Electron / Chromium 屏幕录制 - 那些我踩过的坑
背景
Web 屏幕录制也许对我们来说并不陌生,最常见的场景,例如:各种视频会议、远程桌面软件,远程会议软件的出现大大方便了人们的交流与沟通,在 WFH 期间对众多企业的线上运转起到关键的作用。除了屏幕的实时分享,录屏的应用还存在另一种应用场景,即“记录实时操作并保留现场,方便后续追溯与回放”,即是我们业务的主要场景。对于我们的业务,强依赖该功能的稳定性。以下是我们业务对该功能的一些硬性指标:
指标要求
- 支持任意时长的录制,支持超过 6 小时时长的录制。
- 支持同时录音。在录屏同时录制到屏幕中正在播放的内容的声音。
- 支持跨平台,兼容 Windows、Mac、Linux 三个平台。
- 支持在 App 从 A 窗口拖拽到 B 窗口时持续录制。
- 支持在最小化,最大化,全屏时保持录屏,且录制范围仅在 App 内部,不可录制到 App 外。
- 支持长时间,不间断,不关闭 App 的情况下可以不断录制。
- 支持在无需完整下载录屏的情况下,在 Web 端随意拖拽时间线。
- 支持 App 多标签页切换情况下,对多标签页的同时录制。
- 支持 App 多开窗口在同一个系统窗口内,同时录制 App 窗口。
- 支持直播实时流的录制。
- 录屏文件不能存储在本地,录制结束后必须自动上传并加密存储。
技术方案探索
目前 Chromium 端上视频直接录制,一般来说有两种技术方案,即:rrweb 方案、以及 WebRTC API 方案。如果考虑 Electron 场景,又会额外多出一种 ffmpeg 的方案。
rrweb
优势
- 支持在录屏的同时直接录制到当前 Tab 内的声音。
- 跨平台兼容。
- 支持窗口的拖拽、最小化、最大化、全屏等情况的持续录制。
- 录屏尺寸小。
- 支持在无需完整下载录屏的情况下,在 Web 端随意拖拽时间线。
- 性能较好。
劣势
- 无法录制直播实时流。考虑其实现原理,录屏场景有限。
- 不支持在关闭 App 标签页的情况录制,如果 Renderer 进程关闭,则会直接终止录制并丢失录屏。
- 某些场景会对页面 DOM 有影响。
ffmpeg
优势
- 同等体积,录屏文件的输出质量好。
- 性能好。
- 支持录制直播实时流。
劣势
- 跨平台兼容处理复杂。
- 录制区域非动态,虽支持选区,但若 App 移动则无能为力的录制到屏幕外内容。
- 不支持 App 多标签页切换情况下,对多标签页进行暂停或继续。
- 支持在 App 从 A 窗口拖拽到 B 窗口时持续对 App 录制。
- 录屏文件中间时间会存储在本地,若 App 关闭后会导致录屏文件的暴露。
- 不支持 App 多开窗口情况下的,且在同时录制。
webRTC
优势
- 支持全部指标 1-11。
劣势
- 性能较差,录制时 CPU 占用率相对较高。
- 原生录制的视频文件,没有视频时长。
- 原生录制的视频文件,不支持时间线拖拽。
- 原生不支持超长时长的录制,若录屏文件大于磁盘空间的 1/10 会报错。
- 原生录制会有较大的内存占用。
- 视频删除依赖 V8 与 Blob 实现的垃圾回收机制,非常容易内存泄露。
考虑到 rrweb 较好的性能,最初我们第一版实际上是基于 rrweb 实现的,但 rrweb 的原生硬伤最终导致我们放弃该方案,比如如果用户关闭窗口会直接导致录屏丢失是不可接受的,其次 rrweb 不支持直播实时流是我们最终放弃他的根本原因。此外考虑到 ffmpeg 的种种限制,以及我们自身的指标要求,最终我们选择了 webRTC API 直接录制的方案实现了录屏功能,并在后续踩了一些列的坑,一下是一些分享。
媒体流的获取
在 WebRTC 标准中,一切持续不断产生媒体的起点,都被抽象成媒体流,例如我们需要录制屏幕与声音,其实现的关键就是找到需要录制屏幕的源和录制音频的源,整体的流程如下图所示:
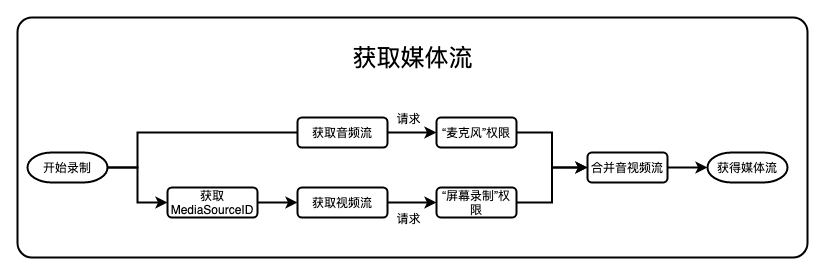
视频流获取
想获取视频流,首先需要获取所需要捕获视频流的 MediaSourceId。Electron 提供了一个获取各个“窗口”和“屏幕”视频 MediaSourceId 的通用 API
import { desktopCapturer } from 'electron';
// 获取全部窗口或屏幕的mediaSourceId
desktopCapturer.getSources({
types: ['screen', 'window'], // 设定需要捕获的是"屏幕",还是"窗口"
thumbnailSize: {
height: 300, // 窗口或屏幕的截图快照高度
width: 300 // 窗口或屏幕的截图快照宽度
},
fetchWindowIcons: true // 如果视频源是窗口且有图标,则设置该值可以捕获到的窗口图标
}).then(sources => {
sources.forEach(source => {
// 如果视频源是窗口且有图标,且fetchWindowIcons设为true,则为捕获到的窗口图标
console.log(source.appIcon);
// 显示器Id
console.log(source.display_id);
// 视频源的mediaSourceId,可通过该mediaSourceId获取视频源
console.log(source.id);
// 窗口名,通常来说与任务管理器看到的进程名一致
console.log(source.name);
// 窗口或屏幕在调用本API瞬间抓捕到的截图快照
console.log(source.thumbnail);
});
});如果你只想获取当前窗口的 MediaSourceID
import { remote } from 'electron';
// 获取当前窗口mediaSourceId的做法
const mediaSourceId = remote.getCurrentWindow().getMediaSourceId();在获取到 mediaSourceId 后,继续获取视频流,方法如下:
import { remote } from 'electron';
// 视频流获取
const videoSource: MediaStream = await navigator.mediaDevices.getUserMedia({
audio: false, // 强行表示不录制音频,音频额外获取
video: {
mandatory: {
chromeMediaSource: 'desktop',
chromeMediaSourceId: remote.getCurrentWindow().getMediaSourceId()
}
}
});其中如果获取的视频源是整个桌面窗口,且操作系统如果是 macOS,还要授权“屏幕录制权限”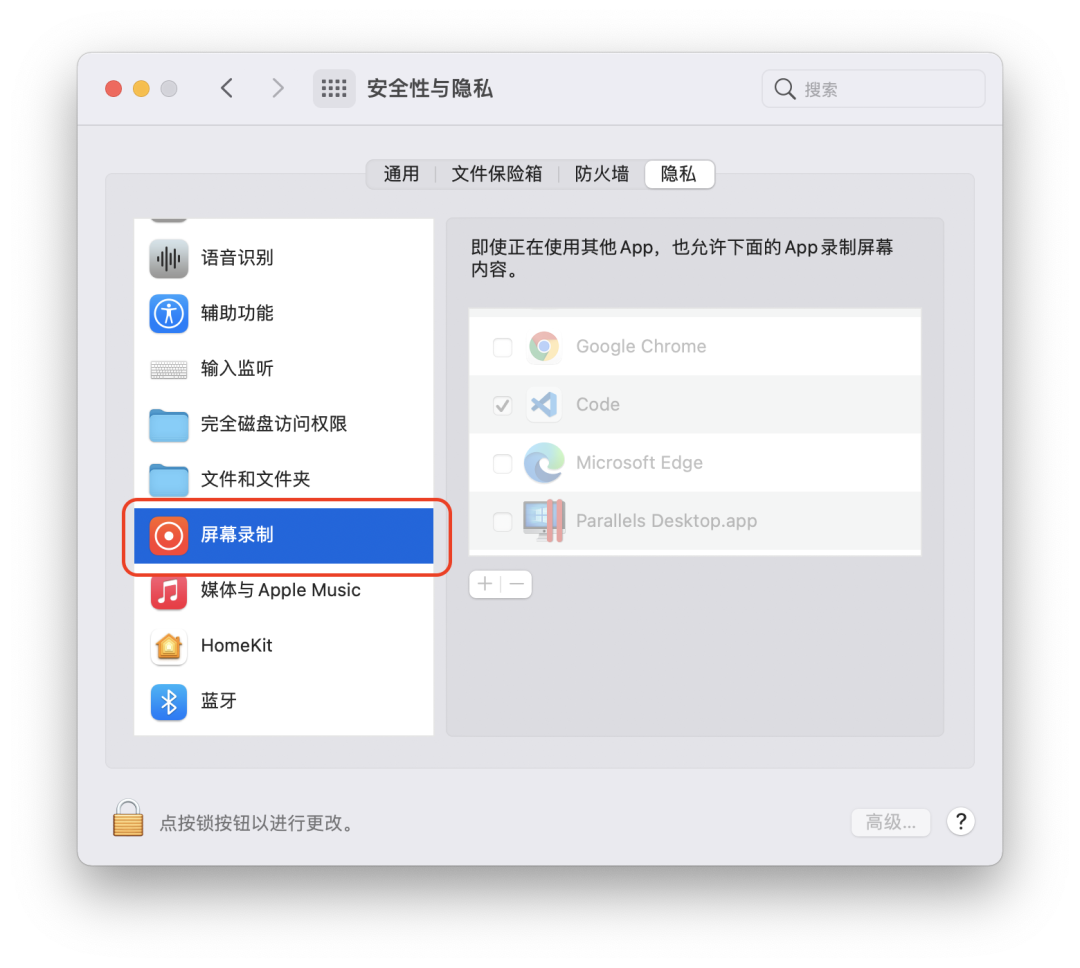
音频源获取
不同于视频源的轻松获取,音频源的获取着实有些复杂,针对 macOS 和 Windows 系统,需要分别处理两种获取方式。首先,在 Windows 获取屏幕音频非常简单且容易,且不需要任何授权,因此这里如果大家需要录制音频,一定要做好权限提示、
// Windows音频流获取
const audioSource: MediaStream = await navigator.mediaDevices.getUserMedia({
audio: {
mandatory: {
// 无需指定mediaSourceId就可以录音了,录得是系统音频
chromeMediaSource: 'desktop',
},
},
// 如果想要录制音频,必须同样把视频的选项带上,否则会失败
video: {
mandatory: {
chromeMediaSource: 'desktop',
},
},
});
// 接着手工移除点不用的视频源,即可完成音频流的获取
(audioSource.getVideoTracks() || []).forEach(track => audioSource.removeTrack(track));接着,再看 macOS 音频流的获取,这里就有一些难度了,由于 macOS 的音频权限设定(参考[1]),任何人都没办法直接录制系统音频,除非安装第三方驱动 Kext,比如 soundFlower 或者 blackHole,由于 blackHole 同时支持 arm64 M1 处理器和 x64 Intel 处理器(参考[2]),因此我们最终选择 blackHole 的方式获取系统音频。那么在引导用户安装 BlackHole 前,我们需要先检查当前的安装状况,如果用户没有安装过,则提示其安装,如果安装过则继续,这里的方式如下:
import { remote } from 'electron';
const isWin = process.platform === 'win32';
const isMac = process.platform === 'darwin';
declare type AudioRecordPermission =
| 'ALLOWED'
| 'RECORD_PERMISSION_NOT_GRANTED'
| 'NOT_INSTALL_BLACKHOLE'
| 'OS_NOT_SUPPORTED';
// 检查用户电脑是否有安装SoundFlower或者BlackHole
async function getIfAlreadyInstallSoundFlowerOrBlackHole(): Promise<boolean> {
const devices = await navigator.mediaDevices.enumerateDevices();
return devices.some(
device => device.label.includes('Soundflower (2ch)') || device.label.includes('BlackHole 2ch (Virtual)')
);
}
