他们渲染了一百万个网页,来了解网络如何崩溃
- 本文已获得原作者的独家授权,有想转载的朋友们可以在后台联系我申请开白哦!
- PS:欢迎掘友们向我投稿哦,被采用的文章还可以送你掘金精美周边!
最近在 medium 上看到这篇“比较新鲜的”文章 《We rendered a million web pages to learn how the web breaks》 觉着不错(老外确实敢想敢做),遂翻译分享,以期拓宽视野、引人思考。本瓜不会去逐字翻译,旦求一个表意流畅。其间也会或加入自己的看法,或引用其它。总之,事儿就是这么个事儿,希望您喜欢~
为什么要渲染一百万个页面?
简单来说,就是现如今出现一种争议(argument):网络从某种程度上来说比 15 年前更慢了。原因是日益繁荣的 JS 框架、网络字体、以及各类 polyfills 的增长,它们并没有使得我们从更高速的计算器、更快速的网络通信、更完备的网络协议中获益更多,甚至带来了损害。
So the argument goes. 于是乎,作者团队想证明这种说法是否是成立的,并尝试找出导致 2020 年网站缓慢和崩溃的常见因素。
如何实现这一计划?
作者团队使用 Puppeteer 编写了一个 Web 浏览器(Chrome)脚本,启动 200 个 EC2 实例,让它在周末运行,渲染排名前一百万域名的根页面。

在这个计划中,他们跟踪所有的 window.onerror 所捕获的错。
通常来说,我们都会跟踪客户反馈的错误,但是这一次,跟踪的却是整个网络的错误!这次将有足够的说服力:研究网页到底是如何在实际运行中崩溃的?
最常见的错误
分析数据表明,大多数问题都可以被归类。而这,就能为开发人员指引 Web 技术的未来发展方向:修复这一些小问题就可以将 Web 的报错数量减少十倍。
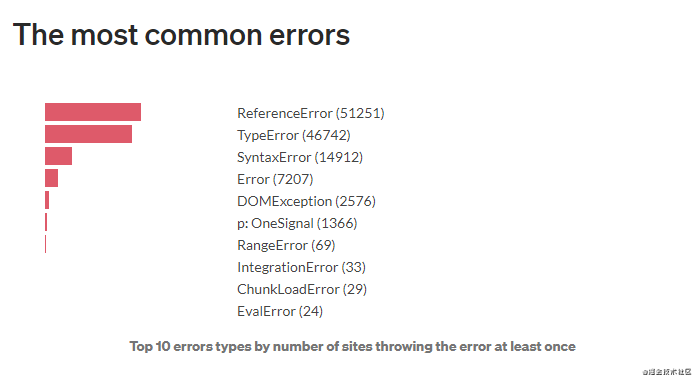
- 引用错误
- 类型错误
- 语法错误
- Error
- 调用异常
- OneSignal
- 超出范围
- Integration Error
- chunk 下载错误
- eval 计算错误
如 Tolstoy 所说:工作中的网址皆不相同,但是破坏它们的方式却是一致的。如您所见,这些网络错误的分布符合【齐夫定律】。此例中,有三种错误占了所有错误的极大比例。即:
引用错误(ReferenceError)、类型错误(TypeError)、语法错误(SyntaxError) 占所有错误的 85%!
显然,造成这些错误的方式有很多种,错误消息中的特定字符串会告诉我们具体发生了什么。作为开发者,我们一定常常遇到这其中的一些,并总是对它们感到熟悉。(这个错误我见过~)
当然,有很多方法可以产生这些错误类型。错误消息中的特定字符串告诉我们更多有关实际发生的情况的信息。查看最常见的错误消息会给您一定的熟悉感。作为网络开发人员,您之前可能已经遇到过其中一些。
让我们来看下具体的错误 TOP10 又是哪些?

- 找不到 $ 符(JQ 经典常见)
- 找不到 qq_qun(?)
