hashicorp raft 源码走读 2
上文讲到 hashicorp[1] raft 如何做 leader 选举,transport 层如何工作的,本次看下如何做日志复制 log replication
数据结构
来看一下日志同步的函数 AppendEntriesRequest 和 AppendEntriesResponse
type AppendEntriesRequest struct {
// Provide the current term and leader
Term uint64
Leader []byte
// Provide the previous entries for integrity checking
PrevLogEntry uint64
PrevLogTerm uint64
// New entries to commit
Entries []*Log
// Commit index on the leader
LeaderCommitIndex uint64
}Term当前 leader 的任期,Leader是 leader idPrevLogEntry和PrevLogTerm是 leader 知道的该 follower 上一次得到日志的索引和任期号,用于日志一致性检测Entries本次 rpc 调用发送的所有日志条目,因为允许 batch 发送,所以是数组LeaderCommitIndex当前 leader commit 的日志序号,follower 得到后可以 apply 这之前的所有日志
type AppendEntriesResponse struct {
// Newer term if leader is out of date
Term uint64
// Last Log is a hint to help accelerate rebuilding slow nodes
LastLog uint64
// We may not succeed if we have a conflicting entry
Success bool
// There are scenarios where this request didn't succeed
// but there's no need to wait/back-off the next attempt.
NoRetryBackoff bool
}Term当前 follower 知道的任期号,如果比 leader 的大,说明 leader 过期了,会重新触发选举- 如果日志不匹配,需要 leader 重传缺失的 log,
LastLog表示 follower 拥有的最新 log, 加速 leader 重传,否则每次都是 nextIndex-1 就太低效了 Success函数调用是否成功,NoRetryBackoff表示是否需要重传
日志复制
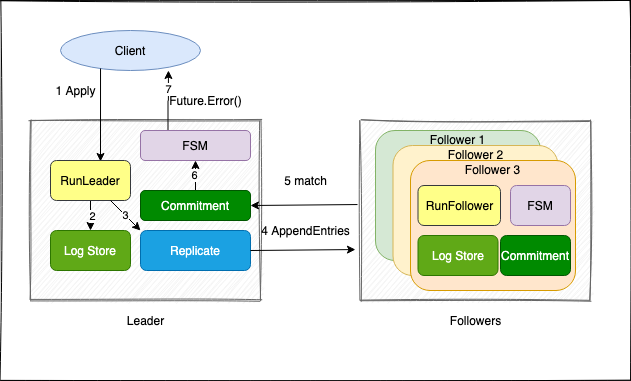
1. 用户写入
我们先用 application 视角看如何写入共识模块
func (r *Raft) Apply(cmd []byte, timeout time.Duration) ApplyFuture {
return r.ApplyLog(Log{Data: cmd}, timeout)
}用户直接调用 Apply 函数,将 cmd 封装成 Log 调用 ApplyLog 写入,并且提供超时时间 timeout
// ApplyLog performs Apply but takes in a Log directly. The only values
// currently taken from the submitted Log are Data and Extensions.
