大话Redis系列--深入探讨多路复用(下)
之前我们介绍了IO多路复用相关的知识点,但是之前对于IO多路复用的底层实现并没有做过多的深入的挖掘,今天的这篇文章准备从IO的底层实现进行深入分析。
JAVA层面的BIO和NIO
先一起回顾下上一篇文章中所说到的几个IO相关案例:
BIO
使用BIO的时候,当服务端启动之后会建立一个ServerSocket对象,如果没有新的数据抵达请求端,ServerSocket在调用accept函数的时候会堵塞当前调用线程。
当一个Socket连接到服务端的时候,accept函数会放开,然后进入到对于Socket请求的数据报文读取的阶段。这个阶段我们的写法可能如下所示:
socket.getInputStream().read(bytes);
但是直接这么使用会有个不足点,假设客户端只是建立了连接,但是没有发送数据包的话,会导致read函数执行的时候当前调用线程会被堵塞。如果没有对于数据响应部分开启额外线程处理的话,这个位置就会一直处于堵塞的状态,从而影响了后续其他socket的请求。
因此早期使用BIO的时候,对于数据的处理部分会采用额外开启线程的模式去处理。代码大致如下所示:
socket.getInputStream().read(bytes);
Thread t = new Thread(new Runnable() {
@Override
public void run() {
handleData();
}
});这种实现的不足点在于:
- 一个连接开一个线程,假设有10万个连接,岂不是要开启10个线程。开启10w个线程的话,首先单机服务器如果只有单个网卡的话是绝对不支持的,另外即使开启了多网卡模式真的保证了四元组组合数达到10w+,那么CPU的频繁切换也是非常消耗性能的。线程切换在linux操作系统中实质上是轻量级的进程切换,进程在做上下文切换的时候需要将PCB中的上下文数据保存在寄存器中(例如PC,SP,EAX寄存器),然后工作队列中元素频繁切换,用户态和内核态也需要不断进行调整,软中断指令频繁发送,所以说这种方式在高请求量的场景下是非常不佳的。
NIO
在使用NIO的时候,实质上就在早期的ServerSocket上边包装了一层,命名为了:ServerSocketChannel。这个类里面对于是否堵塞定义了一个状态变量blocking(默认还是堵塞模式)

