看完这篇,再也不怕堆排序、Top K、中位数问题面试了
引言
堆是前端进阶必不可少的知识,也是面试的重难点,例如内存堆与垃圾回收、Top K 问题等,这篇文章将从基础开始梳理整个堆体系,按以下步骤来讲:
- 什么是堆
- 怎样建堆
- 堆排序
- 内存堆与垃圾回收
- Top K 问题
- 中位数问题
- 最后来一道leetcode题目,加深理解
下面开始吧
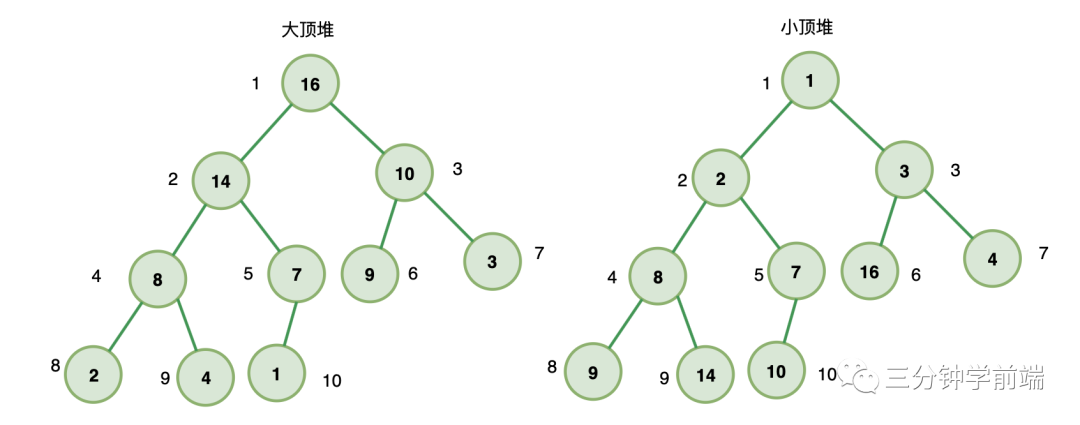
9.1 堆
满足下面两个条件的就是堆:
- 堆是一个完全二叉树
- 堆上的任意节点值都必须大于等于(大顶堆)或小于等于(小顶堆)其左右子节点值
如果堆上的任意节点都大于等于子节点值,则称为 大顶堆
如果堆上的任意节点都小于等于子节点值,则称为 小顶堆
也就是说,在大顶堆中,根节点是堆中最大的元素;
在小顶堆中,根节点是堆中最小的元素;
9.2 怎样创建一个大(小)顶堆
我们在上一节说过,完全二叉树适用于数组存储法( 前端进阶算法7:小白都可以看懂的树与二叉树 ),而堆又是一个完全二叉树,所以它可以直接使用数组存储法存储:简单来说: 堆其实可以用一个数组表示,给定一个节点的下标 i (i从1开始) ,那么它的父节点一定为 A[i/2] ,左子节点为 A[2i] ,右子节点为 A[2i+1]
function Heap() {
let items = [,]
}那么怎样去创建一个大顶堆(小顶堆)喃?
常用的方式有两种:
- 插入式创建:每次插入一个节点,实现一个大顶堆(或小顶堆)
- 原地创建:又称堆化,给定一组节点,实现一个大顶堆(或小顶堆)
9.3 插入式建堆
插入节点:
- 将节点插入到队尾
- 自下往上堆化: 将插入节点与其父节点比较,如果插入节点大于父节点(大顶堆)或插入节点小于父节点(小顶堆),则插入节点与父节点调整位置
- 一直重复上一步,直到不需要交换或交换到根节点,此时插入完成。

function insert(key) {
items.push(key)
// 获取存储位置
let i = items.length-1
while (i/2 > 0 && items[i] > items[i/2]) {
swap(items, i, i/2); // 交换
i = i/2;
}
}
function swap(items, i, j) {
let temp = items[i]
items[i] = items[j]
items[j] = temp
}时间复杂度: O(logn),为树的高度
9.4 原地建堆(堆化)
假设一组序列:
let arr = [,1, 9, 2, 8, 3, 7, 4, 6, 5]
原地建堆的方法有两种:一种是承袭上面插入的思想,即从前往后、自下而上式堆化建堆;与之对应的另一种是,从后往前、自上往下式堆化建堆。其中
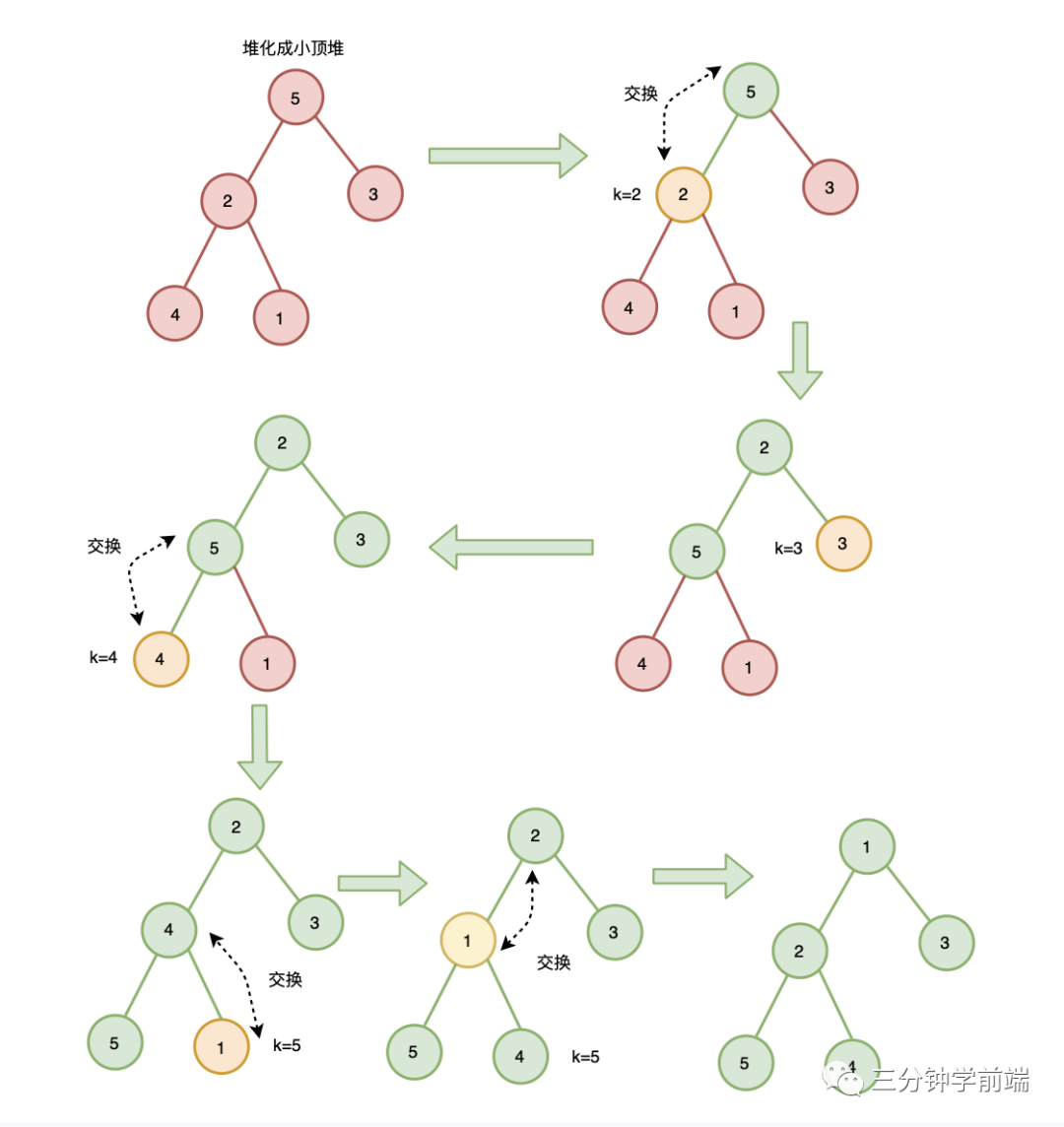
