iOS底层 - 关于死锁,你了解多少?
前言
我们从GCD函数和队列的内容中最后的经典案例中关于死锁的案例开始,从死锁的发生开始,看看其产生的本质原因是为什么。话不多说这就开始。
引用我们在GCD函数和队列一文中和死锁相关的内容:
- 创建串行调度队列的解释:
当我们希望任务以特定的顺序执行时,串行队列很有用。串行队列一次只执行一个任务,并且总是从队列的头部拉去任务。我们可以使用串行队列而不是锁来保护共享资源或可变数据结构。与锁不同,串行队列确保任务以可以预测的顺序执行。而且 只要我们将任务异步提交到串行队列,队列就永远不会死锁。
- 在将单个任务添加到队列中的解释:
有两种方法可以将任务添加到队列中:异步或同步。如果可能,使用dispatch_async和dispatch_async_f函数的异步执行优先于同步替代方案。当您将块对象或函数添加到队列时,无法知道该代码何时执行。因此,异步添加块或函数可让您安排代码的执行并继续从调用线程执行其他工作。如果您从应用程序的主线程调度任务,这尤其重要——也许是为了响应某些用户事件。 尽管您应该尽可能以异步方式添加任务,但有时您仍可能需要同步添加任务以防止竞争条件或其他同步错误。在这些情况下,您可以使用dispatch_sync和dispatch_sync_f函数将任务添加到队列中。这些函数会阻塞当前的执行线程,直到指定的任务完成执行。 重要提示: 您永远不应从在您计划传递给函数的同一队列中执行的任务调用dispatch_sync或dispatch_sync_f函数。这对于保证死锁的串行队列尤其重要,但对于并发队列也应避免。
以上两部分内容,是在阐述串行队列的概念解释和将任务添加到队列中的两种方式的规范内容。总的来说,是帮助我们在正确使用串行队列,以及在将任务添加到队列中时,避免死锁的发生。 下面,我们从案例中的死锁开始。
死锁的发生
正如上面的重要提示中锁阐述的一样,我们永远不应该将函数添加到队列中执行任务时使用同步的方式。这对于保证死锁的串行队列尤其重要,但对于并发队列也应避免。
的确,这是避免死锁的重要思路,但是,还是难以避免,在实际开发中,我们使用了下面的代码:
串行队列,同步函数中同步函数
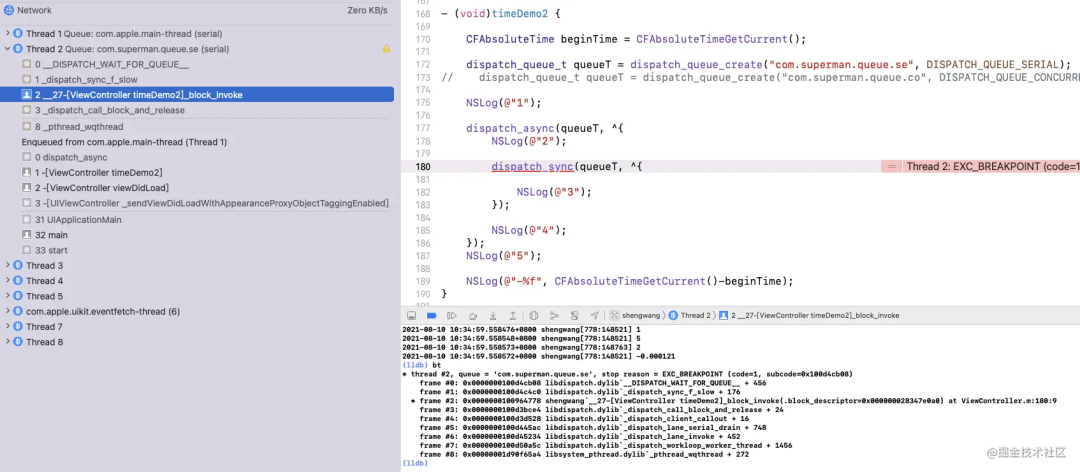
第180行,我们的程序发生来死锁,从堆栈的信息中可以看到是 :
libdispatch.dylib _dispatch_sync_f_slow: -> libdispatch.dylib __DISPATCH_WAIT_FOR_QUEUE__:
跟踪流程
在180行,打上断点。在GCD函数和队列篇章中,我们知道dispatch_syn函数的执行流程如下:
dispatch_sync -> _dispatch_sync_f -> _dispatch_sync_f_inline
在_dispatch_sync_f_inline中,有五条分支,我们分别下五个符号断点:
_dispatch_sync_f_inline
static inline void
_dispatch_sync_f_inline(dispatch_queue_t dq, void *ctxt,
dispatch_function_t func, uintptr_t dc_flags)
{
if (likely(dq->dq_width == 1)) {
return _dispatch_barrier_sync_f(dq, ctxt, func, dc_flags);
}
if (unlikely(dx_metatype(dq) != _DISPATCH_LANE_TYPE)) {
DISPATCH_CLIENT_CRASH(0, "Queue type doesn't support dispatch_sync");
}
dispatch_lane_t dl = upcast(dq)._dl;
// 全局并发队列和绑定到非分派线程的队列
