抖音音乐在跨端性能及异常监控上的实践
背景
作为日活 6 亿的国民级 App,抖音中存在着非常非常多的用户功能,并且几乎每天都有新业务在抖音中孵化、上线。很显然,Native 原生开发的速度和发版节奏是无法满足业务快速迭代的诉求的。因此在抖音中,存在着大量的 Hybrid 业务场景,使用的技术栈包括传统的 webview、reactNative,以及字节自研的 Lynx。
Lynx,字节跳动原创客户端跨端引擎框架,以 JavaScript 作为开发语言,可以让前端研发使用熟悉的 DSL 进行跨端开发。在今年的春晚活动中,Lynx 取得了非常亮眼的表现,在缩减客户端发板成本的同时,有效保障了页面体验。
抖音音乐业务在端内开展 Hybrid 场景时,就选择了 Lynx 技术框架。得益于公司自研,业务在监控上有了非常多的自主性。针对实际业务场景,从用户视角出发,定制了一套业务监控指标。
容器介绍
区别于传统的 H5 场景的容器 Webview,Lynx 有着自己的跨端容器 Bullet。容器对于跨端业务的全链路的监控来说非常重要,下面先来简单介绍下抖音跨端 Bullet。
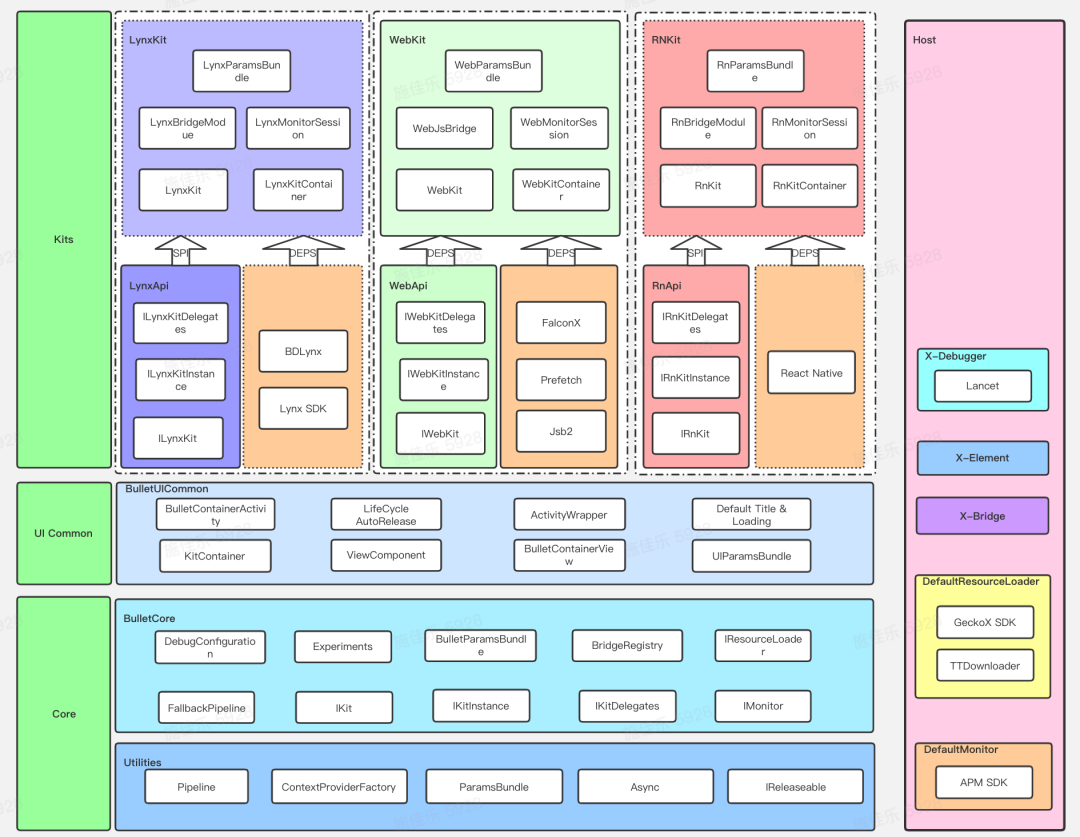
Bullet 是什么?
