Guava Cache 原理分析与最佳实践
在大部分互联网架构中 Cache 已经成为了必可不少的一环。常用的方案有大家熟知的 NoSQL 数据库(Redis、Memcached),也有大量的进程内缓存比如 EhCache 、Guava Cache、Caffeine 等。
本系列文章会选取本地缓存和分布式缓存(NoSQL)的优秀框架比较他们各自的优缺点、应用场景、项目中的最佳实践以及原理分析。本文主要针对本地 Cache 的老大哥 Guava Cache 进行介绍和分析。
基本用法
Guava Cache 通过简单好用的 Client 可以快速构造出符合需求的 Cache 对象,不需要过多复杂的配置,大多数情况就像构造一个 POJO 一样的简单。这里介绍两种构造 Cache 对象的方式:CacheLoader 和 Callable
▐ CacheLoader
构造 LoadingCache 的关键在于实现 load 方法,也就是在需要访问的缓存项不存在的时候 Cache 会自动调用 load 方法将数据加载到 Cache 中。这里你肯定会想假如有多个线程过来访问这个不存在的缓存项怎么办,也就是缓存的并发问题如何怎么处理是否需要人工介入,这些在下文中也会介绍到。 除了实现 load 方法之外还可以配置缓存相关的一些性质,比如过期加载策略、刷新策略 。
private static final LoadingCache<String, String> CACHE = CacheBuilder
.newBuilder()
// 最大容量为 100 超过容量有对应的淘汰机制,下文详述
.maximumSize(100)
// 缓存项写入后多久过期,下文详述
.expireAfterWrite(60 * 5, TimeUnit.SECONDS)
// 缓存写入后多久自动刷新一次,下文详述
.refreshAfterWrite(60, TimeUnit.SECONDS)
// 创建一个 CacheLoader,load 表示缓存不存在的时候加载到缓存并返回
.build(new CacheLoader<String, String>() {
// 加载缓存数据的方法
@Override
public String load(String key) {
return "cache [" + key + "]";
}
});
public void getTest() throws Exception {
CACHE.get("KEY_25487");
}▐ Callable
除了在构造 Cache 对象的时候指定 load 方法来加载缓存外,我们亦可以在获取缓存项时指定载入缓存的方法,并且可以根据使用场景在不同的位置采用不同的加载方式。
比如在某些位置可以通过二级缓存加载不存在的缓存项,而有些位置则可以直接从 DB 加载缓存项。
// 注意返回值是 Cache
private static final Cache<String, String> SIMPLE_CACHE = CacheBuilder
.newBuilder()
.build();
public void getTest1() throws Exception {
String key = "KEY_25487";
// get 缓存项的时候指定 callable 加载缓存项
SIMPLE_CACHE.get(key, () -> "cache [" + key + "]");
}缓存项加载机制
如果某个缓存过期了或者缓存项不存在于缓存中,而恰巧此此时有大量请求过来请求这个缓存项,如果没有保护机制就会导致大量的线程同时请求数据源加载数据并生成缓存项,这就是所谓的 “缓存击穿” 。
举个简单的例子,某个时刻有 100 个请求同时请求 KEY_25487 这个缓存项,而不巧这个缓存项刚好失效了,那么这 100 个线程(如果有这么多机器和流量的话)就会同时从 DB 加载这个数据,很可怕的点在于就算某一个线程率先获取到数据生成了缓存项,其他的线程还是继续请求 DB 而不会走到缓存。
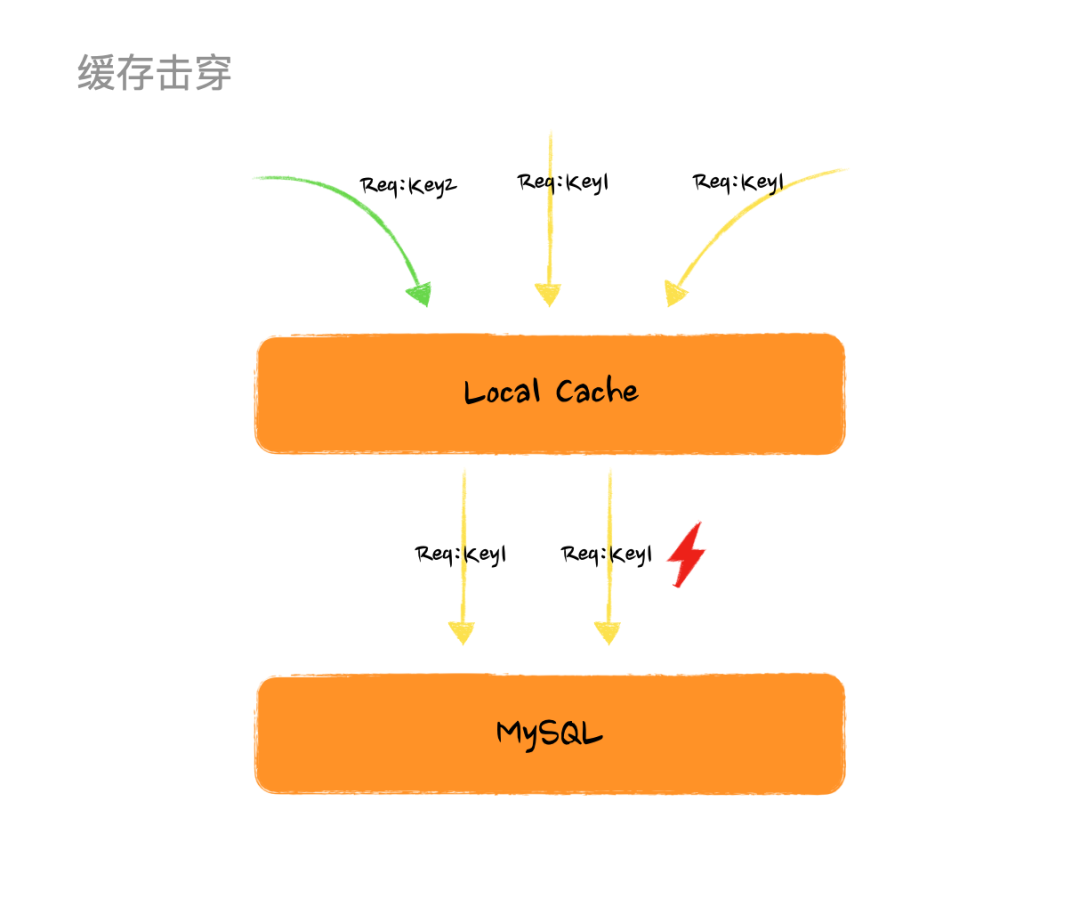
【缓存击穿图例】
看到上面这个图或许你已经有方法解这个问题了,如果多个线程过来如果我们只让一个线程去加载数据生成缓存项,其他线程等待然后读取生成好的缓存项岂不是就完美解决。那么恭喜你在这个问题上,和 Google 工程师的思路是一致的。不过采用这个方案,问题是解了但没有完全解,后面会说到它的缺陷。
其实 Guava Cache 在 load 的时候做了并发控制,在多个线程请求一个不存在或者过期的缓存项时保证只有一个线程进入 load 方法,其他线程等待直到缓存项被生成,这样就避免了大量的线程击穿缓存直达 DB 。不过试想下如果有上万 QPS 同时过来会有大量的线程阻塞导致线程无法释放,甚至会出现线程池满的尴尬场景,这也是说为什么这个方案解了 “缓存击穿” 问题但又没完全解。
