时钟源为什么会影响性能
前几天帮同事看问题时,意外的发现了时钟源影响性能的 case, 比较典型,记录一下。网上也有人遇到过,参考虾皮的[Go] Time.Now函数CPU使用率异常[1] 和 Two frequently used system calls are ~77% slower on AWS EC2[2]
本质都是由 vdso fallback 到系统调用,所以慢了,但是触发这个条件的原因不太一样。我最后的分析也可能理解有误,欢迎一起讨论并指正。
另外,配图的意思是知道这些就可以了,往下看没球用 :(
现象
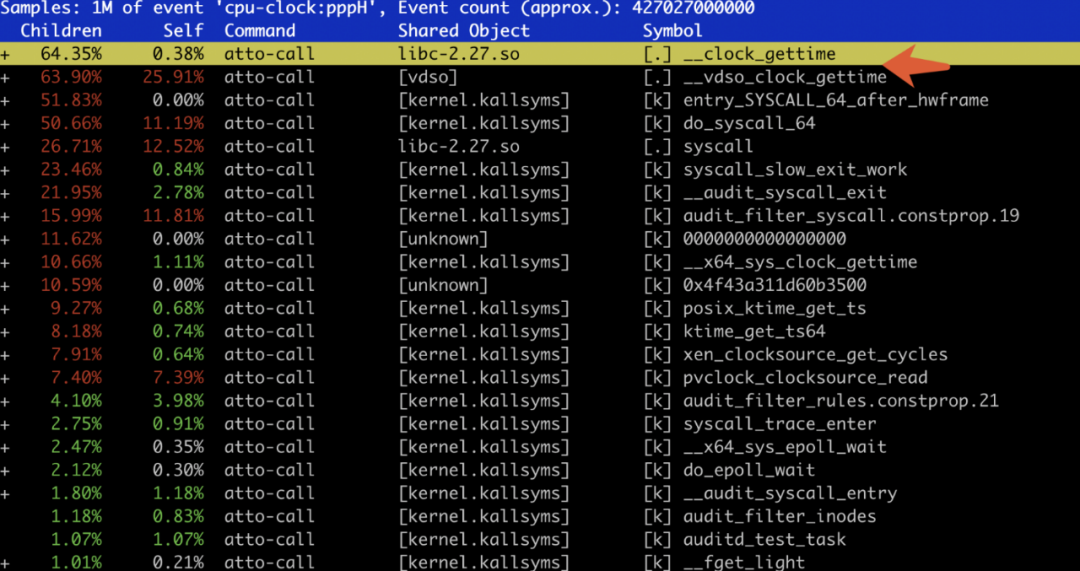
上图是 perf 性能图,可以发现 __clock_gettime 系统调用相关的耗时最多,非常诡异。
// time_demo.go
// strace -ce clock_gettime go run time_demo.go
package main
import (
"fmt"
"time"
)
func main(){
for i := 0; i < 10; i++{
t1 := time.Now()
t2 := time.Now()
fmt.Printf("Time taken: %v\n", t2.Sub(t1))
}
}上图是最小复现 demo, 直接查看 time.Now() 函数的耗时。使用 strace -ce 来查看系统调用的统计报表
~# strace -ce clock_gettime go run time_demo.go
Time taken: 1.983µs
Time taken: 1.507µs
Time taken: 2.247µs
Time taken: 2.993µs
Time taken: 2.703µs
Time taken: 1.927µs
Time taken: 2.091µs
Time taken: 2.16µs
Time taken: 2.085µs
Time taken: 2.234µs
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
100.00 0.001342 13 105 clock_gettime
------ ----------- ----------- --------- --------- ----------------
100.00 0.001342 105 total上面是有问题的机器结果,可以发现大量的系统调用 clock_gettime 产生。
~# strace -ce clock_gettime go run time_demo.go
Time taken: 138ns
Time taken: 94ns
Time taken: 73ns
Time taken: 88ns
Time taken: 87ns
Time taken: 83ns
Time taken: 93ns
Time taken: 78ns
Time taken: 93ns
Time taken: 99ns上面是正常性能机器的结果,耗时是纳秒级别的,快了几个量级。并且没有任何系统调用产生。可以想象一下,每个请求,不同模块都要做大量的 P99 统计,如果 time.Now 自身耗时这么大那这个服务基本不可用了。
有问题机器系统调用函数样子如下:
clock_gettime(CLOCK_MONOTONIC, {tv_sec=857882, tv_nsec=454310014}) = 0
测试内核是 5.4.0-1038
time.Now()
来看一下 go time.Now 的实现
// src/runtime/timestub.go
//go:linkname time_now time.now
func time_now() (sec int64, nsec int32, mono int64) {
sec, nsec = walltime()
return sec, nsec, nanotime()
}time 只暴露了函数的定义,实现是由底层不同平台的汇编实现,暂时只关注 amd64, 来看下汇编代码
// src/runtime/sys_linux_amd64.s
// func walltime1() (sec int64, nsec int32)
// non-zero frame-size means bp is saved and restored
TEXT runtime·walltime1(SB),NOSPLIT,$8-12
......