func (r *Raft) ApplyLog(log Log, timeout time.Duration) ApplyFuture {
metrics.IncrCounter([]string{"raft", "apply"}, 1)
var timer <-chan time.Time
if timeout > 0 {
timer = time.After(timeout)
}
// Create a log future, no index or term yet
logFuture := &logFuture{
log: Log{
Type: LogCommand,
Data: log.Data,
Extensions: log.Extensions,
},
}
logFuture.init()
select {
case <-timer:
return errorFuture{ErrEnqueueTimeout}
case <-r.shutdownCh:
return errorFuture{ErrRaftShutdown}
case r.applyCh <- logFuture:
return logFuture
}
}将 Log 封装到 Future 类里面,然后将 future 写到 raft 的通道 applyCh 里面,异步的等待处理。此时用户需要调用 logFuture.Error() 阻塞等待返回值即可。接下来看一下 raft 模块如何处理
2. 更新 fsm
NewRaft 启动后,会运行两个 goroutine r.run 和 r.runFSM, r.run 根据 raft 节点不同角色来运行不同 raft 函数。r.runFSM 用于从 raft 中获取完成共识的 log, 然后应用到用户的 fsm,然后 logFuture.Error() 解除阻塞,获得数据,先看一下 runFSM
func (r *Raft) runFSM() {
var lastIndex, lastTerm uint64
batchingFSM, batchingEnabled := r.fsm.(BatchingFSM)
configStore, configStoreEnabled := r.fsm.(ConfigurationStore)
commitSingle := func(req *commitTuple) {
// Apply the log if a command or config change
var resp interface{}
// Make sure we send a response
defer func() {
// Invoke the future if given
if req.future != nil {
req.future.response = resp
req.future.respond(nil)
}
}()
switch req.log.Type {
case LogCommand:
start := time.Now()
resp = r.fsm.Apply(req.log)
metrics.MeasureSince([]string{"raft", "fsm", "apply"}, start)
case LogConfiguration:
if !configStoreEnabled {
// Return early to avoid incrementing the index and term for
// an unimplemented operation.
return
}
start := time.Now()
configStore.StoreConfiguration(req.log.Index, DecodeConfiguration(req.log.Data))
metrics.MeasureSince([]string{"raft", "fsm", "store_config"}, start)
}
// Update the indexes
lastIndex = req.log.Index
lastTerm = req.log.Term
}
commitBatch := func(reqs []*commitTuple) {
if !batchingEnabled {
for _, ct := range reqs {
commitSingle(ct)
}
return
}
// Only send LogCommand and LogConfiguration log types. LogBarrier types
// will not be sent to the FSM.
shouldSend := func(l *Log) bool {
switch l.Type {
case LogCommand, LogConfiguration:
return true
}
return false
}
var lastBatchIndex, lastBatchTerm uint64
sendLogs := make([]*Log, 0, len(reqs))
for _, req := range reqs {
if shouldSend(req.log) {
sendLogs = append(sendLogs, req.log)
}
lastBatchIndex = req.log.Index
lastBatchTerm = req.log.Term
}
var responses []interface{}
if len(sendLogs) > 0 {
start := time.Now()
responses = batchingFSM.ApplyBatch(sendLogs)
metrics.MeasureSince([]string{"raft", "fsm", "applyBatch"}, start)
metrics.AddSample([]string{"raft", "fsm", "applyBatchNum"}, float32(len(reqs)))
// Ensure we get the expected responses
if len(sendLogs) != len(responses) {
panic("invalid number of responses")
}
}
// Update the indexes
lastIndex = lastBatchIndex
lastTerm = lastBatchTerm
var i int
for _, req := range reqs {
var resp interface{}
// If the log was sent to the FSM, retrieve the response.
if shouldSend(req.log) {
resp = responses[i]
i++
}
if req.future != nil {
req.future.response = resp
req.future.respond(nil)
}
}
}
restore := func(req *restoreFuture) {
......
}
snapshot := func(req *reqSnapshotFuture) {
......
}
for {
select {
case ptr := <-r.fsmMutateCh:
switch req := ptr.(type) {
case []*commitTuple:
commitBatch(req)
case *restoreFuture:
restore(req)
default:
panic(fmt.Errorf("bad type passed to fsmMutateCh: %#v", ptr))
}
case req := <-r.fsmSnapshotCh:
snapshot(req)
case <-r.shutdownCh:
return
}
}
}这个函数先看底下的 for 循环,主要是从 r.fsmMutateCh, r.fsmSnapshotCh 两个通道接收事件,snapshot 相关的先忽略,只看 commitSingle, commitBatch, 应用 Logs 到用户 fsm
commitSingle很简单,应用单个 Log, cmd 类型是LogCommand的话,调用用户层fsm.Apply应用日志。如果是LogConfiguration, 那么 configStore 保存配置变更。commitBatch如果用户 fsm 不支持 batch 操作,挨个调用commitSingle去应用单个 Log. 否则就可以调用fsm.ApplyBatch批量应用日志,可以提高并发
这两步操作最后都要更新 lastIndex, lastTerm, 调用 req.future.respond 写 future, 解除 client 阻塞。至此看完了 raft 与 client 简单交互的逻辑。记住,r.applyCh 用于写用户请求,r.fsmMutateCh 用于读取数据返回到 application 层。
3. leader 接收用户请求
r.run 根据节点角色来调用不同函数,主要是 runLeader, 先忽略其它,只看 leaderLoop 如何处理用户请求
// leaderLoop is the hot loop for a leader. It is invoked
// after all the various leader setup is done.
func (r *Raft) leaderLoop() {
// stepDown is used to track if there is an inflight log that
// would cause us to lose leadership (specifically a RemovePeer of
// ourselves). If this is the case, we must not allow any logs to
// be processed in parallel, otherwise we are basing commit on
// only a single peer (ourself) and replicating to an undefined set
// of peers.
stepDown := false
lease := time.After(r.conf.LeaderLeaseTimeout)
for r.getState() == Leader {
select {
......
case newLog := <-r.applyCh:
if r.getLeadershipTransferInProgress() {
r.logger.Debug(ErrLeadershipTransferInProgress.Error())
newLog.respond(ErrLeadershipTransferInProgress)
continue
}
// Group commit, gather all the ready commits
ready := []*logFuture{newLog}
GROUP_COMMIT_LOOP:
for i := 0; i < r.conf.MaxAppendEntries; i++ {
select {
case newLog := <-r.applyCh:
ready = append(ready, newLog)
default:
break GROUP_COMMIT_LOOP
}
}
// Dispatch the logs
if stepDown {
// we're in the process of stepping down as leader, don't process anything new
for i := range ready {
ready[i].respond(ErrNotLeader)
}
} else {
r.dispatchLogs(ready)
}
......
}
}
}select 有很多 case 分支,暂时只看 <-r.applyCh 部分
- 判断是否 getLeadershipTransferInProgress 处在 leader 切换中,是的话 respond 错误给 client
- 尝试从
r.applyCh通道中拿更多的 logFuture, 这样可以做 batch 操作,提高性能 - 判断是否处在 stepDown 状态,是的话 respond 错误给 client, 解除阻塞
- 调和
r.dispatchLogs发送 ready 所有日志
func (r *Raft) dispatchLogs(applyLogs []*logFuture) {
now := time.Now()
defer metrics.MeasureSince([]string{"raft", "leader", "dispatchLog"}, now)
term := r.getCurrentTerm()
lastIndex := r.getLastIndex()
n := len(applyLogs)
logs := make([]*Log, n)
metrics.SetGauge([]string{"raft", "leader", "dispatchNumLogs"}, float32(n))
for idx, applyLog := range applyLogs {
applyLog.dispatch = now
lastIndex++
applyLog.log.Index = lastIndex
applyLog.log.Term = term
logs[idx] = &applyLog.log
r.leaderState.inflight.PushBack(applyLog)
}
// Write the log entry locally
if err := r.logs.StoreLogs(logs); err != nil {
r.logger.Error("failed to commit logs", "error", err)
for _, applyLog := range applyLogs {
applyLog.respond(err)
}
r.setState(Follower)
return
}
r.leaderState.commitment.match(r.localID, lastIndex)
// Update the last log since it's on disk now
r.setLastLog(lastIndex, term)
// Notify the replicators of the new log
for _, f := range r.leaderState.replState {
asyncNotifyCh(f.triggerCh)
}
}- 获取当前 term 和 lastIndex, 批量填充到所有 applyLogs 中,Index 是递增的,然后 PushBack 到 inflight 队列中
StoreLogs保存持久化所有 logs, 如果报错,那么循环 respond, 设退到 follower 状态- 调用
match更新 commitment, 这个是用来判断大多数节点 commit 到哪个 index 上了,多数 commit 就可以 apply 了 setLastLog更新当前 leader 最新 log 的 index, termasyncNotifyCh异步通知当前有新的 log 需要发送到所有 follower
那么 f.triggerCh 哪来的呢?
4. leader 发送请求到 follower
刚才提到 runLeader 函数,里机会调用 startStopReplication 建立给所有 follower 发送消息的通道。我们来看一下
func (r *Raft) startStopReplication() {
inConfig := make(map[ServerID]bool, len(r.configurations.latest.Servers))
lastIdx := r.getLastIndex()
// Start replication goroutines that need starting
for _, server := range r.configurations.latest.Servers {
if server.ID == r.localID {
continue
}
inConfig[server.ID] = true
if _, ok := r.leaderState.replState[server.ID]; !ok {
r.logger.Info("added peer, starting replication", "peer", server.ID)
s := &followerReplication{
peer: server,
commitment: r.leaderState.commitment,
stopCh: make(chan uint64, 1),
triggerCh: make(chan struct{}, 1),
triggerDeferErrorCh: make(chan *deferError, 1),
currentTerm: r.getCurrentTerm(),
nextIndex: lastIdx + 1,
lastContact: time.Now(),
notify: make(map[*verifyFuture]struct{}),
notifyCh: make(chan struct{}, 1),
stepDown: r.leaderState.stepDown,
}
r.leaderState.replState[server.ID] = s
r.goFunc(func() { r.replicate(s) })
asyncNotifyCh(s.triggerCh)
r.observe(PeerObservation{Peer: server, Removed: false})
}
}
// Stop replication goroutines that need stopping
for serverID, repl := range r.leaderState.replState {
if inConfig[serverID] {
continue
}
// Replicate up to lastIdx and stop
r.logger.Info("removed peer, stopping replication", "peer", serverID, "last-index", lastIdx)
repl.stopCh <- lastIdx
close(repl.stopCh)
delete(r.leaderState.replState, serverID)
r.observe(PeerObservation{Peer: repl.peer, Removed: true})
}
}- 遍历配置 configurations, 给每个 follower 建立一个结构体
followerReplication用于追踪每个 follower 的同步状态。每个 follower 会起一个replicate的异步 goroutine - 遍历己有的 replState, 如果有不在 configurations 的节点,那么退出 goroutine
让我们来看一下 replicate 函数
// replicate is a long running routine that replicates log entries to a single
// follower.
func (r *Raft) replicate(s *followerReplication) {
// Start an async heartbeating routing
stopHeartbeat := make(chan struct{})
defer close(stopHeartbeat)
r.goFunc(func() { r.heartbeat(s, stopHeartbeat) })
RPC:
shouldStop := false
for !shouldStop {
select {
......
case <-s.triggerCh:
lastLogIdx, _ := r.getLastLog()
shouldStop = r.replicateTo(s, lastLogIdx)
// This is _not_ our heartbeat mechanism but is to ensure
// followers quickly learn the leader's commit index when
// raft commits stop flowing naturally. The actual heartbeats
// can't do this to keep them unblocked by disk IO on the
// follower. See https://github.com/hashicorp/raft/issues/282.
case <-randomTimeout(r.conf.CommitTimeout):
lastLogIdx, _ := r.getLastLog()
shouldStop = r.replicateTo(s, lastLogIdx)
}
// If things looks healthy, switch to pipeline mode
if !shouldStop && s.allowPipeline {
goto PIPELINE
}
}
return
PIPELINE:
// Disable until re-enabled
s.allowPipeline = false
// Replicates using a pipeline for high performance. This method
// is not able to gracefully recover from errors, and so we fall back
// to standard mode on failure.
if err := r.pipelineReplicate(s); err != nil {
if err != ErrPipelineReplicationNotSupported {
r.logger.Error("failed to start pipeline replication to", "peer", s.peer, "error", err)
}
}
goto RPC
}- 开启 heartbeat goroutine 做心跳,暂时不看
s.triggerCh触发,说明有数据待发送到 follower, lastLogIdx 为当前 leader 最新的日志号,根据该 follower 的状态 s 来调用replicateTo发送- 最后如果一次 rpc 调有成功,并且配置充许 pipeline 的话,调用
pipelineReplicate开启流水线发送,提高效率
// replicateTo is a helper to replicate(), used to replicate the logs up to a
// given last index.
// If the follower log is behind, we take care to bring them up to date.
func (r *Raft) replicateTo(s *followerReplication, lastIndex uint64) (shouldStop bool) {
// Create the base request
var req AppendEntriesRequest
var resp AppendEntriesResponse
var start time.Time
START:
// Prevent an excessive retry rate on errors
if s.failures > 0 {
select {
case <-time.After(backoff(failureWait, s.failures, maxFailureScale)):
case <-r.shutdownCh:
}
}
// Setup the request
if err := r.setupAppendEntries(s, &req, atomic.LoadUint64(&s.nextIndex), lastIndex); err == ErrLogNotFound {
goto SEND_SNAP
} else if err != nil {
return
}
// Make the RPC call
start = time.Now()
if err := r.trans.AppendEntries(s.peer.ID, s.peer.Address, &req, &resp); err != nil {
r.logger.Error("failed to appendEntries to", "peer", s.peer, "error", err)
s.failures++
return
}
appendStats(string(s.peer.ID), start, float32(len(req.Entries)))
// Check for a newer term, stop running
if resp.Term > req.Term {
r.handleStaleTerm(s)
return true
}
// Update the last contact
s.setLastContact()
// Update s based on success
if resp.Success {
// Update our replication state
updateLastAppended(s, &req)
// Clear any failures, allow pipelining
s.failures = 0
s.allowPipeline = true
} else {
atomic.StoreUint64(&s.nextIndex, max(min(s.nextIndex-1, resp.LastLog+1), 1))
if resp.NoRetryBackoff {
s.failures = 0
} else {
s.failures++
}
r.logger.Warn("appendEntries rejected, sending older logs", "peer", s.peer, "next", atomic.LoadUint64(&s.nextIndex))
}
CHECK_MORE:
// Poll the stop channel here in case we are looping and have been asked
// to stop, or have stepped down as leader. Even for the best effort case
// where we are asked to replicate to a given index and then shutdown,
// it's better to not loop in here to send lots of entries to a straggler
// that's leaving the cluster anyways.
select {
case <-s.stopCh:
return true
default:
}
// Check if there are more logs to replicate
if atomic.LoadUint64(&s.nextIndex) <= lastIndex {
goto START
}
return
// SEND_SNAP is used when we fail to get a log, usually because the follower
// is too far behind, and we must ship a snapshot down instead
SEND_SNAP:
if stop, err := r.sendLatestSnapshot(s); stop {
return true
} else if err != nil {
r.logger.Error("failed to send snapshot to", "peer", s.peer, "error", err)
return
}
// Check if there is more to replicate
goto CHECK_MORE
}- 调用
setupAppendEntries构建 rpc 请求的 req, 里面包含所有待发送的 logs - transport 调用
AppendEntries发送请求到网络,如果错误是日志不存在,那么跳转到sendLatestSnapshot发送快照 - 如果 follower 的任期大于该 leader, 处理 Term 异常的情况
setLastContact更新该 follower 最新 contact 时间- 调用
updateLastAppended触发 commitment 发起 match 匹配调用
5. leader 确认提交
leader 调用 replicateTo 发送完数据,会调用 updateLastAppended 触发 match 操作
func updateLastAppended(s *followerReplication, req *AppendEntriesRequest) {
// Mark any inflight logs as committed
if logs := req.Entries; len(logs) > 0 {
last := logs[len(logs)-1]
atomic.StoreUint64(&s.nextIndex, last.Index+1)
s.commitment.match(s.peer.ID, last.Index)
}
// Notify still leader
s.notifyAll(true)
}更新当前 follower 的 s.nextIndex 下一次待发送日志号,调用 match 触发匹配操作。notifyAll 是用来确认 leader 的,以后再看
func (c *commitment) match(server ServerID, matchIndex uint64) {
c.Lock()
defer c.Unlock()
if prev, hasVote := c.matchIndexes[server]; hasVote && matchIndex > prev {
c.matchIndexes[server] = matchIndex
c.recalculate()
}
}
// Internal helper to calculate new commitIndex from matchIndexes.
