如何使用 raft 实现分布式 kv 存储
开源实现中,hashicorp[1] 实现的 raft 最好理解,对外接口简洁,更接近论文。本次分享我们来看一下,如何使用 hashicorp 来构建分布式 kv 系统。源码来自 raftdb[2] 和 hraftdb[3]
整体架构
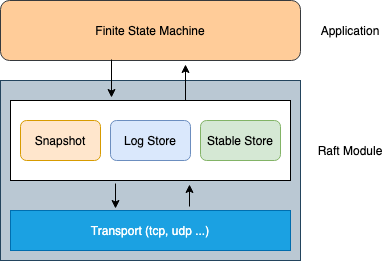
系统整体分为两层,fsm 状态机需要用户自己编写,满足 FSM 接口即可,一般为了性能考虑最好实现 BatchingFSM,当 raft module 模块完成与 follower 交互确认请求被 majority 大多数接收后,执行 fsm.Apply 将请求应用到状态机。
// FSM provides an interface that can be implemented by
// clients to make use of the replicated log.
type FSM interface {
Apply(*Log) interface{}
Snapshot() (FSMSnapshot, error)
Restore(io.ReadCloser) error
}
type BatchingFSM interface {
ApplyBatch([]*Log) []interface{}
FSM
}底层 raft module 模块均为 hashicorp 库提供,节点间通信使用 TCPTransport 实现了 Transport 接口。Log Store 与 Stable Store 使用 hashicorp 定制的 raft-boltdb[4] 引擎。Snapshot 使用库提供的 FileSnapshot 文件快照。
FSM 实现
真正的分布式 kv 系统非常复杂,raftdb[5] 的状态机是一个普通的 map, 最精简的内存数据库
// Store is a simple key-value store, where all changes are made via Raft consensus.
type Store struct {
RaftDir string
RaftBind string
mu sync.Mutex
m map[string]string // The key-value store for the system.
raft *raft.Raft // The consensus mechanism
logger *log.Logger
}
type fsm StoreStore 是 fsm 状态机的实现,m map[string]string 保存真正的 kv 数据。
// Apply applies a Raft log entry to the key-value store.
func (f *fsm) Apply(l *raft.Log) interface{} {
var c command
if err := json.Unmarshal(l.Data, &c); err != nil {
panic(fmt.Sprintf("failed to unmarshal command: %s", err.Error()))
}
switch c.Op {
case "set":
return f.applySet(c.Key, c.Value)
case "delete":
return f.applyDelete(c.Key)
default:
panic(fmt.Sprintf("unrecognized command op: %s", c.Op))
}
}
func (f *fsm) applySet(key, value string) interface{} {
f.mu.Lock()
defer f.mu.Unlock()
f.m[key] = value
return nil
}
func (f *fsm) applyDelete(key string) interface{} {
f.mu.Lock()
defer f.mu.Unlock()
delete(f.m, key)
return nil
}Apply 实现 fsm.Apply 接口函数,简单的安全写入删除 map
// Snapshot returns a snapshot of the key-value store.
func (f *fsm) Snapshot() (raft.FSMSnapshot, error) {
f.mu.Lock()
defer f.mu.Unlock()
// Clone the map.
o := make(map[string]string)
for k, v := range f.m {
o[k] = v
}
return &fsmSnapshot{store: o}, nil
}
// Restore stores the key-value store to a previous state.
func (f *fsm) Restore(rc io.ReadCloser) error {
o := make(map[string]string)
if err := json.NewDecoder(rc).Decode(&o); err != nil {
return err
}
// Set the state from the snapshot, no lock required according to
// Hashicorp docs.
f.m = o
return nil
}Snapshot 用于生成快照 snapshot, 简单的 clone map, 在真实分布式产品中一般都要结合底层存储引擎来实现,比如 rocksdb. Restore 用于回放快照。
启动服务
一般 raft 服务都要有两个端口,raftaddr 用于共识模块通信,httpaddr 用于用户请求与节点上下线,略去部分代码,只看 store.Open 实现
// Open opens the store. If enableSingle is set, and there are no existing peers,
// then this node becomes the first node, and therefore leader, of the cluster.
// localID should be the server identifier for this node.
func (s *Store) Open(enableSingle bool, localID string) error {
......
// Setup Raft communication.
addr, err := net.ResolveTCPAddr("tcp", s.RaftBind)
transport, err := raft.NewTCPTransport(s.RaftBind, addr, 3, 10*time.Second, os.Stderr)
// Create the snapshot store. This allows the Raft to truncate the log.
snapshots, err := raft.NewFileSnapshotStore(s.RaftDir, retainSnapshotCount, os.Stderr)
if err != nil {
return fmt.Errorf("file snapshot store: %s", err)
}
// Create the log store and stable store.
var logStore raft.LogStore
var stableStore raft.StableStore
boltDB, err := raftboltdb.NewBoltStore(filepath.Join(s.RaftDir, "raft.db"))
logStore = boltDB
stableStore = boltDB
// Instantiate the Raft systems.
