一个有趣的分布式缓存实现 — groupcache
“ 你见过只有get,没有set的分布式缓存?能用来做啥?”
-
groupcache 架构设计
-
API 接口特点
-
client & server
-
缓存一致性
-
防击穿
-
group 的机制
-
协商填充
-
预热机制
-
热点数据多节点备份
-
使用例子
分布式系统中,各种场景都有缓存组件的应用身影。redis memcached 等作为内存缓存,可以缓存各种适合放到内存的元数据;cdn 也是一种缓存代理实现的产品形态(比如可以使用 nginx 来实现);项目中,我们也经常实现自己的缓存,比如用 SSD 作为更好的磁盘介质来缓存 SATA 盘的数据。缓存经常要面对的一个重要问题,就是缓存更新导致的缓存一致性问题,今天介绍一个特殊的缓存实现——groupcache,只有 get,没有 set 的缓存,那么自然就没有更新导致的缓存一致性问题,因为你就更新不了。
groupcache
groupcache 是一个小巧的 kv 存储库,由 Brad Fitzpatrick ( memcached 的作者)实现,这里一个缓存库,注意是库,而非是一个开箱即用的 server 进程组件。groupcache 是一个非常有趣的缓存实现,最大的特点是没有删除接口,换句话说,kv 键值一旦设置进去了,那么用户端是没有主动的手段删除这个值的,这个值将不能被用户修改, k 的 v 不能修改,那么带来的好处就是没有覆盖更新带来的一致性问题,但正因为如此,所以这个库是有自己的特殊场景的,需要业务自己满足这种场景的使用。
先抛出 3 个自问自答的问题:
思考问题:groupcache 没有更新和删除接口,那么空间岂不是会越来越多?还有实用意义吗?
其实不是的,groupcache 没有 set,update,delete 接口只是让用户无法更新和删除已经缓存的内容而已,而不是说设置进去的 kv 要永久保存,缓存空间肯定不是无限的,groupcache 内部是通过 LRU 来管理内容的。
思考问题:groupcache 没有 set 接口,那内容是怎么设置进去的呢?
- 初始化的时候,就需要明确当 key miss 的时候,怎么获取到内容的手段,把这个手段配置好是前提;
- get 调用的时候,当 key miss 的时候,就会调用初始化的获取手段来获取数据,如果 hit 的话,那么就直接返回了;
思考问题:这种只能 get ,不能更新 key 的缓存有啥用?有什么适用场景?
这个其实是看用户的适用场景的,比如你缓存一些静态文件,用文件 md5 作为 key,value 就是文件。这种场景就很适合用 groupcache 这种缓存,因为 key 对应的 value 不需要变。
那么 groupcache 作为一个有趣的缓存库实现,有啥不一样呢?
如果是单机缓存的实现可以非常简单,通过内存中维护一个 cache map,当收到查询请求时,先查询 cache 是否命中,如果命中则直接返回,否则必须到存储系统执行查询,然后缓存一份,再返回结果。缓存系统一般要考虑缓存穿透,雪崩,击穿等问题:
穿透:指查询不一定存在的数据,此时从数据源查询不到结果,因此也无法对结果进行缓存,这直接导致此类型的查询请求每次都会落到后端,加大后端的压力;
击穿:指对于那些热点数据,在缓存失效的时候,高并发的请求会导致后端请求压力骤升。缓存失效可能是多种因素引起的:
- 比如扫描式的遍历
- 比如缓存时间到期
- 或者请求过大,不断的cache不断的淘汰导致
雪崩:穿透和击穿的场景可能引发进一步的雪崩,比如大量的缓存过期时间被设置为相同或者近似,缓存批量失效,一时间所有的查询都落到后端;
groupcache 架构设计
API 接口特点
groupcache 封装 Group 这个对象对外提供服务,这个服务只有三个极简的接口:
| 接口名 | 作用 |
|---|---|
| Get | 传入一个 key,获取 value |
| Name | Group 的名字,因为可以有多个 Group |
| CacheStats | 统计数据,比如命中率等 |
这三个就是完全的对外使用的 API,没有更改,删除的接口,缓存一旦写入,则永远不会变动(指的是用户)。
client & server
groupcache 实现的库是 client 也是 server ,这个怎么理解?groupcache 实现的是一个分布式的无中心化的缓存集群。每个节点,既作为 server ,对外提供 api 访问,返回 key 的数据,节点之间,也是相互访问的,是以 C/S 模式。
缓存一致性
groupcache 缓存一旦设置之后,没有更新和删除接口,也没有失效时间(完全是内部根据空间淘汰缓存,对外不感知),你根本无法更新,所以自然就没有更新导致的缓存一致性问题,不过注意了,这个要适配用户应用场景(这个要理解)。
没有缓存失效时间,那么就不存在因为时间到期,导致批量缓存失效,从而引发大量击穿相关的问题。
防击穿
在使用缓存的场景,有一个必须要考虑的:当出现缓存失效的时候,会不会导致突发大量的缓存击穿流量?
