hashicorp raft 源码走读 1
上文讲到如何基于 hashicorp[1] raft 构建分布式 kv 存储。那么我们读一下源码,具体看如何实现 raft, 如何对应论文中提到的几个问题与优化。先看 leader election
整体架构
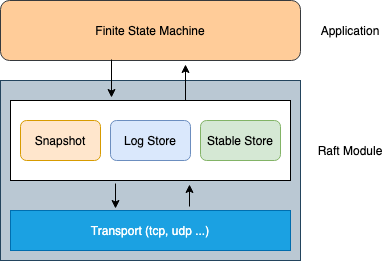
还是上文的图,除了 fsm 需要用户实现,其它都由 hashicorp 提供,完全开箱即用的产品。接下来我们带着论文描述的问题,来阅读一下源码实现
结构体
我其实很讨厌分析源码,上来就拿出结构体一顿乱讲,很烦 :( 好在不太多... 读过论文的都会熟悉
// Log entries are replicated to all members of the Raft cluster
// and form the heart of the replicated state machine.
type Log struct {
// Index holds the index of the log entry.
Index uint64
// Term holds the election term of the log entry.
Term uint64
// Type holds the type of the log entry.
Type LogType
// Data holds the log entry's type-specific data.
Data []byte
}Log 结构体代表日志里的一个 entry, Index 是索引号,Term 代表当前产生日志时的 leader 任期,Type 是日志类别,表示 Data 具体是做什么的,比如成员变更,或是用户产生的。
type RequestVoteRequest struct {
// Provide the term and our id
Term uint64
Candidate []byte
// Used to ensure safety
LastLogIndex uint64
LastLogTerm uint64
// Used to indicate to peers if this vote was triggered by a leadership
// transfer. It is required for leadership transfer to work, because servers
// wouldn't vote otherwise if they are aware of an existing leader.
LeadershipTransfer bool
}
// RequestVoteResponse is the response returned from a RequestVoteRequest.
type RequestVoteResponse struct {
// Newer term if leader is out of date.
Term uint64
// Peers is deprecated, but required by servers that only understand
// protocol version 0. This is not populated in protocol version 2
// and later.
Peers []byte
// Is the vote granted.
Granted bool
}一起看一下 RequestVote 请求的 req 和 resp
Term与Candidate是当前发起选举的任期和唯一标识LastLogIndex,LastLogTerm表示 candidate 拥有最新的日志 index 与 termLeadershipTransfer表示是否是强制转移 leader, 因为 follower 已有 leader 的时候是不会投票的,只有 leader 能发起强制转移- resp 如果同意,那么
Granted为 true. 另外如果节点的 term 比这个 candidate 大,也会同时返回最新的 term
通信 Transport
hashicorp 提供了 Transport 接口,只要符合的都可以传输数据,比如我们常用的 TCPTransport. 对外提供两个功能:
- 调用函数
AppendEntries发送日志,RequestVote发起选举,InstallSnapshot安装发送快照,还有其它函数 - 对外提供 RPC channel, 打通 raft 与底层 transport 交互通道

通过 NewTCPTransport 会创建一个基于 tcp 的传输层,如上图所示,数据使用 MsgPack 编解码,同时启动一个异步监听端口的 trans.listen 函数
// listen is used to handling incoming connections.
func (n *NetworkTransport) listen() {
const baseDelay = 5 * time.Millisecond
const maxDelay = 1 * time.Second
var loopDelay time.Duration
for {
// Accept incoming connections
conn, err := n.stream.Accept()
......
n.logger.Debug("accepted connection", "local-address", n.LocalAddr(), "remote-address", conn.RemoteAddr().String())
// Handle the connection in dedicated routine
go n.handleConn(n.getStreamContext(), conn)
}
}每当创建一个连接,都会新启动 goroutine handleConn 来处理请求
func (n *NetworkTransport) handleConn(connCtx context.Context, conn net.Conn) {
defer conn.Close()
r := bufio.NewReader(conn)
w := bufio.NewWriter(conn)
dec := codec.NewDecoder(r, &codec.MsgpackHandle{})
enc := codec.NewEncoder(w, &codec.MsgpackHandle{})
for {
select {
case <-connCtx.Done():
n.logger.Debug("stream layer is closed")
return
default:
}
if err := n.handleCommand(r, dec, enc); err != nil {
if err != io.EOF {
n.logger.Error("failed to decode incoming command", "error", err)
}
return
}
if err := w.Flush(); err != nil {
n.logger.Error("failed to flush response", "error", err)
return
}
}
}- 对 conn 网络连接封装编解码,MsgPack, 市面上其它的 raft 实现都使用 pb
handleCommand具体的处理单个请求,最后调用Flush把数据刷到网络发送出去
// handleCommand is used to decode and dispatch a single command.