上述机制其实就是 expireAfterWrite/expireAfterAccess 来控制的,如果你配置了过期策略对应的缓存项在过期后被访问就会走上述流程来加载缓存项。
缓存项刷新机制
缓存项的刷新和加载看起来是相似的,都是让缓存数据处于最新的状态。区别在于:
- 缓存项加载是一个被动的过程,而缓存刷新是一个主动触发动作。如果缓存项不存在或者过期只有下次 get 的时候才会触发新值加载。而缓存刷新则更加主动替换缓存中的老值。
- 另外一个很重要点的在于,缓存刷新的项目一定是存在缓存中的,他是对老值的替换而非是对 NULL 值的替换。
由于缓存项刷新的前提是该缓存项存在于缓存中,那么缓存的刷新就不用像缓存加载的流程一样让其他线程等待而是允许一个线程去数据源获取数据,其他线程都先返回老值直到异步线程生成了新缓存项。
这个方案完美解决了上述遇到的 “缓存击穿” 问题,不过他的前提是已经生成缓存项了。在实际生产情况下我们可以做 缓存预热 ,提前生成缓存项,避免流量洪峰造成的线程堆积。
这套机制在 Guava Cache 中是通过 refreshAfterWrite 实现的,在配置刷新策略后,对应的缓存项会按照设定的时间定时刷新,避免线程阻塞的同时保证缓存项处于最新状态。
但他也不是完美的,比如他的限制是缓存项已经生成,并且如果恰巧你运气不好,大量的缓存项同时需要刷新或者过期, 就会有大量的线程请求 DB,这就是常说的 “缓存血崩”。
缓存项异步刷新机制
上面说到缓存项大面积失效或者刷新会导致雪崩,那么就只能限制访问 DB 的数量了,位置有三个地方:
- 源头:因为加载缓存的线程就是前台请求线程,所以如果控制请求线程数量的确是减少大面积失效对 DB 的请求,那这样一来就不存在高并发请求,就算不用缓存都可以。
- 中间层缓冲:因为请求线程和访问 DB 的线程是同一个,假如在中间加一层缓冲,通过一个后台线程池去异步刷新缓存所有请求线程直接返回老值,这样对于 DB 的访问的流量就可以被后台线程池的池大小控住。
- 底层:直接控 DB 连接池的池大小,这样访问 DB 的连接数自然就少了,但是如果大量请求到连接池发现获取不到连接程序一样会出现连接池满的问题,会有大量连接被拒绝的异常。
所以比较合适的方式是通过添加一个异步线程池异步刷新数据,在 Guava Cache 中实现方案是重写 CacheLoader 的 reload 方法。
private static final LoadingCache<String, String> ASYNC_CACHE = CacheBuilder.newBuilder()
.build(
CacheLoader.asyncReloading(new CacheLoader<String, String>() {
@Override
public String load(String key) {
return key;
}
@Override
public ListenableFuture<String> reload(String key, String oldValue) throws Exception {
return super.reload(key, oldValue);
}
}, new ThreadPoolExecutor(5, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<>()))
);LocalCache 源码分析
先整体看下 Cache 的类结构,下面的这些子类表示了不同的创建方式本质还都是 LocalCache
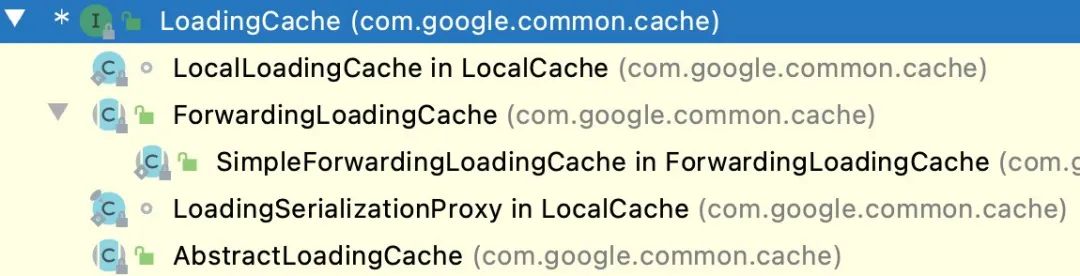
【Cache 类图】
核心代码都在 LocalCache 这个文件中,并且通过这个继承关系可以看出 Guava Cache 的本质就是 ConcurrentMap。

【LocalCache 继承与实现】
在看源码之前先理一下流程,先理清思路。如果想直接看源码理解流程可以先跳过这张图 ~
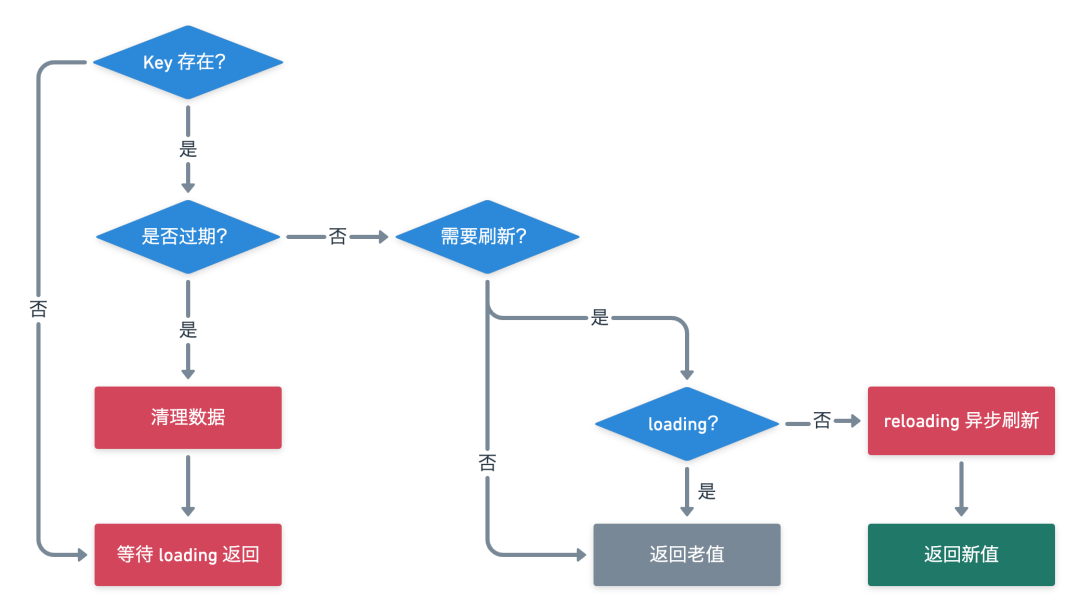
【 get 缓存数据流程图】
这里核心理一下 Get 的流程,put 阶段比较简单就不做分析了。
▐ LocalCache#get
V get(K key, CacheLoader<? super K, V> loader) throws ExecutionException {
int hash = hash(checkNotNull(key));
// 根据 hash 获取对应的 segment 然后从 segment 获取具体值
return segmentFor(hash).get(key, hash, loader);
