同步框架异步化改造—任务协程化 (一)
导语
我们系统内部有一个异步执行任务的一个组件B。B从数据库里取任务执行。之前B是单线程串行执行,并发度纯粹由进程数决定。这里的实现是通过极小的代码改动,变更为全异步架构。原理就是:通过协程调度,充分利用cpu。通过patch,把底层阻塞socket io偷梁换柱为非阻塞socket,从而为协程切换提供基础。
背景
B是异步执行任务的一个组件。从数据库里取任务执行。之前B是单线程串行执行,并发度纯粹由进程数决定。由于现网task任务并发很大。当数据库里的task任务数比进程数要多的时候,就会出现等待。现网数据看到等待时延可高达上百秒。所以当前B最大的问题是吞吐不行,并发度为1。每台机器的B进程数有限,带来的内存开销和数据库的长连接开销都很大。
从架构分析来讲,B属于IO密集型的程序。大量的数据库IO访问和WEB HTTP IO请求访问。CPU的利用率极低,都用在等IO上了。吞吐是瓶颈,那么这两种类型的IO访问就是吞吐上不来的原因。
所以本次,这对这个吞吐进行了优化改动:
- 每个任务协程化,以一个主协程调度执行协程任务,并且控制并发深度
- 通过python patch,把数据库的IO,HTTP IO请求,都patch成为全异步的socket请求
进行以上改动,B转变成全异步架构。B并发能力有质的变化。每台机器节约1G的内存。
为什么用协程?而不用其他的异步方案?
这是因为现有的B是一个已经存在的复杂组件。内部全方位360%无死角的使用了同步io。其他方案都不如协程非侵入式的改动方案好,不需要改动业务代码。只需要改动最开始的入口,patch最底层的阻塞io调用就行了。
协程调度的简单原理实现
首先说下改动的简单思路实现,这个是实现本质,然后说下我们用的gevent库。因为之前用过linux的协程切换接口。协程调度,linux提供的协程接口非常简单。就4个。
#include <ucontext.h>
void makecontext(ucontext_t *ucp, void (*func)(), int argc, ...);
int swapcontext(ucontext_t *oucp, const ucontext_t *ucp);
int getcontext(ucontext_t *ucp);
