Node.js CPU 偶发 100% 排查小结
开始前,先贴下本文目录, 主要篇幅在第二部分:如何定位。
前言(背景)
内部管理系统,Node.js项目线上运行一直稳定、正常, 某天开始使用人员反馈系统访问卡顿,同时对应服务器出现CPU 占用 95% ~ 120%过高的钉钉告警,超过100%是因为对应Linux服务器是多核, 出现后1~5分钟后正常,偶发出现,这次问题持续时间较长,参考、阅读了不少文章,写个博文记录、总结下。
问题出现 ~ 解决时间 2021.07.21 ~ 2021.08.01
先说下内部系统技术架构,前端React, 后端NodeJS框架Egg.js(Koa2封装)。所以监控定位时有些 NodeJs 库不适合接入,这个第二部分详细讲。
如何定位
Node项目接入性能监控平台
NodeJs项目出现CPU占用100%以上时,登录对应服务器命令行top -c查看当前服务器哪个进程占用CPU最高!
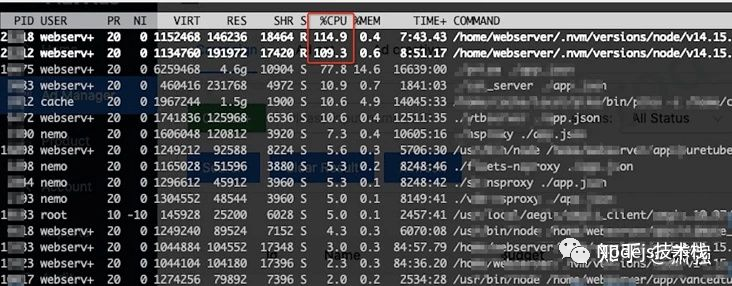
所以需要接入性能监控平台,具体可看 如何接入Node监控平台 - alinode , 我们是内部服务器部署了aliNode,操作界面差不多。接入成功后,出现CPU过高时有以下图表:

火焰图
火焰图(Flame Graph)大家应该听过,它可以将 CPU 的使用情况可视化,使我们直观地了解到程序的性能瓶颈。我们通常要结合操作系统的性能分析工具(profiling tracer)使用火焰图,常见的操作系统的性能分析工具如下:
Linux:perf, eBPF, SystemTap, and ktap。
Solaris, illumos, FreeBSD:DTrace。
Mac OS X:DTrace and Instruments。
Windows:Xperf.exe。如果未接入NodeJs性能监控, 得在服务器(一般是Linux)安装以上分析工具;
接入NodeJs性能监控后能一键导出 火焰图, 理解火焰图网上很多教程, 例如:快速定位NodeJs线上问题 - 之火焰图篇

然而,这边实践发现火焰图两问题:
1)时效性不够
例如 Node性能监控上 “抓取性能数据” - 生成火焰图, 生成的是 最近5分钟 的火焰图, 出现问题(看到钉钉告警)再上去“抓取”生成的 可能是正常运行代码的火焰图。
2)无法定位到具体代码
即使CPU过高问题持续很久, “抓取”的是异常运行状态下的火焰图,也有可能发现生成的图不对劲,无法与我们业务代码锲合,这边就遇到生成的火焰图无法定位到具体代码(-_-||。
不同项目不一样,或许 火焰图 能帮助大家定位到具体代码。
顺便说下,Node性能监控平台一般能导出 火焰图文件, 导出的文件名如:u-c3979add-7db3-4365-b1ed-9a2556b6a320-u-x-cpuprofile-4012-20210730-241648.cpuprofile, 在 Chrome 上可导入:
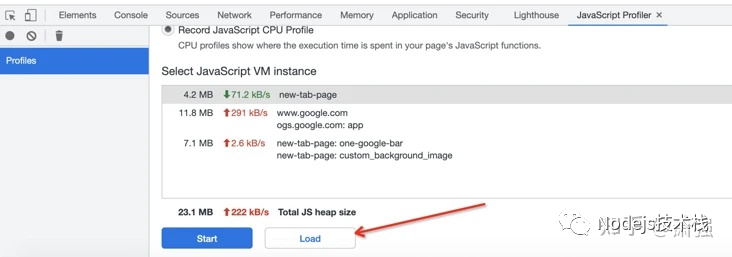
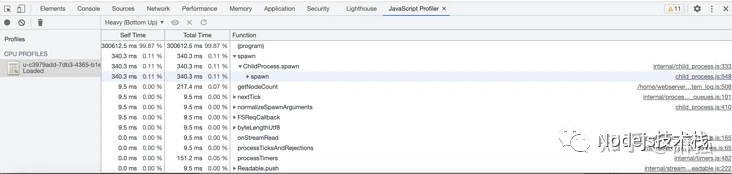
GC Trace(垃圾回收跟踪)
Node 底层V8引擎的垃圾回收一般跟内存相关,为什么CPU过高要看 垃圾回收跟踪数据?
