初探 raft
最近业务开发用到了 etcd, 在编写 runbook 时顺便研究了一下 raft 论文。常见的共识算法 (consensus algorithm) 有 raft[1] 和 paxos[2] 两种,paxos 算法难以理解,工程难以实现,所以在 raft 论文放出后,大部分开源服务都使用 raft, 包括知名的 etcd[3], tidb[4], consul[5] 等等。
一般公司使用 raft, 都会集成 etcd 或 hashicorp 库,不会直接造轮子(分布式轮子坑一大堆,就怕挖完坑,自己跳不出来)。etcd raft 灵活,很多都要用户自己实现,而 hashicorp 更简洁,对外暴露接口较少,开箱即用,如果业务开发要集成 raft, 推荐使用 hashicorp. 另外国人开发的 dragonboat raft[6] 库号称性能很强,支持 multi-raft, 后面的文章也会讲讲。
共识算法
A consensus algorithm is a process in computer science used to achieve agreement on a single data value among distributed processes or systems. Consensus algorithms are designed to achieve reliability in a network involving multiple unreliable nodes.Consensus algorithms allow a collection of machines to work as a coherent group that can survive the failures of some of its members.
可以看到 consensus algorithm 有如下特点
- 目标 解决分布式系统中,对于单个数据值如何达成一致的问题
- 前提 这些系统构建在普通的商用机器上,这些机器都是不可靠的,随时有挂掉的风险
- 容错 必须接受部分成员离线或是死机,比如 raft 容忍最多 (n-1)/2 挂掉
初探 Raft
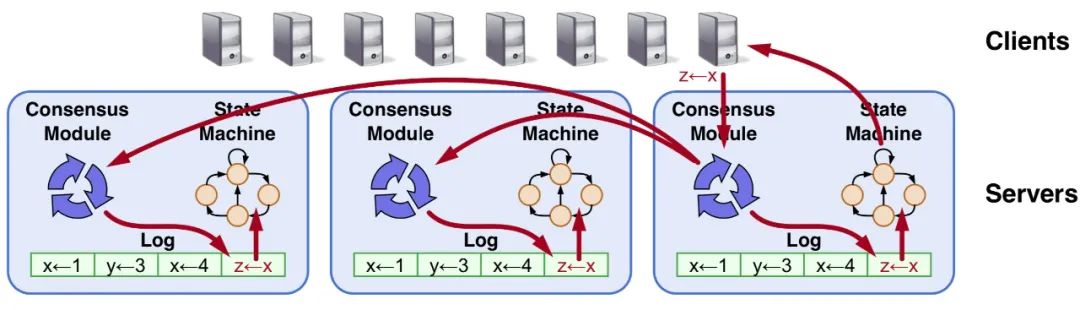
典型的写入请求流程: client 发送 request 到 leader 节点,共识模块将有户请求写入本地 Log 中,然后广播 entry 到所有 follower 节点,当 quorum 过半数确认收到数据后,leader commit 这条 entry,然后 apply 到本地状态机(fsm), 最后返回给 client. 那么 follower 什么时候 apply 这么记录呢?leader 下次发送请求或 heartbeat 心跳时,会携带 leader commmitted index, follower 就可以 commit 这个 index 之前的所有 entry。