noswitch:
SUBQ $16, SP // Space for results
ANDQ $~15, SP // Align for C code
MOVQ runtime·vdsoClockgettimeSym(SB), AX
......那么问题来了,vdso 是什么?
系统调用
首先说,大家都知道系统调用慢,涉及陷入内核,上下文开销。但是到底多慢呢?
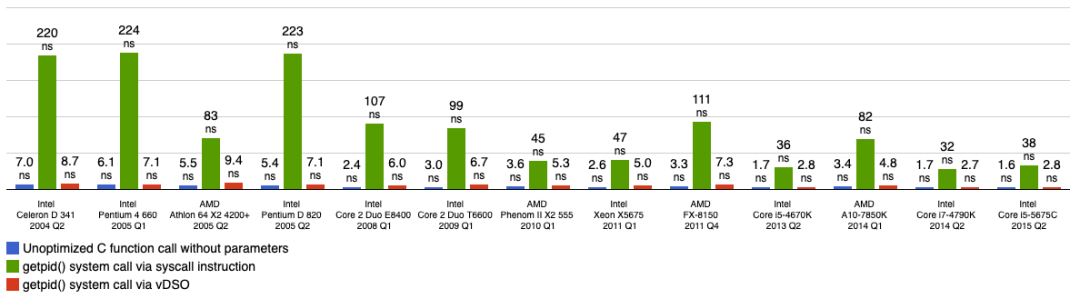
上图是系统调用和普通函数调用的开销对比,参考 [Measurements of system call performance and overhead](http://arkanis.de/weblog/2017-01-05-measurements-of-system-call-performance-and-overhead, Measurements of system call performance and overhead), 可以看到,getpid 走系统调用的开销远大于通过 vdso 的方式,而且也远大于普通函数调用。
vdso (virtual dynamic shared object) 参考 vdso man7[3], 本质上来说,还是因为系统调用太慢,涉及到上下文切换,少部分频繁使用的系统调用贡献了大部分时间。所以把这部分,不涉及安全的从内核空间,映射到用户空间。
x86-64 functions
The table below lists the symbols exported by the vDSO. All of
these symbols are also available without the "__vdso_" prefix,
but you should ignore those and stick to the names below.
symbol version
─────────────────────────────────
__vdso_clock_gettime LINUX_2.6
__vdso_getcpu LINUX_2.6
__vdso_gettimeofday LINUX_2.6
__vdso_time LINUX_2.6上面就是 x86 支持 vdso 的函数,一共 4 个?不可能这么少吧?来看一下线上真实情况的
~# uname -a
Linux 5.4.0-1041-aws #43~18.04.1-Ubuntu SMP Sat Mar 20 15:47:52 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux
~# cat /proc/self/maps | grep -i vdso
7fff2edff000-7fff2ee00000 r-xp 00000000 00:00 0 [vdso]内核版本是 5.4.0, 通过 maps 找到当前进程的vdso, 权限是r-xp,可读可执行但不可写,我们可以直接把他dump出来看看。先在另一个 session 执行 cat, 等待输入,然后用 gdb attach
~# ps aux | grep cat
root 9869 0.0 0.0 9360 792 pts/1 S+ 02:18 0:00 cat
root 9931 0.0 0.0 16152 1100 pts/0 S+ 02:18 0:00 grep --color=auto cat~# cat /proc/9869/maps | grep -i vdso
7ffe717e6000-7ffe717e7000 r-xp 00000000 00:00 0 [vdso]
~# gdb /bin/cat 9869
...........
(gdb) dump memory /tmp/vdso.so 0x7ffe717e6000 0x7ffe717e7000
(gdb) quit再查看符号表
~# file /tmp/vdso.so
/tmp/vdso.so: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, BuildID[sha1]=17d65245b85cd032de7ab130d053551fb0bd284a, stripped
~# objdump -T /tmp/vdso.so
/tmp/vdso.so: file format elf64-x86-64
DYNAMIC SYMBOL TABLE:
0000000000000950 w DF .text 00000000000000a1 LINUX_2.6 clock_gettime
00000000000008a0 g DF .text 0000000000000083 LINUX_2.6 __vdso_gettimeofday
0000000000000a00 w DF .text 000000000000000a LINUX_2.6 clock_getres
0000000000000a00 g DF .text 000000000000000a LINUX_2.6 __vdso_clock_getres
00000000000008a0 w DF .text 0000000000000083 LINUX_2.6 gettimeofday
0000000000000930 g DF .text 0000000000000015 LINUX_2.6 __vdso_time
0000000000000930 w DF .text 0000000000000015 LINUX_2.6 time
0000000000000950 g DF .text 00000000000000a1 LINUX_2.6 __vdso_clock_gettime
0000000000000000 g DO *ABS* 0000000000000000 LINUX_2.6 LINUX_2.6
0000000000000a10 g DF .text 000000000000002a LINUX_2.6 __vdso_getcpu
0000000000000a10 w DF .text 000000000000002a LINUX_2.6 getcpu为什么这么麻烦呢?因为这个 vdso.so 是在内存中维护的,并不像其它 so 动态库一样有对应的文件。
说了这么多,所以问题来了,为什么有了 vdso, 获取时间还要走系统调用呢???
时钟源
关于时钟源,下面的引用来自于 muahao
内核在启动过程中会根据既定的优先级选择时钟源。优先级的排序根据时钟的精度与访问速度。其中CPU中的TSC寄存器是精度最高(与CPU最高主频等同),访问速度最快(只需一条指令,一个时钟周期)的时钟源,因此内核优选TSC作为计时的时钟源。其它的时钟源,如HPET, ACPI-PM,PIT等则作为备选。但是,TSC不同与HPET等时钟,它的频率不是预知的。因此,内核必须在初始化过程中,利用HPET,PIT等始终来校准TSC的频率。如果两次校准结果偏差较大,则认为TSC是不稳定的,则使用其它时钟源。并打印内核日志:Clocksource tsc unstable.
正常来说,TSC的频率很稳定且不受CPU调频的影响(如果CPU支持constant-tsc)。内核不应该侦测到它是unstable的。但是,计算机系统中存在一种名为SMI(System Management Interrupt)的中断,该中断不可被操作系统感知和屏蔽。如果内核校准TSC频率的计算过程quick_ pit_ calibrate ()被SMI中断干扰,就会导致计算结果偏差较大(超过1%),结果是tsc基准频率不准确。最后导致机器上的时间戳信息都不准确,可能偏慢或者偏快。
当内核认为TSC unstable时,切换到HPET等时钟,不会给你的系统带来过大的影响。当然,时钟精度或访问时钟的速度会受到影响。通过实验测试,访问HPET的时间开销为访问TSC时间开销的7倍左右。如果您的系统无法忍受这些,可以尝试以下解决方法:在内核启动时,加入启动参数:tsc=reliable
内核实现
1. 各类时钟源注册
参考 linux insides[4] timers 一节,可以看到各个时钟源调用 clocksource_register_khz 进行注册,分别看 tsc 和 xen
static int __init init_tsc_clocksource(void)
{
......
if (boot_cpu_has(X86_FEATURE_TSC_KNOWN_FREQ)) {
if (boot_cpu_has(X86_FEATURE_ART))
art_related_clocksource = &clocksource_tsc;
clocksource_register_khz(&clocksource_tsc, tsc_khz);
......
}
static struct clocksource clocksource_tsc = {
.name = "tsc",
.rating = 300,
.read = read_tsc,
.mask = CLOCKSOURCE_MASK(64),
.flags = CLOCK_SOURCE_IS_CONTINUOUS |
CLOCK_SOURCE_VALID_FOR_HRES |
CLOCK_SOURCE_MUST_VERIFY,
.archdata = { .vclock_mode = VCLOCK_TSC },
.resume = tsc_resume,
.mark_unstable = tsc_cs_mark_unstable,
.tick_stable = tsc_cs_tick_stable,
.list = LIST_HEAD_INIT(clocksource_tsc.list),
};查看 clocksource_tsc 时钟源的 vclock_mode 是 VCLOCK_TSC
static void __init xen_time_init(void)
{
......
clocksource_register_hz(&xen_clocksource, NSEC_PER_SEC);
......
}
static void xen_setup_vsyscall_time_info(void)
{
......
xen_clocksource.archdata.vclock_mode = VCLOCK_PVCLOCK;
}查看 xen 时钟源的 vclock_mode 是 VCLOCK_PVCLOCK
2. 时钟源与 timekeeper
那么问题来了,clocksource 是如何与 vdso_data 关联的呢?这里面比较复杂,参考 linux内核中的定时器和时间管理[5] 和 vdso段数据更新, 定位到 /kernel/time/tick-common.c 的 timekeeping_update 函数,由它负责将定时器更新到用户层的 vdso 区。
/* must hold timekeeper_lock */
static void timekeeping_update(struct timekeeper *tk, unsigned int action)
{
......
update_vsyscall(tk);
update_pvclock_gtod(tk, action & TK_CLOCK_WAS_SET);
......
}
void update_vsyscall(struct timekeeper *tk)
{
struct vdso_data *vdata = __arch_get_k_vdso_data();
struct vdso_timestamp *vdso_ts;
s32 clock_mode;
u64 nsec;
/* copy vsyscall data */
vdso_write_begin(vdata);
clock_mode = tk->tkr_mono.clock->vdso_clock_mode;
vdata[CS_HRES_COARSE].clock_mode = clock_mode;
vdata[CS_RAW].clock_mode = clock_mode;
/* CLOCK_REALTIME also required for time() */
vdso_ts = &vdata[CS_HRES_COARSE].basetime[CLOCK_REALTIME];
vdso_ts->sec = tk->xtime_sec;
vdso_ts->nsec = tk->tkr_mono.xtime_nsec;
/* CLOCK_REALTIME_COARSE */
vdso_ts = &vdata[CS_HRES_COARSE].basetime[CLOCK_REALTIME_COARSE];
vdso_ts->sec = tk->xtime_sec;
vdso_ts->nsec = tk->tkr_mono.xtime_nsec >> tk->tkr_mono.shift;
/* CLOCK_MONOTONIC_COARSE */
vdso_ts = &vdata[CS_HRES_COARSE].basetime[CLOCK_MONOTONIC_COARSE];
vdso_ts->sec = tk->xtime_sec + tk->wall_to_monotonic.tv_sec;
nsec = tk->tkr_mono.xtime_nsec >> tk->tkr_mono.shift;
nsec = nsec + tk->wall_to_monotonic.tv_nsec;
vdso_ts->sec += __iter_div_u64_rem(nsec, NSEC_PER_SEC, &vdso_ts->nsec);
/*
* Read without the seqlock held by clock_getres().
* Note: No need to have a second copy.
*/
WRITE_ONCE(vdata[CS_HRES_COARSE].hrtimer_res, hrtimer_resolution);
/*
* If the current clocksource is not VDSO capable, then spare the
* update of the high reolution parts.
*/
if (clock_mode != VDSO_CLOCKMODE_NONE)
update_vdso_data(vdata, tk);
__arch_update_vsyscall(vdata, tk);
vdso_write_end(vdata);
__arch_sync_vdso_data(vdata);
}
static void update_pvclock_gtod(struct timekeeper *tk)
{
struct pvclock_gtod_data *vdata = &pvclock_gtod_data;
u64 boot_ns;
boot_ns = ktime_to_ns(ktime_add(tk->tkr_mono.base, tk->offs_boot));
write_seqcount_begin(&vdata->seq);
/* copy pvclock gtod data */
vdata->clock.vclock_mode = tk->tkr_mono.clock->archdata.vclock_mode;
vdata->clock.cycle_last = tk->tkr_mono.cycle_last;
vdata->clock.mask = tk->tkr_mono.mask;
vdata->clock.mult = tk->tkr_mono.mult;
vdata->clock.shift = tk->tkr_mono.shift;
vdata->boot_ns = boot_ns;
vdata->nsec_base = tk->tkr_mono.xtime_nsec;
vdata->wall_time_sec = tk->xtime_sec;
write_seqcount_end(&vdata->seq);
}
static void update_pvclock_gtod(struct timekeeper *tk)
{
struct pvclock_gtod_data *vdata = &pvclock_gtod_data;
u64 boot_ns;
boot_ns = ktime_to_ns(ktime_add(tk->tkr_mono.base, tk->offs_boot));
write_seqcount_begin(&vdata->seq);
/* copy pvclock gtod data */
vdata->clock.vclock_mode = tk->tkr_mono.clock->archdata.vclock_mode;
vdata->clock.cycle_last = tk->tkr_mono.cycle_last;
vdata->clock.mask = tk->tkr_mono.mask;
vdata->clock.mult = tk->tkr_mono.mult;
vdata->clock.shift = tk->tkr_mono.shift;
vdata->boot_ns = boot_ns;
vdata->nsec_base = tk->tkr_mono.xtime_nsec;
vdata->wall_time_sec = tk->xtime_sec;
write_seqcount_end(&vdata->seq);
}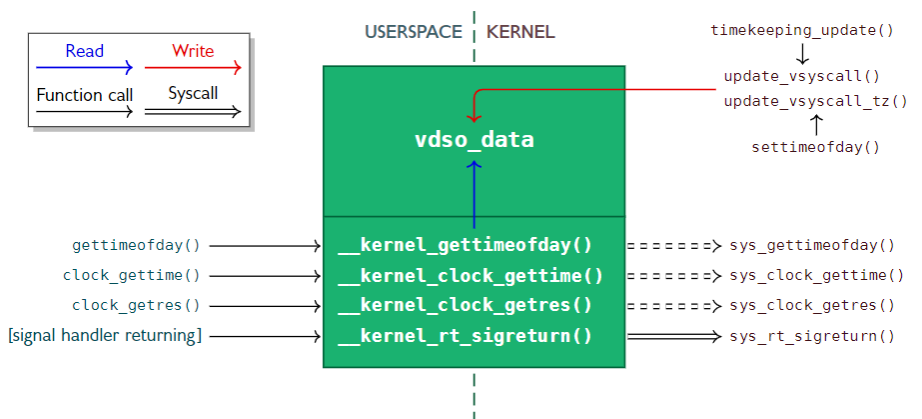
上面的截图来自 arm vdso 实现,和 x86 的类似。
然后再看一下 timekeeper 和 clocksource 是如何对应的呢?在 timekeeping_init 函数里
void __init timekeeping_init(void)
{
struct timespec64 wall_time, boot_offset, wall_to_mono;
struct timekeeper *tk = &tk_core.timekeeper;
struct clocksource *clock;
......
clock = clocksource_default_clock();
if (clock->enable)
clock->enable(clock);
tk_setup_internals(tk, clock);
...