- 自下而上式堆化 :将节点与其父节点比较,如果节点大于父节点(大顶堆)或节点小于父节点(小顶堆),则节点与父节点调整位置
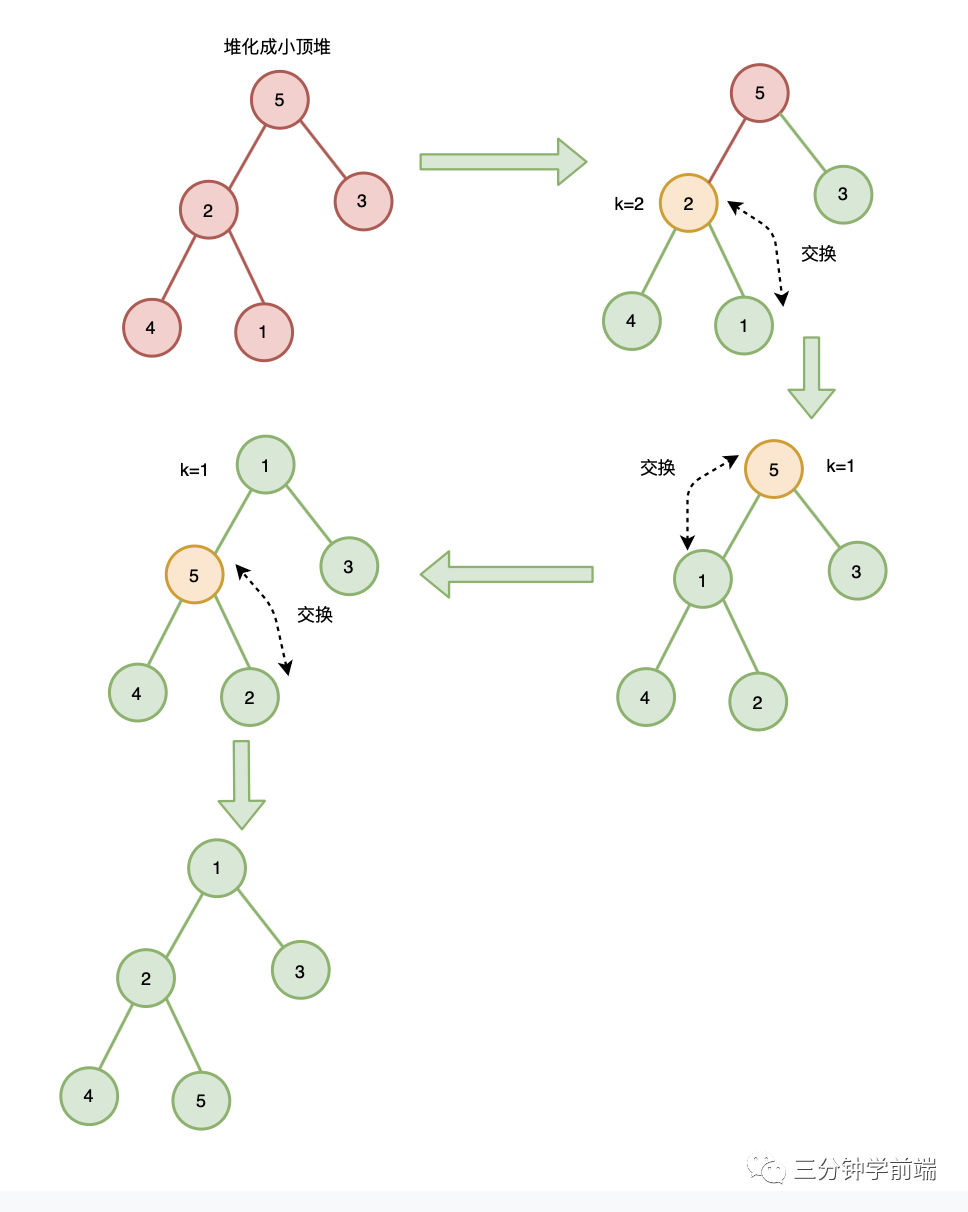
- 自上往下式堆化 :将节点与其左右子节点比较,如果存在左右子节点大于该节点(大顶堆)或小于该节点(小顶堆),则将子节点的最大值(大顶堆)或最小值(小顶堆)与之交换
所以,自下而上式堆是调整节点与父节点(往上走),自上往下式堆化是调整节点与其左右子节点(往下走)。
10.4.1 从前往后、自下而上式堆化建堆
这里以小顶堆为例,
// 原地建堆
function buildHeap(items, heapSize) {
while(heapSize < items.length - 1) {
heapSize ++
heapify(items, heapSize)
}
}
function heapify(items, i) {
// 自下而上式堆化
while (Math.floor(i/2) > 0 && items[i] < items[Math.floor(i/2)]) {
swap(items, i, Math.floor(i/2)); // 交换
i = Math.floor(i/2);
}
}
function swap(items, i, j) {
let temp = items[i]
items[i] = items[j]
items[j] = temp
}
// 测试
var items = [,5, 2, 3, 4, 1]
// 初始有效序列长度为 1
buildHeap(items, 1)
console.log(items)
// [empty, 1, 2, 3, 5, 4]测试成功
10.4.2 从后往前、自上而下式堆化建堆
这里以小顶堆为例
注意:从后往前并不是从序列的最后一个元素开始,而是从最后一个非叶子节点开始,这是因为,叶子节点没有子节点,不需要自上而下式堆化。
最后一个子节点的父节点为 n/2 ,所以从 n/2 位置节点开始堆化:
// 原地建堆
// items: 原始序列
// heapSize: 初始有效序列长度
function buildHeap(items, heapSize) {
// 从最后一个非叶子节点开始,自上而下式堆化
for (let i = Math.floor(heapSize/2); i >= 1; --i) {
heapify(items, heapSize, i);
}
}
function heapify(items, heapSize, i) {
// 自上而下式堆化
while (true) {
var minIndex = i;
if(2*i <= heapSize && items[i] > items[i*2] ) {
minIndex = i*2;
}
if(2*i+1 <= heapSize && items[minIndex] > items[i*2+1] ) {