Bullet,字节自研的跨端通用容器,它可以同时处理 Lynx、webview、reactNative 三种跨端实现,集合了跨端场景所需要的基础能力,抹平了三种技术栈在 JSB、资源加载等方面的差异。让接入的业务客户端做到一次接入,各跨端场景均可适用。21 年春节活动中也使用了 Bullet 容器。
下面是一张 Bullet 的结构图,大体展现了 Bullet 所具备的能力。
Lynx 页面加载过程
在正式介绍跨端监控前,先来简单介绍下 Lynx 页面在 Bullet 中被加载的过程。
Bullet 架构中将 Lynx 完整的加载链路拆解成了一个个独立的子任务,执行上类似于前端中的“链式执行的 Promise”,一个任务后紧接下一个任务,上一个任务的结果会作为下一个任务的输入。
整个过程大体分为 4 个子任务:路由解析、离线资源加载、Lynx Client 初始化,Lynx 首屏渲染。
执行的顺序如下图所示
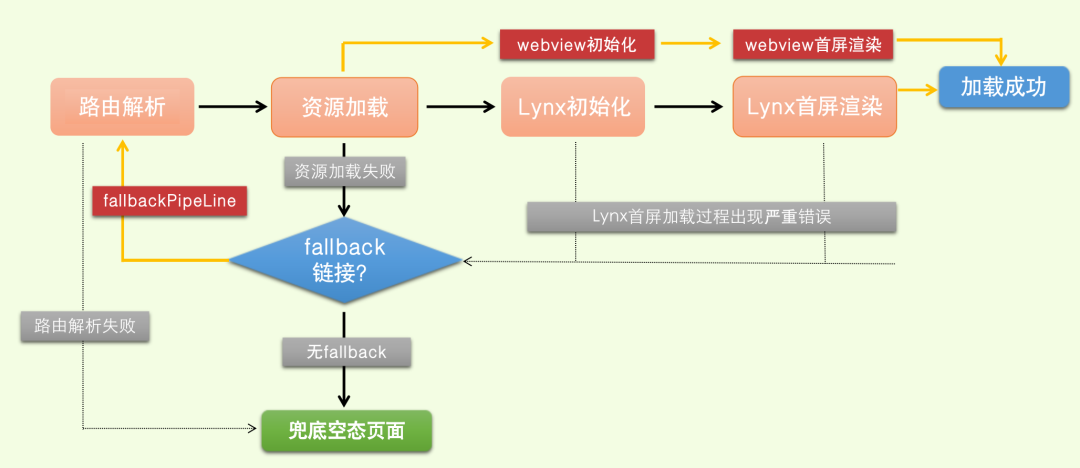
当用户行为触发唤起 Lynx 场景的页面时,Bullet 会拦截 schema,并进行路由解析,根据路由规则结合 Gecko 进行 Lynx 静态资源的加载,完成资源加载后,初始化 Lynx,将资源交由 Lynx 进行解析渲染。
Gecko,字节跳动资源分发中台,专注于客户端文件分发场景,是提升客户端动态化能力的重要基础设施。作为资源分发通道,支持各类灵活可定制的分发规则,助力业务快速迭代,大幅提升用户体验。