// Must be called with lock held.
func (c *commitment) recalculate() {
if len(c.matchIndexes) == 0 {
return
}
matched := make([]uint64, 0, len(c.matchIndexes))
for _, idx := range c.matchIndexes {
matched = append(matched, idx)
}
sort.Sort(uint64Slice(matched))
quorumMatchIndex := matched[(len(matched)-1)/2]
if quorumMatchIndex > c.commitIndex && quorumMatchIndex >= c.startIndex {
c.commitIndex = quorumMatchIndex
asyncNotifyCh(c.commitCh)
}
}给所有 follower 的 matchIndex 做排序,过半 quorum 接收到的就可以 commit 了,更新 c.commitIndex, 然后通知 c.commitCh 可以 apply 后续操作了。
func (r *Raft) leaderLoop() {
// stepDown is used to track if there is an inflight log that
// would cause us to lose leadership (specifically a RemovePeer of
// ourselves). If this is the case, we must not allow any logs to
// be processed in parallel, otherwise we are basing commit on
// only a single peer (ourself) and replicating to an undefined set
// of peers.
stepDown := false
lease := time.After(r.conf.LeaderLeaseTimeout)
for r.getState() == Leader {
select {
......
case <-r.leaderState.commitCh:
// Process the newly committed entries
oldCommitIndex := r.getCommitIndex()
commitIndex := r.leaderState.commitment.getCommitIndex()
r.setCommitIndex(commitIndex)
......
start := time.Now()
var groupReady []*list.Element
var groupFutures = make(map[uint64]*logFuture)
var lastIdxInGroup uint64
// Pull all inflight logs that are committed off the queue.
for e := r.leaderState.inflight.Front(); e != nil; e = e.Next() {
commitLog := e.Value.(*logFuture)
idx := commitLog.log.Index
if idx > commitIndex {
// Don't go past the committed index
break
}
// Measure the commit time
metrics.MeasureSince([]string{"raft", "commitTime"}, commitLog.dispatch)
groupReady = append(groupReady, e)
groupFutures[idx] = commitLog
lastIdxInGroup = idx
}
// Process the group
if len(groupReady) != 0 {
r.processLogs(lastIdxInGroup, groupFutures)
for _, e := range groupReady {
r.leaderState.inflight.Remove(e)
}
}
......
}
}
}忽略 leaderLoop 函数里其它分支,只看 r.leaderState.commitCh 消息
- oldCommitIndex 是旧的 commit index, 调用
getCommitIndex从 commitment 里获取最新的 commitIndex,中间的差值就是可以 commit 并 apply 的 - 获取 inFlight 中所有可以 commit 的 Logs groupFutures
- 调用
processLogs处理日志,并且从 inFlight 队列中删除
func (r *Raft) processLogs(index uint64, futures map[uint64]*logFuture) {
// Reject logs we've applied already
lastApplied := r.getLastApplied()
if index <= lastApplied {
r.logger.Warn("skipping application of old log", "index", index)
return
}
applyBatch := func(batch []*commitTuple) {
select {
case r.fsmMutateCh <- batch:
case <-r.shutdownCh:
for _, cl := range batch {
if cl.future != nil {
cl.future.respond(ErrRaftShutdown)
}
}
}
}
batch := make([]*commitTuple, 0, r.conf.MaxAppendEntries)
// Apply all the preceding logs
for idx := lastApplied + 1; idx <= index; idx++ {
var preparedLog *commitTuple
// Get the log, either from the future or from our log store
future, futureOk := futures[idx]
if futureOk {
preparedLog = r.prepareLog(&future.log, future)
} else {
l := new(Log)
if err := r.logs.GetLog(idx, l); err != nil {
r.logger.Error("failed to get log", "index", idx, "error", err)
panic(err)
}
preparedLog = r.prepareLog(l, nil)
}
switch {
case preparedLog != nil:
// If we have a log ready to send to the FSM add it to the batch.
