一文了解 etcd watch 实现
前几天在群里讨论服务发现,最简单的模型使用 etcd watch 来实现消息订阅,我司也是这方案。但从可运维及稳定性考虑,etcd 并不是最佳选择,好多小伙伴所在的公司仍然采用 mysql 的推拉结合方式。这让我想起来,很多人面试问如何实现延迟队列,花里胡哨一大堆解决方案,可能公司最后还是使用 mysql 轮询 ...
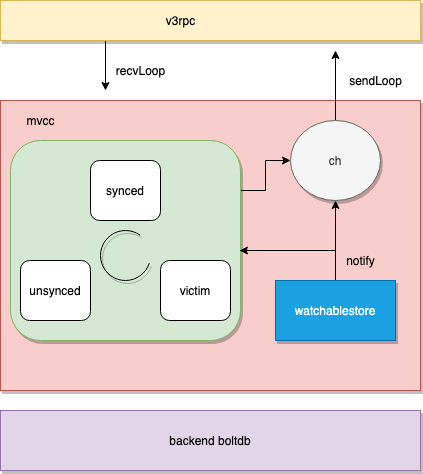
扯远了,来看一下 etcd 如何实现的 watch, 原理不算复杂,但要处理很多场景,比如不同 client 消费速度不同的问题,处理如何高效匹配 range 范围等等。下面是整体架构图
经典使用
先看一下经典的使用 case, 代码做了简化,网上有很多人说 watch 丢消息,基本就是姿势错误导致的。
func watch(ctx context.Context, revision int64) {
......
for {
rch := watcher.Watch(ctx, "/somepath", clientv3.WithRev(revision), clientv3.WithPrefix())
for wresp := range rch {
// meet compacted error, use the compact revision.
if wresp.CompactRevision != 0 {
logging.Warn("required revision has been compacted, use the compact revision:%d, required-revision:%d", wresp.CompactRevision, revision)
revision = wresp.CompactRevision
break
}
if wresp.Canceled {
logging.Warn("watcher is canceled with revision: %d error: %v", revision, wresp.Err())
return
}
for _, ev := range wresp.Events {
process(ev)
}
revision = wresp.Header.Revision
}
select {
case <-ctx.Done():
// server closed, return
return
default:
}
}
......
}上面代码是经典的使用方式,算是标准实践,要注意处理 compact revision, 处理 ctx 超时,以及上层的 rewatch. 同时 watch 时可以指定 option, 接受历史版本数据,订阅一个范围前辍等等
服务初始化
etcd 启动时会注册 WatchServer[1], pb.WatchServer 用于处理 watch 请求
// NewWatchServer returns a new watch server.
func NewWatchServer(s *etcdserver.EtcdServer) pb.WatchServer {
return &watchServer{
lg: s.Cfg.Logger,
clusterID: int64(s.Cluster().ID()),
memberID: int64(s.ID()),
maxRequestBytes: int(s.Cfg.MaxRequestBytes + grpcOverheadBytes),
sg: s,
watchable: s.Watchable(),
ag: s,
}
}这里面关注 watchable 就行,是一个接口,实际上实现是 mvcc.watchableStore
接收 watch 请求
func (ws *watchServer) Watch(stream pb.Watch_WatchServer) (err error) {
sws := serverWatchStream{
lg: ws.lg,
clusterID: ws.clusterID,
memberID: ws.memberID,
maxRequestBytes: ws.maxRequestBytes,
sg: ws.sg,
watchable: ws.watchable,
ag: ws.ag,
gRPCStream: stream,
watchStream: ws.watchable.NewWatchStream(),
// chan for sending control response like watcher created and canceled.
ctrlStream: make(chan *pb.WatchResponse, ctrlStreamBufLen),
progress: make(map[mvcc.WatchID]bool),
prevKV: make(map[mvcc.WatchID]bool),
fragment: make(map[mvcc.WatchID]bool),
closec: make(chan struct{}),
}
sws.wg.Add(1)
go func() {
sws.sendLoop()
sws.wg.Done()
}()
errc := make(chan error, 1)
// Ideally recvLoop would also use sws.wg to signal its completion
// but when stream.Context().Done() is closed, the stream's recv
// may continue to block since it uses a different context, leading to
// deadlock when calling sws.close().
go func() {
if rerr := sws.recvLoop(); rerr != nil {
if isClientCtxErr(stream.Context().Err(), rerr) {
if sws.lg != nil {
sws.lg.Debug("failed to receive watch request from gRPC stream", zap.Error(rerr))
} else {
plog.Debugf("failed to receive watch request from gRPC stream (%q)", rerr.Error())
}
} else {
if sws.lg != nil {
sws.lg.Warn("failed to receive watch request from gRPC stream", zap.Error(rerr))
} else {
plog.Warningf("failed to receive watch request from gRPC stream (%q)", rerr.Error())
}
streamFailures.WithLabelValues("receive", "watch").Inc()
}
errc <- rerr
}
}()
select {
case err = <-errc:
close(sws.ctrlStream)
case <-stream.Context().Done():
err = stream.Context().Err()
// the only server-side cancellation is noleader for now.
if err == context.Canceled {
err = rpctypes.ErrGRPCNoLeader
}
}
sws.close()
return err
}- 每一个 watch 流都创建一个
serverWatchStream结构体 - 开启两个 goroutine,
sendLoop用于发送 watch 消息到流中,recvLoop接受请求 - select 阻塞直到流关闭,或是超时退出。
1. 接收 watch 请求 recvLoop
func (sws *serverWatchStream) recvLoop() error {
for {
req, err := sws.gRPCStream.Recv()
......
switch uv := req.RequestUnion.(type) {
case *pb.WatchRequest_CreateRequest:
creq := uv.CreateRequest
if len(creq.Key) == 0 {
// \x00 is the smallest key
creq.Key = []byte{0}
}
if len(creq.RangeEnd) == 0 {
// force nil since watchstream.Watch distinguishes
// between nil and []byte{} for single key / >=
creq.RangeEnd = nil
}
if len(creq.RangeEnd) == 1 && creq.RangeEnd[0] == 0 {
// support >= key queries
creq.RangeEnd = []byte{}
}
if !sws.isWatchPermitted(creq) {
wr := &pb.WatchResponse{
Header: sws.newResponseHeader(sws.watchStream.Rev()),
WatchId: creq.WatchId,
Canceled: true,
Created: true,
CancelReason: rpctypes.ErrGRPCPermissionDenied.Error(),
}
select {
case sws.ctrlStream <- wr:
case <-sws.closec:
}
return nil
}
filters := FiltersFromRequest(creq)
wsrev := sws.watchStream.Rev()
rev := creq.StartRevision
if rev == 0 {
rev = wsrev + 1
}
id, err := sws.watchStream.Watch(mvcc.WatchID(creq.WatchId), creq.Key, creq.RangeEnd, rev, filters...)
if err == nil {
sws.mu.Lock()
if creq.ProgressNotify {
sws.progress[id] = true
}
if creq.PrevKv {
sws.prevKV[id] = true
}
if creq.Fragment {
sws.fragment[id] = true
}
sws.mu.Unlock()
}
wr := &pb.WatchResponse{
Header: sws.newResponseHeader(wsrev),
WatchId: int64(id),
Created: true,
Canceled: err != nil,
}
if err != nil {
wr.CancelReason = err.Error()
}
select {
case sws.ctrlStream <- wr:
case <-sws.closec:
return nil
}
case *pb.WatchRequest_CancelRequest:
if uv.CancelRequest != nil {
id := uv.CancelRequest.WatchId
err := sws.watchStream.Cancel(mvcc.WatchID(id))
if err == nil {
sws.ctrlStream <- &pb.WatchResponse{
Header: sws.newResponseHeader(sws.watchStream.Rev()),
WatchId: id,
Canceled: true,
}
sws.mu.Lock()
delete(sws.progress, mvcc.WatchID(id))
delete(sws.prevKV, mvcc.WatchID(id))
delete(sws.fragment, mvcc.WatchID(id))
sws.mu.Unlock()
}
}
case *pb.WatchRequest_ProgressRequest:
if uv.ProgressRequest != nil {
sws.ctrlStream <- &pb.WatchResponse{
Header: sws.newResponseHeader(sws.watchStream.Rev()),
WatchId: -1, // response is not associated with any WatchId and will be broadcast to all watch channels
}
}
default:
// we probably should not shutdown the entire stream when
// receive an valid command.
// so just do nothing instead.
continue
}
}
}recvLoop 从 gRPCStream 读出 req, 然后分别处理类型为 CreateRequest, CancelRequest, ProgressRequest 的情况
- CreateRequest: 监听的可能是一个范围,所以构建 key 和 RangeEnd. 处理 StartRevision, 如果为 0, 那么使用当前系统最新的 Rev+1. 调用 mvcc 层的 watchStream.Watch, 返回一个 watchid, 将这个 id 写到 ctrlStream 返回给 client
- CancelRequest: 还是调用 mvcc 层的 watchableStore.Cancel 取消订阅,然后清除状态信息
- ProgressRequest: broadcast 广播当前系统的 Rev 版本
2. 接收 watch 请求 sendLoop
func (sws *serverWatchStream) sendLoop() {
// watch ids that are currently active
ids := make(map[mvcc.WatchID]struct{})
// watch responses pending on a watch id creation message
pending := make(map[mvcc.WatchID][]*pb.WatchResponse)
interval := GetProgressReportInterval()
progressTicker := time.NewTicker(interval)
defer func() {
progressTicker.Stop()
// drain the chan to clean up pending events
for ws := range sws.watchStream.Chan() {
mvcc.ReportEventReceived(len(ws.Events))
}
for _, wrs := range pending {
for _, ws := range wrs {
mvcc.ReportEventReceived(len(ws.Events))
}
}
}()
for {
select {
case wresp, ok := <-sws.watchStream.Chan():
if !ok {
return
}
// TODO: evs is []mvccpb.Event type
// either return []*mvccpb.Event from the mvcc package
// or define protocol buffer with []mvccpb.Event.
evs := wresp.Events
events := make([]*mvccpb.Event, len(evs))
sws.mu.RLock()
needPrevKV := sws.prevKV[wresp.WatchID]
sws.mu.RUnlock()
for i := range evs {
events[i] = &evs[i]
if needPrevKV {
opt := mvcc.RangeOptions{Rev: evs[i].Kv.ModRevision - 1}
r, err := sws.watchable.Range(evs[i].Kv.Key, nil, opt)
if err == nil && len(r.KVs) != 0 {
events[i].PrevKv = &(r.KVs[0])
}
}
}
canceled := wresp.CompactRevision != 0
wr := &pb.WatchResponse{
Header: sws.newResponseHeader(wresp.Revision),
WatchId: int64(wresp.WatchID),
Events: events,
CompactRevision: wresp.CompactRevision,
Canceled: canceled,
}
if _, okID := ids[wresp.WatchID]; !okID {
// buffer if id not yet announced
wrs := append(pending[wresp.WatchID], wr)
pending[wresp.WatchID] = wrs
continue
}
mvcc.ReportEventReceived(len(evs))
sws.mu.RLock()
fragmented, ok := sws.fragment[wresp.WatchID]
sws.mu.RUnlock()
var serr error
if !fragmented && !ok {
serr = sws.gRPCStream.Send(wr)
} else {
serr = sendFragments(wr, sws.maxRequestBytes, sws.gRPCStream.Send)
}
......
sws.mu.Lock()
if len(evs) > 0 && sws.progress[wresp.WatchID] {
// elide next progress update if sent a key update
sws.progress[wresp.WatchID] = false
}
sws.mu.Unlock()
case c, ok := <-sws.ctrlStream:
if !ok {
return
}
if err := sws.gRPCStream.Send(c); err != nil {
......
}
// track id creation
wid := mvcc.WatchID(c.WatchId)
if c.Canceled {
delete(ids, wid)
continue
}
if c.Created {
// flush buffered events
ids[wid] = struct{}{}
for _, v := range pending[wid] {
mvcc.ReportEventReceived(len(v.Events))
if err := sws.gRPCStream.Send(v); err != nil {
......
}
}
delete(pending, wid)
}
case <-progressTicker.C:
sws.mu.Lock()
for id, ok := range sws.progress {
if ok {
sws.watchStream.RequestProgress(id)
}
sws.progress[id] = true
}
sws.mu.Unlock()
case <-sws.closec:
return
}
}
}在 watchid 生成前,可能就有消息触发了,此时还没有 id, 所以消息会堆积到 pending 中。整个函数主要从 mvcc.watchStream.Chan() 中处理读取订阅的消息,处理 ctrlStream 控制消息和处理 progressTicker
- Chan(): 如果 needPrevKV, 需要填充。watchid 不存在的话,暂时移到 pending 队列中。Fragment 查看是否需要分包,这里阈值是 1.5M, 不需要的话直接调用
sws.gRPCStream.Send发送即可。如果有数据发送的情况,sws.progress[wresp.WatchID] 置为 false, 不用发进度消息 - ctrlStream: 读取控制消息,这里只要是获取 watchid, 然后发送堆积的 pending 消息
- progressTicker: 定期调用
RequestProgress生成进度消息,把当前 Rev 发给 client
MVCC watch
这一块主要是看 mvcc.watchStream, 看下 Watch 如何实现
// Watch creates a new watcher in the stream and returns its WatchID.
func (ws *watchStream) Watch(id WatchID, key, end []byte, startRev int64, fcs ...FilterFunc) (WatchID, error) {
// prevent wrong range where key >= end lexicographically
// watch request with 'WithFromKey' has empty-byte range end
if len(end) != 0 && bytes.Compare(key, end) != -1 {
return -1, ErrEmptyWatcherRange
}
ws.mu.Lock()
defer ws.mu.Unlock()
if ws.closed {
return -1, ErrEmptyWatcherRange
}
if id == AutoWatchID {
for ws.watchers[ws.nextID] != nil {
ws.nextID++
}
id = ws.nextID
ws.nextID++
} else if _, ok := ws.watchers[id]; ok {
return -1, ErrWatcherDuplicateID
}
w, c := ws.watchable.watch(key, end, startRev, id, ws.ch, fcs...)
ws.cancels[id] = c
ws.watchers[id] = w
return id, nil
}主要是用来生成 watchid, 自增就可以了。
func (s *watchableStore) watch(key, end []byte, startRev int64, id WatchID, ch chan<- WatchResponse, fcs ...FilterFunc) (*watcher, cancelFunc) {
wa := &watcher{
key: key,
end: end,
minRev: startRev,
id: id,
ch: ch,
fcs: fcs,
}
s.mu.Lock()
s.revMu.RLock()
synced := startRev > s.store.currentRev || startRev == 0
if synced {
wa.minRev = s.store.currentRev + 1
if startRev > wa.minRev {
wa.minRev = startRev
}
}
if synced {
s.synced.add(wa)
} else {
slowWatcherGauge.Inc()
s.unsynced.add(wa)
}
s.revMu.RUnlock()
s.mu.Unlock()
watcherGauge.Inc()
return wa, func() { s.cancelWatcher(wa) }
}watchableStore 一共有三个 group: synced, unsynced 与 victims, 当 client watch 时是从历史记录开始的,也就是说此时有一堆消息待发送给 client, 那么将 watcher 结构体扔到 unsynced 组中,否则扔到 synced 组中。为什么这么做呢?因为消息处理有快慢,后面具体代码再讲,只要记住 watcher 会在这三个组中流转即可,当然理想情况一直待在 synced 组中
func newWatchableStore(lg *zap.Logger, b backend.Backend, le lease.Lessor, ig ConsistentIndexGetter, cfg StoreConfig) *watchableStore {
s := &watchableStore{
store: NewStore(lg, b, le, ig, cfg),
victimc: make(chan struct{}, 1),
unsynced: newWatcherGroup(),
synced: newWatcherGroup(),
stopc: make(chan struct{}),
}
s.store.ReadView = &readView{s}
s.store.WriteView = &writeView{s}
if s.le != nil {
// use this store as the deleter so revokes trigger watch events
s.le.SetRangeDeleter(func() lease.TxnDelete { return s.Write(traceutil.TODO()) })
}
s.wg.Add(2)
go s.syncWatchersLoop()
go s.syncVictimsLoop()
return s
}在 newWatchableStore 时,会生成两个异步 goroutine, syncWatchersLoop 用于将 unsynced 的 watcher 变成 synced watcher, syncVictimsLoop 用于将 victims 的消息尽可能的发送出。
MVCC 消息生成
底层 Txn 用 watchableStoreTxnWrite 封装了一下,在调用 End 提交事务前,调用 notify 将变更的消息发送出去。
func (tw *watchableStoreTxnWrite) End() {
changes := tw.Changes()
if len(changes) == 0 {
tw.TxnWrite.End()
return
}
rev := tw.Rev() + 1
evs := make([]mvccpb.Event, len(changes))
for i, change := range changes {
evs[i].Kv = &changes[i]
if change.CreateRevision == 0 {
evs[i].Type = mvccpb.DELETE
evs[i].Kv.ModRevision = rev
} else {
evs[i].Type = mvccpb.PUT
}
}
// end write txn under watchable store lock so the updates are visible
// when asynchronous event posting checks the current store revision
tw.s.mu.Lock()
tw.s.notify(rev, evs)
tw.TxnWrite.End()
tw.s.mu.Unlock()
}遍历 changes, 判断类型 mvccpb.DELETE 或是 mvccpb.PUT, 然后封装成 envs 事件,调用 tw.s.notify 发送出去后提交。
// notify notifies the fact that given event at the given rev just happened to
// watchers that watch on the key of the event.
func (s *watchableStore) notify(rev int64, evs []mvccpb.Event) {
var victim watcherBatch
for w, eb := range newWatcherBatch(&s.synced, evs) {
if eb.revs != 1 {
if s.store != nil && s.store.lg != nil {
s.store.lg.Panic(
"unexpected multiple revisions in watch notification",
zap.Int("number-of-revisions", eb.revs),
)
} else {
plog.Panicf("unexpected multiple revisions in notification")
}
}
if w.send(WatchResponse{WatchID: w.id, Events: eb.evs, Revision: rev}) {
pendingEventsGauge.Add(float64(len(eb.evs)))
} else {
// move slow watcher to victims
w.minRev = rev + 1
if victim == nil {
victim = make(watcherBatch)
}
w.victim = true
victim[w] = eb
s.synced.delete(w)
slowWatcherGauge.Inc()
}
}
s.addVictim(victim)
}newWatcherBatch 用于从 synced 组中获取待发送的 watcher, 然后调用 w.send 发送到 channel 里面,如果 channel 满了,那么说明发送不出去,将 watcher 从 synced 组中删除,并添加到 victim 组中,等后后续异步 goroutine syncVictimsLoop 处理。我们看一下,newWatcherBatch 实现
func newWatcherBatch(wg *watcherGroup, evs []mvccpb.Event) watcherBatch {
if len(wg.watchers) == 0 {
return nil
}
wb := make(watcherBatch)
for _, ev := range evs {
for w := range wg.watcherSetByKey(string(ev.Kv.Key)) {
if ev.Kv.ModRevision >= w.minRev {
// don't double notify
wb.add(w, ev)
}
}
}
return wb
}watcherSetByKey 用于返回满足 ev.Kv.Key 的 watcher, 这里内部实现使用 adt 红黑树,可以做到快速的范围匹配。感兴趣的可以看源代码。
func (w *watcher) send(wr WatchResponse) bool {
progressEvent := len(wr.Events) == 0
if len(w.fcs) != 0 {
ne := make([]mvccpb.Event, 0, len(wr.Events))
for i := range wr.Events {
filtered := false
for _, filter := range w.fcs {
if filter(wr.Events[i]) {
filtered = true
break
}
}
if !filtered {
ne = append(ne, wr.Events[i])
}
}
wr.Events = ne
}
// if all events are filtered out, we should send nothing.
if !progressEvent && len(wr.Events) == 0 {
return true
}
select {
case w.ch <- wr:
return true
default:
return false
}
}send 函数先 apply filter 过滤一遍,然后发送到 w.ch 中,如果满了则返回 false. 这个 w.ch 就是 v3rpc 使用的 channel, 有数据后就发送 http2 stream ...