// 总是落在慢的情况下 DISPATCH_ROOT_QUEUE_STATE_INIT_VALUE
if (unlikely(!_dispatch_queue_try_reserve_sync_width(dl))) {
return _dispatch_sync_f_slow(dl, ctxt, func, 0, dl, dc_flags);
}
if (unlikely(dq->do_targetq->do_targetq)) {
return _dispatch_sync_recurse(dl, ctxt, func, dc_flags);
}
_dispatch_introspection_sync_begin(dl);
_dispatch_sync_invoke_and_complete(dl, ctxt, func DISPATCH_TRACE_ARG(
_dispatch_trace_item_sync_push_pop(dq, ctxt, func, dc_flags)));
}先来到了 _dispatch_barrier_sync_f 分支
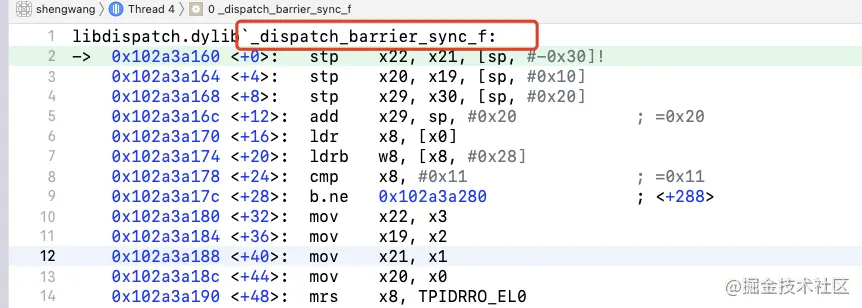
_dispatch_barrier_sync_f
static void
_dispatch_barrier_sync_f(dispatch_queue_t dq, void *ctxt,
dispatch_function_t func, uintptr_t dc_flags)
{
_dispatch_barrier_sync_f_inline(dq, ctxt, func, dc_flags);
}再下 _dispatch_barrier_sync_f_inline 符号断点, 很遗憾没有断住,直接来到了 _dispatch_sync_f_slow :
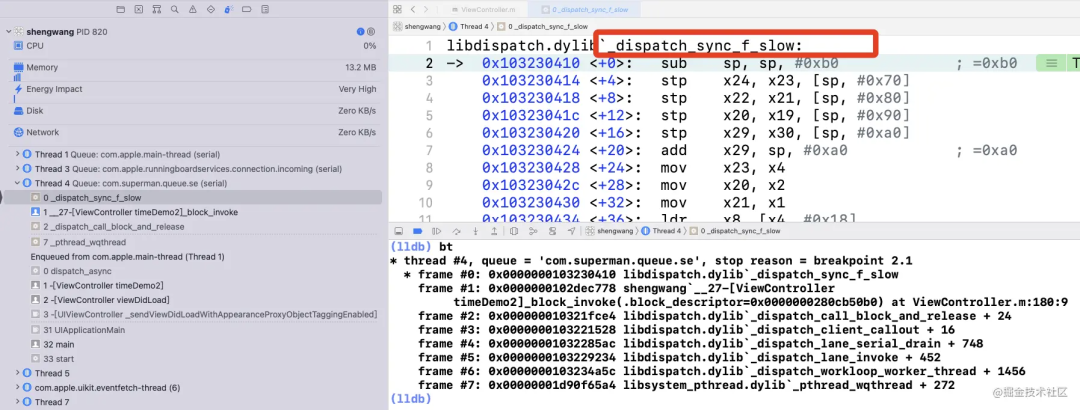
我们来到 _dispatch_barrier_sync_f_inline 内部的实现:
_dispatch_barrier_sync_f_inline
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_barrier_sync_f_inline(dispatch_queue_t dq, void *ctxt,
dispatch_function_t func, uintptr_t dc_flags)
{
dispatch_tid tid = _dispatch_tid_self();
if (unlikely(dx_metatype(dq) != _DISPATCH_LANE_TYPE)) {
DISPATCH_CLIENT_CRASH(0, "Queue type doesn't support dispatch_sync");
}
dispatch_lane_t dl = upcast(dq)._dl;
// 更正确的做法是合并线程的qos
// 刚刚获得了进入队列状态的barrier锁。
//
// 然而,这对于快速路径来说太昂贵了,所以跳过它。
// 选择的权衡是,如果队列在较低优先级的线程上
// 与此快速路径,此线程可能收到无用的覆盖。
//
// 全局并发队列和绑定到非分派线程的队列
// 总是落在慢的情况下 DISPATCH_ROOT_QUEUE_STATE_INIT_VALUE
if (unlikely(!_dispatch_queue_try_acquire_barrier_sync(dl, tid))) {
return _dispatch_sync_f_slow(dl, ctxt, func, DC_FLAG_BARRIER, dl,
DC_FLAG_BARRIER | dc_flags);
}
if (unlikely(dl->do_targetq->do_targetq)) {