因为 NodeJs 内存泄露 会导致超过 V8引擎 垃圾回收最大内存(1.4G),进而重启 V8 GC 导致 CPU 100%。
默认情况下,32位系统新生代内存大小为16MB,老生代内存大小为700MB,64位系统下,新生代内存大小为32MB,老生代内存大小为1.4GB。
当然可修改 V8 垃圾回收最大内存上限值:
# node在启动时可以传递参数来调整限制内存大小。以下方式就调整了node的使用内存
node --max-old-space-size=1700 // 单位是MB
node --max_semi_space_size=1024 // 单位是KB以下截图内容 引自Node.js 应用故障排查手册, 考虑脱敏就不用内部监控系统截图。


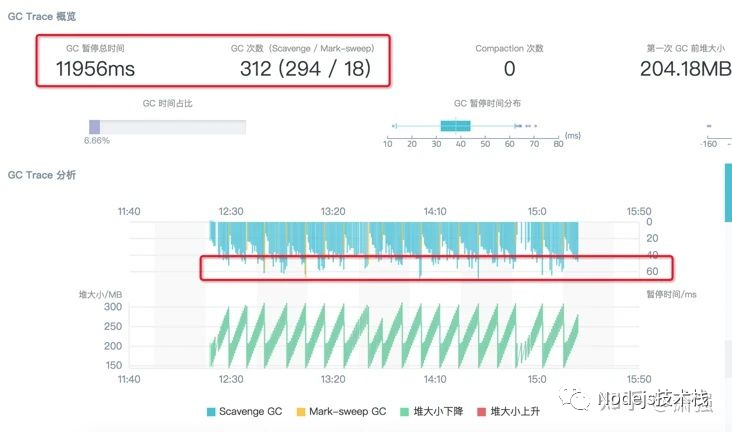
结果展示中,可以比较方便的看到问题进程的 GC 具体次数,GC 类型以及每次 GC 的耗费时间等信息,方便我们进一步的分析定位。比如这次问题的 GC Trace 结果分析图中,我们可以看到红圈起来的几个重要信息:GC 总暂停时间高达 47.8s,大头是 Scavenge 3min 的 GC 追踪日志里面,总共进行了 988 次的 Scavenge 回收 每次 Scavenge 耗时均值在 50 ~ 60ms 之间 从这些解困中我们可以看到此次 GC 案例的问题点集中在 Scavenge 回收阶段,即新生代的内存回收。那么通过翻阅 V8 的 Scavenge 回收逻辑可以知道,这个阶段触发回收的条件是:Semi space allocation failed。这样就可以推测,我们的应用在压测期间应该是在新生代频繁生成了大量的小对象,导致默认的 Semi space 总是处于很快被填满从而触发 Flip 的状态,这才会出现在 GC 追踪期间这么多的 Scavenge 回收和对应的 CPU 耗费,这样这个问题就变为如何去优化新生代的 GC 来提升应用性能。
这里可能有同学看不懂 Scavenge GC 和 Mark-sweep GC 。具体到业务代码来说 Scavenge GC 就是一些占用内存比较小的临时变量 回收处理。
而 Mark-sweep GC 是占用内存小的全局变量 或 占用内存大的临时变量 回收处理。
总的来说, 只要出现 GC Trace(垃圾回收跟踪)时间过长, 一般都是 内存泄露 导致超过 V8引擎 垃圾回收最大内存(1.4G)进而重启 V8 GC 导致 CPU 100%。
具体看 深入浅出Node(第五章内存控制) - 微信读书, 国内最经典的NodeJS书籍《深入浅出Node》虽然是2013年12月1日出版,但关于 V8引擎垃圾回收机制 内容放现在也不过时,V8引擎 官方最近关于垃圾回收机制更新(2019 - V8 引擎官方:GC算法更新 )内容基本没变,只是Mark-sweep GC 阶段添加了三优化机制。
这边场景,观察到 GC Trace 相关数据正常, 所以排除 内存泄露 导致CPU过高。
单独服务器部署
通过 火焰图 和 GC Trace 还是无法定位到具体代码怎么办?每天都会出现 2 ~ 3次, 怀疑是服务器其他服务影响, 也考虑到需要 多台服务器 来重现模拟问题。
所以跟运维申请全新的一台服务器,配置可以低一些, 主要用于排除干扰。