开启了NIO的非堵塞模式之后,它内部需要我们开启一个叫做选择器的角色,(开启的方式是使用Selector的open函数),开启了选择器之后,需要将ServerSocketChannel注册到这个选择器中,并且声明自己感兴趣的事件类型:例如说accept事件,read事件,write事件,connect事件。
NIO内部的接收Socket连接部分是一个叫做select的函数,这个函数的调用会堵塞调用线程,但是一旦有数据报文抵达服务端并且成功构建连接之后,便会注册到selector注册器上,然后根据程序代码定义对于不同的事件类型执行不同的逻辑模块。
这块的逻辑案例如下:
while (true) {
selector.select();
System.out.println("select end!");
Set<SelectionKey> selectionKeys = selector.selectedKeys();
Iterator<SelectionKey> iterator = selectionKeys.iterator();
while (iterator.hasNext()) {
SelectionKey selectionKey = iterator.next();
if (selectionKey.isAcceptable()) {
SocketChannel socketChannel = serverSocket.accept();
socketChannel.configureBlocking(false);
socketChannel.register(selector, SelectionKey.OP_READ);
System.out.println("client is connected!");
} else if (selectionKey.isReadable()) {
SocketChannel socketChannel = (SocketChannel) selectionKey.channel();
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
int len = socketChannel.read(byteBuffer);
if (len > 0) {
System.out.println("receive data!" + new String(byteBuffer.array(),0,len));
