LOCK
LOCK
锁,大家应该很熟悉了,用来避免竞争,实现同步。本文以 xv6 为例来讲解锁本身是怎么实现的,废话不多说,先来看一些需要了解的概念.(插个题外话,有知道封面出处,四个框填什么的吗?文末揭晓答案)
一些概念
公共资源:顾名思义就是被多个任务共享的资源,可以是公共内存,也可以是公共文件等等
临界区:要访问使用公共资源,肯定得通过一些代码指令去访问,这些代码指令就是临界区
并发:单个 CPU 上交替处理多个任务,宏观上看就像是同时进行的一样,但微观上看任意时刻还是只有一个任务在进行。
并行:多个处理器同时处理多个任务,能够做到真正意义上的多个任务同时进行。
互斥:也称为排他,任何时候公共资源只允许最多一个任务独享,不允许多个任务同时执行临界区的代码访问公共资源。
竞争条件:竞争条件指的是多个任务以竞争的形式并行访问公共资源,公共资源的最终状态取决于这些任务的临界区代码的精确执行时序。
显然竞争条件并不是我们想要的,虽然一些竞争条件出现的概率很小,但根据墨菲定律,会出错的总会出错,加之计算机的运行频率,就算出错的概率再小,在某天某时某刻那也是有可能发生的。
所以对于进入临界区访问公共资源我们要避免竞争条件,保证公共资源的互斥排他性,一般有两种大的解决方案来实现互斥:
- 忙等待:没进入临界区时一直循环,占用 CPU 资源
- 休眠等待:没进入临界区时一直休眠,不占用 CPU,CPU 利用率较高,但有进程上下文切换的开销
那如何知道临界区能不能进,公共资源能不能访问,总得有个测试的东西,好让进程知晓现在是否进入临界区访问公共资源,这个用来测试的东西就是锁。根据上面两种大的解决方案,xv6 实现了两种锁,自旋锁和休眠锁,下面来仔细看看:
自旋锁
结构定义
struct spinlock {
uint locked; // Is the lock held?
// For debugging:
char *name; // Name of lock.
struct cpu *cpu; // The cpu holding the lock.
uint pcs[10]; // The call stack (an array of program counters)
// that locked the lock.
};有关自旋锁的结构定义如上,最重要的就是 locked 元素,用来表示该锁是否已被某 CPU 取得,1 表示该锁已某 CPU 取走,0 表示该锁空闲。其他三个元素用作为 debug 调试信息,后面用到具体再看。
相关函数
void initlock(struct spinlock *lk, char *name) //初始化锁 lk
{
lk->name = name; //初始化该锁的名字
lk->locked = 0; //初始化该锁空闲
lk->cpu = 0; //初始化持有该锁的CPU为空
}
void pushcli(void)
{
int eflags;
eflags = readeflags(); //读取eflags寄存器
cli(); //关中断
if(mycpu()->ncli == 0) //关中断次数为0时,这应为第一次pushcli()
mycpu()->intena = eflags & FL_IF; //将intena一直设置为1,开关中断用ncli来控制
mycpu()->ncli += 1; //关中断次数加1
}void popcli(void)
{
if(readeflags()&FL_IF) //如果eflags寄存器IF位为1
panic("popcli - interruptible");
if(--mycpu()->ncli < 0) //如果计数小于0
panic("popcli");
if(mycpu()->ncli == 0 && mycpu()->intena) //关中断次数为0时即开中断
sti();
}pushcli() 和 popcli() 为 cli() 和 sti() 的封装函数,只是增加了计数,每个 popcli() 与 pushcli() 匹配,有多少次 pushcli() 就要有多少次 popcli()。为什么使用 pushcli() 和 popcli() 而不是使用 cli() sti() 后面详细说明。
int holding(struct spinlock *lock)
{
int r;
pushcli();
r = lock->locked && lock->cpu == mycpu(); //检验锁lock是否被某CPU锁持有且上锁
popcli();
return r;
}关中断下检查锁是否被某 CPU 取走,仔细看检查是否持有锁的条件为两个:一是锁是否被取走,二锁是否由当前 CPU 取走。
void acquire(struct spinlock *lk)
{
pushcli(); // disable interrupts to avoid deadlock.