// 获取是否有麦克风权限(blackhole的实现方式是将屏幕音频模拟为麦克风)
function getMacAudioRecordPermission(): 'not-determined' | 'granted' | 'denied' | 'restricted' | 'unknown' {
return remote.systemPreferences.getMediaAccessStatus('microphone');
}
// 请求麦克风权限(blackhole的实现方式是将屏幕音频模拟为麦克风)
function requestMacAudioRecordPermission(): Promise<boolean> {
return remote.systemPreferences.askForMediaAccess('microphone');
}
async function getAudioRecordPermission(): Promise<AudioRecordPermission> {
if (isWin) {
// Windows直接支持
return 'ALLOWED';
} else if (isMac) {
if (await getIfAlreadyInstallSoundFlowerOrBlackHole()) {
if (getMacAudioRecordPermission() !== 'granted') {
if (!(await requestMacAudioRecordPermission())) {
return 'RECORD_PERMISSION_NOT_GRANTED';
}
}
return 'ALLOWED';
}
return 'NOT_INSTALL_BLACKHOLE';
} else {
// Linux暂时还不支持录制音频
return 'OS_NOT_SUPPORTED';
}
}此外,Electron 应用必须在 info.plist 中声明自己需要用到音频录制权限,才可以录制音频,以 Electron-builder 打包流程为例:
// 添加electron-builder配置
const createMac = () => ({
...commonConfig,
// 声明afterPack钩子函数,用于处理音频授权时的i18n
afterPack: 'scripts/macAfterPack.js',
mac: {
...commonMacConfig,
// 必须指定entitlements.mac.plist用于签名时的权限声明
entitlements: 'scripts/entitlements.mac.plist',
// 必须限制运行时为"hardened",以使应用通过natorize公证
hardenedRuntime: true,
extendInfo: {
// 为info.plist添加多语言支持
LSHasLocalizedDisplayName: true,
}
}
});为了获取音频录制权限,需要自定义 entitlements.mac.plist,并声明以下四个变量:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>com.apple.security.cs.allow-jit</key>
<true/>
<key>com.apple.security.cs.allow-unsigned-executable-memory</key>
<true/>
<key>com.apple.security.cs.allow-dyld-environment-variables</key>
<true/>
<key>com.apple.security.device.audio-input</key>
<true/>
</dict>
</plist>为了使音频录制前的“麦克风授权”提示支持多语言,我们这里手动添加以下自定义文字到每个语言的.lproj/InfoPlist.strings 文件内:
// macAfterPack.js
const fs = require('fs');
// 用于存储到xxx.lproj/InfoPlist.strings的的i18n文字
const i18nNSStrings = {
en: {
NSMicrophoneUsageDescription: 'Please allow this program to access your system audio',
},
ja: {
NSMicrophoneUsageDescription: 'このプログラムがシステムオーディオにアクセスして録音することを許可してください',
},
th: {
NSMicrophoneUsageDescription: 'โปรดอนุญาตให้โปรแกรมนี้เข้าถึงและบันทึกเสียงระบบของคุณ',
},
ko: {
NSMicrophoneUsageDescription: '이 프로그램이 시스템 오디오에 액세스하고 녹음 할 수 있도록 허용하십시오',
},
zh_CN: {
NSMicrophoneUsageDescription: '请允许本程序访问录制您的系统音频',
},
};
exports.default = async context => {
const { electronPlatformName, appOutDir } = context;
if (electronPlatformName !== 'darwin') {
return;
}
const productFilename = context.packager.appInfo.productFilename;
const resourcesPath = `${appOutDir}/${productFilename}.app/Contents/Resources/`;
console.log(
`[After Pack] start create i18n NSString bundle, productFilename: ${productFilename}, resourcesPath: ${resourcesPath}`
);
return Promise.all(
Object.keys(i18nNSStrings).map(langKey => {
const infoPlistStrPath = `${langKey}.lproj/InfoPlist.strings`;
let infos = '';
const langItem = i18nNSStrings[langKey];
Object.keys(langItem).forEach(infoKey => {
infos += `"${infoKey}" = "${langItem[infoKey]}";\n`;
});
return new Promise(resolve => {
const filePath = `${resourcesPath}${infoPlistStrPath}`;
fs.writeFile(filePath, infos, err => {
resolve();
if (err) {
throw err;
}
console.log(`[After Pack] ${filePath} create success`);
});
});
})
);
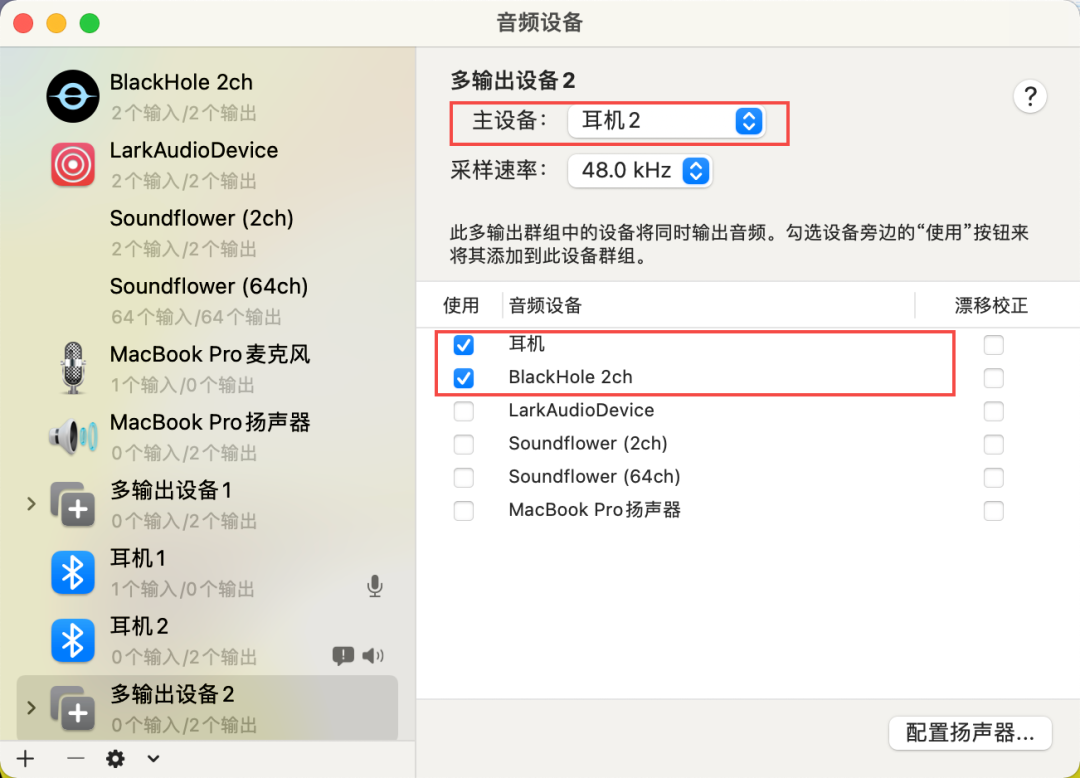
};以上,可以完成最基本的 macOS 音频录制能力权限。接着,以 Blackhole 安装过程为例如下图:

if (process.platform === 'darwin') {
const permission = await getAudioRecordPermission();
switch (permission) {
case 'ALLOWED':
const devices = await navigator.mediaDevices.enumerateDevices();
const outputdevices = devices.filter(
_device => _device.kind === 'audiooutput' && _device.deviceId !== 'default'
);
const soundFlowerDevices = outputdevices.filter(_device => _device.label === 'Soundflower (2ch)');
const blackHoleDevices = outputdevices.filter(_device => _device.label === 'BlackHole 2ch (Virtual)');
// 如果用户安装soundFlower或者blackhole,则按优先级获取deviceId
const deviceId = soundFlowerDevices.length ?
soundFlowerDevices[0].deviceId :
blackHoleDevices.length ?
blackHoleDevices[0].deviceId :
null;
if (deviceId) {
// 当获取到可使用的deviceId时,抓取音频流
const audioSource = await navigator.mediaDevices.getUserMedia({
audio: {
deviceId: {
exact: deviceId, // 根据获取到的deviceId,获取音频流
},
sampleRate: 44100,
// 这里的三个参数都关闭可以获得最原始的音频
// 否则Chromium默认会对音频做一些处理
echoCancellation: false,
noiseSuppression: false,
autoGainControl: false,