minIndex = i*2+1;
}
if (minIndex === i) break;
swap(items, i, minIndex); // 交换
i = minIndex;
}
}
function swap(items, i, j) {
let temp = items[i]
items[i] = items[j]
items[j] = temp
}
// 测试
var items = [,5, 2, 3, 4, 1]
// 因为 items[0] 不存储数据
// 所以:heapSize = items.length - 1
buildHeap(items, items.length - 1)
console.log(items)
// [empty, 1, 2, 3, 4, 5]测试成功
9.5 排序算法:堆排序
原理
堆是一棵完全二叉树,它可以使用数组存储,并且大顶堆的最大值存储在根节点(i=1),所以我们可以每次取大顶堆的根结点与堆的最后一个节点交换,此时最大值放入了有效序列的最后一位,并且有效序列减1,有效堆依然保持完全二叉树的结构,然后堆化,成为新的大顶堆,重复此操作,知道有效堆的长度为 0,排序完成。
完整步骤为:
- 将原序列(n个)转化成一个大顶堆
- 设置堆的有效序列长度为 n
- 将堆顶元素(第一个有效序列)与最后一个子元素(最后一个有效序列)交换,并有效序列长度减1
- 堆化有效序列,使有效序列重新称为一个大顶堆
- 重复以上2步,直到有效序列的长度为 1,排序完成
动图演示

代码实现
function heapSort(items) {
// 构建大顶堆
buildHeap(items, items.length-1)
// 设置堆的初始有效序列长度为 items.length - 1
let heapSize = items.length - 1
for (var i = items.length - 1; i > 1; i--) {
// 交换堆顶元素与最后一个有效子元素
swap(items, 1, i);
// 有效序列长度减 1
heapSize --;
// 堆化有效序列(有效序列长度为 currentHeapSize,抛除了最后一个元素)
heapify(items, heapSize, 1);
}
return items;
}
// 原地建堆
// items: 原始序列
// heapSize: 有效序列长度
function buildHeap(items, heapSize) {
// 从最后一个非叶子节点开始,自上而下式堆化
for (let i = Math.floor(heapSize/2); i >= 1; --i) {
heapify(items, heapSize, i);
}
}
function heapify(items, heapSize, i) {
// 自上而下式堆化
while (true) {
var maxIndex = i;