return _dispatch_sync_recurse(dl, ctxt, func,
DC_FLAG_BARRIER | dc_flags);
}
_dispatch_introspection_sync_begin(dl);
_dispatch_lane_barrier_sync_invoke_and_complete(dl, ctxt, func
DISPATCH_TRACE_ARG(_dispatch_trace_item_sync_push_pop(
dq, ctxt, func, dc_flags | DC_FLAG_BARRIER)));
}(_dispatch_sync_f_inline 和 _dispatch_barrier_sync_f_inline 内部实现有点相似)
其内部的第二个分支便是调用 _dispatch_sync_f_slow
_dispatch_sync_f_slow
DISPATCH_NOINLINE
static void
_dispatch_sync_f_slow(dispatch_queue_class_t top_dqu, void *ctxt,
dispatch_function_t func, uintptr_t top_dc_flags,
dispatch_queue_class_t dqu, uintptr_t dc_flags)
{
dispatch_queue_t top_dq = top_dqu._dq;
dispatch_queue_t dq = dqu._dq;
if (unlikely(!dq->do_targetq)) {
return _dispatch_sync_function_invoke(dq, ctxt, func);
}
pthread_priority_t pp = _dispatch_get_priority();
struct dispatch_sync_context_s dsc = {
.dc_flags = DC_FLAG_SYNC_WAITER | dc_flags,
.dc_func = _dispatch_async_and_wait_invoke,
.dc_ctxt = &dsc,
.dc_other = top_dq,
.dc_priority = pp | _PTHREAD_PRIORITY_ENFORCE_FLAG,
.dc_voucher = _voucher_get(),
.dsc_func = func,
.dsc_ctxt = ctxt,
.dsc_waiter = _dispatch_tid_self(),
};
_dispatch_trace_item_push(top_dq, &dsc);
__DISPATCH_WAIT_FOR_QUEUE__(&dsc, dq);
if (dsc.dsc_func == NULL) {
// dsc_func being cleared means that the block ran on another thread ie.
// case (2) as listed in _dispatch_async_and_wait_f_slow.
dispatch_queue_t stop_dq = dsc.dc_other;
return _dispatch_sync_complete_recurse(top_dq, stop_dq, top_dc_flags);
}
_dispatch_introspection_sync_begin(top_dq);
_dispatch_trace_item_pop(top_dq, &dsc);
_dispatch_sync_invoke_and_complete_recurse(top_dq, ctxt, func,top_dc_flags
DISPATCH_TRACE_ARG(&dsc));
