赏析Singleflight设计
前言
今天想与大家分享一下
singleflight这个库,singleflight仅仅只有100多行却可以做到防止缓存击穿,有点厉害哦!所以本文我们就一起来看一看他是怎么设计的~。注意:本文基于 https://pkg.go.dev/golang.org/x/sync/singleflight进行分析。
缓存击穿
什么是缓存击穿
平常在高并发系统中,会出现大量的请求同时查询一个
key的情况,假如此时这个热key刚好失效了,就会导致大量的请求都打到数据库上面去,这种现象就是缓存击穿。缓存击穿和缓存雪崩有点像,但是又有一点不一样,缓存雪崩是因为大面积的缓存失效,打崩了DB,而缓存击穿则是指一个key非常热点,在不停的扛着高并发,高并发集中对着这一个点进行访问,如果这个key在失效的瞬间,持续的并发到来就会穿破缓存,直接请求到数据库,就像一个完好无损的桶上凿开了一个洞,造成某一时刻数据库请求量过大,压力剧增!
如何解决
-
方法一
我们简单粗暴点,直接让热点数据永远不过期,定时任务定期去刷新数据就可以了。不过这样设置需要区分场景,比如某宝首页可以这么做。
-
方法二
为了避免出现缓存击穿的情况,我们可以在第一个请求去查询数据库的时候对他加一个互斥锁,其余的查询请求都会被阻塞住,直到锁被释放,后面的线程进来发现已经有缓存了,就直接走缓存,从而保护数据库。但是也是由于它会阻塞其他的线程,此时系统吞吐量会下降。需要结合实际的业务去考虑是否要这么做。
-
方法三
方法三就是singleflight的设计思路,也会使用互斥锁,但是相对于方法二的加锁粒度会更细,这里先简单总结一下singleflight的设计原理,后面看源码在具体分析。
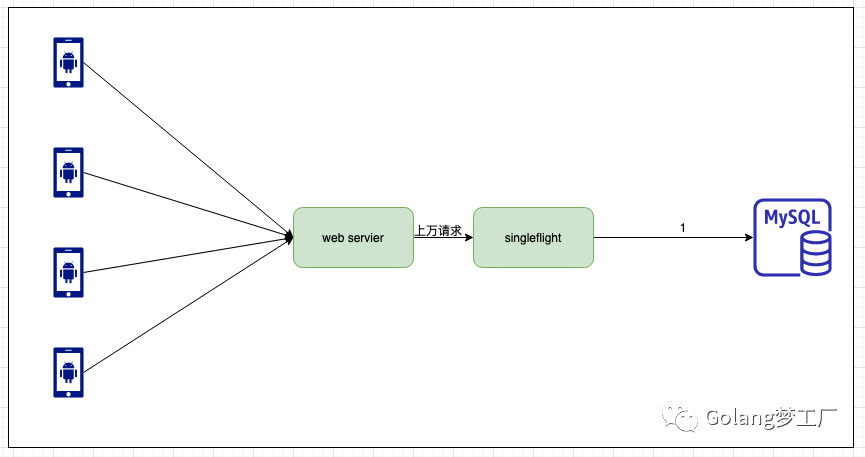
singleflightd的设计思路就是将一组相同的请求合并成一个请求,使用
map存储,只会有一个请求到达mysql,使用sync.waitgroup包进行同步,对所有的请求返回相同的结果。
 截屏2021-07-14 下午8.30.56
源码赏析
截屏2021-07-14 下午8.30.56
源码赏析
已经迫不及待了,直奔主题吧,下面我们一起来看看singleflight是怎么设计的。
数据结构
singleflight的结构定义如下:
type Group struct {
mu sync.Mutex // 互斥锁,保证并发安全
m map[string]*call // 存储相同的请求,key是相同的请求,value保存调用信息。
}Group结构还是比较简单的,只有两个字段,m是一个map,key是相同请求的标识,value是用来保存调用信息,这个map是懒加载,其实就是在使用时才会初始化;mu是互斥锁,用来保证m的并发安全。m存储调用信息也是单独封装了一个结构:
type call struct {
wg sync.WaitGroup
// 存储返回值,在wg done之前只会写入一次
val interface{}
// 存储返回的错误信息
err error
// 标识别是否调用了Forgot方法
forgotten bool
// 统计相同请求的次数,在wg done之前写入
dups int
// 使用DoChan方法使用,用channel进行通知
chans []chan<- Result
}
// Dochan方法时使用
type Result struct {
Val interface{} // 存储返回值
Err error // 存储返回的错误信息
Shared bool // 标示结果是否是共享结果
}Do方法
// 入参:key:标识相同请求,fn:要执行的函数
// 返回值:v: 返回结果 err: 执行的函数错误信息 shard: 是否是共享结果
func (g *Group) Do(key string, fn func() (interface{}, error)) (v interface{}, err error, shared bool) {
// 代码块加锁
g.mu.Lock()
// map进行懒加载
if g.m == nil {
// map初始化
g.m = make(map[string]*call)
}
// 判断是否有相同请求
if c, ok := g.m[key]; ok {
// 相同请求次数+1
c.dups++
// 解锁就好了,只需要等待执行结果了,不会有写入操作了
g.mu.Unlock()
// 已有请求在执行,只需要等待就好了
c.wg.Wait()
// 区分panic错误和runtime错误
if e, ok := c.err.(*panicError); ok {
panic(e)
} else if c.err == errGoexit {
runtime.Goexit()
}
return c.val, c.err, true
}
// 之前没有这个请求,则需要new一个指针类型
c := new(call)
// sync.waitgroup的用法,只有一个请求运行,其他请求等待,所以只需要add(1)
c.wg.Add(1)
// m赋值
g.m[key] = c
// 没有写入操作了,解锁即可
g.mu.Unlock()
// 唯一的请求该去执行函数了
g.doCall(c, key, fn)
return c.val, c.err, c.dups > 0
}这里是唯一有疑问的应该是区分panic和runtime错误部分吧,这个与下面的docall方法有关联,看完docall你就知道为什么了。
docall
// doCall handles the single call for a key.