ra, err := raft.NewRaft(config, (*fsm)(s), logStore, stableStore, snapshots, transport)
if err != nil {
return fmt.Errorf("new raft: %s", err)
}
s.raft = ra
if enableSingle && newNode {
s.logger.Printf("bootstrap needed")
configuration := raft.Configuration{
Servers: []raft.Server{
{
ID: config.LocalID,
Address: transport.LocalAddr(),
},
},
}
ra.BootstrapCluster(configuration)
} else {
s.logger.Printf("no bootstrap needed")
}
return nil
}- 基于给定的
RaftBind来创建NewTCPTransport, 也可以是其它的协议,能通信就行,理论上 udp 不丢数据的情况也可以 NewBoltStore创建 boltDB 存储,用于logStore存储日志和stableStore保存状态- 调用
NewRaft创建 raft 服务,第一次启动后默认为follower状态 - 如果是新建的集群,需要
BootstrapCluster初始化 raft 集群,join 方式加入的不需要
用户请求
所有 kv 操作都对应着 get/delete/post, 我们只看 Set 操作的实现。
// Set sets the value for the given key.
func (s *Store) Set(key, value string) error {
if s.raft.State() != raft.Leader {
return ErrNotLeader
}
c := &command{
Op: "set",
Key: key,
Value: value,
}
b, err := json.Marshal(c)
if err != nil {
return err
}
f := s.raft.Apply(b, raftTimeout)
return f.Error()
}将本次操作封装成 command, json 序列化后调用 raft.Apply 去执行本次操作,返回值是 future 类型,f.Error() 会阻塞在这里,直到报错或是共识模块完成将数据写入 majority 节点,并调用 fsm.Apply 应用到状态机后返回。
其它 snapshot 等等暂时不看了,感兴趣的自行看源代码
测试
1. 启动并读写
关于如何启动三个节点测试,请参考 https://github.com/hanj4096/raftdb 文档,很简单。
$raftdb -id node01 -haddr raft-cluster-host01:8091 -raddr raft-cluster-host01:8089 ~/.raftdb
启动第一个节点时无需指定 join, 因为他是集群中第一个启动的
$raftdb -id node02 -haddr raft-cluster-host02:8091 -raddr raft-cluster-host02:8089 -join raft-cluster-host01:8091 ~/.raftdb
$raftdb -id node03 -haddr raft-cluster-host03:8091 -raddr raft-cluster-host03:8089 -join raft-cluster-host01:8091 ~/.raftdb然后启动另外两个节点时,需要指定 join raft-cluster-host01:8091
host01# curl -XPOST http://raft-cluster-host01:8091/key -d '{"foo": "bar"}' -L
host01# curl http://raft-cluster-host01:8091/key/foo -L
{"foo":"bar"}写入数据 foo:bar 后,可以从 raft-cluster-host01 节点上读出数据,没有问题
host01# curl -i http://raft-cluster-host02:8091/key/foo -L
HTTP/1.1 307 Temporary Redirect
Content-Type: text/html; charset=utf-8
Location: http://172.24.213.39:8091/key/foo
Date: Mon, 03 Aug 2020 09:58:38 GMT
Content-Length: 69
HTTP/1.1 200 OK
Date: Mon, 03 Aug 2020 09:58:38 GMT
Content-Length: 13
Content-Type: text/plain; charset=utf-8
{"foo":"bar"}再试一下从其它节点读,发现做了 307 跳转,也就是只能从 leader 节点读写数据。
2. failover 切换
杀掉 raft-cluster-host01 节点,观察日志,发现 leader 己经转移
host02# tail -f nohup.out
2020-08-03T18:02:07.598+0800 [WARN] raft: rejecting vote request since we have a leader: from=172.24.213.44:8089 leader=172.24.213.39:8089
2020-08-03T18:02:07.730+0800 [WARN] raft: heartbeat timeout reached, starting election: last-leader=172.24.213.39:8089
2020-08-03T18:02:07.730+0800 [INFO] raft: entering candidate state: node="Node at 172.24.213.40:8089 [Candidate]" term=439
2020-08-03T18:02:07.733+0800 [ERROR] raft: failed to make requestVote RPC: target="{Voter node01 172.24.213.39:8089}" error=EOF
2020-08-03T18:02:07.736+0800 [DEBUG] raft: votes: needed=2
2020-08-03T18:02:07.736+0800 [DEBUG] raft: vote granted: from=node02 term=439 tally=1
2020-08-03T18:02:09.277+0800 [DEBUG] raft: lost leadership because received a requestVote with a newer term
2020-08-03T18:02:09.282+0800 [INFO] raft: entering follower state: follower="Node at 172.24.213.40:8089 [Follower]" leader=host03# tail -f nohup.out
2020-08-03T18:02:07.596+0800 [WARN] raft: heartbeat timeout reached, starting election: last-leader=172.24.213.39:8089
2020-08-03T18:02:07.596+0800 [INFO] raft: entering candidate state: node="Node at 172.24.213.44:8089 [Candidate]" term=439
2020-08-03T18:02:07.598+0800 [ERROR] raft: failed to make requestVote RPC: target="{Voter node01 172.24.213.39:8089}" error="dial tcp 172.24.213.39:8089: connect: connection refused"