}看到其实现内容,依然会觉得和上面两个(_dispatch_sync_f_inline 和 _dispatch_barrier_sync_f_inline) 有点相似。
再次根据分支下符号断点,就断不住了,直接会崩溃,根据堆栈,我们会来到:
__DISPATCH_WAIT_FOR_QUEUE__(&dsc, dq) 的执行。
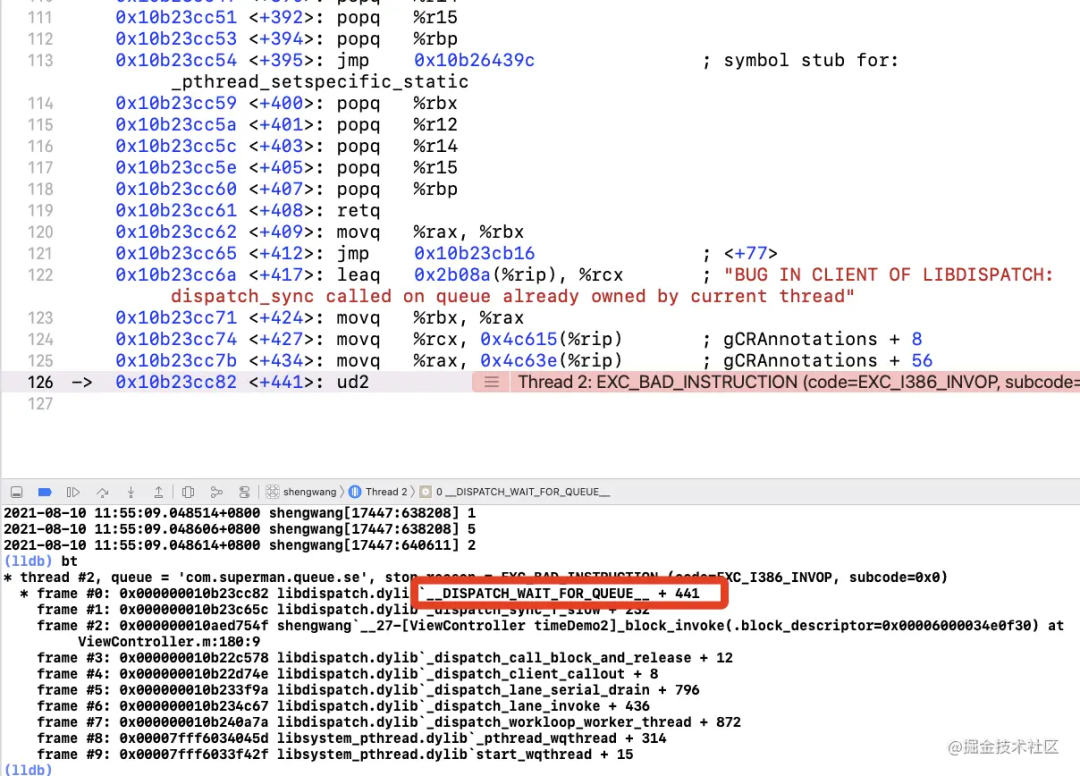
最终奔溃的点
__DISPATCH_WAIT_FOR_QUEUE__
DISPATCH_NOINLINE
static void
__DISPATCH_WAIT_FOR_QUEUE__(dispatch_sync_context_t dsc, dispatch_queue_t dq)
{
uint64_t dq_state = _dispatch_wait_prepare(dq);
if (unlikely(_dq_state_drain_locked_by(dq_state, dsc->dsc_waiter))) {
DISPATCH_CLIENT_CRASH((uintptr_t)dq_state,
"dispatch_sync called on queue "
"already owned by current thread");
}
...
}程序崩溃在这里,那么,我们就需要重点分析下这里的 if 判断条件是什么?符合了怎样的条件,以至于程序崩溃的发生。
函数对比的两个内容:
// 1、当前的队列线程的线程ID
#define _dispatch_tid_self() ((dispatch_tid)_dispatch_thread_port())
#define _dispatch_thread_port() pthread_mach_thread_np(_dispatch_thread_self())
#define _dispatch_thread_self() ((uintptr_t)pthread_self())
// 2、队列的状态
_dispatch_wait_prepare(dq);_dq_state_drain_locked_by
ISPATCH_ALWAYS_INLINE
static inline bool
_dq_state_drain_locked_by(uint64_t dq_state, dispatch_tid tid)
{
return _dispatch_lock_is_locked_by((dispatch_lock)dq_state, tid);
}
#define DLOCK_OWNER_MASK ((dispatch_lock)0xfffffffc)
DISPATCH_ALWAYS_INLINE
static inline bool
_dispatch_lock_is_locked_by(dispatch_lock lock_value, dispatch_tid tid)
{
// equivalent to _dispatch_lock_owner(lock_value) == tid
// DLOCK_OWNER_MASK 是一个很大的数 ((dispatch_lock)0xfffffffc)
// 前面的结果只要不为0 与上 DLOCK_OWNER_MASK 也不为0
// 如果前面的结果与上DLOCK_OWNER_MASK结果为0 那前面的结果 必然为0
// 最终, lock_value 和 tid 相同 才会 为 0
return ((lock_value ^ tid) & DLOCK_OWNER_MASK) == 0;
}总结
最后, 本来这个锁住要等待的线程的状态和我们的线程ID相同。也就是我们的线程本来应该在等待状态,然而这个时候,又调用了线程的队列来添加任务,告诉系统要调起此线程,结果在我们的系统中此线程又是等待的状态。所以,此次添加任务是无法实现的。
在这里,又要调起线程,然后线程又是等待状态,此时就是一个矛盾,无法继续执行下去,所以就发生了死锁。