如果懂 MySQL 的,可以做这样的类比,Consensus Module 类似半同步 semi-replication, 要确认 follower 接收到 binlog 才返回。Log 类似 redo log, 保存所有逻辑修改,只允许顺序 apply, 不能乱序。State Machine 状态机类似 innodb, 所谓的将 entry apply 到 fsm 类似于 MySQL 崩溃恢复时的前滚,用 redo log 恢复 b+tree 中不一致的数据。
图中的 fsm 是一个简单的 hash 表,client 请求前有两个元素 y=3 x=4 (这里 x=1 被覆盖了), 请求结束后增加一个 z=4. 关于 raft 如何工作有动画演示网站 https://raft.github.io 可以参考,非常直观。
Raft 特点
相对于其它共识算法,Raft 有很多特点,使得更加易于理解与工程实现
- Strong leader 所有的数据流向,只能从 leader 传播到 follower, 所以 raft 实现的服务是一个
CP系统,在 leader 挂掉的时间,不能提供服务 - Leader election 随机的超时时间,follower 收不到 leader 的心跳后,不会同一时间发起选举请求,避免选票被瓜分 split vote
- Membership changes
joint consensus用于解决成员变更问题,论文这么写的,但是具体工程实现有不同的方式
为了实现共识,Raft 将工作划分了几个任务:Leader election, Log replication, Safety, Membership changes 和 Log Compaction
1.Leader election
Raft 里有任期 term 的概念,当 Leader 角色不变时,term 维持不变,直到 Leader 挂掉或是有 Candidate 触发选举. term 单调递增
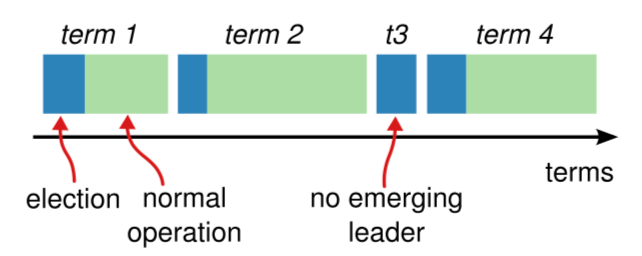
从图中也可以看到,一个任期 term 的时间被划分两部分: election 和 normal operation, 但是也有例外,比如 t3 时刻只有 election 时间,可能此时发生了 split vote 现象,选票被瓜分了。
集群中节点有三种角色:Follower, Candidate, Leader.
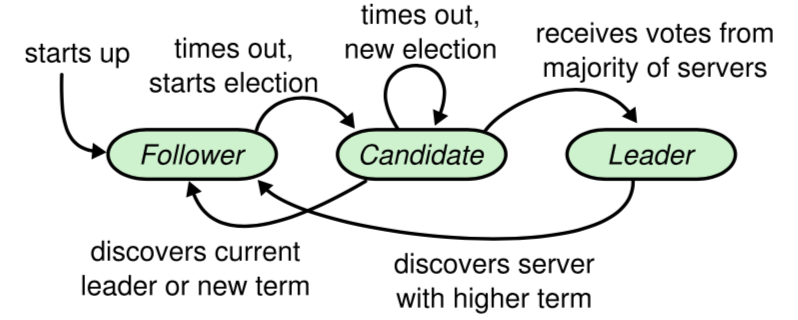
初始时节点状态为 Follower, 在一定时间没收到任何 AppendEntries 或是 Heartbeat 后,变成 Candidate 同时投自己一票,并且 term+1, 并行发送 RequestVote 到其它节点。之后会有三种情况:
- 同一任期 term, 一个节点只能做一次投票,按照先来先得的原则。收到过半数投票后成为新的
Leader, 然发送心跳给所有Follower - 己有其它节点成为
Leader,或是 term 低于其它节点,那么当前节点都会被拒绝,并退回Follower - 选举超时,继续将 term+1, 再发起一轮选举。timeout 是一个随机的时间,避免 split vote, 让选举过程能快速收敛
2.Log replication
Log 里每一个 entry 由 index, term, data 组成,index 单调递增,term 表示当前 leader 任期号,data 就是用户的请求。当 Leader 接收用户请求时,将 Log 并行发送到所有 Follower 节点,过半数 majority 节点 commit 后,Leader 就可以 apply 这个 log
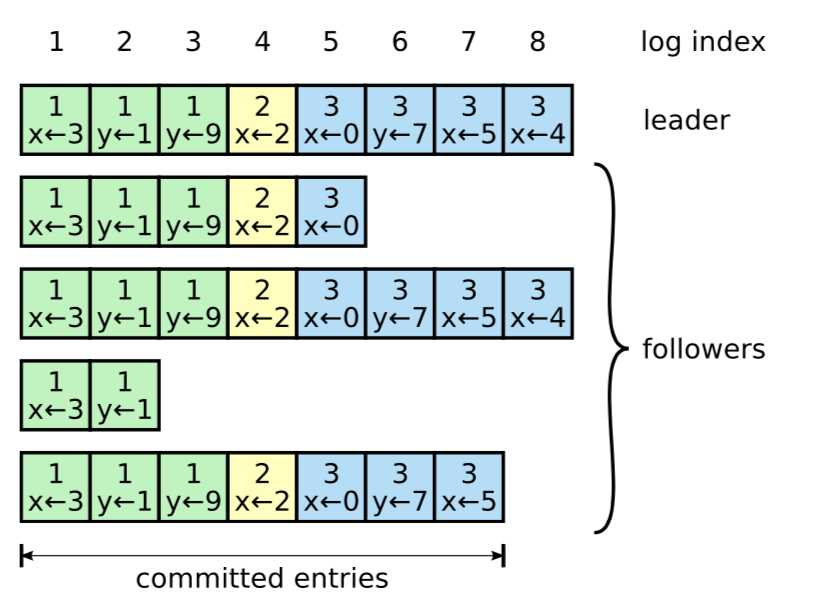
上图是一个 log 的快照,绿色 entry 代表 term 1 时期产生的日志,黄色代表 term 2 产生的日志,蓝色代表 term 3 也就是当前任期的日志, x<-4 这些是 data 携带的用户请求。由于 3 个节点都有 log 7 的数据,所以 7 就是 committed index, log 8 由于只存在于两个节点,没达到 majority 3 的要求,所以属于 uncommitted index. 所有己经应用到 fsm 的点叫做 applied index, 图中没有画出,有不等式 applied index <= committed index 永远成立。
为了维护不同节点间 Log 的一致性,raft 有两个原则,叫做 Log Matching Property:
- 如果不同节点上的 logs 的某个 entry, 拥有相同的 index, term, 那么他们拥有相同的用户请求 data
- 如果不同节点上的 logs 的某个 entry, 拥有相同的 index, term, 那么这个 index 前的所有 entry 也都相同
这两点是由一致性检查来保证的,对于第一条永远成立,raft 规定只有 leader 能写请求,并且不允许 leader 节点删除修改 logs. 第二条其实是一个归纳法,raft 在每次广播请求 AppendEntries 时,都会携带每个 follower 的下一个待发送的 nextIndex, 如果与 follower 的不相同则意味着数据不一致。
如果发生了数据不致,那么 leader 就要将 nextIndex-1,再重新发送以前的 log, 进行探测,如果不一致的数据较多,那肯定相当慢。所以 follower 需要返回时携带 lastlog 信息,方便加速数据重传与同步,每个库的工程实现可能不同。
3.Safety
关于如何保证 Safety 有好多子问题
3.1 Election restriction