int setcontext(const ucontext_t *ucp);- makecontext 就是创建一个新的上下文。
- swapcontex 就是切换上下文。会保存当前的上下文,并切换到另一个上下文。本质上来讲,就是切换一整套的寄存器值。保存当前上下文到oucp,切换到ucp上下文中
- getcontext 用户保存上下文(保存当前上下文到ucp结构)
- setcontext 用户切换上下文(把ucp接口里保存的context恢复到当前上下文)。这个ucp是通过getcontext,或者makecontext获取的。
利用以上的四个接口,就有了实现我们的协程调度了。通俗来讲,就是手动调度切换cpu。以提高cpu的利用率。怎么个调度法?这个其实是很关键的核心。总体来分为两大类:
- 对称的切换调度方式
- 非对称的切换调度方式
对称的调度方式是指:每个协程任务都是一样的,不存在主次,都可以相互切换。这类调度类型看着美观,但是实现起来会非常复杂,如果加上一些协程锁,异步io切换逻辑之后,而且极容易出错。不容易实现时序的串行化。
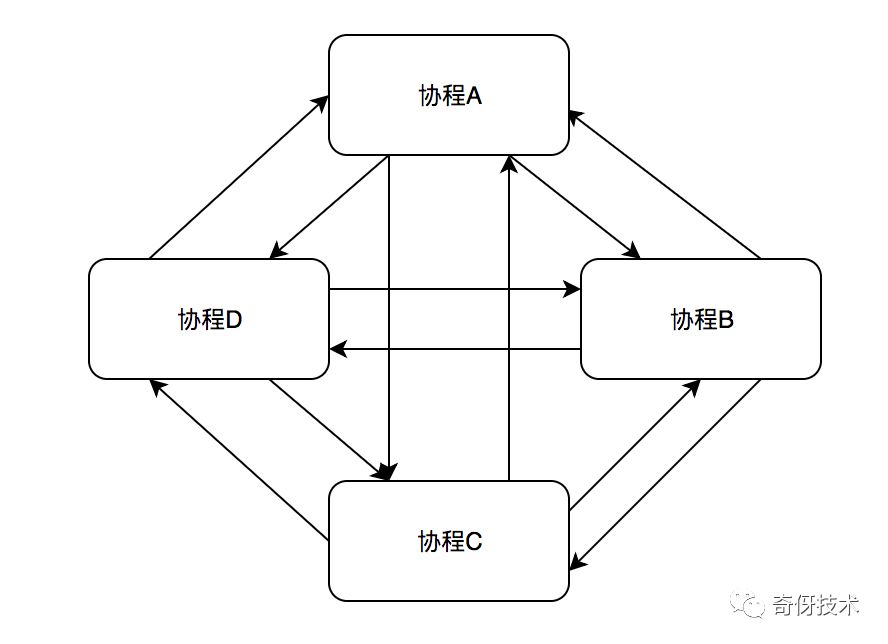
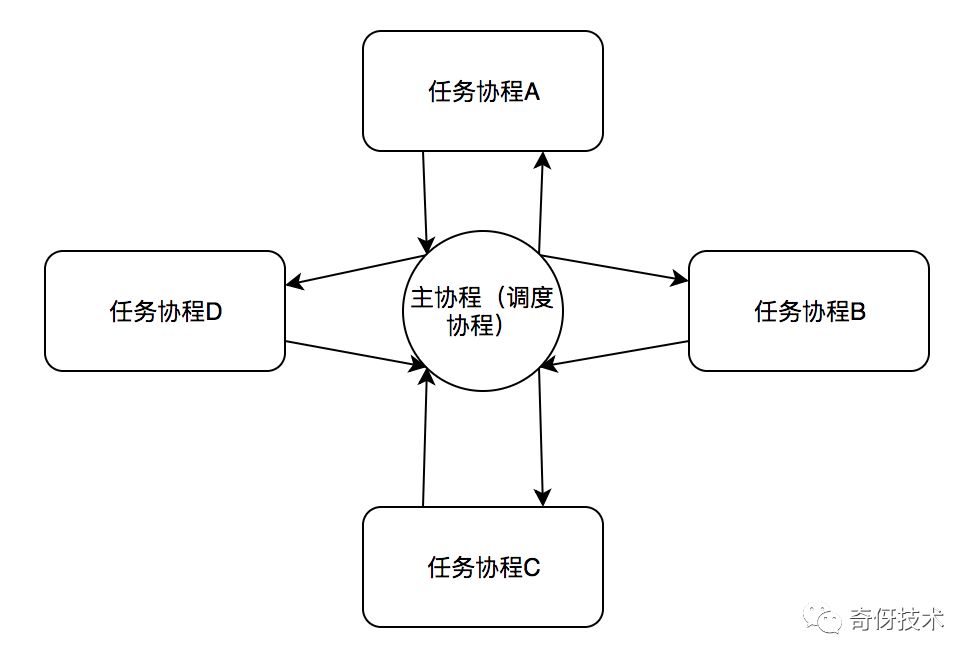
非对称的调度方式:最典型的就是有一个中心调度任务。主要角色分为:
- 主协程:负责所有的协程调度
- 任务协程:执行具体的业务逻辑代码的协程任务
基本原则是:
- 严格保证所有的协程切换都必须且只能在 "主协程"<-> "任务协程” 之间进行
- 存在串行逻辑的时候,必须保证严格的串行时序(这个会在协程锁的实现里讲)
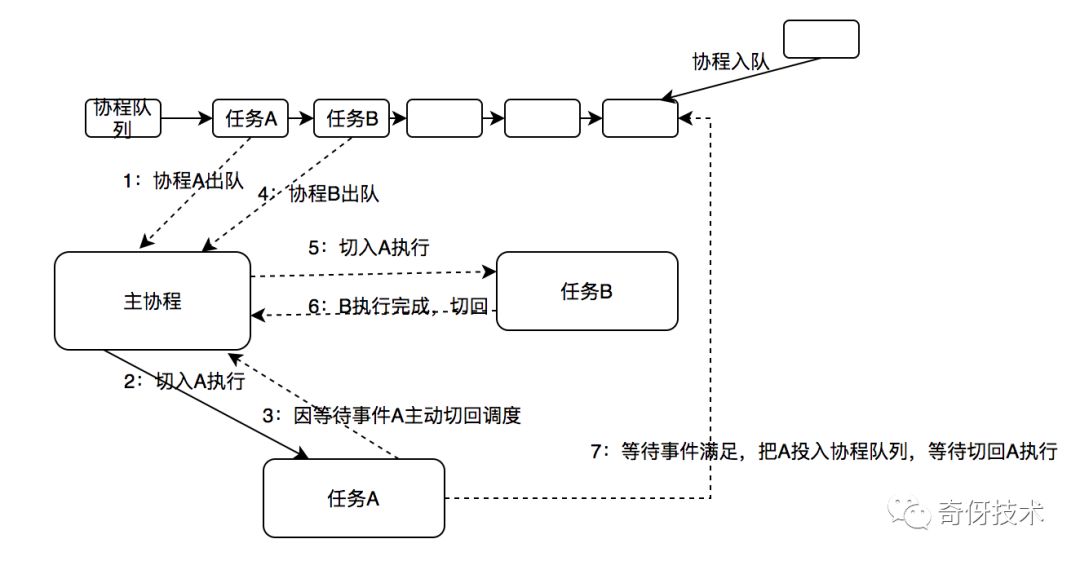
简单原理讲述:
下图是一个比较完整的切换示意图:
- 主协程(调度协程)总是从协程队列中取出协程任务执行
- 协程任务执行过程中,遇到等待事件,需要保存好上下文,设置好唤醒路径之后,切回调度
- 切回调度之后,CPU就让出来了,就可以执行其他的任务,从而实现了并发
- 等待事件到来之后,按照之前设置好的环境路径,把协程任务再次投入到协程队列尾端,等待执行
- 等重新取到协程的时候,主协程切入,从之前切出的地方开始执行