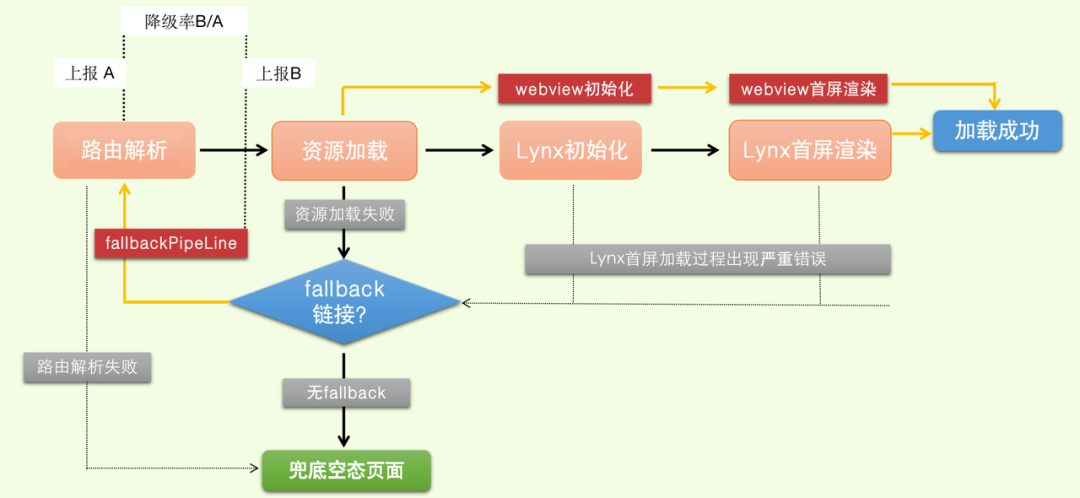
以上是各个链路都执行正常时的路径。当其中每个环节出现异常时,Bullet 会触发相应的错误处理机制。
当路由解析失败,Bullet 会加载兜底的 BulletView,呈现给用户错误提示页面。在其他环节出现异常时,若 schema 上带有 fallback 链接,则 Bullet 会进入兜底的 fallbackPipeline,再次开始路由规则的解析,资源的加载,跟 Lynx 场景不同的时是,此时初始化的 webview,在 webivew 中呈现 web 资源。
监控方案
指标定义
针对上述 Bullet 以及 Lynx 的执行过程,结合音乐场景的高体验要求的特性,我们自定义了多种监控指标,主要分为两大类,一类是性能指标,一类是错误指标。
性能监控
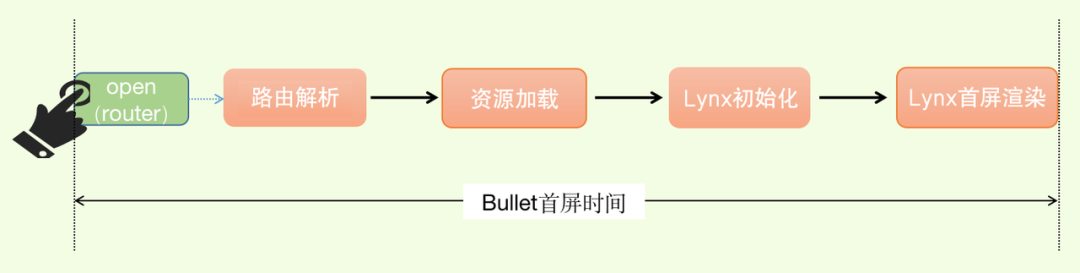
Bullet 容器首屏时间
不同于 web 场景常用的 FMP 指标,我们监测了从用户点击到Lynx页面首屏加载完成的时间间隔。在抖音,Hybrid 页面的 schema 是由 Bullet 中的 router service 管理,因此用户点击时 ~= Bullet 中 router 的 open 方法被调用时。
Lynx SDK 主要负责渲染,在渲染完成时会抛出一个回调函数,因此 Lynx 首屏渲染完成时 = Lynx 的首屏回调函数执行时。