if(holding(lk)) // 如果已经取了锁
panic("acquire");
while(xchg(&lk->locked, 1) != 0) //原子赋值
;
__sync_synchronize(); //发出一个full barrier
// 调试信息
lk->cpu = mycpu(); //记录当前取锁的CPU
getcallerpcs(&lk, lk->pcs); //获取调用栈信息
}关中断下进行取锁的操作,以避免死锁,原因见后面 FAQ
检查当前 CPU 是否已经持有锁,如果已持有,则 panic(),也就是说 xv6 不允许同一个 CPU 对同一个锁重复上锁。
上锁的语句为 xchg() 函数可以看作一个原子赋值函数(本是交换,与 1 交换就相当于赋值,详见[内联汇编] ,将 赋值为 1,返回 的旧值。也就是说如果该锁空闲没有 CPU 持有,那么当前 CPU 将其赋值为 1 表示取得该锁,xchg 返回旧值 0,跳出 while 循环。如果该锁已经被某 CPU 持有,那么 xchg 对其赋值为 1,但返回值也是 1,不满足循环跳出条件,所以一直循环等待某 CPU 释放该锁。因取锁可能需要一直循环等待,所以名为自旋锁。
__sync_synchronize() 是发出一个 full barrier,简单来说就是不允许将这条语句之前的内存读写指令放在这条之后,也不允许将这条语句之后的内存读写指令放在这条指令之前。为啥要放个屏障在这?按照正常的逻辑思维应该是该 CPU 获取到了锁才对该锁的一些 debug 信息做记录的对吧,如果不加屏障,顺序就可能颠倒。再者就是中断方面的原因,后面详述。
void release(struct spinlock *lk)
{
if(!holding(lk))
panic("release");
lk->pcs[0] = 0;
lk->cpu = 0;
__sync_synchronize();
asm volatile("movl $0, %0" : "+m" (lk->locked) : );