func (g *Group) doCall(c *call, key string, fn func() (interface{}, error)) {
// 标识是否正常返回
normalReturn := false
// 标识别是否发生panic
recovered := false
defer func() {
// 通过这个来判断是否是runtime导致直接退出了
if !normalReturn && !recovered {
// 返回runtime错误信息
c.err = errGoexit
}
c.wg.Done()
g.mu.Lock()
defer g.mu.Unlock()
// 防止重复删除key
if !c.forgotten {
delete(g.m, key)
}
// 检测是否出现了panic错误
if e, ok := c.err.(*panicError); ok {
// 如果是调用了dochan方法,为了channel避免死锁,这个panic要直接抛出去,不能recover住,要不就隐藏错误了
if len(c.chans) > 0 {
go panic(e) // 开一个写成panic
select {} // 保持住这个goroutine,这样可以将panic写入crash dump
} else {
panic(e)
}
} else if c.err == errGoexit {
// runtime错误不需要做任何时,已经退出了
} else {
// 正常返回的话直接向channel写入数据就可以了
for _, ch := range c.chans {
ch <- Result{c.val, c.err, c.dups > 0}
}
}
}()
// 使用匿名函数目的是recover住panic,返回信息给上层
func() {
defer func() {
if !normalReturn {
// 发生了panic,我们recover住,然后把错误信息返回给上层
if r := recover(); r != nil {
c.err = newPanicError(r)
}
}
}()
// 执行函数
c.val, c.err = fn()
// fn没有发生panic
normalReturn = true
}()
// 判断执行函数是否发生panic
if !normalReturn {
recovered = true
}
}这里来简单描述一下为什么区分panic和runtime错误,不区分的情况下如果调用出现了恐慌,但是锁没有被释放,会导致使用相同key的所有后续调用都出现了死锁,具体可以查看这个issue:https://github.com/golang/go/issues/33519。
Dochan和Forget方法
//异步返回
// 入参数:key:标识相同请求,fn:要执行的函数
// 出参数:<- chan 等待接收结果的channel
func (g *Group) DoChan(key string, fn func() (interface{}, error)) <-chan Result {
// 初始化channel
ch := make(chan Result, 1)
g.mu.Lock()
// 懒加载
if g.m == nil {
g.m = make(map[string]*call)
}
// 判断是否有相同的请求
if c, ok := g.m[key]; ok {
//相同请求数量+1
c.dups++
// 添加等待的chan
c.chans = append(c.chans, ch)
g.mu.Unlock()
return ch
}
c := &call{chans: []chan<- Result{ch}}
c.wg.Add(1)
g.m[key] = c
g.mu.Unlock()
// 开一个写成调用
go g.doCall(c, key, fn)
// 返回这个channel等待接收数据
return ch
}
// 释放某个 key 下次调用就不会阻塞等待了
func (g *Group) Forget(key string) {
g.mu.Lock()
if c, ok := g.m[key]; ok {
c.forgotten = true
}
delete(g.m, key)
g.mu.Unlock()
}注意事项
因为我们在使用singleflight时需要自己写执行函数,所以如果我们写的执行函数一直循环住了,就会导致我们的整个程序处于循环的状态,积累越来越多的请求,所以在使用时,还是要注意一点的,比如这个例子:
result, err, _ := d.singleGroup.Do(key, func() (interface{}, error) {
for{
// TODO
}
} 不过这个问题一般也不会发生,我们在日常开发中都会使用context控制超时。
总结
好啦,这篇文章就到这里啦。因为最近我在项目中也使用singleflight这个库,所以就看了一下源码实现,真的是厉害,这么短的代码就实现了这么重要的功能,我怎么就想不到呢。。。。所以说还是要多读一些源码库,真的能学到好多,真是应了那句话:你知道的越多,不知道的就越多!