} else if (len == -1) {
System.out.println("client is close");
socketChannel.close();
}
}
iterator.remove();
}
}NIO在接受socket连接的时候依旧会是堵塞调用线程,但是在处理请求的时候可以做到非堵塞的方式,
好了,从Java的语言层面我们大概地回顾了之前讲过的知识点,接下来我们抛开JVM的层面,从os层去认知这块内容点吧。
硬件设备知识补充
在学习后边的知识之前我们需要先了解下cpu底层的一些细节知识内容。CPU内部会有许多个小引脚,其本质就是一簇一簇的电线,专门用于接收外界的中断信号。图中的intr其实就是中断控制器和cpu引脚链接的部分,8259A中断控制器内部也有多个外部接口,这些外部接口会和各个硬件设备打通,接收外部传入的中断信号内容。
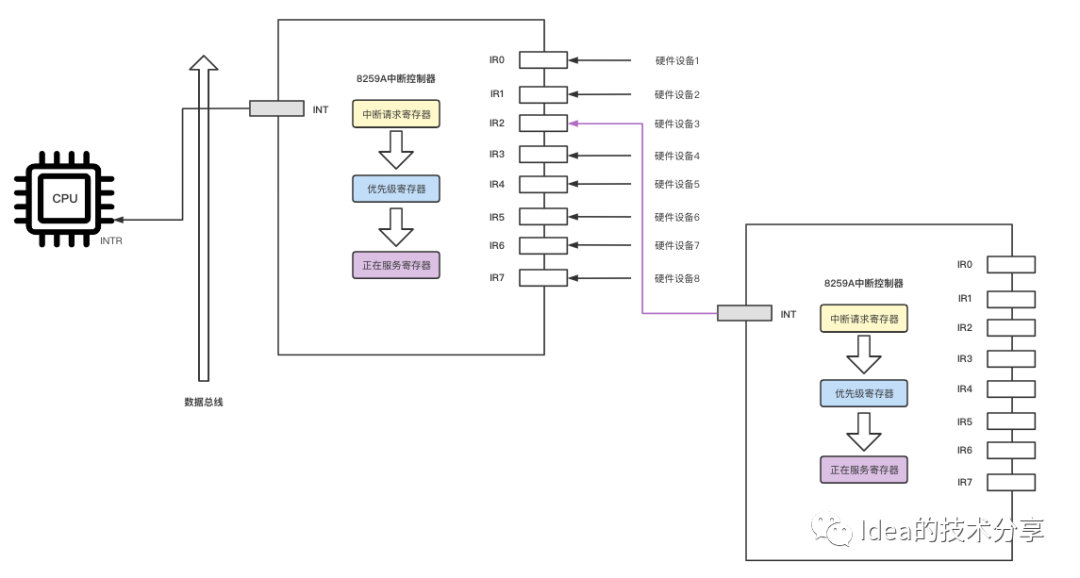
计算机的硬件设备众多,光靠一个中断控制器是完全不够的,因此还需要有多个级联的中断控制器,所以就会出现上图中的粉红色箭头所连接的部分。
Linux内部的中断主要分为了硬中断和软中断,前者是由硬件设备发出的中断信号,后者是由程序发出的中断信号。
Linux内部的IRQ
IRQ number是一个虚拟的interrupt ID,和硬件无关,仅仅是被CPU用来标识一个外设中断。假设同一秒钟有10个硬件设备往单个cpu发送中断信号指令,那么就会有十个不同的irq请求被发送到cpu中,每个irq请求都会携带一个顺序号码,我们大致可以看作为irq0,irq1,irq2,irq3....irq9。这十个irq请求的序号会进入到中断控制器的内部。如下图部分所示:
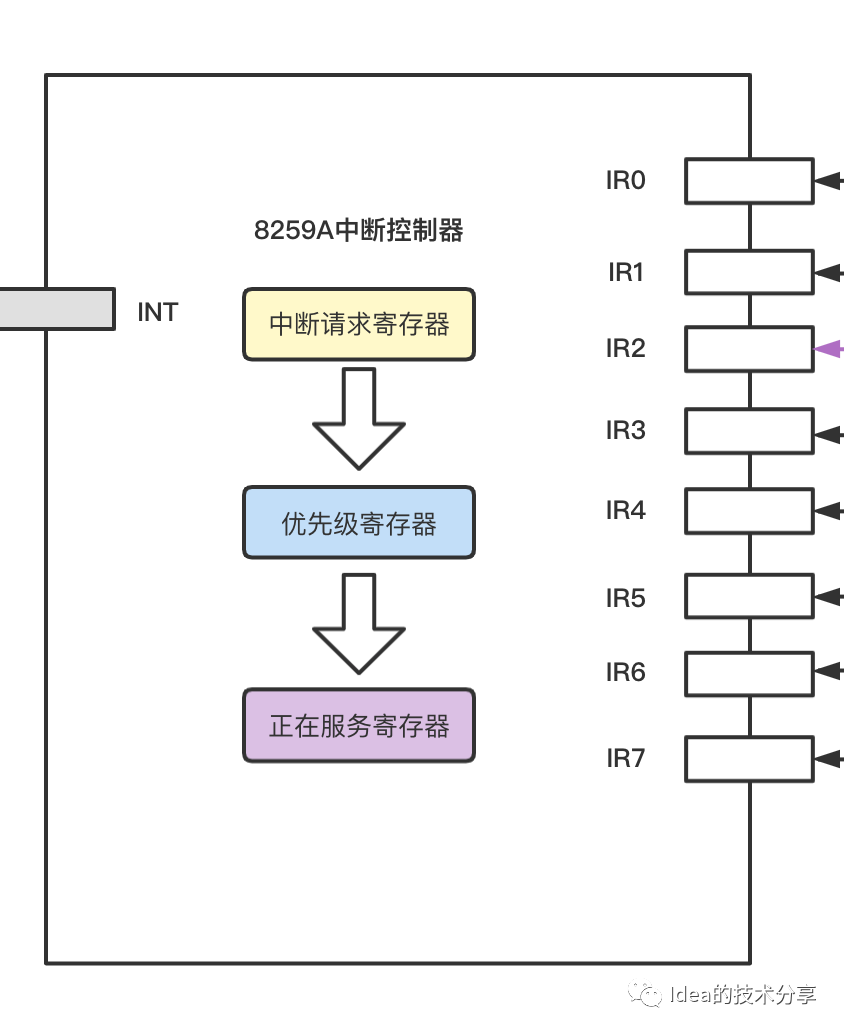
这里我大概介绍下这些个寄存器内部发生了怎样的变化。
中断请求寄存器:
内部会有一个bitset集合,例如鼠标硬件发送了一个irq3信号,那么就会对鼠标硬件对应的索引下标位的bitset进行标记为1的操作,表示当前哪个硬件设备需要发送中断信号。
优先级寄存器主要是用于对同时多个中断的请求信号进行排序,主要就是根据irq请求抵达的先后顺序进行一个排序,诸如irq0,irq1,irq2,irq3.....