popcli();
}释放锁,基本就是加锁的逆操作了,释放锁和清除调试信息,有关内联汇编的同样还是看前文,本文不赘述。
调试信息
其他的像记录 CPU 都好说,主要是来看这个 getcallerpcs() 函数,寻找记录调用栈的信息:
void getcallerpcs(void *v, uint pcs[])
{
uint *ebp;
int i;
ebp = (uint*)v - 2;
for(i = 0; i < 10; i++){
if(ebp == 0 || ebp < (uint*)KERNBASE || ebp == (uint*)0xffffffff)
break;
pcs[i] = ebp[1]; // saved %eip
ebp = (uint*)ebp[0]; // saved %ebp
}
for(; i < 10; i++)
pcs[i] = 0;
}pc[] 到底是个啥玩意儿?每次调用函数使用 call 指令的时候都会把 call 指令的下一条指令压栈,pc[] 就是存放的是这个返回地址,来看看是怎么实现的。
首先要知道函数调用的几个规则:
- call 指令调用函数之前要先将参数压栈,方向为从右至左,先压最后一个参数,最后压第一个参数
- call x,将 x 赋给 eip, 将下一条指令的地址压入栈中
- 进入函数时先 push %ebp,再 movl %esp, %ebp 形成新的栈帧。
所以栈中的情况大致应该是这样的:
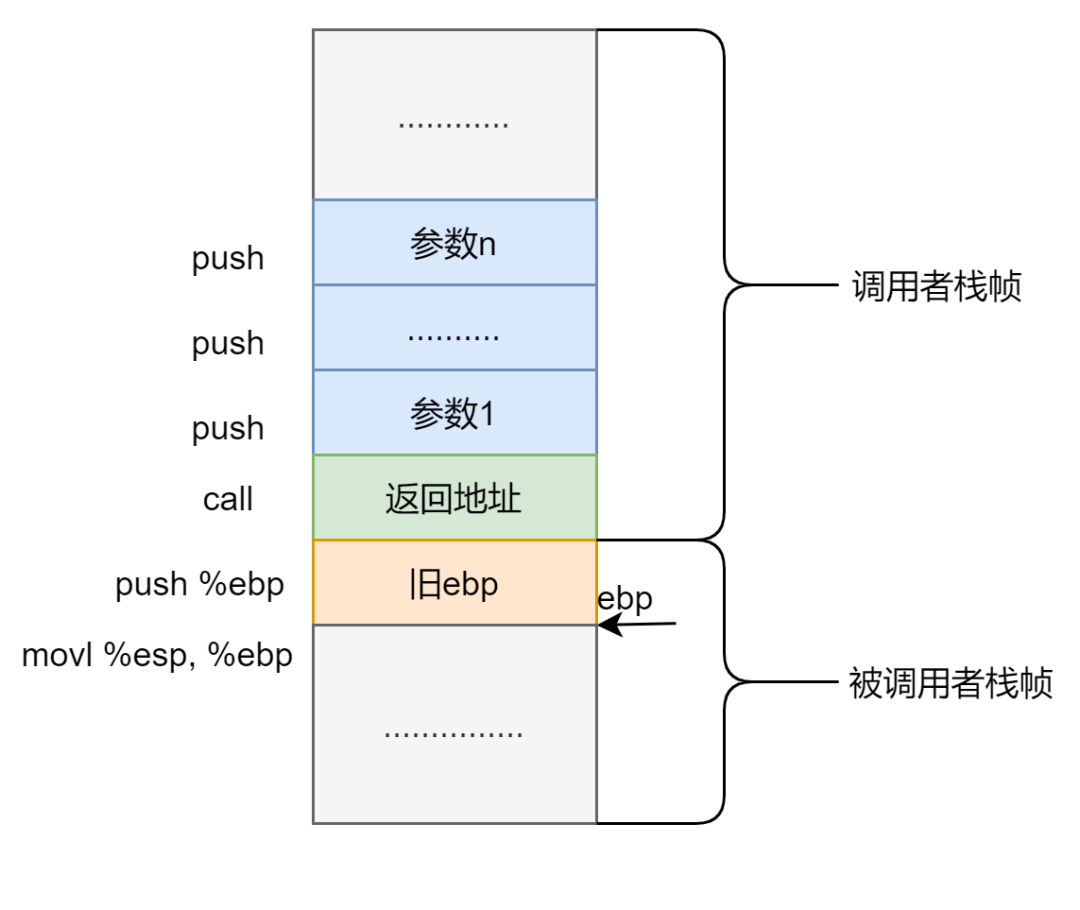
要理清 getcallerpcs() 函数,不能只看一层调用,至少要看两层调用,举个例子:函数 A 调用 acquire(plk),acquire(plk) 调用 getcallerpcs(&plk, plk->pcs),这里我用 plk 来表示锁,只是想说明它是个指针是个地址,所以 getcallerpcs() 中的 &plk,是个二级指针,这也是这个函数能够得以实现的关键点之一,来看看栈帧什么样子的:
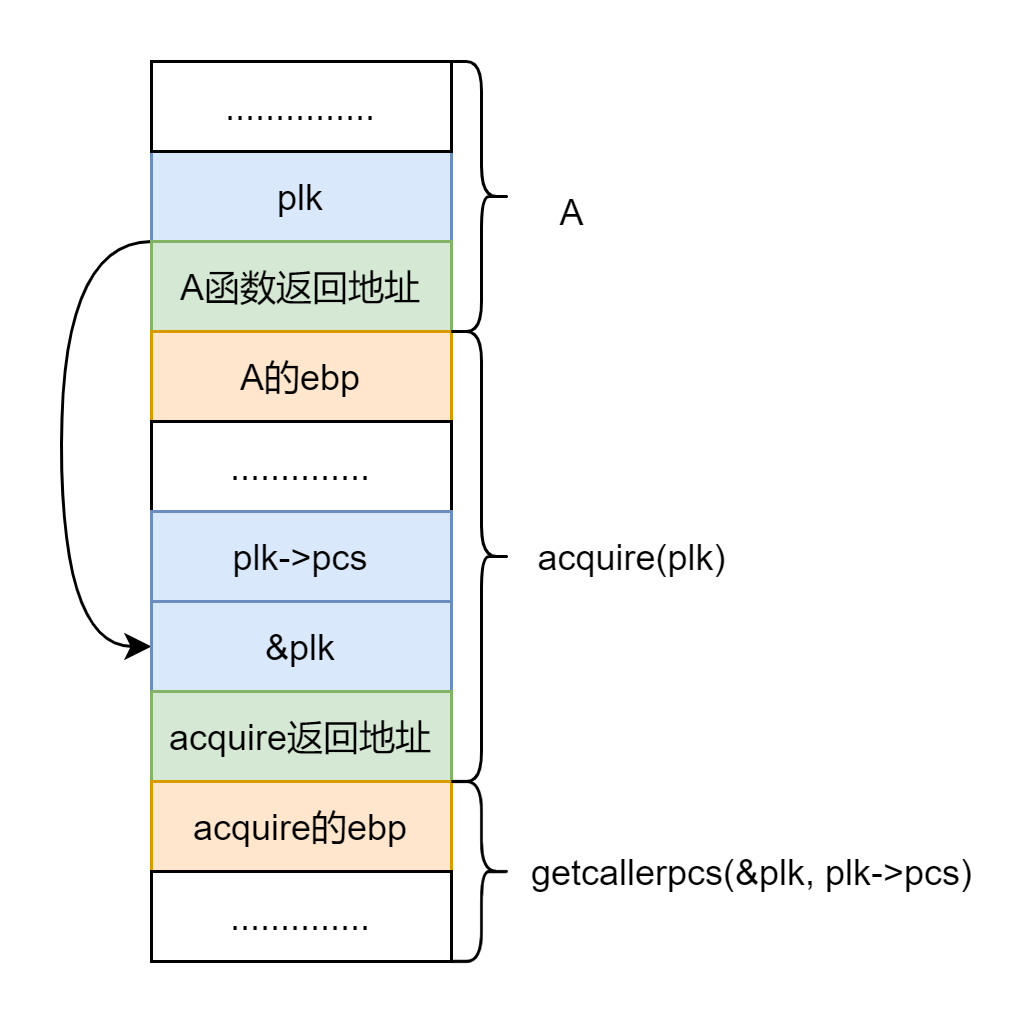
FAQ
基本函数说完,来聊聊一些遗留问题:
xv6 的竞争条件有哪些?
xv6 是个支持多处理器的系统,各个 CPU 之间可以并行执行,所以可能会出现同时访问公共资源的情况。
在单个 CPU 上,中断也可能导致并发,在允许中断时,内核代码可能在任何时候停下来,然后执行中断处理程序,内核代码和中断处理程序交叉访问公共资源也可能导致错误。所以在取锁检验锁都要在关中断下进行。
另外 xv6 不支持线程,而各个进程之间内存是不共享的,加之内核进入临界区访问公共资源的时候是关了中断的,关中断后除了自己休眠是不会让出 CPU 的,所以各个进程之间的并发其实并不会产生竞争条件
为什么要使用 xchg()?
试想不使用 xchg() 来实现应该怎么实现?下面代码由 xv6 文档给出:
for(;;) {
if(!lk->locked) {
lk->locked = 1;
break;
}
}这种实现方式,访问 和修改分为了两步,可能会出现这样的状况:CPU1 和 CPU2 接连执行到上述的 if 语句,发现 ,那么两者都执行 拿到了锁,这就违反了互斥的原则。而 xchg() 直接将 与 1 原子交换并返回 的旧值则避免了上述问题。
acquire() 函数为什么要关中断,或者说先关中断再上锁?
对于为什么要关中断前面竞争条件简单说过,这里从死锁的角度来看,假如两者交换先上锁再关中断或者直接不关中断,若有 A 调用 acquire() 想要获得锁,当它拿到锁时刚好发生中断,中断处理程序也想要获得该锁,但 A 已经换下 CPU 了,肯定释放不了啊,那么就产生死锁。所以要先关中断再上锁。
release() 函数先原子赋值释放锁再开中断,也就同理了,如果两者交换先开中断,那么在释放锁之前可能发生中断,而中断处理程序刚好需要该锁,那么发生死锁。
关中断开中断为什么要使用 pushcli() 和 popcli() 而不直接使用 cli() 和 sti()?