}▐ Segment#get
V get(K key, int hash, CacheLoader<? super K, V> loader) throws ExecutionException {
checkNotNull(key);
checkNotNull(loader);
try {
// count 表示在这个 segment 中存活的项目个数
if (count != 0) {
// 获取 segment 中的元素 (ReferenceEntry) 包含正在 load 的数据
ReferenceEntry<K, V> e = getEntry(key, hash);
if (e != null) {
long now = map.ticker.read();
// 获取缓存值,如果是 load,invalid,expired 返回 null,同时检查是否过期了,过期移除并返回 null
V value = getLiveValue(e, now);
if (value != null) {
// 记录访问时间
recordRead(e, now);
// 记录缓存命中一次
statsCounter.recordHits(1);
// 刷新缓存并返回缓存值 ,后面展开
return scheduleRefresh(e, key, hash, value, now, loader);
}
ValueReference<K, V> valueReference = e.getValueReference();
// 如果在 loading 等着 ,后面展开
if (valueReference.isLoading()) {
return waitForLoadingValue(e, key, valueReference);
}
}
}
// 走到这说明从来没写入过值 或者 值为 null 或者 过期(数据还没做清理),后面展开
return lockedGetOrLoad(key, hash, loader);
} catch (ExecutionException ee) {
Throwable cause = ee.getCause();
if (cause instanceof Error) {
throw new ExecutionError((Error) cause);
} else if (cause instanceof RuntimeException) {
throw new UncheckedExecutionException(cause);
}
throw ee;
} finally {
postReadCleanup();
}
}▐ Segment#scheduleRefresh
// com.google.common.cache.LocalCache.Segment#scheduleRefresh
V scheduleRefresh(
ReferenceEntry<K, V> entry,
K key,
int hash,
V oldValue,
long now,
CacheLoader<? super K, V> loader) {
if (
// 配置了刷新策略 refreshAfterWrite
map.refreshes()
// 到刷新时间了
&& (now - entry.getWriteTime() > map.refreshNanos)
// 没在 loading
&& !entry.getValueReference().isLoading()) {
// 开始刷新,下面展开
V newValue = refresh(key, hash, loader, true);
if (newValue != null) {
return newValue;
}
}
return oldValue;
}
// com.google.common.cache.LocalCache.Segment#refresh
V refresh(K key, int hash, CacheLoader<? super K, V> loader, boolean checkTime) {
// 插入 loading 节点
final LoadingValueReference<K, V> loadingValueReference =
insertLoadingValueReference(key, hash, checkTime);
if (loadingValueReference == null) {
return null;
}
// 异步刷新,下面展开
ListenableFuture<V> result = loadAsync(key, hash, loadingValueReference, loader);