},
video: false,
});
}
break;
case 'NOT_INSTALL_BLACKHOLE':
// 这里做一些提示,告知用户没有安装插件
break;
case 'RECORD_PERMISSION_NOT_GRANTED':
// 这里做一些提示,告知用户没有授权
break;
default:
break;
}
}以上,虽然有些许繁琐,但是!至少!我们可以同时录制 Windows 和 macOS 的音频啦~如果正确配置好,执行上述代码后,会弹出如图所示的原生授权弹窗:
合并音视频流
在以上步骤执行后,我们便可以合并两个流,提取各自的轨道,完成一个新的 MediaStream 的创建。
// 合并音频流与视频流
const combinedSource = new MediaStream([...this._audioSource.getAudioTracks(), ...this._videoSource.getVideoTracks()]);媒体流的录制
编码格式
我们已经有了录制源,但没有创建录制 = 没有开始录,Chromium 提供了一个叫做 MediaRecorder 的类,用于我们传入媒体流并录制视频,因此如何创建 MediaRecorder 并发起录制,是录屏的核心。MediaRecorder 本身支持仅支持录制 webm 格式,但支持多种编码格式,例如:vp8、vp9、h264 等,MediaRecorder 贴心的提供了一个 API,方便我们测试编码格式兼容性
let types: string[] = [
"video/webm",
"audio/webm",
"video/webm;codecs=vp9",
"video/webm;codecs=vp8",
"video/webm;codecs=daala",
"video/webm;codecs=h264",
"audio/webm;codecs=opus",
"video/mpeg"
];
for (let i in types) {
// 可以自行测试需要的编码的MIME Type是否支持
console.log( "Is " + types[i] + " supported? " + (MediaRecorder.isTypeSupported(types[i]) ? "Yes" : "No :("));
}经测试,以上编码格式录制时的 CPU 占用并没有什么本质区别,因此建议直接选 VP9 录。
创建录制
确定好编码,并合并好音视频流,我们可以真正开始录制了:
const recorder = new MediaRecorder(combinedSource, {
mimeType: 'video/webm;codecs=vp9',
// 支持手动设置码率,这里设了1.5Mbps的码率,以限制码率较大的情况
// 由于本身还是动态码率,这个值并不准确
videoBitsPerSecond: 1.5e6,
});
const timeslice = 5000;
const fileBits: Blob[] = [];
// 当数据可用时,会回调该函数,有以下四种情况:
// 1. 手动停止MediaRecorder时
// 2. 设置了timeslice,每到一次timeslice时间间隔时
// 3. 媒体流内所有轨道均变成非活跃状态时
// 4. 调用recorder.requestData()转移缓冲区数据时
recorder.ondataavailable = (event: BlobEvent) => {
fileBits.push(event.data as Blob);
}
recorder.onstop = () => {
// 录屏停止并获取录屏文件
// 触发时机一定在ondataavailable之后
const videoFile = new Blob(fileBits, { type: 'video/webm;codecs=vp9' });
}
if (timeslice === 0) {
// 开始录制,并一直存储数据到缓冲区,直到停止
recorder.start();
} else {
// 开始录制,并且每timeslice毫秒,触发一次ondataavailable,输出并清空缓冲区(非常重要)
recorder.start(timeslice);
}
setTimeout(() => {
// 30秒后停止
recorder.stop();
}, 30000);暂停/恢复录制
// 暂停录制
recorder.pause();
// 恢复录制
recorder.resume();完成以上 API 的调用,我们“录屏功能 MVP”版本就算跑通了。
录制产物的处理
正如前面技术方案探索内容中提到的,直接使用浏览器实现的这套方法,会有一些坑,尽管如此,本文的核心其实就是这部分,也就是解决录屏带来的那些坑。
锁屏触发视频流停止问题
实验发现,通过 navigator.getUserMedia 获取的视频流,在锁屏情况(是的 macOS、Windows 全部操作系统都会)会中断,我们可以通过一下代码测试该现象:
import { remote } from 'electron';
// 视频流获取
const videoSource: MediaStream = await navigator.mediaDevices.getUserMedia({
audio: false, // 强行表示不录制音频,音频额外获取
video: {
mandatory: {
chromeMediaSource: 'desktop',
chromeMediaSourceId: remote.getCurrentWindow().getMediaSourceId()
}
}
});
recorder.ondataavailable = () => console.log('数据可用');
recorder.onstop = () => console.log('录屏停止');
const recorder = new MediaRecorder(videoSource, {
mimeType: 'video/webm;codecs=vp9',
// 支持手动设置码率,这里设了1.5Mbps的码率,以限制码率较大的情况
// 由于本身还是动态码率,这个值并不准确
videoBitsPerSecond: 1.5e6,
});
// 开始录制,等10秒,手动触发锁屏
recorder.start();
setInterval(() => {
console.log('轨道活跃:', videoSource.active);
}, 1000);
10秒后控制台输出:
轨道活跃: true
轨道活跃: true
轨道活跃: true
轨道活跃: true
轨道活跃: true
轨道活跃: true
轨道活跃: true
轨道活跃: true
轨道活跃: true
数据可用
录屏停止
轨道活跃: false
...以上实验说明锁屏会触发视频流状态由“活跃”转为“不活跃”,该问题最大的坑点在于解锁后“状态并不会自动恢复为活跃”,必须开发者手动重新调用 navigator.mediaDevices getUserMedia 获取视频流。那么如何知道用户是否锁屏呢?这里我探索出来一种方法:
// 启动MediaRecorder的时候,如果抛错,此时重新获取视频流
try {
this.recorder.start(5000);
} catch (e) {
this._combinedSource = await this.getSystemVideoMediaStream()
this.recorder = new MediaRecorder(this._combinedSource, {
mimeType: VIDEO_RECORD_FORMAT,
videoBitsPerSecond: 1.5e6,
});
this.recorder.start(5000);
}第二个坑点在于,以上仅针对纯视频流场景录屏,如果同时录制音频流+视频流,那么**“由于音频流锁屏时的状态始终保持活跃”,而“仅视频流锁屏时会触发状态变为不活跃”**,由于并非全部轨道都变为不活跃,这里“MediaRecorder 并不会触发 ondataavailable 和 onstop,录屏将会仍然继续进行,但录出来的视频是黑屏”,成为这个问题的一大槽点与大坑。那么如何解决音视频流锁屏时并不触发 ondataavailable 和 onstop 的问题呢?这里有一种我探索的方法:
// 如果视频流不活跃,停止音频流
// 如果音频流不活跃,停止视频流(虽然不会发生,只是兜底)
const startStreamActivityChecker = () =>
window.setInterval(() => {
if (this._videoSource?.active === false) {
this._audioSource?.getTracks().forEach(track => track.stop());
}
if (this._audioSource?.active === false) {
this._videoSource?.getTracks().forEach(track => track.stop());
}
}, 1000);
}缺少视频时长与时间线不可拖拽问题
- Issue1: MediaRecorder output should have Cues element -https://bugs.chromium.org/p/chromium/issues/detail?id=561606
- Issue2: Videos created with MediaRecorder API are not seekable / scrubbable -https://bugs.chromium.org/p/chromium/issues/detail?id=569840