前面我们已经知道如果在 CPU 持有锁的阶段发生中断,中断服务程序可能也要取锁,那么就会死锁,所以 xv6 直接决定在取锁的时候就关中断,CPU 持有锁的整个阶段都处于关中断,只有释放锁的时候才可能开中断,注意这里是可能,因为用的是 popcli()。
那么正题就来了,为什么要使用 pushcli() 和 popcli(),其实也简单,那是因为某个函数中可能要取多个锁,比如先后取了锁 1 锁 2,那么释放锁 2 之后能开中断吗?显然不能,必须等锁 1 也释放的时候才能开中断。所以使用增加了计数功能的 pushcli() 和 popcli() 来实现最后一个锁释放的时候才开中断。
内存乱序问题
现今的指令的执行都有流水线的技术,其实还有乱序执行。乱序执行指的是在 CPU 运行中的指令不按照代码既定的顺序执行,而是按照一定的策略打乱后顺序执行,以此来提高性能。
不是所有的指令序列都可以打乱,没有关系的指令之间才可以打乱。这种乱序执行的确在一定程度上可以提高性能,但也会暴露一些问题,比如前面涉及开关中断的指令,对于我们人来说,这种指令与它相邻的一些指令之间肯定是有逻辑联系的,但 CPU 不知道啊,CPU 判断指令之间是否有关系只能凭借简单的逻辑,比如 B 指令需要 A 指令的结果。但是像上面那种复杂的逻辑关系它是不能判断的就可能将指令顺序错误的打乱,为避免这种情况,我们设置了屏障,禁止这个屏障前后的指令顺序打乱。
休眠锁
xv6 里面还提供了另一种锁,休眠锁,它在自旋锁的基础之上实现,定义如下:
struct sleeplock {
uint locked; // Is the lock held?
struct spinlock lk; // spinlock protecting this sleep lock
// For debugging:
char *name; // Name of lock.
int pid; // Process holding lock
};休眠锁的初始化,检验是否持有锁等都类似,就不赘述了,在这里主要看看取锁和放锁的区别:
void acquiresleep(struct sleeplock *lk)
{
acquire(&lk->lk); //优先级:->高于&
while (lk->locked) { //当锁已被其他任务取走
sleep(lk, &lk->lk); //休眠
}
lk->locked = 1; //上锁
lk->pid = myproc()->pid; //取锁进程的pid
release(&lk->lk);
}
void releasesleep(struct sleeplock *lk)
{
acquire(&lk->lk);
lk->locked = 0;
lk->pid = 0;
wakeup(lk); //唤醒
release(&lk->lk);
}获取休眠锁的过程是在自带的自旋锁的保护之下,要先获取该休眠锁的自旋锁,才能进行下一步操作,至于原因,加锁无外乎就是要保证临界区的排他性,若不加锁,由于并行并发,其中产生的竞争就有可能导致意想不到的错误。
当休眠锁已经被其他进程取走了,当前进程休眠,所以 while 看起来是循环,其实并没有像自旋锁那样循环等待,而是直接休眠。至于 sleep() 这个函数在本文中不详细解释,等到进程一文慢慢聊,在这儿简单说一说,sleep() 会将当前进程的状态设为休眠 SLEEPING,调度器不会调度状态为休眠的进程,所以这就相当于休眠了。相反,releasesleep(lk) 调用 wakeup(lk) 将休眠在 lk 上的进程状态设为 RUNNABLE,使其重新可以被调度。
本文简单讲述了 xv6 中两种锁的实现方法,关于锁,同步等等问题很深奥,远不是这么点内容可以说清楚的,本文只是做一个简单介绍。本来想将这篇文章放后面的,结果写 xv6 其他部分的时候基本到处都有用到锁,没办法,只有往前提一提。关于这两种锁的用法在后面其他文章的时候再详述。
最后就是揭晓封面来源,其实来自一部英剧,应该很多人看过吧,没看过肯定都听过,那就是神探夏洛克啦。夏洛克英文名 SHERLOCK,所以封面上四个框该填 SHER。出自于神探夏洛克第二季第一集,讲述夏洛克和艾琳的故事,艾琳喜欢上了夏洛克以此作密码,最后被夏洛克给破解了。整部剧都挺不错的,卷福主演,没看过的可以看看。
好啦,本文就到这里,有什么错误还请批评指正,也欢迎大家来同我讨论交流学习进步。