此数值监测了用户从点击到看到页面首屏的耗时,是目前业务场景中最核心关注的指标之一。
计算公式:**容器首屏时间 = Lynx首屏渲染完成时 -Bullet的 router 拦截时**
Lynx 首屏时间
在 Lynx 页面加载的整体链路,Bullet 容器负责了 Lynx 页面的完整加载链路。而 Lynx 首屏则代表了 Lynx 容器侧的整体渲染表现。当整体链路耗时较久时,我们可以通过对比 Bullet 容器首屏与 Lynx 首屏时间,找到链路的耗时点。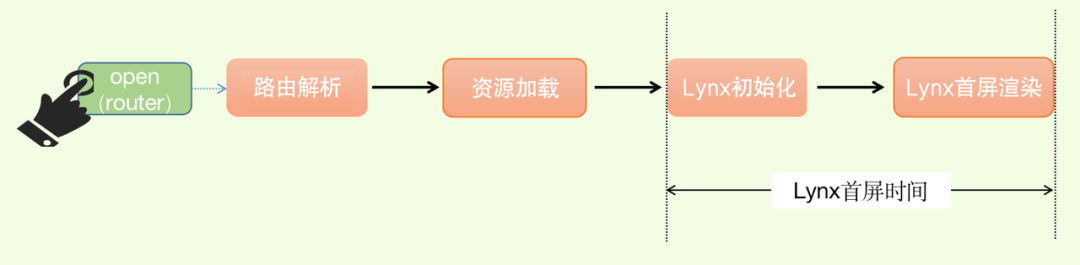
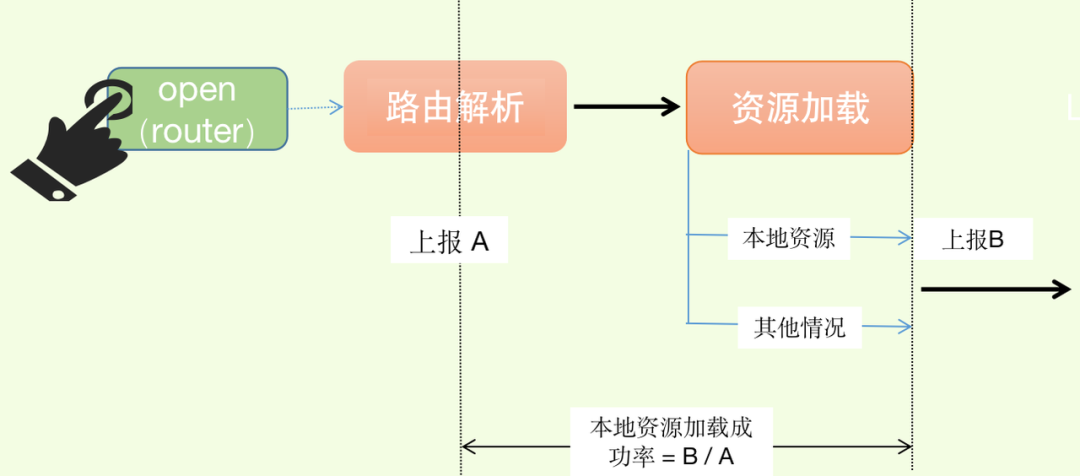
本地资源拦截成功率
Lynx 产物在实际生产环境中,是利用资源分发平台 Gecko 进行提前下发。下发的策略是,在合适的时机,提前缓存在 App 中,实现资源资源的离线化加载,这也是 Lynx 在性能上表现优异的原因之一。
Bullet 容器在资源加载时,优先尝试加载本地资源。在某些异常场景,比如网络异常或是资源分发平台 Gecko 异常时,会存在本地资源加载失败的情况,此时 Bullet 会去尝试拉取远程的 CDN 资源。
本地资源拦截成功率这一指标主要监控 Gecko 以及 Bullet 在资源加载环节的稳定性。是否成功到拦截本地资源,对于全链路的耗时有着比较大的影响,因此该指标可以用于分析全链路的耗时问题。
计算公式:本地资源拦截成功率 = 从本地加载Lynx资源成功量 / 路由解析总量
页面降级率
前面的小节提到过,Bullet 针对 Lynx 页面链路上的异常情况会进行兜底的 fallback 处理,降级至 web 场景。通常情况下降级 web 后,页面整体的体验和首屏加载时长都会差于 Lynx 场景。我们对这一数值进行监控,同时确保此数值极低,保障极致的用户体验。
计算公式:页面降级率 = 进入 fallbackPipeline 的总量 / 路由解析总量
【终极指标】自定义 TTI
在实际的业务场景中,我们通常会在首屏加载骨架屏。除了极少数纯静态的展示页面外,用户可交互的首屏都至少依赖于一个 API 接口的数据。
由于每个业务场景对页面可交互的定义都不同,因此 TTI 的结束时间点无法统一衡量。在与 Bullet 侧同学沟通后,Bullet 容器在 Hybrid 场景注入了一个 containerInitTime 值,用于代表用户点击的时间。
抖音音乐的场景中,对于用户点击到落地页面的音频首帧起播的时长是最关注的。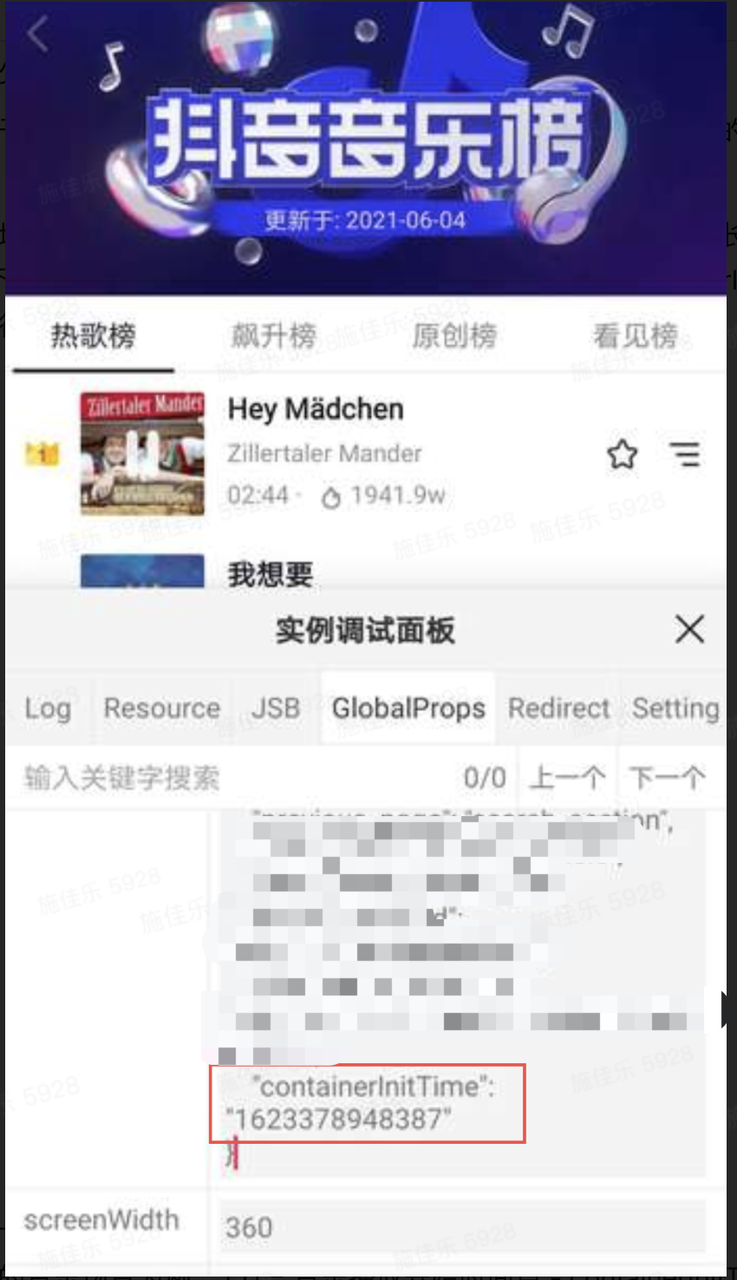
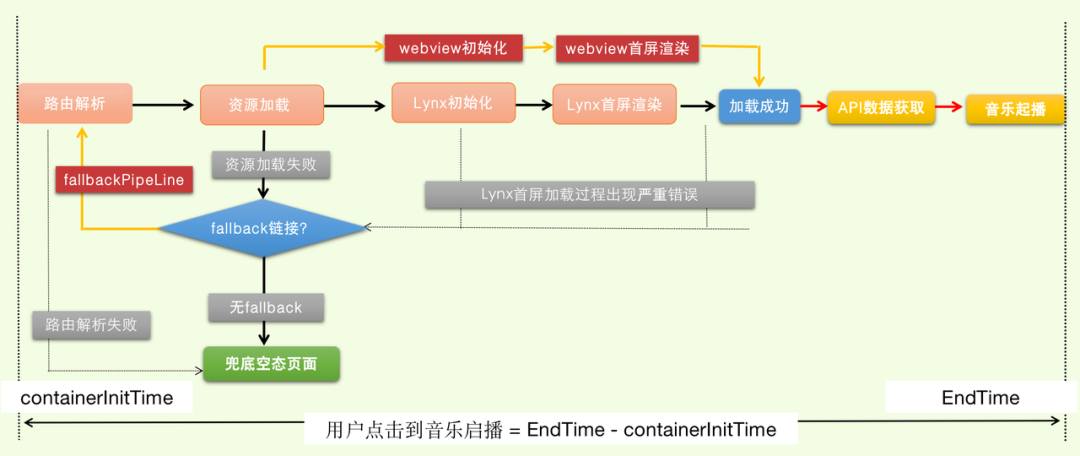
计算公式:自定义 TTI = 自定义时间节点 - containerInitTime
错误监控
在性能监控上,目前我们主要关注了用户从首屏到可交互的耗时,以及一些 Lynx 加载链路上的核心阶段的耗时和资源加载的稳定性。
在错误指标上,我们则聚焦在页面运行时的一些异常问题上,保障页面运行的稳定性。
页面加载失败率
尽管 Bullet 在 Lynx 的整个加载链路中做了很多的兜底策略,但以防黑天鹅事件,Bullet 页面的加载失败率监控仍然是非常有必要的。这个指标也是衡量 Lynx 链路稳定性的核心指标之一。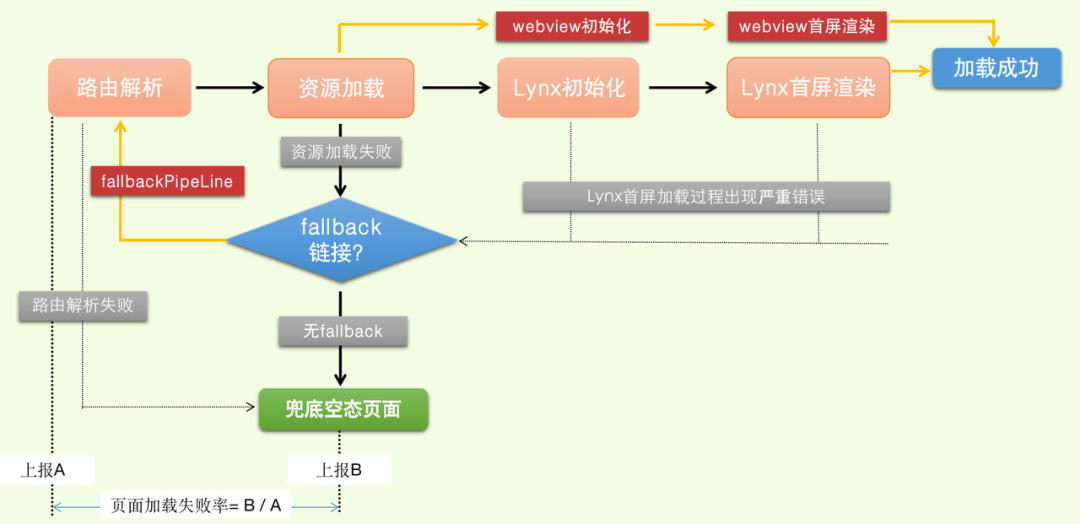
JS 错误/JSB 错误/API 请求错误/引擎层错误
页面运行时,我们全面监控了各类错误情况。包括 JS 错误、JSB 错误、发送的 API 请求错误以及容器(引擎)层的错误。 数据分析&监控上报
数据日报
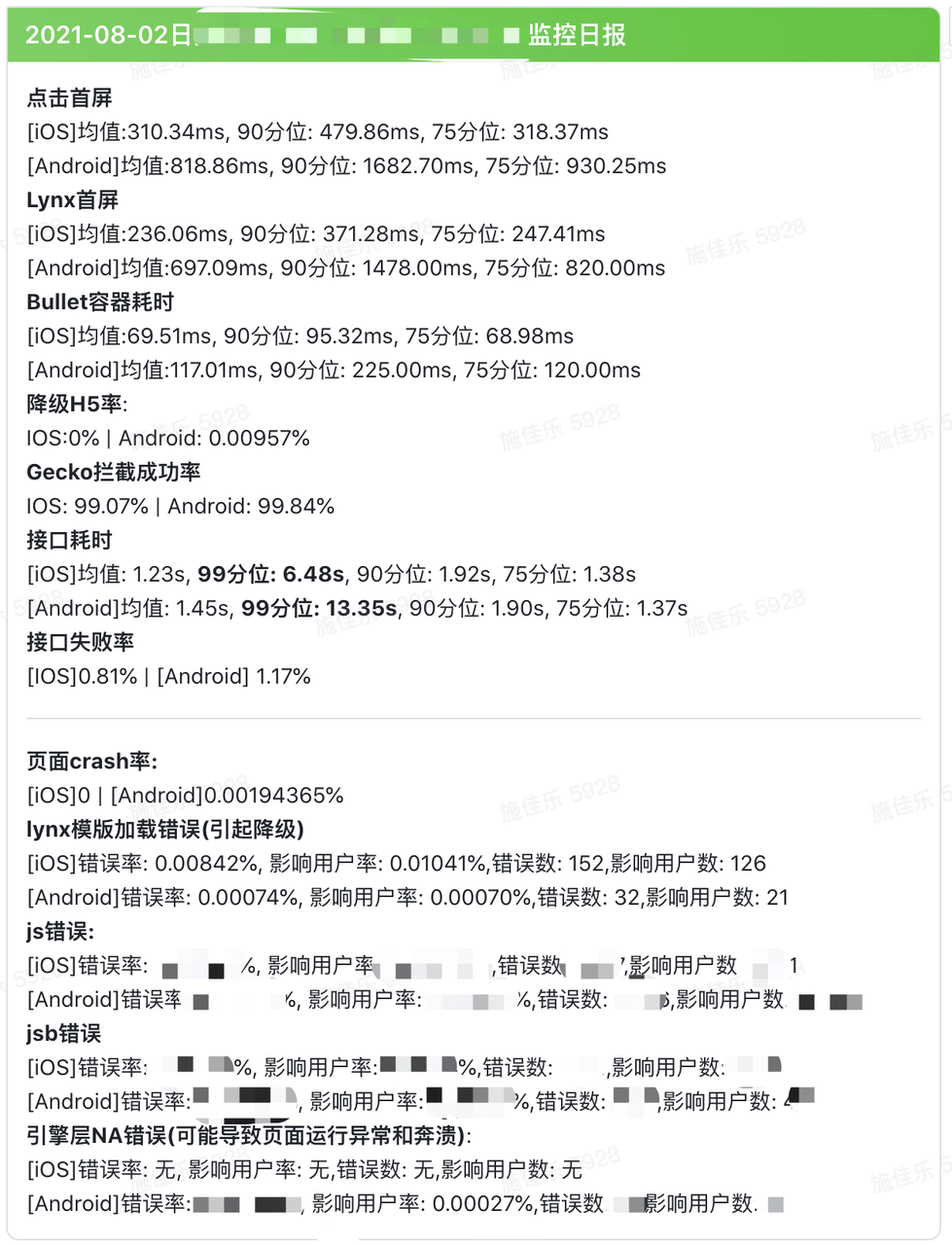
针对上述的监控指标,我们通过开发飞书的机器人[1],在相关的业务同步群中,每日同步业务场景的数据指标,以下是某个抖音音乐场景在某日的数据指标卡片。
阈值设定
21 年抖音的春节项目使用的就是 lynx 技术栈,依据春节总结的指标,我们制定了一份阈值标准。
| 性能阈值 | ||||
|---|---|---|---|---|
| 点击首屏 | lynx首屏 | 降级H5率 | 本地资源拦截率 | |
| IOS | 500ms | 200ms | 0.0001 | 99% |
| Android | 800ms | 680ms | 0.0001 | 99% |
| 错误阈值 | ||||
|---|---|---|---|---|
| jsb错误率 | js错误率 | 引擎层NA错误率 | API接口错误率 | |
| IOS | 0.0001 | 0.001 | 0.001 | 0.015 |
| Android | 0.0001 | 0.001 | 0.001 | 0.01 |
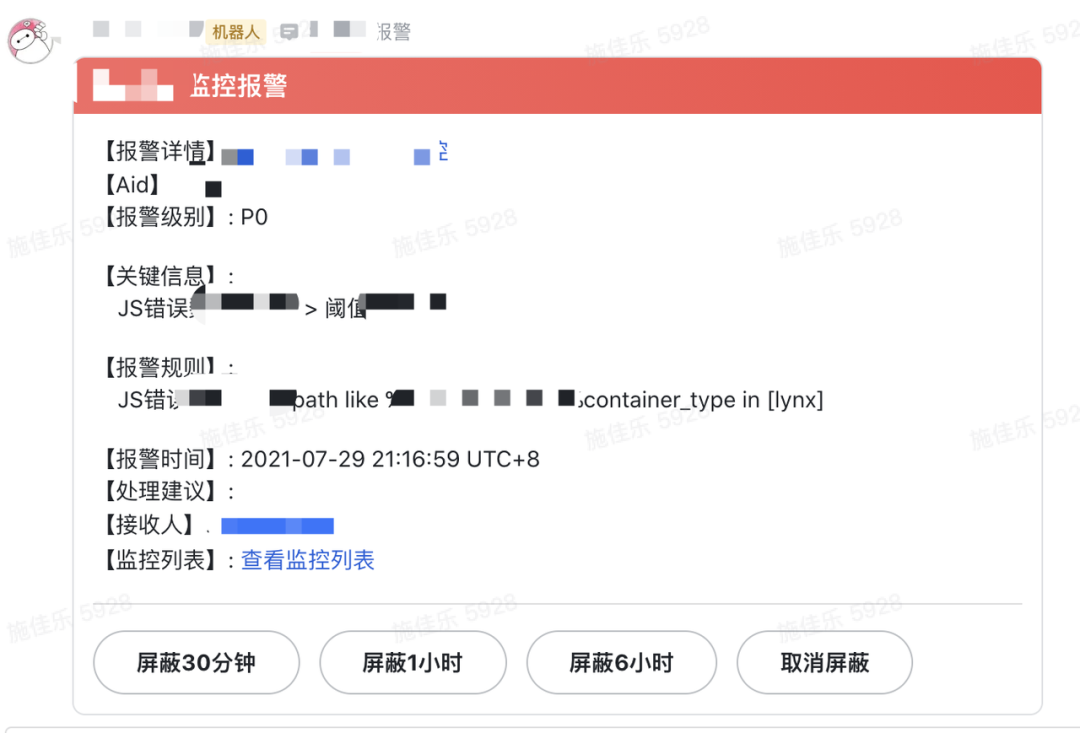
实时报警
目前抖音中的 Hybrid 相关的埋点监控数据都是实时上报监控平台,监控平台会进行实时的数据清洗工作。
利用监控平台的定时检测能力,我们对于异常错误,设置了每半个小时进行一次数据检测。当相关错误的阈值超过设置的阈值时,就会触发报警。(监控平台的报警能力连接了飞书,报警时飞书会发送一条加急消息)
错误治理
目前通过这套监控方案,我们已经发现和治理了很多的线上问题。目前推进解决的问题主要有以下几类:
场景 1:推进关键页面的首屏性能优化&关键接口瘦身
通过每日的性能数据监控,在音乐人的看见音乐计划活动期间,发现了活动页面的性能表现低于预期,活动页面的 Bullet 容器首屏时间在安卓侧超过 1s,Lynx 首屏时间超过 800ms,同时页面的首屏 TTI 也超过 3.5s。
对 Lynx 渲染链路进一步分析,发现了首屏时间主要耗费在资源包加载上。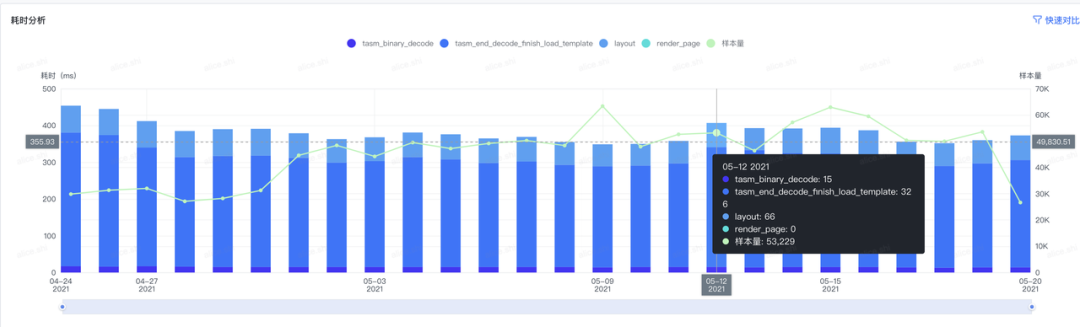
于是对资源包进行体积压缩优化,通过首屏页面第一屏切割,静态图片压缩方式,将资源包提体积从 1134KB,缩小至 416KB,包体积瘦身 63.32%,页面的首屏时间也降低了 38.75%。
针对活动页面首屏 TTI 过大的问题,通过对接口数据瘦身、缩短获取路径方式,接口响应耗时减少将近 1s。
场景 2:推进解决 Lynx 底层的代码优化
通过对 Lynx 引擎层的错误监控,我们发现了一些 Lynx 底层一些代码问题,比如代码中的各类判空问题等。通过 Lynx 侧负责同学的及时修复处理,提高了线上业务的容错性和稳定性。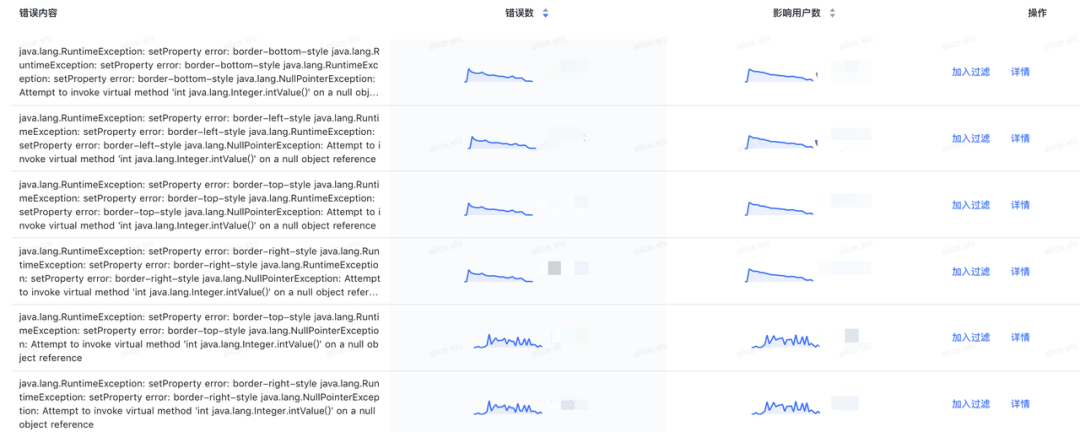
总结&未来规划
以上就是抖音音乐目前在抖音内的跨端监控实践。现阶段,我们只监控了页面核心一些数据指标,相对于 web 场景的完善的监控指标来说,Lynx 场景的监控还相差较多。比如缺少页面的流畅度、LCP、FID 等等指标。
同时在数据分析维度,目前还不够细化,比如针对不同评分的机型,需要设定不同阈值的标准。针对端错误场景引入错误等级制度,将上报的错误进行归类细化,以对用户的实际影响,将错误分为 fatal 类错误(页面加载错误)、serious 类错误(用户无法正常交互)、warning 类错误(影响用户体验),帮助业务开发同学更好的评估和处理页面的错误。
在未来,我们还希望建立一套全面的完善的 Hybrid 性能&错误评估体系,能够将 web、lynx、native 三个场景进行数据对焦,帮助开发同学在技术选型时,能够从数据维度清晰的、全面的对比 3 种技术栈的优劣。
道阻且长,行则将至,行而不辍,未来可期。