2020-08-03T18:02:07.600+0800 [DEBUG] raft: votes: needed=2
2020-08-03T18:02:07.600+0800 [DEBUG] raft: vote granted: from=node03 term=439 tally=1
2020-08-03T18:02:07.736+0800 [INFO] raft: duplicate requestVote for same term: term=439
2020-08-03T18:02:09.275+0800 [WARN] raft: Election timeout reached, restarting election
2020-08-03T18:02:09.275+0800 [INFO] raft: entering candidate state: node="Node at 172.24.213.44:8089 [Candidate]" term=440
2020-08-03T18:02:09.277+0800 [ERROR] raft: failed to make requestVote RPC: target="{Voter node01 172.24.213.39:8089}" error="dial tcp 172.24.213.39:8089: connect: connection refused"
2020-08-03T18:02:09.279+0800 [DEBUG] raft: votes: needed=2
2020-08-03T18:02:09.279+0800 [DEBUG] raft: vote granted: from=node03 term=440 tally=1
2020-08-03T18:02:09.282+0800 [DEBUG] raft: vote granted: from=node02 term=440 tally=2
2020-08-03T18:02:09.282+0800 [INFO] raft: election won: tally=2
2020-08-03T18:02:09.282+0800 [INFO] raft: entering leader state: leader="Node at 172.24.213.44:8089 [Leader]"可以看到超时之后,raft-cluster-host03 发起的选举收到了过半选票,当选为新的 leader
host03# curl -i http://raft-cluster-host03:8091/key/foo -L
HTTP/1.1 200 OK
Date: Mon, 03 Aug 2020 10:04:52 GMT
Content-Length: 13
Content-Type: text/plain; charset=utf-8
{"foo":"bar"}经过测试,数据也可以从新的 leader 读取
3. 网络分区
chaos 测试有很多,包括网络分区,丢包等等,我们先用 iptables 制造网络分区,节点 raft-cluster-host01 只能收到 leader 节点 raft-cluster-host03 的数据,而无法发送。然后再将 iptables 去掉,再次查看 raft-cluster-host03 发现 leader 己经变成了 follower
host03# tail -f nohup.out
2020-08-03T18:22:19.770+0800 [ERROR] raft: peer has newer term, stopping replication: peer="{Voter node01 172.24.213.39:8089}"
2020-08-03T18:22:19.770+0800 [INFO] raft: entering follower state: follower="Node at 172.24.213.44:8089 [Follower]" leader=
2020-08-03T18:22:19.770+0800 [INFO] raft: aborting pipeline replication: peer="{Voter node02 172.24.213.40:8089}"
2020-08-03T18:22:19.789+0800 [DEBUG] raft: lost leadership because received a requestVote with a newer term
2020-08-03T18:22:21.507+0800 [DEBUG] raft: lost leadership because received a requestVote with a newer termhost01# tail -f nohup.out
2020-08-03T18:22:21.503+0800 [WARN] raft: Election timeout reached, restarting election
2020-08-03T18:22:21.503+0800 [INFO] raft: entering candidate state: node="Node at 172.24.213.39:8089 [Candidate]" term=509
2020-08-03T18:22:21.507+0800 [DEBUG] raft: votes: needed=2
2020-08-03T18:22:21.507+0800 [DEBUG] raft: vote granted: from=node01 term=509 tally=1
2020-08-03T18:22:21.510+0800 [DEBUG] raft: vote granted: from=node03 term=509 tally=2
2020-08-03T18:22:21.510+0800 [INFO] raft: election won: tally=2
2020-08-03T18:22:21.510+0800 [INFO] raft: entering leader state: leader="Node at 172.24.213.39:8089 [Leader]"
2020-08-03T18:22:21.510+0800 [INFO] raft: added peer, starting replication: peer=node02
2020-08-03T18:22:21.510+0800 [INFO] raft: added peer, starting replication: peer=node03
2020-08-03T18:22:21.511+0800 [INFO] raft: pipelining replication: peer="{Voter node03 172.24.213.44:8089}"
2020-08-03T18:22:21.512+0800 [INFO] raft: pipelining replication: peer="{Voter node02 172.24.213.40:8089}"查看日志可以看到,raft-cluster-host01 节点上线后,由于 term 非常大,并且 iptables 网络分区期间,leader 并没有新数据生成,所以抢主成功。
当网络分区再上线后,candidate term 远大于 leader, 就会发现这种现象。由于 raft 是 CP 系统,没有 leader 就无法提供访问,所以很多库都针对这个问题做了优化,如何优化呢?以后再讲
小结
这次分享就这些,以后面还会分享更多 etcd 与 raft 的内容。
参考资料
[1]hashicorp raft: https://github.com/hashicorp/raft,
[2]raftdb: https://github.com/hanj4096/raftdb,
[3]hraftdb: https://github.com/otoolep/hraftd,
[4]raft-boltdb: github.com/hashicorp/raft-boltdb,
[5]raftdb: https://github.com/hanj4096/raftdb,