比如,一个 k-v 存储,客户端先看是否有 k 的缓存,如果有,那么直接给用户返回,如果没有,则向后端存储请求。比如,突然来了1万个这样的请求,发现都是 miss,那么都去后端拉数据了,这种就可能会一下导致后端压力暴涨。其实,这种场景,只要第一个人发下去了就行了,其他的请求等着这个请求返回就好了,大家都是请求同一个值。
内部实现了 singlefilght 就是解决这个问题的,原理很简单,这里就讲一个变形实现:
首先,封装一个请求结构
type call interface {
wg sync.WaitGroup
val interface{}
err error
}这个接口要能做这几个事情:
- 能够存值,第一个请求回来的时候,值赋给
val - 要能够同步,第一个请求下去之后,后面的请求发现有同名
key下去了,那么就地等待,这里通过 wg 来同步这个行为。第一个请求回来之后,通过 wg 来唤醒 - 要能够存 error ,如果有错误,那么要能存起来
其次,要有个 map 结构
type Group struct {
mu sync.Mutex
m map[string]*call
}map 结构是用来存储 k-v 的,key 是用户请求 key ,value 是下去的请求,抽象为了 call 。
最后就是防止击穿的逻辑了:
1 . 如果 map 里面有同名 key 已经下去了,那么就地等待,等唤醒之后,直接返回值
2 . 如果 map 没有同名 key ,那么说明该这个请求亲自下去了
a . 创建一个 call 对象,把自己的 key 放进去,这样别人就能感知到他已经去服务端拿数据了
func (g *Group) Do(key string, fn func() (interface{}, error)) (interface{}, error) {
g.mu.Lock()
if g.m == nil {
g.m = make(map[string]*call)
}
// 如果已经有人去拿数据了,那么等
if c, ok := g.m[key]; ok {
g.mu.Unlock()
c.wg.Wait()
return c.val, c.err
}
// 否则,自己下去
c := new(call)
c.wg.Add(1)
g.m[key] = c
g.mu.Unlock()
c.val, c.err = fn()
c.wg.Done()
g.mu.Lock()
delete(g.m, key)
g.mu.Unlock()
return c.val, c.err
}group 的机制
所谓 group 其实是一个命名空间的设计,不同的命名空间是相互隔离的。
协商填充
固定的 key 由固定的节点服务,这个相当于一个绑定。举个例子,A,B,C 三个节点,如果请求发给了 A,节点 A 哈希计算发现这个请求应该是 B 节点执行,那么会转给 B 执行。这样只需要 B 节点把这个请求处理好即可,这样能防止在缓存 miss 的时候,整个系统节点的惊群效应。
通过这种协商才能保证请求聚合发到 B,同一时间 B 收到大量相同 key 的请求,无论自己有没有,都能很好处理,因为有之前说的防击穿的措施:
- 如果 B 有,立马返回就行;
- 如果没有也只是放一个请求下去,后端压力可以很小的;
预热机制
这个其实是和协商填充一起达到的效果,请求实现了节点绑定,那么在分布式集群的模式下,很容易实现预热的效果,你这个请求大概率是已经被其他节点缓存了的。
热点数据多节点备份
分布式缓存系统中,一般需要从两个层面考虑热点均衡的问题:
1 . 大量的 key 是否均衡的分布到节点;
a . 这个指请求数量的分布均衡
2 . 某些 key 的访问频率也是有热点的,也是不均衡的;
针对第一点,不同节点会负责特定的 key 集合的查询请求,一般来讲只要哈希算法还行, key 的分布是均衡的,但是针对第二点,如果某些 key 属于热点数据而被大量访问,这很会导致压力全都在某个节点上。
groupcache 有一个热点数据自动扩展机制用来解决这个问题,针对每个节点,除了会缓存本节点存在且大量访问的 key 之外,也会缓存那些不属于节点的(但是被频繁访问)的 key,缓存这些 key 的对象被称为 hotcache。
协商机制和多节点备份这两个特性是 groupcache 的杀手级特性。
使用例子
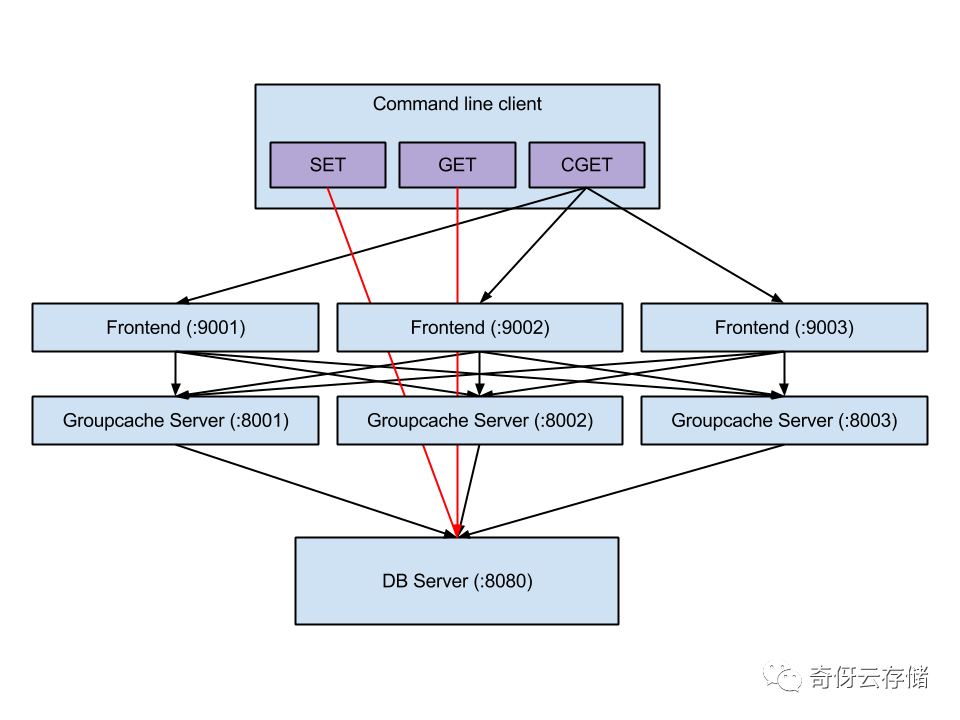
网上有一个非常好的使用例子:https://capotej.com/blog/2013/07/28/playing-with-groupcache/
架构图如下: