Kafka 降本实用指南

根据 Gartner 的预测,预计在 2021 年,全球终端用户在公共云服务上的支出将在 2020 年的 2700 亿美元基础上增长 23%,达到 3320 亿美元。
Kafka 的市场增长趋势也是一样的。世界各地的组织都在使用 Kafka 作为主要的流处理平台来大规模收集、处理和分析数据。随着组织的发展和壮大,数据规模也在增长,随之而来的云成本同样日益上升。
所以我们能做些什么呢?为了削减成本,我们是否可以实施一些容易实现的策略?
本文就此主题列举了一些可能会有所帮助的提示和 KIP(Kafka 改进建议)!
免责声明
这篇文章不会涵盖那些旨在降本的托管服务方法。在某些用例中,像 Confluent Cloud 这样的托管服务可能会起到作用。要获取更多信息,你可以参考 Confluent 网站上的成本效益页面。
在开始之前,我们先来了解一些基础知识。
1 我们的钱都花在了什么地方?
我可以试着列出我们在使用各种云服务时花钱购买的所有组件,但这样还不如来看 Gwen Shapira 在她的文章“Apache Kafka 的成本:为 DIY 运维定价的工程师指南”中总结的内容。
我们从一些相当明显且易于量化的费用开始分析。如果你打算在 AWS 上运行 Kafka,你需要为 EC2 machines 支付费用来运行你的 broker。如果你使用像 EKS 这样的 Kubernetes 服务,你要为 节点 和服务本身(Kubernetes 主节点)付费。大多数相关的 EC2 类型都是 EBS 存储,Kubernetes 仅支持 EBS 作为一等磁盘选项,这意味着 除了 EBS 数据卷之外,你还需要为 EBS 根卷付费。还要记得,在合并 KIP-500 之前 Kafka 不只有 broker——我们还需要运行 Apache ZooKeeper,给它 算上三到五个节点及其存储的费用。我们的 Kafka 是在一个 负载均衡器(部分充当一个 NAT 层)之后运行的,并且由于每个 broker 都需要单独寻址,因此你需要 为“引导”路由和每个 broker 的路由付费。
所有这些都是固定成本,你一个字节都不向 Kafka 发送也得花这些钱。
除此之外还有网络成本。将数据导入 EC2 需要花钱,并且根据你的网络设置(VPC、私有链接或公共互联网),你可能在发送和接收数据时都要付费。如果你在不同地区或区域之间复制数据,请一定要考虑到这些成本。如果你通过 ELB 路由流量,你将为此流量支付额外费用。不要忘了算上入口和出口,并且要记住,使用 Kafka 时,你读取的数据往往是写入量的 3-5 倍。
现在我们算上了运行软件、摄取数据、存储和读取数据的成本,我们就快完成了。你还需要监控 Kafka,对吧?一定要考虑到监控(Kafka 有许多重要的指标)——无论是使用服务还是自托管,你还需要一种收集日志 并搜索它们的方法。最后这些可能成为系统中最昂贵的部分,特别是如果你有许多分区的时候,这会显著增加指标的数量。
我加粗了帖子中的要点,还有来自 Kafka 生态系统的其他一些组件在文中没有直接提到,如 Schema Registry、Connect workers,以及 CMAK 或 Cruise-Control 等工具,但这些都适用于同样的三个要素——机器、存储和网络。
虽然有更多要素是难以衡量的,例如员工工资、停机时间,甚至处理中断(也就是将系统维持在可用状态所必须完成的工作),但上面这三点是我们在使用云提供商时花钱购买的主要要素。
2 我们可以做什么?
除了适用于几乎所有分布式系统的一些基本概念之外,随着时间的推移,Kafka 的提交者引入了一些直接或间接影响 Kafka TCO 的 KIP 和特性。
但我们还是会从显而易见的东西开始分析——
你是否使用了正确的实例类型?
AWS 上有很多实例类型可供选择(当然,这里提到的方法也可以用在其他云提供商上)。
Kafka 可以在廉价的货架硬件上轻松运行,并且不会出什么显眼的问题。如果你在谷歌上搜索生产级 Kafka 集群的推荐实例类型,你会发现人们建议用 r4、d2 甚至 c5 与 GP2/3 或 IO2 存储搭配用于一般用途。
每种组合都有自己的优点和缺点,你可能需要根据各种权衡来找到最适合自己的选项——这些权衡包括更长的恢复时间(HDD 磁盘)、存储性价比、网络吞吐量,甚至 EBS 在极端情况下的性能下降。
但随着时间的推移,i3 和 i3en 机器得到了人们的青睐;根据我的经验,它们是迄今为止获推荐最多的高回报率大规模部署实例类型,就算你考虑到了使用非永久存储器带来的运维开销也是如此。
使用 Kafka 时,i3 和 i3en 在无数基准测试中都提供了更好的性能,并充分利用了非永久驱动器的优势(10gbps 磁盘带宽,对比 EBS 优化的 C 级实例的 875mbps)。
ScyllaDB 的这篇很棒的文章,研究了在主要瓶颈因素是存储容量的系统上使用 i3en 机器带来的显著成本优势(稍后会详细介绍):
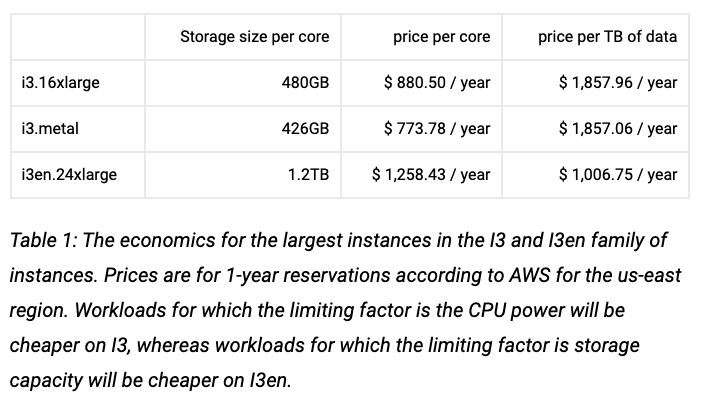
作为降低成本的第一步,你需要重新评估你的实例类型决策:你的集群是否饱和?在什么情况下饱和?是否存在其他实例类型,可能比你第一次创建集群时选择的类型更合适?EBS 优化实例与 GP2/3 或 IO2 驱动器的混合是否真的比 i3 或 i3en 机器(及其带来的优势)有更好的性价比?
如果你不熟悉这款工具,你应该了解一下。
压缩
压缩在 Kafka 中并不新鲜,大多数用户已经知道了自己可以在 GZIP、Snappy 和 LZ4 之间做出选择。但自从KIP-110被合并进 Kafka,并添加了用于 Zstandard 压缩的压缩器后,它已实现了显著的性能改进,并且是降低网络成本的完美方式。
Zstandard 是 Facebook 的压缩算法;与其他压缩算法相比,它旨在实现更小、更快的数据压缩。
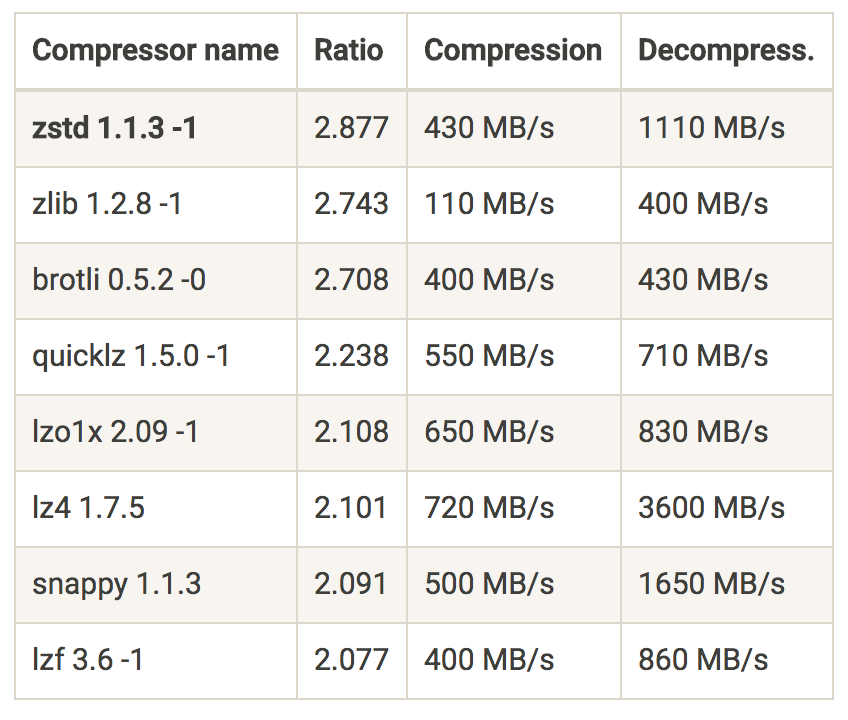
例如,使用 zstd(Zstandard)后,Shopify 获得了 4.28 倍的压缩率。关于 zstd 优势的另一个很好的例子是 Cloudflare 的“挤一挤 firehose:从 Kafka 压缩中获得最大收益”这篇文章。
这和降低成本又有什么关系呢?以生产者端略高的 CPU 使用率为代价,你将获得更高的压缩率并在线上“挤进”更多信息。
Amplitude 在他们的帖子中介绍,在切换到 Zstandard 后,他们的带宽使用量减少了三分之二,仅在处理管道上就可以节省每月数万美元的数据传输成本。
毕竟你还要支付数据传输费用,记得吗?
从最近的副本中获取数据
为了容错需求,在同一 AWS 区域内的几个可用区上分布集群是很常见的做法。
遗憾的是,我们无法通过协调让消费者的分布与他们需要消费的分区 leader 完美对齐,以避免跨区域流量和成本。参阅 KIP-392。
2015 年的 KIP-36 合并之后,机架感知就可以启用了,并且只需在配置文件中添加一行代码就可以轻松完成:
broker.rack=<rack ID as string> # For example, AWS AZ ID
在实现 KIP-392 之前,此设置仅控制副本位置(将 AZ 视为机架)。而这个 KIP 正好解决了这个麻烦,并允许你利用局部性来减少昂贵的跨 dc 流量。
一些客户端已经实现了这一更改,如果你的客户端还不支持它,这里有一个开源项目适合你周末来研究!
集群均衡
这一点可能看起来没那么明显,但如果你的集群不平衡,也可能会影响集群成本。
不平衡的集群可能会损害集群性能,导致某些 borker 比其他 broker 的负载更大,让响应延迟更高,并且在某些情况下会导致这些 broker 的资源饱和,从而导致不必要的扩容。
不平衡集群面临的另一个风险是在一个 broker 出故障后出现更高的 MTTR(例如当该 broker 不必要地持有更多分区时),以及更高的数据丢失风险(想象一个复制因子为 2 的主题,其中一个节点由于启动时要加载的 segment 过多,于是难以启动)。
不要让这个相对容易完成的任务去浪费金钱。你可以使用 CMAK、Kafka-Kit 等工具,更好的是 Cruise-Control,它允许你根据多个目标(容量违规、副本计数违规、流量分布等)自动执行这些任务。
3 微调你的配置——生产者、broker、消费者
听起来很明显吧?其实在友好的 Kafka 集群幕后,你可以启用或更改大量设置。
这些设置会极大地影响集群的工作方式:资源利用率、集群可用性、保证、延迟等等。
例如,行为不端的客户端会影响你的 broker 资源利用率(CPU、磁盘等)。更改你的客户端 batch.size 和 linger.ms(与业务逻辑相适应)可以显著降低集群 LoadAvg 和 CPU 使用率。
消息转换会带来处理开销,因为 Kafka 客户端和 broker 之间的消息需要转换才能被双方理解,从而导致更高的 CPU 使用率。升级你的生产者和消费者可以解决这一问题,将本来不需要用在这上面的资源释放出来。
这样的例子数不胜数。
通过适当的微调,你可以让集群更好地运作、提供更多服务、增加吞吐量、释放资源,从而避免不必要的扩容,甚至可以将集群缩小到适合你需求的大小。
阅读和处理每一行文档是一项不可能完成的任务,因此你可以先阅读其中一篇关于调整客户端和 broker 的帖子。我会推荐 Strimzi 的系列相关文章——Broker、生产者和消费者。
4 未来
压缩级别
如前所述,使用某种压缩算法(最好是 zstd)可以极大地提高性能并节省数据传输费用。
处理压缩时,你需要面对一种新的权衡决策——CPU vs IO(压缩后文件的大小)。大多数算法提供了一些压缩级别可供选择,这会影响所需的处理能力和压缩后的数据集大小。
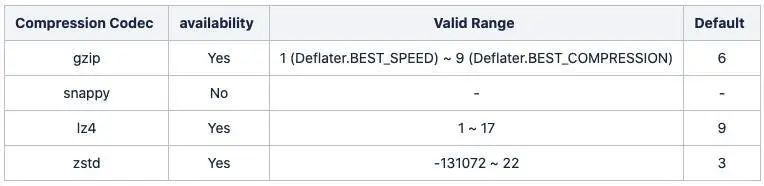
压缩器支持的压缩级别
到目前为止,Kafka 仅支持每种压缩器的默认压缩级别。这个问题将在 KIP-390 上得到解决,KIP-390 将随 Kafka3.0.0 一起提供。