- Issue3: No duration or seeking cue for opus audio produced with mediarecoder -https://bugs.chromium.org/p/chromium/issues/detail?id=599134
- Issue4: MediaRecorder: consider producing seekable WebM files -https://bugs.chromium.org/p/chromium/issues/detail?id=642012
私以为这两个问题,算是 MediaRecorder api 设计的最大失误了。由于 webm 文件的视频时长和拖拽信息是写在文件头部的,因此在 WebM 录制未完成前,头部的"Duration"永远是不断增加的一个未知值。但由于 MediaRecorder 支持分片定时输出小 Blob 文件,导致第一个 Blob 的头部是不可能包含 Duration 字段的,同样搜索头信息"SeekHead", "Seek", "SeekID", "SeekPosition", "Cues", "CueTime", "CueTrack", "CueClusterPosition", "CueTrackPositions", "CuePoint" 同样缺失。但 Blob 在设计之初又是不可变的文件类型,导致最终录制出的文件没有 Duration 视频时长字段,这个问题已经被 Chromium 官方标识为“wont fix”,并推荐开发者自行找社区解决。
使用 ffmpeg 修复
社区内的一种方案是使用 ffmpeg 对文件进行“拷贝”并输出,例如输入下面的命令:
ffmpeg -i without_meta.webm -vcodec copy -acodec copy with_meta.webm
ffmpeg 会自动计算 Duration 与搜索头信息,这种方案最大的问题在于,如果对客户端集成 ffmpeg,需要直接操作文件且编写跨平台方案,将文件暴露于本地。如果做在服务端,又会增加文件的整体处理流程与时间,虽然不是不可以,但是这不是我们追求的极致方案。
使用 npm 库 fix-webm-duration 修复
这是社区内的另一种方案,即解析 webm 文件的头部信息,并在前端手工记录视频时长,在解析好之后手动将记录好的 Duration 写入 webm 头部,但该方案同样不能解决搜索头丢失导致的可拖拽信息,且依赖手工记录的 duration,修复内容比较有限。
基于 ts-ebml,利用 fix-webm-metainfo 修复
这是本问题的最终解,即完全解析 webm ebml 和 segment 头,根据实际 simple block 的大小计算 Duration 与搜索头。我们利用 ebml 解析 webm,以 MediaRecorder 直出的 webm 文件为例解析,结构如下:
m 0 EBML
u 1 EBMLVersion 1
u 1 EBMLReadVersion 1
u 1 EBMLMaxIDLength 4
u 1 EBMLMaxSizeLength 8
s 1 DocType webm
u 1 DocTypeVersion 4
u 1 DocTypeReadVersion 2
m 0 Segment
m 1 Info segmentContentStartPos, all CueClusterPositions provided in info.cues will be relative to here and will need adjusted
u 2 TimecodeScale 1000000
8 2 MuxingApp Chrome
8 2 WritingApp Chrome
m 1 Tracks tracksStartPos
m 2 TrackEntry
u 3 TrackNumber 1
u 3 TrackUID 31790271978391090
u 3 TrackType 2
s 3 CodecID A_OPUS
b 3 CodecPrivate <Buffer 19>
m 3 Audio
f 4 SamplingFrequency 48000
u 4 Channels 1
m 2 TrackEntry
u 3 TrackNumber 2
u 3 TrackUID 24051277436254136
u 3 TrackType 1
s 3 CodecID V_VP9
m 3 Video
u 4 PixelWidth 1200
u 4 PixelHeight 900
m 1 Cluster clusterStartPos
u 2 Timecode 0
b 2 SimpleBlock track:2 timecode:0 keyframe:true invisible:false discardable:false lacing:1而根据 webm 官网描述(链接[3]),一个正常的 webm 的头信息,应该解析如下:
m 0 EBML
u 1 EBMLVersion 1
u 1 EBMLReadVersion 1
u 1 EBMLMaxIDLength 4
u 1 EBMLMaxSizeLength 8
s 1 DocType webm
u 1 DocTypeVersion 4
u 1 DocTypeReadVersion 2
m 0 Segment
// 这部分缺失
m 1 SeekHead -> This is SeekPosition 0, so all SeekPositions can be calculated as (bytePos - segmentContentStartPos), which is 44 in this case
m 2 Seek
b 3 SeekID -> Buffer([0x15, 0x49, 0xA9, 0x66]) Info
u 3 SeekPosition -> infoStartPos =
m 2 Seek
b 3 SeekID -> Buffer([0x16, 0x54, 0xAE, 0x6B]) Tracks
u 3 SeekPosition { tracksStartPos }
m 2 Seek
b 3 SeekID -> Buffer([0x1C, 0x53, 0xBB, 0x6B]) Cues
u 3 SeekPosition { cuesStartPos }
m 1 Info
// 这部分缺失
f 2 Duration 32480 -> overwrite, or insert if it doesn't exist
u 2 TimecodeScale 1000000
8 2 MuxingApp Chrome
8 2 WritingApp Chrome
m 1 Tracks
m 2 TrackEntry
u 3 TrackNumber 1
u 3 TrackUID 31790271978391090
u 3 TrackType 2
s 3 CodecID A_OPUS
b 3 CodecPrivate <Buffer 19>
m 3 Audio
f 4 SamplingFrequency 48000
u 4 Channels 1
m 2 TrackEntry
u 3 TrackNumber 2
u 3 TrackUID 24051277436254136
u 3 TrackType 1
s 3 CodecID V_VP9
m 3 Video
u 4 PixelWidth 1200
u 4 PixelHeight 900
// 这部分缺失
m 1 Cues -> cuesStartPos
m 2 CuePoint
u 3 CueTime 0
m 3 CueTrackPositions
u 4 CueTrack 1
u 4 CueClusterPosition 3911
m 2 CuePoint
u 3 CueTime 600
m 3 CueTrackPositions
u 4 CueTrack 1
u 4 CueClusterPosition 3911
m 1 Cluster
u 2 Timecode 0
b 2 SimpleBlock track:2 timecode:0 keyframe:true invisible:false discardable:false lacing:1可以看到,我们只要修复好缺失的 Duration、SeakHead、Cues,就可以解决我们的问题,整体流程如下: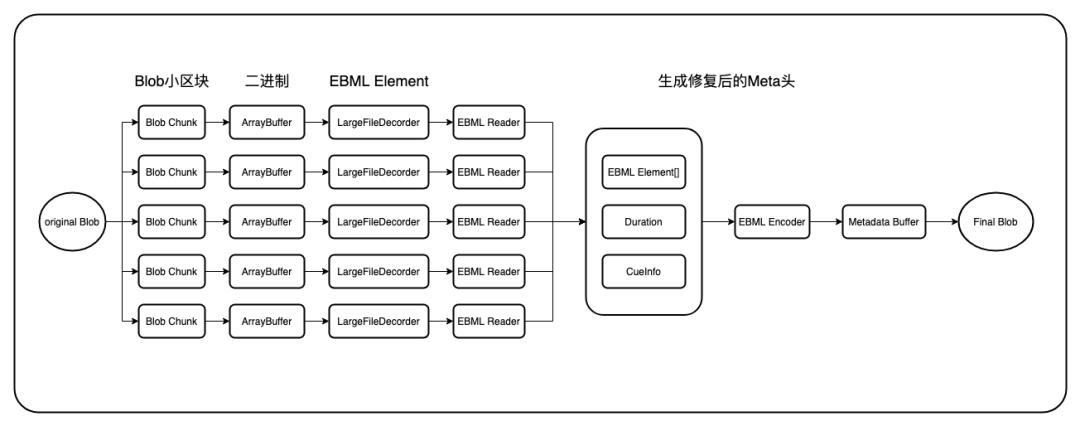
import { tools, Reader } from 'ts-ebml';
import LargeFileDecorder from './decoder';
// fix-webm-metainfo 早期的实现过程
async function fixWebmMetaInfo(blob: Blob): Promise<Blob> {
// 解决ts-ebml不支持大于2GB视频文件的问题
const decoder = new LargeFileDecorder();
const reader = new Reader();
reader.logging = false;
const bufSlices: ArrayBuffer[] = [];
// 由于Uint8Array或者ArrayBuffer支持的最大长度为2046 * 1024 * 1024
const sliceLength = 1 * 1024 * 1024 * 1024;
for (let i = 0; i < blob.size; i = i + sliceLength) {
// 切割Blob,并读取ArrayBuffer
const bufSlice = await blob.slice(i, Math.min(i + sliceLength, blob.size)).arrayBuffer();
bufSlices.push(bufSlice);
}
// 解析ArrayBuffer到可阅读与修改的EBML Element类型,并使用reader读取以计算Duration和Cues