正在服务寄存器其实可以理解为将优先级最高的irq提取到该模块,然后会通过数据总线给cpu发送一个中断信号。这个中断信号会携带有一个向量值,该向量值内部会有对应的程序代码段地址。首先cpu接收到中断信号之后会将当前处在工作队列的程序上下文进行一个保存操作,然后根据irq中发来的向量值到向量表中去搜索对应的中断程序地址。
Linux底层的select,poll,epoll
上一篇文章我们有稍微提及到关于Linux底层对于socket链接的筛选模型:poll,epoll,select三种类型
接下来我们先从select模型开始说起。
select模型
select的官方介绍链接:
https://www.man7.org/linux/man-pages/man2/select.2.html
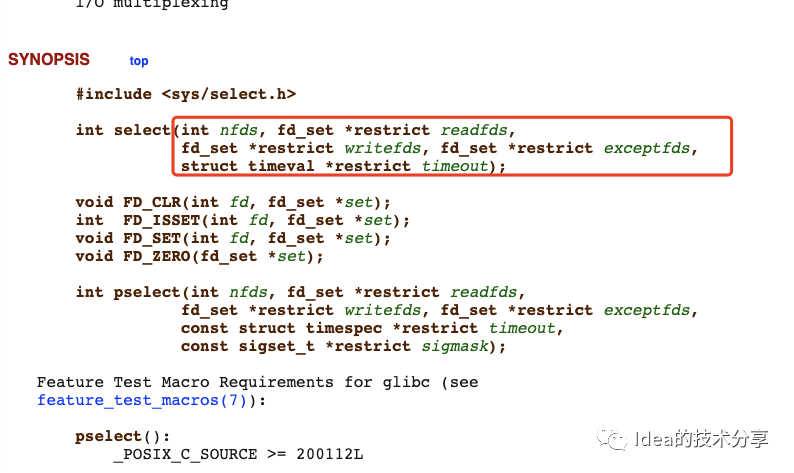
从图中可以看到select函数的入参种有一种叫做fd_set的变量,这个变量的本质是一个bitset集合,并且大小上限为1024。

select函数允许程序去监控多个fd,(这些fd均来自fd_set),当这些fd中有某个属性处于就绪状态的时候,则会返回给调用线程当前处于就绪状态的socket连接有多少个。注意如果是在循环中使用select函数,就一定要每次循环遍历的时候将fd_set这个参数清空。
select函数底层的fd_set集合是如何遍历的呢?
内核态中cpu会对fd_set集合进行轮训的遍历。一旦发现某个集合中对应的fd位为1,则相当于识别有socket连接抵达。
select函数的一些不足点
- 我们看其底层的参数重有三个bitset类型,这三种类型都有一个大小限制(1024),这也就意味着fd数目的上线必须要小于1024。
- 每次fd_set集合的数据拷贝都是需要从用户态拷贝到内核态中,因此当频繁地有外部连接进入的时候,不断的切换上下文是会对cpu造成很严重的性能损耗。
poll模型
其实poll模型和select模型比较相似,都是会对fd进行遍历,但是它使用的是数组类型的数据结构来存储fd信息,因此在存储的时候没有1024这种上限的说法。
linux的官方文档地址:
https://www.man7.org/linux/man-pages/man2/poll.2.html

poll模型也是需要遍历所有的fd集合元素,查看是否有处于就绪状态的fd,(linux内部一切皆文件,所以即使是socket连接其实本质也是一个文件描述符)。和select函数一样,poll函数在调用的时候会返回一个叫数字,这个数字表示已经就绪的连接数目。
poll函数和select函数的异同点
- poll函数虽然对于socket连接的参数使用了数组结构来进行存放,这样能够避免遇到连接上限的阈值,
- 在进行fd遍历的时候,需要将fd连接从用户态拷贝到内核态中,当连接数增加时,这一步带来的性能损耗还是比较高的。
epoll模型
在介绍了select和poll两类模型之后,我们来看看epoll模型。
这里是它的官方解释文档链接:
https://www.man7.org/linux/man-pages/man7/epoll.7.html
epoll模型内部主要有以下几个函数:
-
epoll_create
创建epoll的实例对象
-
epoll_ctl
根据epoll_id去检查各个文件描述符
-
epoll_wait
等待外界的io数据请求,可能会有堵塞
官方说明如下图所示:

epoll模型的内部会有一个叫做eventPoll的对象,它的内部存在着一个等待队列,等待队列的对象其实就是一堆等待着外部链接的socket信息。
当其中的某个socket接收到了外界传输进入的数据信息,就会将eventPoll内部等待队列的数据转移到cpu对应的工作队列中。
看起来其实epoll的工作流程还是和select差不多,但是对于socket的集合信息存储却有所不同。epoll底层使用了红黑树的数据结构,这种结构可以按照事件类型对socket的集合信息进行增删改查,相对高效稳定。
其实最近看了很多关于epoll,poll,select的资料,但是今晚时间比较晚了,所以也只好先写这么多了。说不定改天再看回来又会有新的认识。