if (result.isDone()) {
try {
return Uninterruptibles.getUninterruptibly(result);
} catch (Throwable t) {
// don't let refresh exceptions propagate; error was already logged
}
}
return null;
}
// com.google.common.cache.LocalCache.Segment#loadAsync
ListenableFuture<V> loadAsync(
final K key,
final int hash,
final LoadingValueReference<K, V> loadingValueReference,
CacheLoader<? super K, V> loader) {
// 通过 loader 异步加载数据,下面展开
final ListenableFuture<V> loadingFuture = loadingValueReference.loadFuture(key, loader);
loadingFuture.addListener(
new Runnable() {
@Override
public void run() {
try {
getAndRecordStats(key, hash, loadingValueReference, loadingFuture);
} catch (Throwable t) {
logger.log(Level.WARNING, "Exception thrown during refresh", t);
loadingValueReference.setException(t);
}
}
},
directExecutor());
return loadingFuture;
}
// com.google.common.cache.LocalCache.LoadingValueReference#loadFuture
public ListenableFuture<V> loadFuture(K key, CacheLoader<? super K, V> loader) {
try {
stopwatch.start();
// oldValue 指在写入 loading 节点前这个位置的值,如果这个位置之前没有值 oldValue 会被赋值为 UNSET
// UNSET.get() 值为 null ,所以这个缓存项从来没有进入缓存需要同步 load 具体原因前面提到了,如果通过
// 异步 reload ,由于没有老值会导致其他线程返回的都是 null
V previousValue = oldValue.get();
if (previousValue == null) {
V newValue = loader.load(key);
return set(newValue) ? futureValue : Futures.immediateFuture(newValue);
}
// 异步 load
ListenableFuture<V> newValue = loader.reload(key, previousValue);
if (newValue == null) {
return Futures.immediateFuture(null);
}
// To avoid a race, make sure the refreshed value is set into loadingValueReference
// *before* returning newValue from the cache query.
return transform(
newValue,
new com.google.common.base.Function<V, V>() {
@Override
public V apply(V newValue) {
LoadingValueReference.this.set(newValue);
return newValue;
}
},
directExecutor());
} catch (Throwable t) {
ListenableFuture<V> result = setException(t) ? futureValue : fullyFailedFuture(t);
if (t instanceof InterruptedException) {
Thread.currentThread().interrupt();
}
return result;
}
}▐ Segment#waitForLoadingValue
