
MOVQ (p_wbBuf+wbBuf_next)(R13), R14
LEAQ 16(R14), R14
MOVQ R14, (p_wbBuf+wbBuf_next)(R13)
// 检查 buffer 队列是否满?
CMPQ R14, (p_wbBuf+wbBuf_end)(R13)
// 赋值的前后两个值都会被入队
// 把 value 存到指定 buffer 位置
MOVQ AX, -16(R14) // Record value
// 把 *slot 存到指定 buffer 位置
MOVQ (DI), R13
MOVQ R13, -8(R14)
// 如果 wbBuffer 队列满了,那么就下刷处理,比如置灰,置黑等操作
JEQ flush
ret:
// 赋值:*slot = val
MOVQ 104(SP), R14
MOVQ 112(SP), R13
MOVQ AX, (DI)
RET
flush:
。。。
// 队列满了,统一处理,这个其实是一个批量优化手段
CALL runtime·wbBufFlush(SB)
。。。
JMP ret*思考下:不是说把 `slot = value` 直接置灰色,置黑色,就完了嘛,这里搞得这么复杂?**
最开始还真不是这样的,这个也是一个优化的过程,这里是利用批量的一个思想做的一个优化。我们再理解下最本质的东西,触发了写屏障之后,我们的核心目的是为了能够把赋值的前后两个值记录下来,以便 GC 垃圾回收器能得到通知,从而避免错误的回收。记录下来是最本质的,但是并不是要立马处理,所以这里做的优化就是,攒满一个 buffer ,然后批量处理,这样效率会非常高的。
wbBuf 结构如下:
|-------------------------------------|
| 8 | 8 | 8 * 512 | 4 |
|-------------------------------------|
每个 P 都有这么个 wbBuf 队列。
我们看到 CALL runtime·wbBufFlush(SB) ,这个函数 wbBufFlush 是 golang 实现的,本质上是调用 wbBufFlush1 。这个函数才是 hook 写操作想要做的事情,精简了下代码如下:
func wbBufFlush1(_p_ *p) {
start := uintptr(unsafe.Pointer(&_p_.wbBuf.buf[0]))
n := (_p_.wbBuf.next - start) / unsafe.Sizeof(_p_.wbBuf.buf[0])
ptrs := _p_.wbBuf.buf[:n]
_p_.wbBuf.next = 0
gcw := &_p_.gcw
pos := 0
// 循环批量处理队列里的值,这个就是之前在 gcWriteBarrier 赋值的
for _, ptr := range ptrs {
if ptr < minLegalPointer {
continue
}
obj, span, objIndex := findObject(ptr, 0, 0)
if obj == 0 {
continue
}
mbits := span.markBitsForIndex(objIndex)
if mbits.isMarked() {
continue
}
mbits.setMarked()
if span.spanclass.noscan() {
gcw.bytesMarked += uint64(span.elemsize)
continue
}
ptrs[pos] = obj
pos++
}
// 置灰色(投入灰色的队列),这就是我们的目的,对象在这里面我们就不怕了,我们要扫描的就是这个队列;
gcw.putBatch(ptrs[:pos])
_p_.wbBuf.reset()
}所以我们总结下,写屏障到底做了什么:
- hook 写操作
- hook 住了写操作之后,把赋值语句的前后两个值都记录下来,投入 buffer 队列
- buffer 攒满之后,批量刷到扫描队列(置灰)(这是 GO 1.10 左右引入的优化)
main.funcAlloc1
17 func funcAlloc1 (b *Tstruct) {
18 var b0 Tstruct
19 b0.base = new(BaseStruct) // new 一个BaseStruct结构体,赋值给 b0.base 字段
20 }.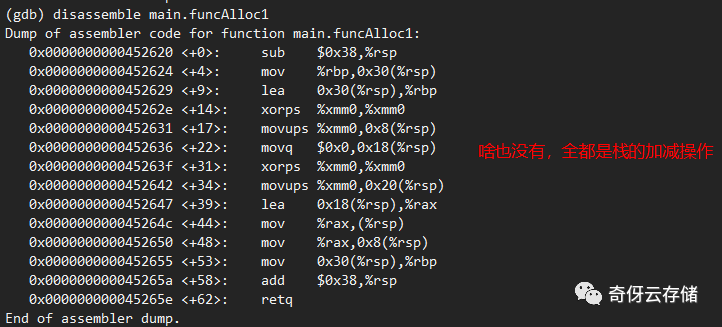
最后,再回顾看下 main.funcAlloc1 函数,这个函数是只有栈操作,非常简单。
下一篇,继续讲述插入写屏障究竟是什么东西?