Raft 要求选举时除了 term 高于 follower 以外,还要求己提交数据 committed index 也是最新的 up-to-date. 所以 Candidate 发送 RequestVote 调用时,会携带自身的 lastlog 信息,这里分两种情况:
- 如果 last commited log 的 term 相同,但是 index 落后于 follower 的话会被拒绝。
- 如果 last commited log 的 term 不相同,term 任期号大的最新
3.2 Committing entries from previous terms
从前面可知,如果 leader 写入的 log 被大多数 majority 节点保存了,那么就可以提交了。但是如果在提交 commit 前 leader 挂掉了,新的 leader 就会重新尝试同步数据,但是新的 leader 不能因为大多数节点保存了 old term 的 log, 就认为这条 log 己经提交了。
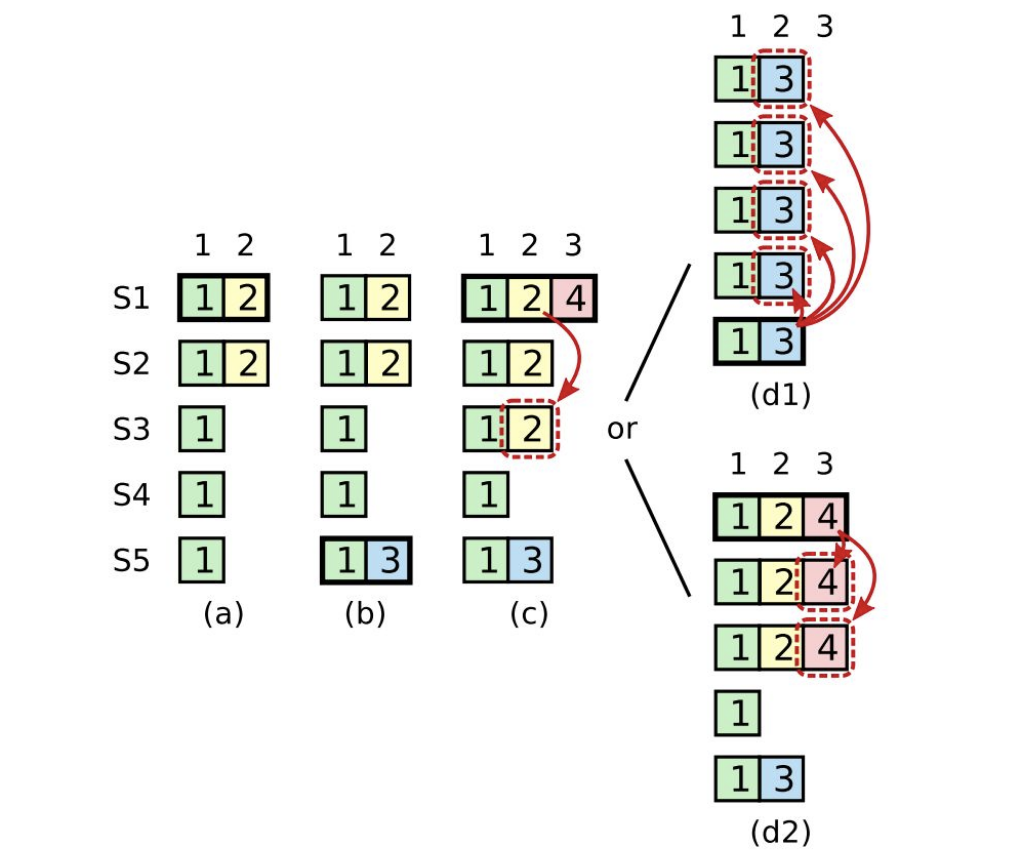
上图就是一个例子(原论文 5.4.2 子问题),我们分解来看,为什么不能 commit old term entry:
- 在 (a) 中 S1 是 leader, 写了一条 (term, index) (2,2) 的数据,只同步到了 S2 上
- 在 (b) 时刻 S1 挂了,此时 S5 当选(选票来自 S3,S4,S5, 原 S1 日志没提交也没过半数保存), 然后 S5 写了一条 (term, index) (3,2) 的数据
- 在 (c) 时刻 S5 挂了,S1 重新上线,当选为 leader, 继续将 (term, index) (2,2) 数据复制到大多数机器上,但是没有提交(先忽略 (term, index) (4,3))
- 在 (d1) 时刻,S1 挂了,S5 当选为 leader(选票来自 S2,S3,S4 index 2 没有提交) 那么会把 S5 上 (term, index) (3,2) 的数据继续复制到所有节点,这相当于抹掉了原来己经复制到多数的 (term, index) (2,2)
- 但是如果 S1 在 (c) 时刻挂掉之前,用自己的任期 term 4 写了一条记录到 majority 机器上,如 (d2) 所示,那么此时原来 (term, index) (2,2) 的数据就一定确认提交了。如果此时 S1 再挂掉,那么 S5 一定不会当选 leader
raft 不允许提交 old term 的数据,即使这些数据己经存储在大多数节点上,raft 只允许提交当前 term 的数据。为了解决上面提到的问题,新当选的 leader 必须立刻发送一个 no-op 的空 entry 给所有 follower, 根据 Log Matching Property 原则,如果本条 no-op 提交了,那面前面所有 old term 任期的数据也是一致的。