// The FSM thread will respond to the future.
batch = append(batch, preparedLog)
// If we have filled up a batch, send it to the FSM
if len(batch) >= r.conf.MaxAppendEntries {
applyBatch(batch)
batch = make([]*commitTuple, 0, r.conf.MaxAppendEntries)
}
case futureOk:
// Invoke the future if given.
future.respond(nil)
}
}
// If there are any remaining logs in the batch apply them
if len(batch) != 0 {
applyBatch(batch)
}
// Update the lastApplied index and term
r.setLastApplied(index)
}- lastApplied 到 index 之间都是可以 commit 并 apply 到 fsm 的数据
- 遍历这些 logs, 如果当前节点是 leader 那么在 futures map 中肯定存在,如果是 follower 节点,那么肯定不存在。都会调用 prepareLog 准备数据,区别就是要从持久化的 r.logs.GetLog 中获取日志
- 追加到 batch 数组中,如果超过了 MaxAppendEntries 阈值,那么直接调用 applyBatch,实际就是写到上文提到的 r.fsmMutateCh
- 最后 batch 小于最大数量时 applyBatch,更新 lastApplied
6. follower 接收请求
runFollower 调用 processRPC 处理接收到的请求
// processRPC is called to handle an incoming RPC request. This must only be
// called from the main thread.
func (r *Raft) processRPC(rpc RPC) {
if err := r.checkRPCHeader(rpc); err != nil {
rpc.Respond(nil, err)
return
}
switch cmd := rpc.Command.(type) {
case *AppendEntriesRequest:
r.appendEntries(rpc, cmd)
case *RequestVoteRequest:
r.requestVote(rpc, cmd)
case *InstallSnapshotRequest:
r.installSnapshot(rpc, cmd)
case *TimeoutNowRequest:
r.timeoutNow(rpc, cmd)
default:
r.logger.Error("got unexpected command",
"command", hclog.Fmt("%#v", rpc.Command))
rpc.Respond(nil, fmt.Errorf("unexpected command"))
}
}我们只看 appendEntries 就好
// appendEntries is invoked when we get an append entries RPC call. This must
// only be called from the main thread.
func (r *Raft) appendEntries(rpc RPC, a *AppendEntriesRequest) {
defer metrics.MeasureSince([]string{"raft", "rpc", "appendEntries"}, time.Now())
// Setup a response
resp := &AppendEntriesResponse{
RPCHeader: r.getRPCHeader(),
Term: r.getCurrentTerm(),
LastLog: r.getLastIndex(),
Success: false,
NoRetryBackoff: false,
}
var rpcErr error
defer func() {
rpc.Respond(resp, rpcErr)
}()
// Ignore an older term
if a.Term < r.getCurrentTerm() {
return
}
// Increase the term if we see a newer one, also transition to follower
// if we ever get an appendEntries call
if a.Term > r.getCurrentTerm() || r.getState() != Follower {
// Ensure transition to follower
r.setState(Follower)
r.setCurrentTerm(a.Term)
resp.Term = a.Term
}
// Save the current leader
r.setLeader(ServerAddress(r.trans.DecodePeer(a.Leader)))
// Verify the last log entry
if a.PrevLogEntry > 0 {
lastIdx, lastTerm := r.getLastEntry()
var prevLogTerm uint64
if a.PrevLogEntry == lastIdx {
prevLogTerm = lastTerm
} else {
var prevLog Log
if err := r.logs.GetLog(a.PrevLogEntry, &prevLog); err != nil {
r.logger.Warn("failed to get previous log",
"previous-index", a.PrevLogEntry,
"last-index", lastIdx,
"error", err)
resp.NoRetryBackoff = true
return
}
prevLogTerm = prevLog.Term
}
if a.PrevLogTerm != prevLogTerm {