decoder.decode(bufSlices).forEach(elm => reader.read(elm));
// 当全部读取结束后,结束reader
reader.stop();
// 利用reader生成好的cues与duration,重建meta头,并转换回arrayBuffer
const refinedMetadataBuf = tools.makeMetadataSeekable(reader.metadatas, reader.duration, reader.cues);
const firstPartSlice = bufSlices.shift() as ArrayBuffer;
const firstPartSliceWithoutMetadata = firstPartSlice.slice(reader.metadataSize);
// 重建回Blob
return new Blob([refinedMetadataBuf, firstPartSliceWithoutMetadata, ...bufSlices], { type: blob.type });
}进程卡死与缓存未复用问题
随着视频长度的增加,fix-webm-metainfo 尽管解决了大尺寸长视频的修复问题,但面对大文件在短时间的全量读取与计算,存在短时间卡死渲染进程的问题。
Web Worker 处理
Web Worker 天生适合该场景的处理,利用 Web Worker,我们可以在不额外创建进程的同时,额外创建一个 Worker 线程,专门进行大视频文件的处理与解析,同时不会卡死主线程,此外由于 Web Worker 支持以引用的方式(Transferable Object)传递 ArrayBuffer,因此也成了本问题最佳解决方法。首先在 Electron 的 BrowserWindow 中开启 nodeIntegrationInWorker:true
webPreferences: {
...
nodeIntegration: true,
nodeIntegrationInWorker: true,
},接着编写 Worker 进程:
import { tools, Reader } from 'ts-ebml';
import LargeFileDecorder from './decoder';
// index.worker.ts
export interface IWorkerPostData {
type: 'transfer' | 'close';
data?: ArrayBuffer;
}
export interface IWorkerEchoData {
buffer: ArrayBuffer;
size: number;
duration: number;
}
const bufSlices: ArrayBuffer[] = [];
async function fixWebm(): Promise<void> {
const decoder = new LargeFileDecorder();
const reader = new Reader();
reader.logging = false;
decoder.decode(bufSlices).forEach(elm => reader.read(elm));
reader.stop();
const refinedMetadataBuf = tools.makeMetadataSeekable(reader.metadatas, reader.duration, reader.cues);
// 将计算后的结果传回父线程
self.postMessage({
buffer: refinedMetadataBuf,
size: reader.metadataSize,
duration: reader.duration
} as IWorkerEchoData, [refinedMetadataBuf]);
}
self.addEventListener('message', (e: MessageEvent<IWorkerPostData>) => {
switch (e.data.type) {
case 'transfer':
// 保存传递过来的ArrayBuffer
bufSlices.push(e.data.data);
break;
case 'close':
// 修复WebM,之后关闭Worker进程
fixWebm().catch(self.postMessage).finally(() => self.close());
break;
default:
break;
}
});父进程:
import FixWebmWorker from './worker/index.worker';
import type { IWorkerPostData, IWorkerEchoData } from './worker/index.worker';
async function fixWebmMetaInfo(blob: Blob): Promise<Blob> {
// 创建Worker进程
const fixWebmWorker: Worker = new FixWebmWorker();
return new Promise(async (resolve, reject) => {
fixWebmWorker.addEventListener('message', (event: MessageEvent<IWorkerEchoData>) => {
if (Object.getPrototypeOf(event.data)?.name === 'Error') {
return reject(event.data);
}
let refinedMetadataBlob = new Blob([event.data.buffer], { type: blob.type });
// 手动关闭Worker进程
fixWebmWorker.terminate();
let body: Blob;
let firstPartBlobSlice = blobSlices.shift();
body = firstPartBlobSlice.slice(event.data.size);
firstPartBlobSlice = null;
// 注:除了利用Web Worker,与早期方案相比,并对meta ArrayBuffer生成Blob
// 不再用ArrayBuffer重建,而是复用之前的Blob
// 这一步做了之后会大量减少一次文件写入,并可解决引用不释放导致的内存泄露问题
// 是本文最关键的决定性一步
let blobFinal = new Blob([refinedMetadataBlob, body, ...blobSlices], { type: blob.type });
refinedMetadataBlob = null;
body = null;
blobSlices = [];
resolve(blobFinal);
blobFinal = null;
});
fixWebmWorker.addEventListener('error', (event: ErrorEvent) => {
blobSlices = [];
reject(event);
});
let blobSlices: Blob[] = [];
let slice: Blob;
const sliceLength = 1 * 1024 * 1024 * 1024;
try {
for (let i = 0; i < blob.size; i = i + sliceLength) {
slice = blob.slice(i, Math.min(i + sliceLength, blob.size));
// 切片读取ArrayBuffer
const bufSlice = await slice.arrayBuffer();
// 发送给Worker进程,并利用 Transferable Objects 提高性能
fixWebmWorker.postMessage({
type: 'transfer',
data: bufSlice
} as IWorkerPostData, [bufSlice]);
blobSlices.push(slice);
slice = null;
}
// 结束处理
fixWebmWorker.postMessage({
type: 'close',
});
} catch (e) {
blobSlices = [];
slice = null;
reject(new Error(`[fix webm] read buffer failed: ${e?.message || e}`));
}
});
}通过对早期 fix-webm-metainfo 的修复过程中 blob_storage 暂存目录的分页文件进行观察,我们察觉到了明显的内存不释放以及文件重复生成的问题,在去除 fix-webm 逻辑后,该问题不再复现,这就说明目前的 fix-webm-metainfo 存在文件缓存未复用和文件引用未删除的问题(这个问题后面讨论)。
文件缓存复用
那么在 ArrayBuffer 与 Blob 的转换中,是否有一种无损,且可复用文件缓存的方式呢?这就是为什么 fix-webm-metainfo 在后面的迭代中,采用了复用 Blob 的方式建立修复后的 Blob,而不是直接使用 ArrayBuffer 建立 Blob 的原因。观察下面的两种方式生成的 Blob 有什么区别:
// 首先创建一个Blob
const a = new Blob([new ArrayBuffer(10000000)]);
// 读出它的buffer
const buffer = await a.arrayBuffer();
// 方式1,实际会占用多少内存?
