一致性算法 - CARP 算法原来这么简单
“ 缓存数组路由协议是什么,这片文章告诉你”
- 哈希算法的应用
- DHT
- 一致性 hash
- CARP
哈希算法的应用
在分布式系统中,数据的分布,或者请求的路由是一个核心的问题,实现数据的分布我们经常使用到 hash 算法。这个非常容易理解,根据一个 key 计算一个 hash ,然后根据这个 hash 值得出你的索引。
比如,如下就是最简单的一个 hash 算法——除余:
h = num % 4
假设
key从 1,2,3,4,5,6,7,8 开始输入h = hash( key )假设 h 为1的时候,落到 A,为2落到 B,3落到 C,0 落到 D
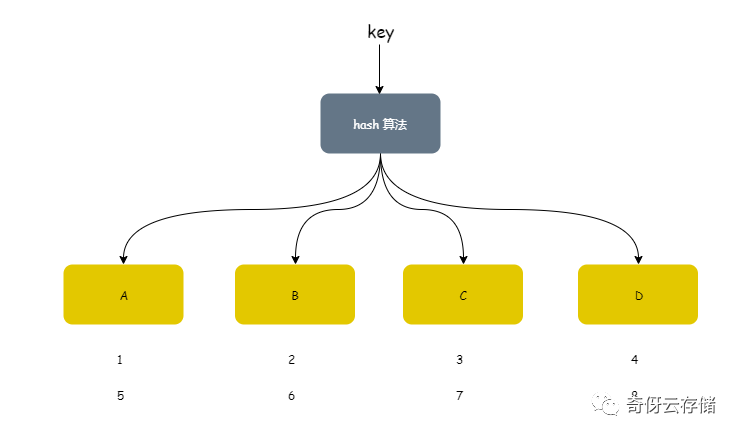
那么散列的效果就如上图。非常容易看出来,这个散列均衡很好,但这个仅仅对于单机系统,无变化的系统。
现在假设增加一个节点 E:
- key 的输入不变(1,2,3,4,5,6,7,8,9)
- hash 算法得变下,
h = num % 5,因为5个节点了嘛,那么现在就是 hash 值为 1 落到A,2落到B,3落到C,4落到D,0落到E
那么重新散列的分布如下图:
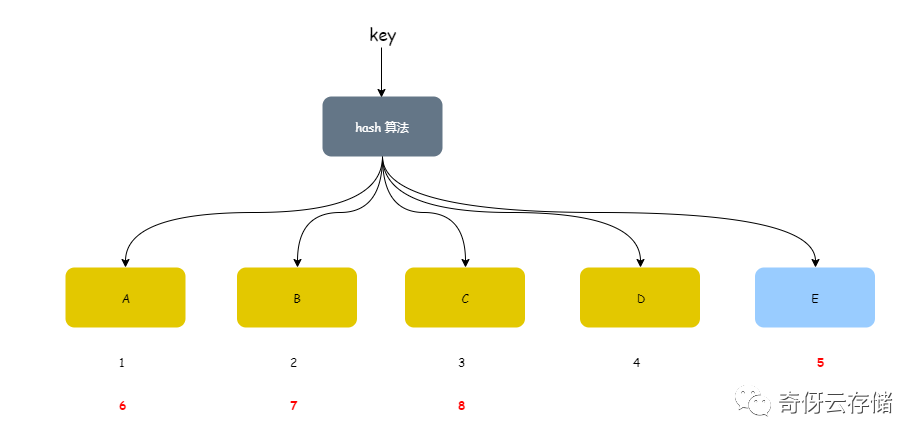
我们看到 hash 分布来了一个乾坤大挪移,失效的点非常多,假设如果我们这里实现的是一个缓存系统,那么就有一半的缓存都失效了。
分布式系统中,由于分布式的特点和网络的不可靠因素,增删节点是再正常不过的需求,所以我们再分布式系统中,一般使用分布式 hash 算法,简称 DHT 。DHT 不是特指一种算法,而是一类算法,是使用与分布式特性的 hash 算法,常常用来实现 DHT 的是一致性 hash 算法,本文要提的 CARP 算法就是其中一种。
DHT
大家可能认为 DHT 算法非常复杂,实现非常抽象,其实不然,我们常见的有两种解决方案:
1 . 环状的一致性 hash 算法
2 . 其他,比如 CARP 算法协议
一致性 hash
1 . 使用 hash 环,然后实际节点分配到这个环上,这样我们输入只需要 hash 到环上的节点即可,当有节点增删的时候,只需要前后移动即可;
2 . 第二种同样是 hash 环,只不过改进了点,使用虚拟的 hash 环,实际节点负责管理一定数量环上的节点,这样能做到更为灵活;
其实一致性 hash 有很多种实现形式,CARP 就是一种。
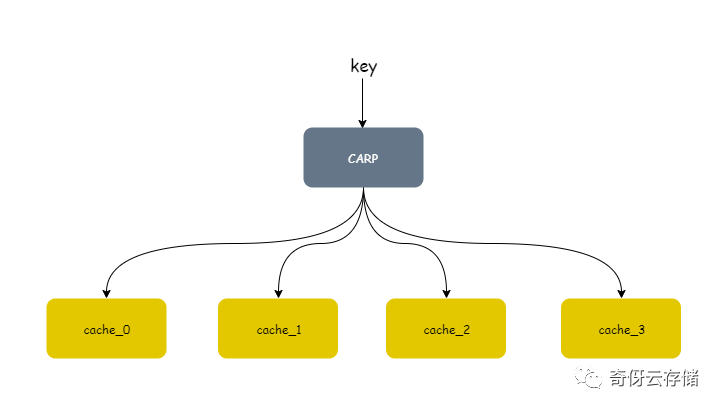
CARP