func (n *NetworkTransport) handleCommand(r *bufio.Reader, dec *codec.Decoder, enc *codec.Encoder) error {
// Get the rpc type
rpcType, err := r.ReadByte()
if err != nil {
return err
}
// Create the RPC object
respCh := make(chan RPCResponse, 1)
rpc := RPC{
RespChan: respCh,
}
// Decode the command
isHeartbeat := false
switch rpcType {
case rpcAppendEntries:
var req AppendEntriesRequest
if err := dec.Decode(&req); err != nil {
return err
}
rpc.Command = &req
// Check if this is a heartbeat
if req.Term != 0 && req.Leader != nil &&
req.PrevLogEntry == 0 && req.PrevLogTerm == 0 &&
len(req.Entries) == 0 && req.LeaderCommitIndex == 0 {
isHeartbeat = true
}
case rpcRequestVote:
var req RequestVoteRequest
if err := dec.Decode(&req); err != nil {
return err
}
rpc.Command = &req
case rpcInstallSnapshot:
var req InstallSnapshotRequest
if err := dec.Decode(&req); err != nil {
return err
}
rpc.Command = &req
rpc.Reader = io.LimitReader(r, req.Size)
case rpcTimeoutNow:
var req TimeoutNowRequest
if err := dec.Decode(&req); err != nil {
return err
}
rpc.Command = &req
default:
return fmt.Errorf("unknown rpc type %d", rpcType)
}
// Check for heartbeat fast-path
if isHeartbeat {
n.heartbeatFnLock.Lock()
fn := n.heartbeatFn
n.heartbeatFnLock.Unlock()
if fn != nil {
fn(rpc)
goto RESP
}
}
// Dispatch the RPC
select {
case n.consumeCh <- rpc:
case <-n.shutdownCh:
return ErrTransportShutdown
}
// Wait for response
RESP:
select {
case resp := <-respCh:
// Send the error first
respErr := ""
if resp.Error != nil {
respErr = resp.Error.Error()
}
if err := enc.Encode(respErr); err != nil {
return err
}
// Send the response
if err := enc.Encode(resp.Response); err != nil {
return err
}
case <-n.shutdownCh:
return ErrTransportShutdown
}
return nil
}- 首先读一个 byte, 表示接下来的数据是什么类型 rpcType
- 根据不同类型解码成不同的结构体 rpcAppendEntries, rpcRequestVote, rpcInstallSnapshot, rpcTimeoutNow, 并封装成
RPC结构体 - 将
RPC请求结构体发送到n.consumeCh供上层 raft 模块调用 - 另外如果是心跳包的话,那么调用
heartbeatFn回调快速响应 - 阻塞读
respCh, 最后上面 raft 模块将返回数据写到RPC.respChchannel 里,handleCommand把数据Encode编码到 conn 刷新数据写到网络
至此,Transport 模块分析完,只需要记住暴露了 n.consumeCh 供 raft 模块读请求即可。至于如何写数据呢,稍后再讲。
选举 Election
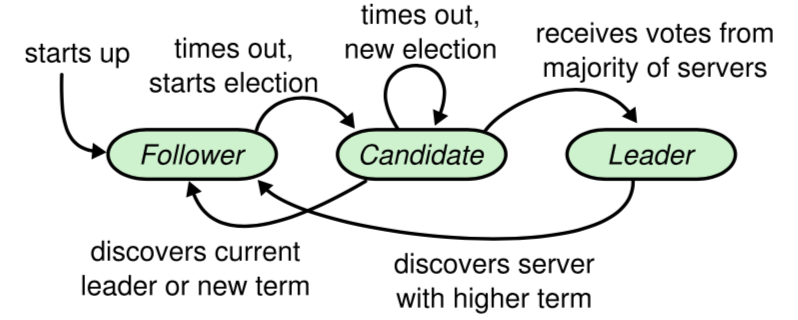
raft 有三种角色,leader, candidate, follower 上图是转换状态机,如果收不到 leader 的心跳,follower 就会变成 candidate 发起选举
1. candidate 发起选举
NewRaft 创建时会启动三个 goroutine: run, runFSM, runSnapshots 分别运行 raft, fsm apply 和 快照。我们此时只需关心 run 函数。
// run is a long running goroutine that runs the Raft FSM.
func (r *Raft) run() {
for {
// Check if we are doing a shutdown
select {
......