实现这个 KIP 后,我们将能在配置中添加一行,将压缩级别设置得更高(设置到合适的级别。记住更高的级别对应更多的资源开销)
compression.type=gzip
compression.level=4 # NEW: Compression level to be used.这个新特性针对真实世界的一个数据集(29218 个 JSON 文件,平均大小为 55.25kb)进行了测试,结果可能因编码、压缩级别的不同和由此产生的延迟而异,如下所示

分层存储
集群上所需的总存储量与主题和分区的数量、消息速率以及最重要的保留期限成正比。集群上的每个 Kafka broker 通常都有大量磁盘,于是单个集群上一般会有数十 TB 的磁盘存储。Kafka 已经成为组织中所有数据的主要入口点,让客户端不仅可以消费最近的事件,还可以根据主题保留来使用较旧的数据。
人们很可能会添加更多 broker 或磁盘,以便根据客户的需求在集群上保存更多数据。
另一种常见模式是将你的数据管道拆分为一些更小的集群,并在上游集群上设置更长的保留期限,以便在发生故障时进行数据恢复。使用这种方法时,你能完全“停止”管道,修复管道中的错误,然后流回所有“丢失”的事件,而不会丢失任何数据。
这两种情况都需要你为集群增加容量,而且通常还会向集群添加不必要的内存和 CPU,于是与将旧数据存储在外部存储的方案相比,它们的总体存储成本效率较低。具有更多节点的更大集群也增加了部署的复杂性并增加了运营成本。
为了解决这个问题,KIP-405 分层存储应运而生。
使用分层存储时,Kafka 集群配置有两层存储:本地和远程。本地层和现在是一样的,也就是使用本地磁盘——而新的远程层会使用外部存储层(如 AWS S3 或 HDFS)来存储完整的日志 segment,这会比本地磁盘便宜得多。
你能为每一层设置多个保留期限,因此对延迟更敏感且使用实时数据的服务可以从本地磁盘提供,而需要旧数据进行回填,或在事故后恢复的服务可以经济地从外部层加载数周甚至数月时间。
除了明显的磁盘成本下降(gp3 每 GB 约 0.08 美元,S3 约 0.023 美元)之外,你还可以根据服务需求(主要基于计算能力而非存储)进行更准确的容量规划,独立于内存和 CPU 来扩展存储,并节省不必要的 broker 和磁盘的费用。
节省的成本是非常可观的。
你的 broker 恢复速度会更快,因为它们在启动时需要加载的本地数据要少得多。
分层存储已在 Confluent Platform 6.0.0 上可用,并将添加到 Kafka3.0 版本中。
KIP-500:Kafka 不需要 Keeper
可能你还没有听说过,在未来的版本中,Kafka 将移除其对 ZooKeeper 管理集群元数据的依赖,并移至基于 Raft 的治理模式。
这不仅将提供一种更具扩展性和健壮性的元数据管理方式,还能简化 Kafka 的部署和配置(去除外部组件),而且还消除了 Zookeeper 部署的成本。
如前所述,Kafka 不仅仅是一堆 broker,我们需要为 Zookeeper 运行三五个节点;除了实例之外,你还需要算上它们的存储和网络的成本,以及难以衡量的运营开销(例如监控、警报、升级、事件和关注)。
5 总结
要降低云成本可以有很多方法。其中一些是可以在几分钟内实现的唾手可得的成果,而另一些则需要更深入的理解、尝试和试错。
这篇文章仅涵盖了降低成本的一小部分方法,但更重要的是它试图强调一个事实,即了解在云上运行 Kafka 时我们需要支付哪些费用是很重要的。
我们需要意识到,有时云成本可能会超出人们的想象。