const b = new Blob([buffer]);
const c = new Blob([buffer]);
const d = new Blob([buffer]);
const e = new Blob([buffer]);
const f = new Blob([buffer]);
const g = new Blob([buffer]);
const h = new Blob([buffer]);
// 方式2,那这种呢?
const i = new Blob([a]);
const j = new Blob([a]);
const k = new Blob([a]);
const l = new Blob([a]);
const m = new Blob([a]);
const n = new Blob([a]);
const o = new Blob([a]);猜猜答案是什么?是的,Blob 存在复用本地文件缓存的机制,方式 1 会在内存或磁盘生成 7 份一模一样的文件,而方式 2 不会额外生成一个文件,i 到 o 的文件均复用了 a 的 blob,在内存或磁盘中只存在一份。那么,修复 webm 的那种方式本质上修改了文件头部的字节,那这种方式也会复用同一个本地文件缓存么?答案是肯定的,被修复前的 webm 和被修复后的 webm 由于差异仅在头部,而整体的大部分区域均采用相同的 Blob slice 出来的子 blob 建立,因此空间依然是复用的。
主进程内存泄露问题
根据 Electron 官方提供的 process.getProcessMemoryInfo() api,我们分别对主进程和渲染进程实现了内存监控,通过监控发现使用录屏的用户的主进程内存占用经常可以达到 2GB,而不使用录屏功能的用户,主进程内存占用仅 80MB,这说明百分百存在内存泄露。在谈及主进程内存泄漏问题之前,不得不提及 Blob 文件类型的实现方式。根据 Chromium Blob 实现官方说明(PPT[4])如下图,我们在 Renderer 进程通过任何一种方式创建的 Blob,本质上最终都会有一个跨进程传输到 Browser 进程的过程(即主进程),也就是说尽管 MediaRecorder 是基于渲染进程的录制,但在将缓冲区文件输出为 Blob 的过程(即 ondataavailable 触发瞬间),会存在跨进程传输。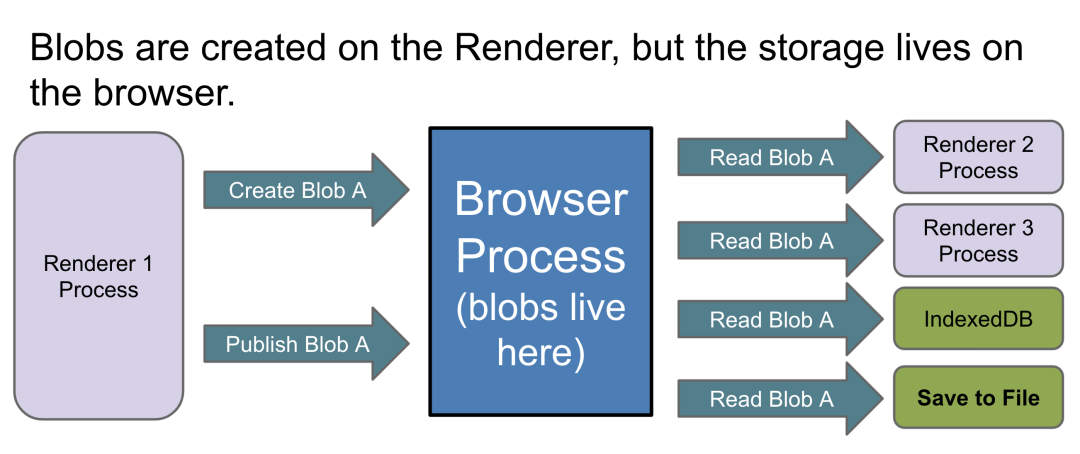
Blob 的传输方式
这里我们通过阅读 Chromium 的 Blob Controller(Code[5])并添加 LOG(INFO)观察
// 作用:判断传输策略
// storage/browser/blob/blob_memory_controller.cc
BlobMemoryController::Strategy BlobMemoryController::DetermineStrategy(
size_t preemptive_transported_bytes,
uint64_t total_transportation_bytes) const {
// Blob文件大小为0,不需要传输
if (total_transportation_bytes == 0)
return Strategy::NONE_NEEDED;
// 当Blob文件大小大于可用内存数,且大于可用磁盘空间时,传输直接失败
if (!CanReserveQuota(total_transportation_bytes))
return Strategy::TOO_LARGE;
// 普通调用可忽略
if (preemptive_transported_bytes == total_transportation_bytes &&
pending_memory_quota_tasks_.empty() &&
preemptive_transported_bytes <= GetAvailableMemoryForBlobs()) {
return Strategy::NONE_NEEDED;
}
// Chromium编译时开启文件分页(默认开启),且配置了override_file_transport_min_size时
if (UNLIKELY(limits_.override_file_transport_min_size > 0) &&
file_paging_enabled_ &&
total_transportation_bytes >= limits_.override_file_transport_min_size) {
return Strategy::FILE;
}
// Blob小于0.25MB时,直接走ipc传输
if (total_transportation_bytes <= limits_.max_ipc_memory_size)
return Strategy::IPC;
// Chromium编译时开启文件分页(默认开启)
// Blob文件大小小于可用磁盘空间
// Blob文件大小大于可用内存空间
if (file_paging_enabled_ &&
total_transportation_bytes <= GetAvailableFileSpaceForBlobs() &&
total_transportation_bytes > limits_.memory_limit_before_paging()) {
return Strategy::FILE;
}
// 默认传输策略,即内存共享方式,通过渲染进程传递给主进程
return Strategy::SHARED_MEMORY;
}
bool BlobMemoryController::CanReserveQuota(uint64_t size) const {
// 同时检查内“可用内存空间”与“可用磁盘空间”
return size <= GetAvailableMemoryForBlobs() ||
size <= GetAvailableFileSpaceForBlobs();
}
// 如果当前内存使用量小于2GB(按x64电脑算,max_blob_in_memory_space = 2 * 1024 * 1024 * 1024)
// 计算剩余内存量
size_t BlobMemoryController::GetAvailableMemoryForBlobs() const {
if (limits_.max_blob_in_memory_space < memory_usage())
return 0;
return limits_.max_blob_in_memory_space - memory_usage();
}
// 计算剩余磁盘量
uint64_t BlobMemoryController::GetAvailableFileSpaceForBlobs() const {
if (!file_paging_enabled_)
return 0;
uint64_t total_disk_used = disk_used_;
if (in_flight_memory_used_ < pending_memory_quota_total_size_) {