V waitForLoadingValue(ReferenceEntry<K, V> e, K key, ValueReference<K, V> valueReference)
throws ExecutionException {
// 首先你要是一个 loading 节点
if (!valueReference.isLoading()) {
throw new AssertionError();
}
checkState(!Thread.holdsLock(e), "Recursive load of: %s", key);
// don't consider expiration as we're concurrent with loading
try {
V value = valueReference.waitForValue();
if (value == null) {
throw new InvalidCacheLoadException("CacheLoader returned null for key " + key + ".");
}
// re-read ticker now that loading has completed
long now = map.ticker.read();
recordRead(e, now);
return value;
} finally {
statsCounter.recordMisses(1);
}
}
// com.google.common.cache.LocalCache.LoadingValueReference#waitForValue
public V waitForValue() throws ExecutionException {
return getUninterruptibly(futureValue);
}
// com.google.common.util.concurrent.Uninterruptibles#getUninterruptibly
public static <V> V getUninterruptibly(Future<V> future) throws ExecutionException {
boolean interrupted = false;
try {
while (true) {
try {
// hang 住,如果该线程被打断了继续回去 hang 住等结果,直到有结果返回
return future.get();
} catch (InterruptedException e) {
interrupted = true;
}
}
} finally {
if (interrupted) {
Thread.currentThread().interrupt();
}
}
}▐ Segment#lockedGetOrLoad
V lockedGetOrLoad(K key, int hash, CacheLoader<? super K, V> loader) throws ExecutionException {
ReferenceEntry<K, V> e;
ValueReference<K, V> valueReference = null;
LoadingValueReference<K, V> loadingValueReference = null;
boolean createNewEntry = true;
// 要对 segment 写操作 ,先加锁
lock();
try {
// re-read ticker once inside the lock
long now = map.ticker.read();
preWriteCleanup(now);
// 这里基本就是 HashMap 的代码,如果没有 segment 的数组下标冲突了就拉一个链表
int newCount = this.count - 1;
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
int index = hash & (table.length() - 1);
ReferenceEntry<K, V> first = table.get(index);
for (e = first; e != null; e = e.getNext()) {
K entryKey = e.getKey();
if (e.getHash() == hash
&& entryKey != null
&& map.keyEquivalence.equivalent(key, entryKey)) {
valueReference = e.getValueReference();