if(2*i <= heapSize && items[i] < items[i*2] ) {
maxIndex = i*2;
}
if(2*i+1 <= heapSize && items[maxIndex] < items[i*2+1] ) {
maxIndex = i*2+1;
}
if (maxIndex === i) break;
swap(items, i, maxIndex); // 交换
i = maxIndex;
}
}
function swap(items, i, j) {
let temp = items[i]
items[i] = items[j]
items[j] = temp
}
// 测试
var items = [,1, 9, 2, 8, 3, 7, 4, 6, 5]
heapSort(items)
// [empty, 1, 2, 3, 4, 5, 6, 7, 8, 9]测试成功
**时间复杂度:**建堆过程的时间复杂度是 O(n) ,排序过程的时间复杂度是 O(nlogn) ,整体时间复杂度是 O(nlogn)
空间复杂度:O(1)
9.6 内存堆与垃圾回收
前端面试高频考察点,已经在 栈 章节中介绍过,点击前往 [全方位解读前端用到的栈结构(调用栈、堆、垃圾回收等)]
9.7 堆的经典应用:Top K 问题(常见于腾讯、字节等面试中)
什么是 Top K 问题?简单来说就是在一组数据里面找到频率出现最高的前 K 个数,或前 K 大(当然也可以是前 K 小)的数。
这种问题我们该怎么处理喃?我们以从数组中取前 K 大的数据为例,可以按以下步骤来:
- 从数组中取前
K个数,构造一个小顶堆 - 从
K+1位开始遍历数组,每一个数据都和小顶堆的堆顶元素进行比较,如果小于堆顶元素,则不做任何处理,继续遍历下一元素;如果大于堆顶元素,则将这个元素替换掉堆顶元素,然后再堆化成一个小顶堆。 - 遍历完成后,堆中的数据就是前 K 大的数据
遍历数组需要 O(N) 的时间复杂度,一次堆化需要 O(logK) 时间复杂度,所以利用堆求 Top K 问题的时间复杂度为 O(NlogK)。
利用堆求 Top K 问题的优势
也许很多人会认为,这种求 Top K 问题可以使用排序呀,没必要使用堆呀
其实是可以使用排序来做的,将数组进行排序(可以是最简单的快排),去前 K 个数就可以了,so easy
但当我们需要在一个动态数组中求 Top K 元素怎么办喃,动态数组可能会插入或删除元素,难道我们每次求 Top K 问题的时候都需要对数组进行重新排序吗?那每次的时间复杂度都为 O(NlogN)
这里就可以使用堆,我们可以维护一个 K 大小的小顶堆,当有数据被添加到数组中时,就将它与堆顶元素比较,如果比堆顶元素大,则将这个元素替换掉堆顶元素,然后再堆化成一个小顶堆;如果比堆顶元素小,则不做处理。这样,每次求 Top K 问题的时间复杂度仅为 O(logK)
9.8 堆的经典应用:中位数问题