- jQuery 未定义(常见)
- 意外的符号 '<'(常见)
- 无效或意外符号
- 无法读取 undefined 的 envelope 属性(常见)
- $ 符不是一个函数(常见)
- 无法读取 null 的 addRventListener 属性
- 意外的标识符
- 无法读取 null 的 appendChild 属性
这些报错都指向特定的错误消息,作者团队继续调试这些错误的样本,来深入了解它们的具体错误情况。结果,意想不到的事情发生了:事实证明,对于引用错误(ReferenceError)和语法错误(SyntaxError)而言,有一个共通的根本原因 —— 即 资源加载失败,对于类型错误(TypeErrors),也有一个本质上的发现,即它们都属于同一种问题。
作者团队深入研究产生了以下文章,描述了对每个错误的发现:
How to resolve ReferenceError:我们可以获取公共库的高频全局变量的使用趋势,在此基础上,构建相关联的变量名和特定的库来解决引用错误。即采用自定义高频变量覆盖公告库来解决此类大部分问题。
What causes TypeError on live web sites:97% 的类型错误都来自于 null 或者 undefined。它们大多数是因为没有符合第三方库或者浏览器环境的依赖,或者是因为文档对象发生错误导致选择器拿不到值。
What causes SyntaxError on live web sites:开发过程中,多数的语法错误来自于拼写错误。实际运行中,多数的语法错误来自网络故障或者 JS 的编写错误。
如何预测错误数量?
作者团队最初用逻辑回归和分类的方法(logistic regression classifier),尝试根据 JS 所调用的库来预测网站中错误的存在。基于此假设,意味着只要存在某些代码,就预示着会导致错误。
继续深入分析显示:大多数错误由于缺少代码所致,所以这种方式的预测能力较低。但是,我们可以列一个分类器学习的回归系数。这就很高级了~ 它可以显示了这些分类选择依赖的程度。事实上,一小段代码在 webpack 的作用下将与一些错误强有力的连接起来,但它们对浏览器来说又是关键的依赖脚本。
这里还有一个结论:用于追踪 JS 错误的产品有更低的错误数。
让咱们来康康这些库的回归系数,预测是否存在错误。
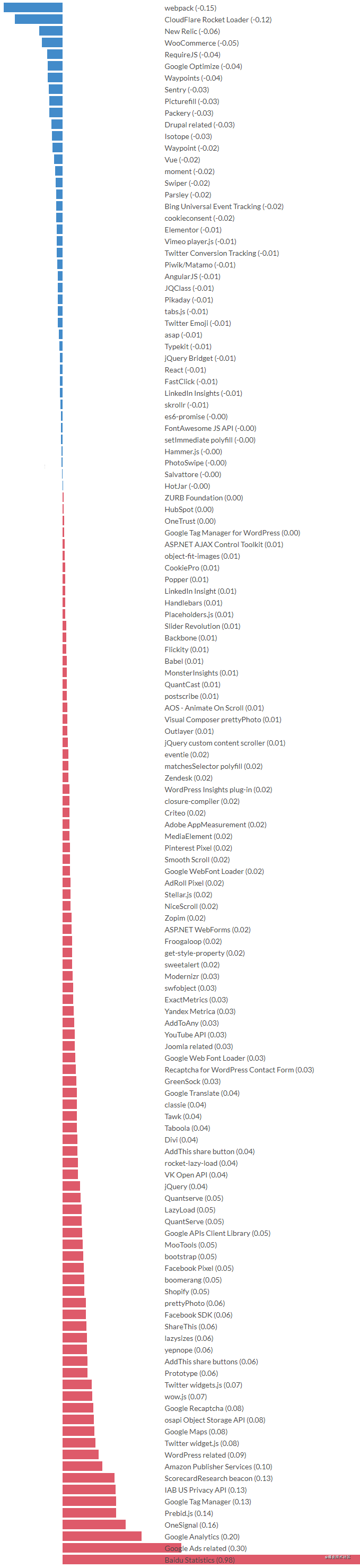
例如,百度统计的回归系数大,代表缺失代码的可能性较小,预测有更低的错误数。不过,本瓜怀疑和墙也有关系,因为一直在用谷歌统计,自觉更不错啊~
网络的错误恢复能力
在调研的一百万个网页中,有 12% 的网站存在一个或多个未处理的错误。这确实是一个惊人的数字。这些错误表明由于某些意外的情况中止了某些程序的执行,从而导致某些功能因此被破坏掉。
从 12% 也能看到 Web 的错误恢复能力是强大的:但无论你的错误是什么,它都必须足够小以至于懒得去修复它。
数据显示:大多数错误来自于运行时缺少代码、数据、或文档对象。很有可能是由于 Web 的绑定特性决定的:类型在运行时(后期)才被确定,而不是在编译时(早期)就被确定。 的确,在运行时才确定类型可以使得加载各类库更轻松自然,但它也造成了一些错误发生的可能:即可能出现缺少库或者 API 发生了改变的情况。当然,运行时才确定类型不是唯一的选择,许多语言都是在编译时就已确定了类型。
比如 Java Applets 构建的 Web,情况将有所不同。(咱能从这个老古董里学点什么~)
如何构建不易出错的网络
在强类型系统的语言中严格要求定义类型,动态运行任何加载库将变得艰难,尤其是当这些库的自定义程度很高,API 很开放的情况。这不仅与来源于网络的代码有关,也和浏览器的运行时有关。
我们可以稍微回顾下 Java Applets,如果你没有正确安装 Java 运行环境,那么 applet 将拒绝运行直到你下载并安装了相应的环境。在 Web 当中,你可以使用旧浏览器查看页面,但有浏览器和网站可能在长久的迭代中逐步崩溃(即运行环境也在变化)。不过,你也可以编写一个在当前版本浏览器和旧版本浏览器都能正常运行的网页。根据这种思路,运行时绑定类型对于网络的发展也是至关重要的!