在新服务器部署代码后, 将访问域名 单独 映射到新服务器, 然后继续观察 是否出现 CPU 飙高情况。结论是 新服务器运行的代码 还是出现 CPU 占用 100%以上情况:
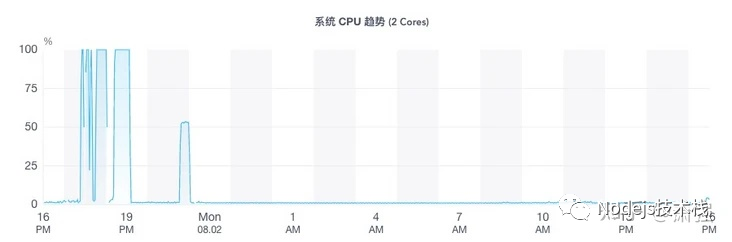
访问日志添加
为什么 域名只映射到这台新服务器?主要方便添加、查看日志, 多台服务器的话用户访问记录太分散,徒增分析、整理日志 时间成本。
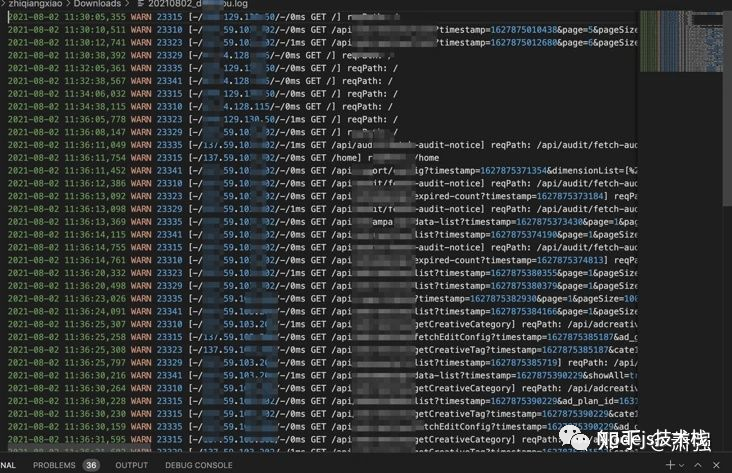
EggJs日志 API 可记录 用户每次访问的页面, 或二级页面弹层时加载数据 等 API数据请求;
在 中间件 添加记录访问日志代码, 静态文件请求忽略。
// app -> middleware -> init.ts
if (!reqPath.includes('/public/')) {
ctx.logger.warn('reqPath:', reqPath);
}添加成功后日志中,包含 “WARN”就是用户访问历史记录:
egg 定时任务API,对应清理日志脚本:
import { Subscription } from 'egg';
import * as fs from 'fs';
import * as child_process from 'child_process';
const CLEAR_WHITE_LIST = ['common-error.log', 'my_app-web.log']; // 保留日志白名单
class ClearLogs extends Subscription {
static get schedule() {
return {
cron: '0 30 7 * * *', // 每天检查一次
type: 'worker', // 每台机器,随机指定某个进程进行执行定时任务
// immediate: true, // 为true时,启动时直接执行
};
}
/**
* subscribe 是真正定时任务执行时被运行的函数
*/
async subscribe() {
const { ctx } = this;
ctx.logger.info('开始清理日志!');
this.clearLog();
}
async clearLog() {
const { ctx } = this;
const loggerPath = ctx.app.config.logger.dir; // eg: /home/webserver/logs/logger/flat_cms/prod
ctx.logger.info('loggerPath: ', loggerPath);
const twoCount = (count: number) => {
return count < 10 ? '0' + count : count.toString();
};
// 删除文件、文件夹
const unlinkFile = (logNameList: string[], subDirPath: string) => {
// console.log('保留文件列表 - logNameList: ', logNameList);
const subFiles = fs.readdirSync(subDirPath);