// Enter into a sub-FSM
switch r.getState() {
case Follower:
r.runFollower()
case Candidate:
r.runCandidate()
case Leader:
r.runLeader()
}
}
} run 函数其实是一个死循环,根据状态运行不同的角色函数,我们先来看一下 follower 如何触发选举
// runFollower runs the FSM for a follower.
func (r *Raft) runFollower() {
didWarn := false
r.logger.Info("entering follower state", "follower", r, "leader", r.Leader())
metrics.IncrCounter([]string{"raft", "state", "follower"}, 1)
heartbeatTimer := randomTimeout(r.conf.HeartbeatTimeout)
for r.getState() == Follower {
select {
......
case <-heartbeatTimer:
// Restart the heartbeat timer
heartbeatTimer = randomTimeout(r.conf.HeartbeatTimeout)
// Check if we have had a successful contact
lastContact := r.LastContact()
if time.Now().Sub(lastContact) < r.conf.HeartbeatTimeout {
continue
}
// Heartbeat failed! Transition to the candidate state
lastLeader := r.Leader()
r.setLeader("")
......
r.logger.Warn("heartbeat timeout reached, starting election", "last-leader", lastLeader)
metrics.IncrCounter([]string{"raft", "transition", "heartbeat_timeout"}, 1)
r.setState(Candidate)
return
}
}
}
}忽略其它 case 分支,当 heartbeatTimer 超时到期后,判断 lastContact 与 leader 上一次通信的时间,过长的话认为心跳失败。经过简单判断后,将状态设置成 Candidate,返回后 run 继续根据状态来运行 runCandidate 函数
// runCandidate runs the FSM for a candidate.
func (r *Raft) runCandidate() {
r.logger.Info("entering candidate state", "node", r, "term", r.getCurrentTerm()+1)
metrics.IncrCounter([]string{"raft", "state", "candidate"}, 1)
// Start vote for us, and set a timeout
voteCh := r.electSelf()
// Make sure the leadership transfer flag is reset after each run. Having this
// flag will set the field LeadershipTransfer in a RequestVoteRequst to true,
// which will make other servers vote even though they have a leader already.
// It is important to reset that flag, because this priviledge could be abused
// otherwise.
defer func() { r.candidateFromLeadershipTransfer = false }()
electionTimer := randomTimeout(r.conf.ElectionTimeout)
// Tally the votes, need a simple majority
grantedVotes := 0
votesNeeded := r.quorumSize()
r.logger.Debug("votes", "needed", votesNeeded)
for r.getState() == Candidate {
select {
case rpc := <-r.rpcCh:
r.processRPC(rpc)
case vote := <-voteCh:
// Check if the term is greater than ours, bail
if vote.Term > r.getCurrentTerm() {
r.logger.Debug("newer term discovered, fallback to follower")
r.setState(Follower)
r.setCurrentTerm(vote.Term)
return
}
// Check if the vote is granted
if vote.Granted {
grantedVotes++
r.logger.Debug("vote granted", "from", vote.voterID, "term", vote.Term, "tally", grantedVotes)
}
// Check if we've become the leader
if grantedVotes >= votesNeeded {
r.logger.Info("election won", "tally", grantedVotes)
r.setState(Leader)
r.setLeader(r.localAddr)
return
}
......
case <-electionTimer:
// Election failed! Restart the election. We simply return,
// which will kick us back into runCandidate
r.logger.Warn("Election timeout reached, restarting election")
return
case <-r.shutdownCh:
return
}
}
}- 首先
electSelf给自己投票,并且并行的将RequestVote发送给集群中所有其它节点 processRPC正常的接收 rpc 请求,如果是 leader 发来的,那么当前节点要退出Candidate状态,变为follower- 从
voteCh里收到投票结果,如果达到quorumSize那么成功当选 leader - 最后如果出现了 split vote 情况,那么
electionTimer选举超时,重新触发一次选举
func (r *Raft) electSelf() <-chan *voteResult {
// Create a response channel
respCh := make(chan *voteResult, len(r.configurations.latest.Servers))
// Increment the term
r.setCurrentTerm(r.getCurrentTerm() + 1)
// Construct the request
lastIdx, lastTerm := r.getLastEntry()
req := &RequestVoteRequest{
RPCHeader: r.getRPCHeader(),
Term: r.getCurrentTerm(),
Candidate: r.trans.EncodePeer(r.localID, r.localAddr),
LastLogIndex: lastIdx,
LastLogTerm: lastTerm,
LeadershipTransfer: r.candidateFromLeadershipTransfer,
}
// Construct a function to ask for a vote
askPeer := func(peer Server) {
r.goFunc(func() {
defer metrics.MeasureSince([]string{"raft", "candidate", "electSelf"}, time.Now())
resp := &voteResult{voterID: peer.ID}
err := r.trans.RequestVote(peer.ID, peer.Address, req, &resp.RequestVoteResponse)
if err != nil {
r.logger.Error("failed to make requestVote RPC",
"target", peer,
"error", err)
resp.Term = req.Term
resp.Granted = false
}
respCh <- resp
})
}
// For each peer, request a vote
for _, server := range r.configurations.latest.Servers {
if server.Suffrage == Voter {
if server.ID == r.localID {
// Persist a vote for ourselves
if err := r.persistVote(req.Term, req.Candidate); err != nil {
r.logger.Error("failed to persist vote", "error", err)
return nil
}
// Include our own vote
respCh <- &voteResult{
RequestVoteResponse: RequestVoteResponse{
RPCHeader: r.getRPCHeader(),
Term: req.Term,
Granted: true,
},
voterID: r.localID,
}
} else {
askPeer(server)
}
}
}
return respCh
}我们来看一下 candidate 如何发起选举请求
- 构建
RequestVoteRequest请求,term ++, 填充 LastLogIndex, LastLogTerm - askPeer 通过 transport 广播
RequestVote给其它节点
2. 其它节点接收 vote
其它节点通过 processRPC 来处理 rpc 请求,对应于 requestVote 函数
// requestVote is invoked when we get an request vote RPC call.