2006 年,艾伦·凯(Alan Kay)和观点研究所(Viewpoint Research Institute)发起了一项雄心勃勃的项目:以两万行代码从裸机重构计算机至实现 GUI 操作系统。虽然这个项目由于资金问题中途停滞,但是最终的报告还是描述了一种运行时绑定的动态的语言的构建( late-bound references and dynamicity )—— KScript。这比 TypeScript 还要早 6 年!

截至此处,我们还没有得到最终的结论。静态类型保证编译器不出现某些类型错误,这是开发者喜闻乐见的。TypeScript 就很有趣了,它跨越了动态类型和静态类型,它需要付出这样的代价:编译器认为编译时期的类型可能不是运行时期的类型。
Web 的运行时绑定机制让我们总处于落后,如果浏览器不支持网页的新特性,代码就会中断。对于 Web 而言,这似乎比 Java Applet 模型“要么没有,要么全有”的特点要好,在 Java Applet 中,只有在正确的运行环境装好的情况下才能运行程序。在 2000 年代初,XHTML 有类似的情况。使用 XHTML,文档需被要求是有效的 XML,无效的标记将导致页面完全不显示。当时,这种行为被许多人提倡,也许是因为无效的 HTML 被看作是导致浏览器有不同呈现的“主谋”。经过了十年的沉淀,有了更好的想法来标准化这些无效标记,并将它们合到了 HTML5 中。从目前的结果看,HTML5 胜过了 XHTML,JavaScript 胜过了 Java applet。
现在还有一匹黑马,那就是 —— WebAssembly。有很多案例都是围绕用静态类型的语言将代码编译为 wasm (比如 Blazor)。我们正处在历史潮头,在这个时代,前端开发将不再有大量的 JS 代码。然而,这种思路下,技术若成为一个个孤岛也注定不会成功。从历史中学习,我们似乎有必要围绕动态找到一个更好的解决方案,并考虑运行时的绑定!
静态类型语言能为我们提供安全性,动态类型语言又是 Web 不易出错的关键。二者的平衡是最终的关键!数据表明,当网络中断时,原因是代码没有按预期运行,导致文档错误、类型错误、三方库或数据无法加载等。我们假设类型系统是解决编程问题的有办法,它确保在编译阶段各种依赖就被做了检查。是否存在一种人体工学(ergonomic)的方法来实现这一目标?它能允许在动态环境中执行这种检查,同时也就能消除困扰当今网络的大多数错误。
作结
- 首先为这个团队的做法点赞,敢想敢做!实际上,研究崩溃只是整个研究的子课题,父课题为 JavaScript Performance in the Wild 2020,其中还包括网络连接情况、第三方库使用情况、页面渲染时间、请求数、重绘次数等等,有兴趣点赞,本瓜后续接着翻。
- 我们可以预见的是 TypeScript 是目前解决 JS 类型问题的最好解决方案!也期待有更多解决方案,解决比如引用问题、语法问题,虽然这些 ESLint 也能做,但它只是插件工具。想有更多的遐想,或许编程语言自身就得足够强大。
- Webpack 太重要了!在如今前端工程化的大环境下,开发俨然变成是对各种依赖库的调用,而最终如何能打包成为一个“称心”的项目在线上运行,才是关键中之关键。
- 就目前看,再远一点的未来是 WebAssembly(给我往 si 里学~)。
- 浏览器是 Web 前端攻城狮一切的基础。说一个数据:谷歌浏览器 2008 年发布,截至 2020 年,已有 69.89% 的市场占有率。但是,谁还记得在 1990 年代中期,网景浏览器 的市场占有率曾高达 90%?或许一切还未成定局!如作者所说,我们处在历史的潮头。浏览器会去往何方?咱们边走边看~
- 以降低耦合、增高内聚的设计思想来 Coding,这不止于前端,这是计算器科学!
- 都看到这里啦?点个赞吧?我是掘金安东尼,人不狠话也多......