// 如果在加载中 不做任何处理
if (valueReference.isLoading()) {
createNewEntry = false;
} else {
V value = valueReference.get();
// 如果缓存项为 null 数据已经被删除,通知对应的 queue
if (value == null) {
enqueueNotification(
entryKey, hash, value, valueReference.getWeight(), RemovalCause.COLLECTED);
// 这个是 double check 如果缓存项过期 数据没被删除,通知对应的 queue
} else if (map.isExpired(e, now)) {
// This is a duplicate check, as preWriteCleanup already purged expired
// entries, but let's accommodate an incorrect expiration queue.
enqueueNotification(
entryKey, hash, value, valueReference.getWeight(), RemovalCause.EXPIRED);
// 再次看到的时候这个位置有值了直接返回
} else {
recordLockedRead(e, now);
statsCounter.recordHits(1);
return value;
}
// immediately reuse invalid entries
writeQueue.remove(e);
accessQueue.remove(e);
this.count = newCount; // write-volatile
}
break;
}
}
// 没有 loading ,创建一个 loading 节点
if (createNewEntry) {
loadingValueReference = new LoadingValueReference<>();
if (e == null) {
e = newEntry(key, hash, first);
e.setValueReference(loadingValueReference);
table.set(index, e);
} else {
e.setValueReference(loadingValueReference);
}
}
} finally {
unlock();
postWriteCleanup();
}
if (createNewEntry) {
try {
// Synchronizes on the entry to allow failing fast when a recursive load is
// detected. This may be circumvented when an entry is copied, but will fail fast most
// of the time.
synchronized (e) {
return loadSync(key, hash, loadingValueReference, loader);
}
} finally {
statsCounter.recordMisses(1);
}
} else {
// The entry already exists. Wait for loading.
return waitForLoadingValue(e, key, valueReference);
}
}总结
结合上面图以及源码我们发现在整个流程中 GuavaCache 是没有额外的线程去做数据清理和刷新的,基本都是通过 Get 方法来触发这些动作,减少了设计的复杂性和降低了系统开销。
简单回顾下 Get 的流程以及在每个阶段做的事情,返回的值。首先判断缓存是否过期然后判断是否需要刷新,如果过期了就调用 loading 去同步加载数据(其他线程阻塞),如果是仅仅需要刷新调用 reloading 异步加载(其他线程返回老值)。
所以如果 refreshTime > expireTime 意味着永远走不到缓存刷新逻辑,缓存刷新是为了在缓存有效期内尽量保证缓存数据一致性所以在配置刷新策略和过期策略时一定保证 refreshTime < expireTime 。
最后关于 Guava Cache 的使用建议 (最佳实践) :
- 如果刷新时间配置的较短一定要重载 reload 异步加载数据的方法,传入一个自定义线程池保护 DB
- 失效时间一定要大于刷新时间
- 如果是常驻内存的一些少量数据失效时间可以配置的较长刷新时间配置短一点 (根据业务对缓存失效容忍度)