func (r *Raft) requestVote(rpc RPC, req *RequestVoteRequest) {
defer metrics.MeasureSince([]string{"raft", "rpc", "requestVote"}, time.Now())
r.observe(*req)
// Setup a response
resp := &RequestVoteResponse{
RPCHeader: r.getRPCHeader(),
Term: r.getCurrentTerm(),
Granted: false,
}
......
// Check if we have an existing leader [who's not the candidate] and also
// check the LeadershipTransfer flag is set. Usually votes are rejected if
// there is a known leader. But if the leader initiated a leadership transfer,
// vote!
candidate := r.trans.DecodePeer(req.Candidate)
if leader := r.Leader(); leader != "" && leader != candidate && !req.LeadershipTransfer {
r.logger.Warn("rejecting vote request since we have a leader",
"from", candidate,
"leader", leader)
return
}
// Ignore an older term
if req.Term < r.getCurrentTerm() {
return
}
// Increase the term if we see a newer one
if req.Term > r.getCurrentTerm() {
// Ensure transition to follower
r.logger.Debug("lost leadership because received a requestVote with a newer term")
r.setState(Follower)
r.setCurrentTerm(req.Term)
resp.Term = req.Term
}
// Check if we have voted yet
lastVoteTerm, err := r.stable.GetUint64(keyLastVoteTerm)
if err != nil && err.Error() != "not found" {
r.logger.Error("failed to get last vote term", "error", err)
return
}
lastVoteCandBytes, err := r.stable.Get(keyLastVoteCand)
if err != nil && err.Error() != "not found" {
r.logger.Error("failed to get last vote candidate", "error", err)
return
}
// Check if we've voted in this election before
if lastVoteTerm == req.Term && lastVoteCandBytes != nil {
r.logger.Info("duplicate requestVote for same term", "term", req.Term)
if bytes.Compare(lastVoteCandBytes, req.Candidate) == 0 {
r.logger.Warn("duplicate requestVote from", "candidate", candidate)
resp.Granted = true
}
return
}
// Reject if their term is older
lastIdx, lastTerm := r.getLastEntry()
if lastTerm > req.LastLogTerm {
r.logger.Warn("rejecting vote request since our last term is greater",
"candidate", candidate,
"last-term", lastTerm,
"last-candidate-term", req.LastLogTerm)
return
}
if lastTerm == req.LastLogTerm && lastIdx > req.LastLogIndex {
r.logger.Warn("rejecting vote request since our last index is greater",
"candidate", candidate,
"last-index", lastIdx,
"last-candidate-index", req.LastLogIndex)
return
}
// Persist a vote for safety
if err := r.persistVote(req.Term, req.Candidate); err != nil {
r.logger.Error("failed to persist vote", "error", err)
return
}
resp.Granted = true
r.setLastContact()
return
}- 如果己知有 leader 节点了,并且未设置 LeadershipTransfer 那么拒绝
- 查看
lastVoteTerm,lastVoteCandBytes检查本次 term 内是否己经投完票了,raft paper 要求一个 term 内对一个节点只能投票一次 - 如果 term 大于请求节点的 LastLogTerm, 拒绝
- 如果 term 相等,lastIdx 大于请求节点的 LastLogIndex, 拒绝
persistVote将投票结果持久化,最后 Granted 设为 true, 设置 lastContact 后返回
小结
这次分享就这些,以后面还会分享更多 etcd 与 raft 的内容。
参考资料
[1]hashicorp raft: https://github.com/hashicorp/raft,