}这是初始化时的函数,每当时钟源变更时,会调用 change_clocksource 切换。
3. 如何调用时间函数
// linux/lib/vdso/gettimeofday.c
static __maybe_unused int
__cvdso_clock_gettime(clockid_t clock, struct __kernel_timespec *ts)
{
int ret = __cvdso_clock_gettime_common(clock, ts);
if (unlikely(ret))
return clock_gettime_fallback(clock, ts);
return 0;
}static __always_inline
long clock_gettime_fallback(clockid_t _clkid, struct __kernel_timespec *_ts)
{
long ret;
asm ("syscall" : "=a" (ret), "=m" (*_ts) :
"0" (__NR_clock_gettime), "D" (_clkid), "S" (_ts) :
"rcx", "r11");
return ret;
}先直接看 fallback 逻辑,好嘛,直接是汇编的 syscall 调用,注意这里汇编是和平台相关的,这个代码是 x86. 这里 unlikely 是做分支预测的,后面的事情大概率不会发生,如果 ret 不为 0, 说明 vdso 获取时间失败,那么来看下什么时候 __cvdso_clock_gettime_common 会失败。
static __maybe_unused int
__cvdso_clock_gettime_common(clockid_t clock, struct __kernel_timespec *ts)
{
const struct vdso_data *vd = __arch_get_vdso_data();
u32 msk;
/* Check for negative values or invalid clocks */
if (unlikely((u32) clock >= MAX_CLOCKS))
return -1;
/*
* Convert the clockid to a bitmask and use it to check which
* clocks are handled in the VDSO directly.
*/
msk = 1U << clock;
if (likely(msk & VDSO_HRES)) {
return do_hres(&vd[CS_HRES_COARSE], clock, ts);
} else if (msk & VDSO_COARSE) {
do_coarse(&vd[CS_HRES_COARSE], clock, ts);
return 0;
} else if (msk & VDSO_RAW) {
return do_hres(&vd[CS_RAW], clock, ts);
}
return -1;
}这里只看 do_hres 实现
static int do_hres(const struct vdso_data *vd, clockid_t clk,
struct __kernel_timespec *ts)
{
const struct vdso_timestamp *vdso_ts = &vd->basetime[clk];
u64 cycles, last, sec, ns;
u32 seq;
do {
seq = vdso_read_begin(vd);
cycles = __arch_get_hw_counter(vd->clock_mode);
ns = vdso_ts->nsec;
last = vd->cycle_last;
if (unlikely((s64)cycles < 0))
return -1;
ns += vdso_calc_delta(cycles, last, vd->mask, vd->mult);
ns >>= vd->shift;
sec = vdso_ts->sec;
} while (unlikely(vdso_read_retry(vd, seq)));
/*
* Do this outside the loop: a race inside the loop could result
* in __iter_div_u64_rem() being extremely slow.
*/
ts->tv_sec = sec + __iter_div_u64_rem(ns, NSEC_PER_SEC, &ns);
ts->tv_nsec = ns;
return 0;
}__arch_get_hw_counter 会根据 clock_mode 求出 cycles 值,这是一个 u64 类型,如果转成 s64 为负数,那就返回 -1, 此时会触发 fallback 系统调用逻辑。
static inline u64 __arch_get_hw_counter(s32 clock_mode)
{
if (clock_mode == VCLOCK_TSC)
return (u64)rdtsc_ordered();
/*
* For any memory-mapped vclock type, we need to make sure that gcc
* doesn't cleverly hoist a load before the mode check. Otherwise we
* might end up touching the memory-mapped page even if the vclock in
* question isn't enabled, which will segfault. Hence the barriers.