算法全称:Cache Array Route Protol,是一种缓存数组路由协议,常常用在缓存系统的客户端。本质要达到的目标:分布式系统在增删节点的时候,失效节点概率平均 1/N(N为节点数)。
怎么实现?
步骤一:根据 key 计算出每个节点的 hash 值
hash_v0 = hashof (node0, key)
hash_v1 = hashof (node1, key)
...
hash_vN = hashof (nodeN, key)什么意思?就是以 key,nodeN 这两个参数作为输入,计算出所有节点的值。比如有 4 个节点:
hash_v0 = hashof (node0, key)
hash_v1 = hashof (node1, key)
hash_v2 = hashof (node2, key)
hash_v3 = hashof (node3, key)得到一个列表 [ hash_v0, hash_v1, hash_v2, hash_v3 ],这就是第一步。
步骤二:按照固定规则,从列表中选一个 hash 值
怎么理解?这里有一个重要的点:固定规则。这个固定规则通常有两种规则:
- 选最大的
- 选最小的
hash_vX = min(hash_v0, hash_v1, ... , hash_vN)
或
hash_vX = max(hash_v0, hash_v1, ... , hash_vN)这两种规则都可以,这样就完成啦,CARP 一致性算法就这么多了。
那么 CARP 算法怎么做到增删节点的时候,缓存失效概率 1/N 的呢?
现在添加一个节点,增加一个节点,我们第一步骤得出来的 hash 列表原有值不会变,只有多一个元属:hash_vN+1(思考下,为啥,因为原有节点的输入没有变哈), 对比来看如下:
hash_vX1 = min(hash_v0, hash_v1, ... , hash_vN)
hash_vX2 = min(hash_v0, hash_v1, ... , hash_vN, hash_vN+1)划重点:那么我们要节点失效的话,其实就是要满足 hash_vX1 < hash_vX2 这个条件,而这在大数据的场景下是个概率条件,hash 函数足够散列的话 hash_vX2 < hash_vX1 的概率是 1/N 。
应用
我们常用 CARP 来做什么?最常见的,我们用在缓存系统中,比如你有一个分布式缓存系统,比如是 redis 集群之类的,客户端要根据 key 选择存放到哪个节点?这里就需要有个算法来保证均衡性,稳定性了。CARP 就是一个比较常见的选择。