subFiles.forEach(fileName => {
const filePath = `${subDirPath}/${fileName}`;
const state = fs.statSync(filePath);
if (state.isFile()) {
if (!logNameList.includes(fileName)) {
fs.unlinkSync(filePath);
// console.log('删除文件:', fileName);
}
} else if (state.isDirectory()) {
const workerProcess = child_process.exec(`rm -rf ${filePath}`,
(error:any) => {
if (error) {
ctx.logger.info('删除文件夹异常 Error code: ' + error.code)
}
});
workerProcess.on('exit', function (code) {
ctx.logger.info('子进程已退出,退出码 ' + code);
})
}
});
};
// 获取最近三天 日志文件
const logNameList: string[] = [];
CLEAR_WHITE_LIST.forEach((logPath)=> {
logNameList.push(logPath); // eg: common-error.log
});
[ new Date(Date.now() - 3600 * 1000 * 24 * 2), new Date(Date.now() - 3600 * 1000 * 24), new Date() ].forEach(timeObj => {
const logSuffix = `${timeObj.getFullYear()}-${twoCount(timeObj.getMonth() + 1)}-${twoCount(timeObj.getDate())}`; // 简单日期处理,不用moment模块
CLEAR_WHITE_LIST.forEach((logPath)=> {
const logName = `${logPath}.${logSuffix}`; // eg: common-error.log.2021-03-06
logNameList.push(logName);
});
});
unlinkFile(logNameList, loggerPath);
ctx.logger.info('清理日志结束!');
}
}
module.exports = ClearLogs;CPU趋势、历史记录 分析和定位
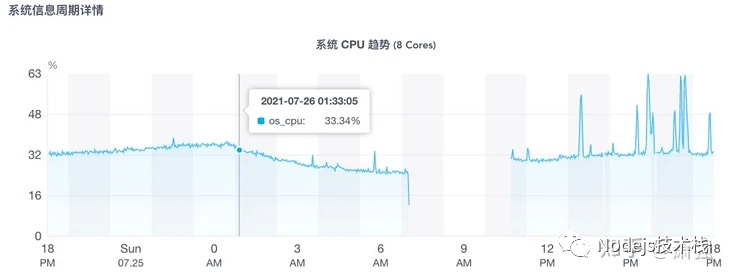
接入NodeJS性能监控后, CPU过高时有钉钉告警, 然后通过 CPU趋势图可定位到 CPU 占用过高前 分钟 级别的细粒度信息, 例如:确定 2021.07.29 17:30 ~ 2021.07.29 17:32 这段时间内CPU异常。
结合这段时间内用户访问历史, 可整理缩小范围,知道访问了哪些页面、请求了哪些API接口导致CPU过高。
一次可能看不出,每次出现整理一份日志记录, 多份数据对比可进一步缩小访问哪些页面导致CPU过高问题范围。