r.logger.Warn("previous log term mis-match",
"ours", prevLogTerm,
"remote", a.PrevLogTerm)
resp.NoRetryBackoff = true
return
}
}
// Process any new entries
if len(a.Entries) > 0 {
start := time.Now()
// Delete any conflicting entries, skip any duplicates
lastLogIdx, _ := r.getLastLog()
var newEntries []*Log
for i, entry := range a.Entries {
if entry.Index > lastLogIdx {
newEntries = a.Entries[i:]
break
}
var storeEntry Log
if err := r.logs.GetLog(entry.Index, &storeEntry); err != nil {
r.logger.Warn("failed to get log entry",
"index", entry.Index,
"error", err)
return
}
if entry.Term != storeEntry.Term {
r.logger.Warn("clearing log suffix",
"from", entry.Index,
"to", lastLogIdx)
if err := r.logs.DeleteRange(entry.Index, lastLogIdx); err != nil {
r.logger.Error("failed to clear log suffix", "error", err)
return
}
if entry.Index <= r.configurations.latestIndex {
r.setLatestConfiguration(r.configurations.committed, r.configurations.committedIndex)
}
newEntries = a.Entries[i:]
break
}
}
if n := len(newEntries); n > 0 {
// Append the new entries
if err := r.logs.StoreLogs(newEntries); err != nil {
r.logger.Error("failed to append to logs", "error", err)
// TODO: leaving r.getLastLog() in the wrong
// state if there was a truncation above
return
}
// Handle any new configuration changes
for _, newEntry := range newEntries {
r.processConfigurationLogEntry(newEntry)
}
// Update the lastLog
last := newEntries[n-1]
r.setLastLog(last.Index, last.Term)
}
metrics.MeasureSince([]string{"raft", "rpc", "appendEntries", "storeLogs"}, start)
}
// Update the commit index
if a.LeaderCommitIndex > 0 && a.LeaderCommitIndex > r.getCommitIndex() {
start := time.Now()
idx := min(a.LeaderCommitIndex, r.getLastIndex())
r.setCommitIndex(idx)
if r.configurations.latestIndex <= idx {
r.setCommittedConfiguration(r.configurations.latest, r.configurations.latestIndex)
}
r.processLogs(idx, nil)
metrics.MeasureSince([]string{"raft", "rpc", "appendEntries", "processLogs"}, start)
}
// Everything went well, set success
resp.Success = true
r.setLastContact()
return
}- 构建响应
AppendEntriesResponse,如果 leader 发来的 term 小于自身 follower 的,返回并报错 - 如果 leader term 大于自身的,那么状态要强制写成 follower
- setLeader 更新当前 follower 知道的 leader id
- PrevLogEntry, PrevLogTerm 用于判断日志一致性检查
- a.Entries 是要 commit 的 logs, 但是如果和现有 logs 有重叠的部分,那么要检查冲突并删除
- newEntries 表示可以安全写入的 logs,
StoreLogs保存,如果这中间的配置的变更,也要应用 - LeaderCommitIndex 表示 leader 己经 commit 到的 index, follower 可以安全的 apply 到
min(a.LeaderCommitIndex, r.getLastIndex())这个位置
优化
至此看完了大致的流程,他也实现了论文提到的两个优化
- batch 操作,如果不支持的话,系统性能尤其是 fsm 性能差很多
- pipeline 流水线复制,用过 redis 的都懂,如果允许 pipeline 网络性能会提升很多
还有待优化的地方,比如 follower processLogs 的时候,logs 需要从存储中获取,但是很多时候 raft 传播日志很快,logs 保存个 lru 列表或是缓存更好一些,减少每次无意义的 IO 调用。
另外 runLeader 中,r.applyCh 持久化 Logs, 与 apply Logs 是串行的,真的一定要串行嘛?
小结
这次分享就这些,以后面还会分享更多 etcd 与 raft 的内容。
参考资料
[1]hashicorp raft: https://github.com/hashicorp/raft,