慢速处理
1.慢速处理 victim
func (s *watchableStore) syncVictimsLoop() {
defer s.wg.Done()
for {
for s.moveVictims() != 0 {
// try to update all victim watchers
}
s.mu.RLock()
isEmpty := len(s.victims) == 0
s.mu.RUnlock()
var tickc <-chan time.Time
if !isEmpty {
tickc = time.After(10 * time.Millisecond)
}
select {
case <-tickc:
case <-s.victimc:
case <-s.stopc:
return
}
}
}调用 moveVictims 尝试去发送堆积的消息
// moveVictims tries to update watches with already pending event data
func (s *watchableStore) moveVictims() (moved int) {
s.mu.Lock()
victims := s.victims
s.victims = nil
s.mu.Unlock()
var newVictim watcherBatch
for _, wb := range victims {
// try to send responses again
for w, eb := range wb {
// watcher has observed the store up to, but not including, w.minRev
rev := w.minRev - 1
if w.send(WatchResponse{WatchID: w.id, Events: eb.evs, Revision: rev}) {
pendingEventsGauge.Add(float64(len(eb.evs)))
} else {
if newVictim == nil {
newVictim = make(watcherBatch)
}
newVictim[w] = eb
continue
}
moved++
}
// assign completed victim watchers to unsync/sync
s.mu.Lock()
s.store.revMu.RLock()
curRev := s.store.currentRev
for w, eb := range wb {
if newVictim != nil && newVictim[w] != nil {
// couldn't send watch response; stays victim
continue
}
w.victim = false
if eb.moreRev != 0 {
w.minRev = eb.moreRev
}
if w.minRev <= curRev {
s.unsynced.add(w)
} else {
slowWatcherGauge.Dec()
s.synced.add(w)
}
}
s.store.revMu.RUnlock()
s.mu.Unlock()
}
if len(newVictim) > 0 {
s.mu.Lock()
s.victims = append(s.victims, newVictim)
s.mu.Unlock()
}
return moved
}代码很简单,先尝试发送 victims 这些消息,如果失败了,再放到 victims 中。成功了的话,还要看当前系统中的 Rev 是否与该 watcher.minRev 相等,再考滤放到 synced 组还是 unsynced 组中。
2.慢速处理 unsynced
syncWatchersLoop 函数循环调用 syncWatchers 处理 unsynced 组数据
// syncWatchers syncs unsynced watchers by:
// 1. choose a set of watchers from the unsynced watcher group
// 2. iterate over the set to get the minimum revision and remove compacted watchers
// 3. use minimum revision to get all key-value pairs and send those events to watchers
// 4. remove synced watchers in set from unsynced group and move to synced group
func (s *watchableStore) syncWatchers() int {
s.mu.Lock()
defer s.mu.Unlock()
if s.unsynced.size() == 0 {
return 0
}
s.store.revMu.RLock()
defer s.store.revMu.RUnlock()
// in order to find key-value pairs from unsynced watchers, we need to
// find min revision index, and these revisions can be used to
// query the backend store of key-value pairs
curRev := s.store.currentRev
compactionRev := s.store.compactMainRev
wg, minRev := s.unsynced.choose(maxWatchersPerSync, curRev, compactionRev)
minBytes, maxBytes := newRevBytes(), newRevBytes()
revToBytes(revision{main: minRev}, minBytes)
revToBytes(revision{main: curRev + 1}, maxBytes)
// UnsafeRange returns keys and values. And in boltdb, keys are revisions.
// values are actual key-value pairs in backend.
tx := s.store.b.ReadTx()
tx.RLock()
revs, vs := tx.UnsafeRange(keyBucketName, minBytes, maxBytes, 0)
var evs []mvccpb.Event
if s.store != nil && s.store.lg != nil {
evs = kvsToEvents(s.store.lg, wg, revs, vs)
} else {
// TODO: remove this in v3.5
evs = kvsToEvents(nil, wg, revs, vs)
}
tx.RUnlock()
var victims watcherBatch
wb := newWatcherBatch(wg, evs)
for w := range wg.watchers {
w.minRev = curRev + 1
eb, ok := wb[w]
if !ok {
// bring un-notified watcher to synced
s.synced.add(w)
s.unsynced.delete(w)
continue
}
if eb.moreRev != 0 {
w.minRev = eb.moreRev
}
if w.send(WatchResponse{WatchID: w.id, Events: eb.evs, Revision: curRev}) {
pendingEventsGauge.Add(float64(len(eb.evs)))
} else {
if victims == nil {
victims = make(watcherBatch)
}
w.victim = true
}
if w.victim {
victims[w] = eb
} else {
if eb.moreRev != 0 {
// stay unsynced; more to read
continue
}
s.synced.add(w)
}
s.unsynced.delete(w)
}
s.addVictim(victims)
vsz := 0
for _, v := range s.victims {
vsz += len(v)
}
slowWatcherGauge.Set(float64(s.unsynced.size() + vsz))
return s.unsynced.size()
}choose从 unsynced 中选择待发送数据的 watcher groups, 只看版本是否可用,即处于 [compactRev, curRev]UnsafeRange从 boltdb 中获取所有满足条件的 keys/values- 遍历 watchers,开始发送符合条件的 keys/values, 成功了那么从 unsynced 中删除,再加到 synced 中,否则加到 victims 队列中
小结
这次分享就这些,以后面还会分享更多 etcd 与 raft 的内容。
参考资料
[1]WatchServer: https://github.com/etcd-io/etcd/blob/master/etcdserver/api/v3rpc/grpc.go#L60,