3.3 Timing and availability
分布式系统时序是一个很大问题,在 raft 中关于超时时间设置要合理,下面是论文中的一个不等式
broadcastTime ≪ electionTimeout ≪ MTBF
其中 broadcastTime 是不同节点间 RPC 调用往返一次的时间,一定要远小于 electionTimeout 选举超时时间,这个显而易。MTBF 节点平均故障时间,这个一般不用考虑,肯定是远大于其它时间。一般内网 RPC roundtrip 都是 20ms 以内,我们线上的 electionTimeout 设置为 1.5s, 因为涉及了 aws 多 AZ 部署。
4.Membership changes
成员变更非常关键,我们的服务不可能一直很稳定,需要扩容缩容,或是滚动升级。所以不能直接从一种配置切换到另外一种配置。
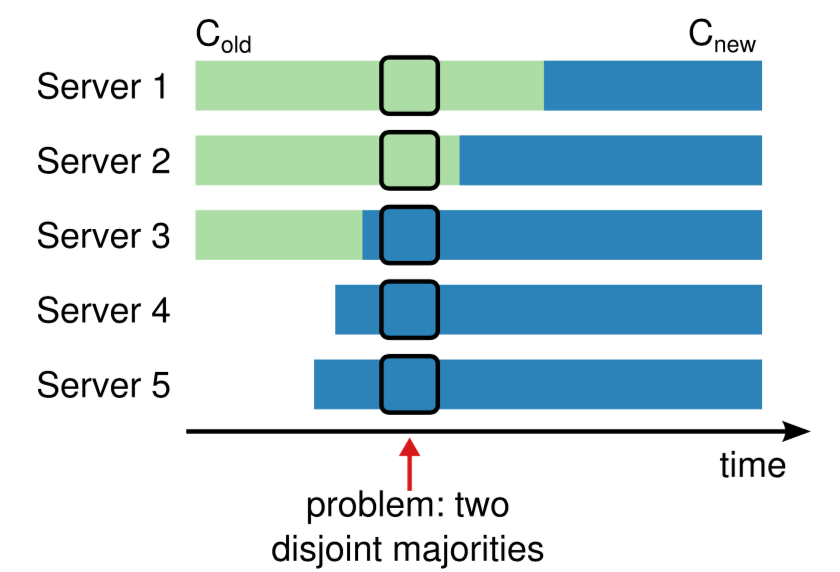
论文里提到了 joint consensus 算法,如上图如何从 C(old) 切到 C(new), 避免多个 leader 产生,太复杂了, hashicorp 就没有实现这个。
从运维实践角度,每次只允许修改一个 member, 才是最安全的,比如我们线上 runbook 就不允许修改多个。这块感兴趣的自行去看论文吧。
5.Log Compaction

日志需要与 fsm 压缩生成 snapshot, 如果很久才做一次的话,历史 logs 会占用很多磁盘空间,并且新同步的节点 replay 历史数据会很慢。
但也不能过于频繁,因为生成 snapshot 会对当前系统产生压力,尤其数据量比较大的时候,魔鬼都在细节当中,工程实践有很多优化点,以后再细讲这一块。
小结
这次分享就这些,推荐大家结合 hashicorp 的源码实现来学习 raft 论文。本次只大致浏览下论文,接下来会分享更多 raft 细节与实现的优化,如何实现 linearizability read, 如何优化 pipeline, 以及 pingcap 是如何优化 multi-group etcd. 理论与实现之间隔着一条鸿沟。
参考资料
[1]raft 英文论文: https://raft.github.io/raft.pdf,
[2]paxos made simple: https://lamport.azurewebsites.net/pubs/paxos-simple.pdf,
[3]etcd: https://github.com/etcd-io/etcd,
[4]tidb: https://github.com/pingcap/tidb,
[5]hashicorp consul: https://www.consul.io/,
[6]dragonboat raft: https://github.com/lni/dragonboat,