total_disk_used +=
pending_memory_quota_total_size_ - in_flight_memory_used_;
}
if (limits_.effective_max_disk_space < total_disk_used)
return 0;
// 实际最大磁盘空间 - 已用磁盘空间
return limits_.effective_max_disk_space - total_disk_used;
}可发现:Blob 的传输与储存基本分为三种,即:“文件”,“共享内存”,以及“IPC”,
- 当文件小于 0.25MB 时优先走“IPC”方式传输
- 当“可用内存空间”大于文件体积时优先走“共享内存”方式传输
- 当“可用内存空间”不足但“可用磁盘空间”充足时,优先走“文件”方式传输
- 当“可用内存空间”与“可用磁盘空间”均不充足时,Blob 不会传输,且最终反馈到渲染进程,会报“File not readble”之类的报错。
最大存储限制
这里引发一个问题“可用内存空间”与“可用磁盘空间”是如何界定的?如果计算?想到这里,又引发我的思考,如果可用内存空间非常大,会造成什么问题?带着这些疑问,我们继续研究 Chromium 的实现:
BlobStorageLimits CalculateBlobStorageLimitsImpl(
const FilePath& storage_dir,
bool disk_enabled,
base::Optional<int64_t> optional_memory_size_for_testing) {
int64_t disk_size = 0ull;
int64_t memory_size = optional_memory_size_for_testing
? optional_memory_size_for_testing.value()
: base::SysInfo::AmountOfPhysicalMemory();
if (disk_enabled && CreateBlobDirectory(storage_dir) == base::File::FILE_OK)
disk_size = base::SysInfo::AmountOfTotalDiskSpace(storage_dir);
BlobStorageLimits limits;
if (memory_size > 0) {
#if !defined(OS_CHROMEOS) && !defined(OS_ANDROID) && !defined(OS_ANDROID) && defined(ARCH_CPU_64_BITS)
// 不是ChromeOS,不是安卓,且架构是64位,则“最大可用内存大小”为2GB
constexpr size_t kTwoGigabytes = 2ull * 1024 * 1024 * 1024;
limits.max_blob_in_memory_space = kTwoGigabytes;
#elif defined(OS_ANDROID)
// 安卓,“最大可用内存”为物理内存的1/100
limits.max_blob_in_memory_space = static_cast<size_t>(memory_size / 100ll);
#else
// 其他架构或,“最大可用内存”为物理内存的1/5
limits.max_blob_in_memory_space = static_cast<size_t>(memory_size / 5ll);
#endif
}
// 实现了一下“最大可用内存”的最小值不小于两倍的“最小分页大小”
if (limits.max_blob_in_memory_space < limits.min_page_file_size)
limits.max_blob_in_memory_space = limits.min_page_file_size;
if (disk_size >= 0) {
#if defined(OS_CHROMEOS)
// ChromeOS,“最大可用磁盘大小”为物理磁盘大小的1/2
limits.desired_max_disk_space = static_cast<uint64_t>(disk_size / 2ll);
#elif defined(OS_ANDROID)
// Android,“最大可用磁盘大小”为物理磁盘大小3/50
limits.desired_max_disk_space = static_cast<uint64_t>(3ll * disk_size / 50);
#else
// 其他平台或架构,“最大可用磁盘大小”为物理磁盘大小1/10
limits.desired_max_disk_space = static_cast<uint64_t>(disk_size / 10);
#endif
}
if (disk_enabled) {
UMA_HISTOGRAM_COUNTS_1M("Storage.Blob.MaxDiskSpace2",
limits.desired_max_disk_space / kMegabyte);
}
limits.effective_max_disk_space = limits.desired_max_disk_space;
CHECK(limits.IsValid());
return limits;
}总结一下两个指标,与 OS、Arch、Memory Size、Disk Size 都有可能有关系:
最大可用内存大小
-
架构是 x64 且平台不是 Chrome OS 或 Android:
2GB -
平台是 Android:
所在设备物理内存大小/ 100 -
其他平台或架构(例如 macOS arm64,chromeOS):
所在设备物理内存大小 / 5
最大可用磁盘大小
-
平台是 Chrome OS:
所在设备,软件所在分区的逻辑磁盘的大小 / 2 -
平台是安卓:
所在设备,软件所在分区的逻辑磁盘的大小 * 3/50 -
其他平台或架构:
所在设备,软件所在分区的逻辑磁盘的大小 / 10
以上结论说明了什么?我们从中发现了两个问题:
- 问题 1:X64 架构的最大可用内存是 2GB,这实际上非常大了,用户的录屏存储并非频繁访问的内容,用户的电脑可能只有 8GB,如果这 2GB 平白被占据实际上是很大一个浪费。
- 问题 2:X64 与非 X64 架构的最大可用内存并不一致。
- 问题 3:最大可用磁盘大小仅为物理硬盘大小的 1/10, 以 128GB 的 SSD 硬盘为例,即使将全部 128GB 均分配给 C 盘,那么最大可用磁盘大小仅为 12.8GB,不考虑其他任何 Blob 的磁盘占用,即使用户 C 盘有 100GB 的剩余空间,依然逃不了录屏文件体积被限制到 12.8GB 的尴尬。
事实真相大白,主进程并非“内存泄露”而是“设计如此”。
修改 Chromium
那么我们如果将最大内存空间改小,将最大可用磁盘空间改大,是不是即可解决主进程内存占用问题,又解决了录屏文件体积限制两个问题呢?答案是肯定的,修改起来也很简单:
// 如果物理内存数大于0