复现问题
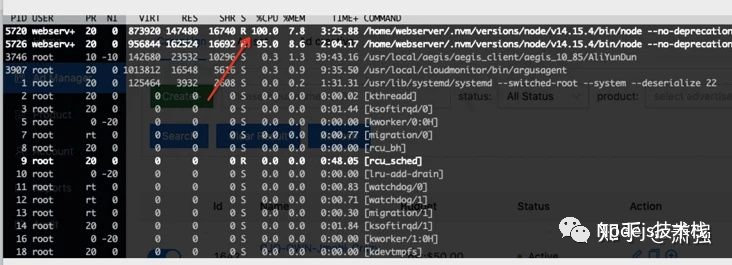
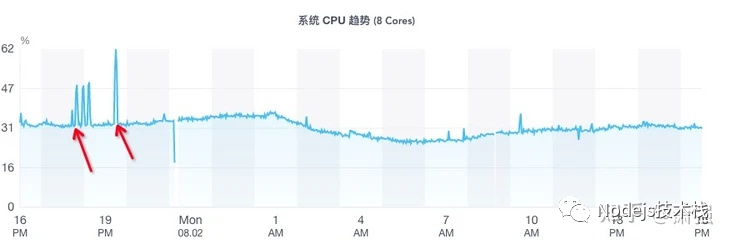
有了日志对比,可模拟访问页面,同时登陆服务器运行指令:top -c 观察CPU运行情况,访问上述整理出现CPU过高时 1 ~ 2分钟内的每一路由 模拟复现问题。
备注:NodeJS 性能监控平台查看 CPU 运行数据会有一定延时, 还是直接登录服务器指令查看更实时!
通过模拟访问定位到访问某路由导致 CPU过高!
定位思路小总结
总的来说定位问题 是以下四步骤:
- 分析 火焰图, 试图根据 火焰图 定位到具体代码;
- 分析 GC Trace, 判断是否 代码 内存泄露 导致CPU 过高;
- 单独服务器部署,排除干扰,确定是否业务代码导致CPU占用率高, 添加每个路由(页面路由、API请求路由)的日志(日志定时清理);
- 通过对比 CPU 飙高前 2~ 3分钟内请求的页面, 找出对应页面、二级页面等 进行访问 观察 对应服务器CPU占用值。
解决问题
以上确定了具体路由后, 就能深入其业务代码(100~200行)查看原因。
最终定位是某个二级弹层请求数据(API路由)时,如果该业务数据满足某一条件时,会将做全表查询, 对 十多万数据进行遍历处理 导致CPU飙高!藏的很深!
原因:历史代码没考虑性能, 有全表查询逻辑, 当然一开始业务表数据 几千条数据 不会触发,随着业务演进,数据量增加至 十万级别 就出现CPU飙升100%情况!
解决:定位到原因解决就简单多了,当然,改动的不是一个API路由,而是对应数据库表关联的所有业务代码。历史代码太多,改动了近10个API路由。
解决的具体方案不展开了, 简述就是 懒加载、MY SQL 语句优化相关:
问题:数据量大时,根据条件检索特别慢
解决:1)给检索字段添加索引;2)部分根据模糊匹配(LIKE '%${filterVar}%')前端过滤。
前端过滤 是对当前页数据进行过滤, 配合 pageSize 最大值调整,例如:调整为当前页最多显示5000, 检索效果、交互欠佳;后续考虑大数据检索,新检索条件最好通过新增字段 实现(方便添加索引);
中台系统列表项数据懒加载
问题:中台系统列表项数据量过大(万级别),导致性能、交互问题,
解决:进入页面 或 onFocus 请求 Top 100数据, 用户输入后 配合 抖动函数实时更新列表;小总结
本文主要分享 Node.js 项目运行时出现 CPU 飙升 100% 时, 排查、定位 到具体业务代码的思路。偶发的线上Node.js问题排查需要各种工具辅助,推荐 alinode 、 Easy-Monitor 这类集成了多种工具的应用性能监控与线上故障定位解决方案。当然网上各种总结帖, CPU 过高问题原因很多,本文提供一种定位思路。有其他更好方法请评论区补充~
参考博文
- node进程cpu 100%问题排查
- NodeJs调试指南
- 唯快不破让NodeJs更快一些
- 深入浅出Node(第五章内存控制) - 微信读书
- V8 引擎垃圾回收与内存分配
- 2019 - V8 引擎官方:GC算法更新
- Node.js 应用故障排查手册()
- Easy-Monitor 3.0 使用指南