*/
#ifdef CONFIG_PARAVIRT_CLOCK
if (clock_mode == VCLOCK_PVCLOCK) {
barrier();
return vread_pvclock();
}
#endif
#ifdef CONFIG_HYPERV_TIMER
if (clock_mode == VCLOCK_HVCLOCK) {
barrier();
return vread_hvclock();
}
#endif
return U64_MAX;
}static u64 vread_pvclock(void)
{
......
do {
version = pvclock_read_begin(pvti);
if (unlikely(!(pvti->flags & PVCLOCK_TSC_STABLE_BIT)))
return U64_MAX;
ret = __pvclock_read_cycles(pvti, rdtsc_ordered());
} while (pvclock_read_retry(pvti, version));
return ret;
}这里判断如果 flags 里没有 PVCLOCK_TSC_STABLE_BIT 标记,则返回 U64_MAX, 来看一下什么时候没有这个标记
static int kvm_guest_time_update(struct kvm_vcpu *v)
{
......
u64 tsc_timestamp, host_tsc;
struct kvm_arch *ka = &v->kvm->arch;
u8 pvclock_flags;
bool use_master_clock;
......
use_master_clock = ka->use_master_clock;
......
if (use_master_clock)
pvclock_flags |= PVCLOCK_TSC_STABLE_BIT;
}/*
*
* Assuming a stable TSC across physical CPUS, and a stable TSC
* across virtual CPUs, the following condition is possible.
* Each numbered line represents an event visible to both
* CPUs at the next numbered event.
*/
static void pvclock_update_vm_gtod_copy(struct kvm *kvm)
{
......
ka->use_master_clock = host_tsc_clocksource && vcpus_matched
&& !ka->backwards_tsc_observed
&& !ka->boot_vcpu_runs_old_kvmclock;
......
}也就是说,如果宿主机使用了 tsc clocksource, 并且没有观察到时钟回退现象,那么就设置 use_master_clock 为 true, 否则为 false.
所以问题来了,我们这台机器是机器学习 aws p3.2xlarge, 怀疑是和宿主机有关,试了下其它 c5 系列的都己经不支持 xen clocksource 了(仅支持 tsc kvm-clock acpi_pm),同时 kvm-clock 源测试也支持 vdso, 参考 官方玩转GPU实例 blog[6], 最新的虚拟化技术 Nitro 己经没有这个问题了。
分析来分析去,我可能分析个寂寞。。。
修复
当然对于老的硬件,或是内核还是有必要修复的
~# cat /sys/devices/system/clocksource/clocksource0/available_clocksource
xen tsc hpet acpi_pm
~# cat /sys/devices/system/clocksource/clocksource0/current_clocksource
xen查看当前时钟源是 xen, 只需要将 tsc 写入即可。
~# echo tsc > /sys/devices/system/clocksource/clocksource0/available_clocksource
但是还有种情况,就是内核将 tsc 标记为不可信 Clocksource tsc unstable, 这时只能重启内核了。或是在启动内核时,指定 tsc=reliable, 参考 manage-ec2-linux-clock-source[7]
GRUB_CMDLINE_LINUX="console=tty0 crashkernel=auto console=ttyS0,115200 clocksource=tsc tsc=reliable"
然后用 grub2-mkconfig -o /boot/grub2/grub.cfg 生成 grub.cfg 配置文件
小结
这次分享就这些,以后面还会分享更多的内容。
参考资料
[1][Go] Time.Now函数CPU使用率异常: https://mp.weixin.qq.com/s/D2ulLXDFpi0FwVRwSQJ0nA,
[2]Two frequently used system calls are ~77% slower on AWS EC2: https://blog.packagecloud.io/eng/2017/03/08/system-calls-are-much-slower-on-ec2/,
[3]vdso man7: https://man7.org/linux/man-pages/man7/vdso.7.html,
[4]linux insides: https://0xax.gitbooks.io/linux-insides/content/Timers/linux-timers-2.html,
[5]linux内核中的定时器和时间管理: https://garlicspace.com/2020/06/07/linux%E5%86%85%E6%A0%B8%E4%B8%AD%E7%9A%84%E5%AE%9A%E6%97%B6%E5%99%A8%E5%92%8C%E6%97%B6%E9%97%B4%E7%AE%A1%E7%90%86-part-7/,
[6]官方玩转GPU实例 blog: https://aws.amazon.com/cn/blogs/china/using-rekognition-realize-serverless-intelligent-album-playing-with-gpu-instance-iii-system-optimization/,
[7]manage-ec2-linux-clock-source: https://aws.amazon.com/premiumsupport/knowledge-center/manage-ec2-linux-clock-source/,