除了 Top K 问题,堆还有一个经典的应用场景就是求中位数问题
中位数,就是处于中间的那个数:
[1, 2, 3, 4, 5] 的中位数是 3
[1, 2, 3, 4, 5, 6] 的中位数是 3, 4
即:
当 n % 2 !== 0 时,中位数为:arr[(n-1)/2]
当 n % 2 === 0 时,中位数为:arr[n/2], arr[n/2 + 1]
如何利用堆来求解中位数问题喃?
这里需要维护两个堆:
- 大顶堆:用来存取前 n/2 个小元素,如果 n 为奇数,则用来存取前
Math.floor(n/2) + 1个元素 - 小顶堆:用来存取后 n/2 个小元素
那么,中位数就为:
- n 为奇数:中位数是大顶堆的堆顶元素
- n 为偶数:中位数是大顶堆的堆顶元素与小顶堆的堆顶元素
当数组为动态数组时,每当数组中插入一个元素时,都需要如何调整堆喃?
如果插入元素比大顶堆的堆顶要大,则将该元素插入到小顶堆中;如果要小,则插入到大顶堆中。
当出入完后后,如果大顶堆、小顶堆中元素的个数不满足我们已上的要求,我们就需要不断的将大顶堆的堆顶元素或小顶堆的堆顶元素移动到另一个堆中,知道满足要求
由于插入元素到堆、移动堆顶元素都需要堆化,所以,插入的时间复杂度为 O(logN) ,每次插入完成后求中位数仅仅需要返回堆顶元素即可,时间复杂度为 O(1)
中位数的变形:TP 99 问题
TP 99 问题:指在一个时间段内(如5分钟),统计某个方法(或接口)每次调用所消耗的时间,并将这些时间按从小到大的顺序进行排序,取第 99% 的那个值作为 TP99 值;
例如某个接口在 5 分钟内被调用了100次,每次耗时从 1ms 到 100ms之间不等数据,将请求耗时从小到大排列,TP99 就是取第 100*0.99 = 99 次请求耗时 ,类似地 TP50、TP90,TP99越小,说明这个接口的性能越好
所以,针对 TP99 问题,我们同样也可以维护两个堆,一个大顶堆,一个小顶堆。大顶堆中保存前 99% 个数据,小顶堆中保存后 1% 个数据。大顶堆堆顶的数据就是我们要找的 99% 响应时间。
本小节参考极客时间的:数据结构与算法之美
9.9 总结
堆是一个完全二叉树,并且堆上的任意节点值都必须大于等于(大顶堆)或小于等于(小顶堆)其左右子节点值,推可以采用数组存储法存储,可以通过插入式建堆或原地建堆,堆的重要应用有:
- 推排序
- Top K 问题:堆化,取前 K 个元素
- 中位数问题:维护两个堆,一大(前50%)一小(后50%),奇数元素取大顶堆的堆顶,偶数取取大、小顶堆的堆顶
JavaScript 的存储机制分为代码空间、栈空间以及堆空间,代码空间用于存放可执行代码,栈空间用于存放基本类型数据和引用类型地址,堆空间用于存放引用类型数据,当调用栈中执行完成一个执行上下文时,需要进行垃圾回收该上下文以及相关数据空间,存放在栈空间上的数据通过 ESP 指针来回收,存放在堆空间的数据通过副垃圾回收器(新生代)与主垃圾回收器(老生代)来回收。