if (memory_size > 0) {
#if !defined(OS_CHROMEOS) && !defined(OS_ANDROID)
// 去除64位判断逻辑,保持32位 Windows,Arm64 Mac一致的2000MB -> 200MB最大内存录制空间逻辑修改
constexpr size_t kTwoHundrendMegabytes = 2ull * 100 * 1024 * 1024;
limits.max_blob_in_memory_space = kTwoHundrendMegabytes;
#elif defined(OS_ANDROID)
limits.max_blob_in_memory_space = static_cast<size_t>(memory_size / 100ll);
#else
limits.max_blob_in_memory_space = static_cast<size_t>(memory_size / 5ll);
#endif
}
if (limits.max_blob_in_memory_space < limits.min_page_file_size)
limits.max_blob_in_memory_space = limits.min_page_file_size;
if (disk_size >= 0) {
#if defined(OS_CHROMEOS)
limits.desired_max_disk_space = static_cast<uint64_t>(disk_size / 2ll);
#elif defined(OS_ANDROID)
limits.desired_max_disk_space = static_cast<uint64_t>(3ll * disk_size / 50);
#else
// 去除录屏Blob_Storage的大小限制, 最大空间由完整磁盘空间的1/10 变为 1
limits.desired_max_disk_space = static_cast<uint64_t>(disk_size);
#endif
}如果你有类似的需要,可以直接复用该修改,且无任何副作用。
缓冲区内存释放问题
有了上述对 Blob 文件格式的理解,我们基本可以理清录屏功能的整个传输链路。缓冲区内存释放问题的解法,相信大家也能想到了,在录制过程中,未对 MediaRecorder stop 前,由于 MediaRecorder 录制的全部数据均存储于 Renderer 进程中,便会造成内存的异常占用,随着录屏时间的增长,这部分的占用会尤为庞大,解决方法也很简单,设定一个 timeslice 或定时 requestData()即可
const recorder = new MediaRecorder(combinedSource, {
mimeType: 'video/webm;codecs=vp9',
videoBitsPerSecond: 1.5e6,
});
const timeslice = 5000;
const fileBits: Blob[] = [];
recorder.ondataavailable = (event: BlobEvent) => {
fileBits.push(event.data as Blob);
}
recorder.onstop = () => {
const videoFile = new Blob(fileBits, { type: 'video/webm;codecs=vp9' });
}
// 解法一,开始录制时,设定timeSlice,确保每timeslice毫秒,自动触发一次ondataavailable,输出并清空缓冲区(非常重要)
recorder.start(timeslice);
// 解法二,录制过程中手动requestData清空缓冲区
recorder.start();
setInterval(() => recorder.requestData(), timeslice);渲染进程内存泄露问题
在编写过程中,由于一些疏忽,我们可能会写出具有内存泄露的代码,那么如何解决该问题?结论是,时刻遵循以下原则:
- 一切对Blob的引用都及时清除
- 尽量用let 指向Blob并手动释放,防止引用不释放的情况发生
// 例1
const a = new Map();
a.set('key', {
blob: new Blob([1]) // Blob1
});
// 手动释放
a.get('key').blob = null;
// 例2
let a = new Blob([]);
doSomething(a);
// 手动释放
a = null;Blob-Internals 观察引用
若想随时 Debug,可以通过观察 Blob 的引用计数的方式,直接访问 chrome://blob-internals/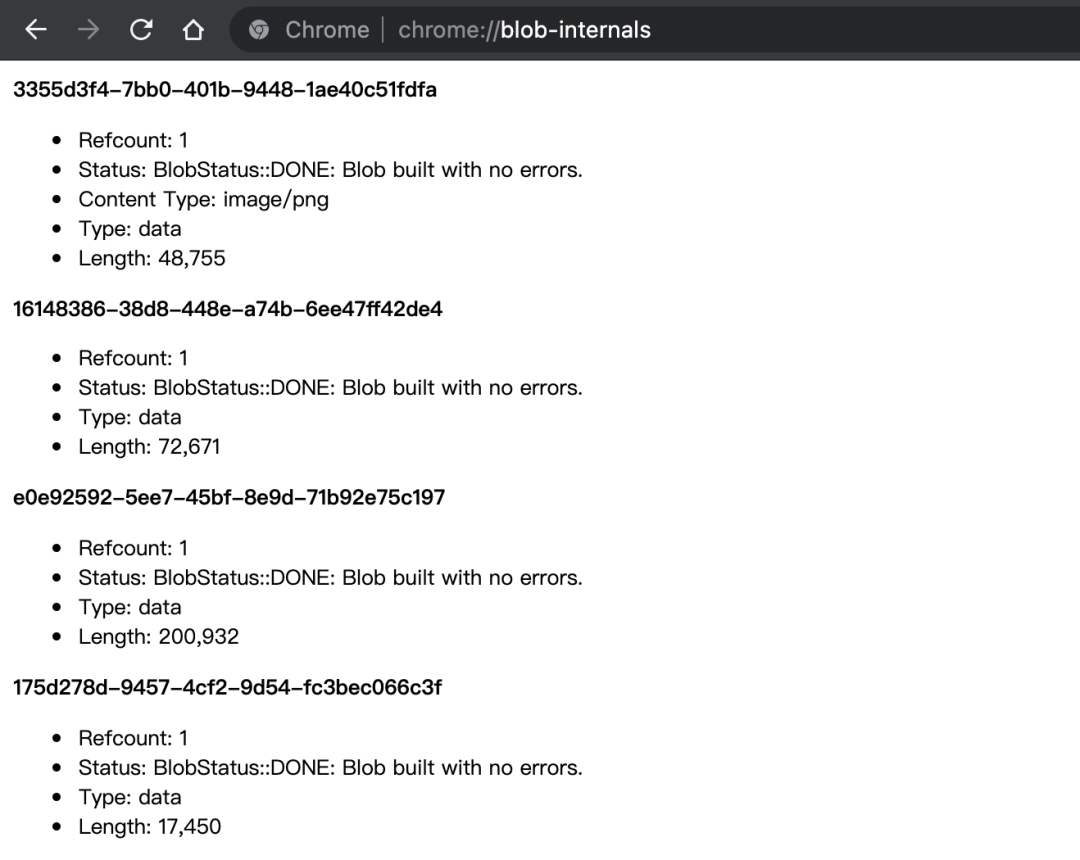
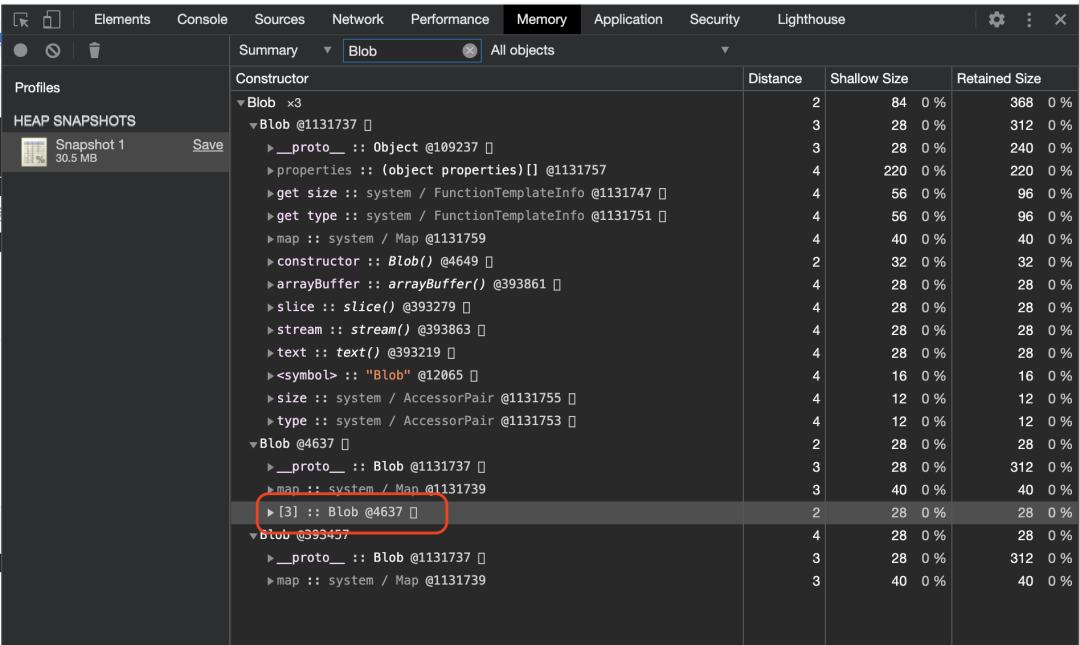
Profiler 抓取堆快照
也可以利用 Profiler 抓取内存堆栈情况。
blob_storage 目录观察
如果你有对 Chromium 修改的能力,可以通过将“最大可用内存”改为较小值(比如 10MB,以此迫使 Blob 直接走文件传输方式存储到硬盘),直接观测 blob_storage 目录内分页文件的产生。Blob 文件在本地磁盘是以分页的形式存储,它的大小是一个动态值,最小为 5MB,最大为 100MB。每次关闭应用时该目录都会被清空,因此需要确保应用开启并持续观测,这种方式是目前最为直观易用的方式,一般来说如果用户持续不关闭应用,而你的代码又存在内存泄露,那么基本可以观察到该目录会产生大量的分页文件而不被释放。
后续的性能优化
当前的处理,尽管已经完美解决了一切修复问题,但存在最后一个问题,就是修复时会占用大量内存,后续我会持续维护 fix-webm-metainfo 库,通过不传输完整 ArrayBuffer 的方式,解决这个问题。
参考资料
[1]参考: https://www.electronjs.org/docs/latest/api/desktop-capturer/#desktopcapturergetsourcesoptions
[2]参考: https://github.com/ExistentialAudio/BlackHole
[3]链接: https://www.webmproject.org/docs/container/
[4]PPT: https://docs.google.com/presentation/d/1MOm-8kacXAon1L2tF6VthesNjXgx0fp5AP17L7XDPSM/edit#slide=id.g91839e9b6_4_5
[5]Code: https://source.chromium.org/chromium/chromium/src/+/master:storage/browser/blob/blob_memory_controller.cc?q=CalculateBlobStorageLimitsImpl&ss=chromium