先简单说下我们用 linux 提供的ucontext等接口实现的调度简单模型。其实我们只用到了3个接口:
void makecontext(ucontext_t *ucp, void (*func)(), int argc, ...);
int swapcontext(ucontext_t *oucp, const ucontext_t *ucp);
int getcontext(ucontext_t *ucp);伪代码示例: 初始化好主协程,并且用到了一个全局协程队列,主协程只负责从这列表中摘取任务执行。-
INIT_LIST_HEAD(&sche_list)
协程创建,任务入队
cotask_create()
{
// 分配cotask内存
cotask = calloc();
// 分配协程堆栈
stack = calloc();
// 设置栈的内存地址和协程栈大小,一般来讲,64k就完全够用了。
// 以前确实出现过,协程任务里面有递归函数调用。导致爆栈了
cotask->ctx.uc_stack.ss_sp = stack;
cotask->ctx.uc_stack.ss_size = stacksize;
// 协程结构初始化,设置好协程切入之后执行的入口
makecontext(&cotask->ctx, cotask_wrap, …);
//把协程任务加入到协程队列中
list_add_tail(&cotask->list, &sche_list);
}取协程任务,切入执行
// 遍历执行协程任务队列的任务
foreach_exec_task () {
list_for_each_safe(pos, next, &sche_list) {
list_del_init(pos)
// 从调度里切入任务协程执行
swapcontext(&sched->ctx, &cotask->ctx);
}
}以上伪代码省略了很多。状态修改,协程周期,校验逻辑。比如:
- 加入爆栈的校验
- 协程的生命周期的校验
- 可能还需要做一些调试工具,比如查看某个协程的协程函数调用栈
- 死锁检查;
比如,某个协程加了mutex阻塞锁,走到后面代码,就直接切到调度,那么后面一旦有协程任务来加同一把mutex锁,就会导致死锁问题
上面讲了一遍协程的基本原理,下一篇正式讲我们的内部实践。