一文读懂 | 进程并发与同步
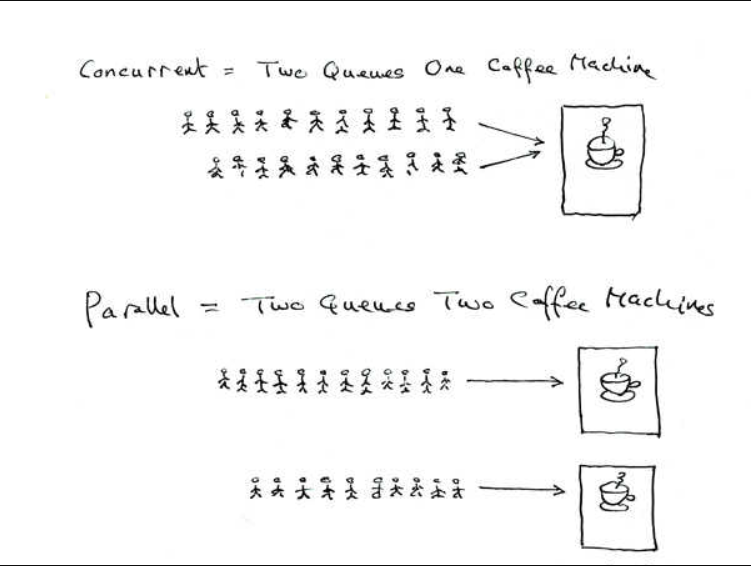
并发 是指在某一时间段内能够处理多个任务的能力,而 并行 是指同一时间能够处理多个任务的能力。并发和并行看起来很像,但实际上是有区别的,如下图(图片来源于网络):
concurrency-parallelism
上图的意思是,有两条在排队买咖啡的队列,并发只有一架咖啡机在处理,而并行就有两架的咖啡机在处理。咖啡机的数量越多,并行能力就越强。
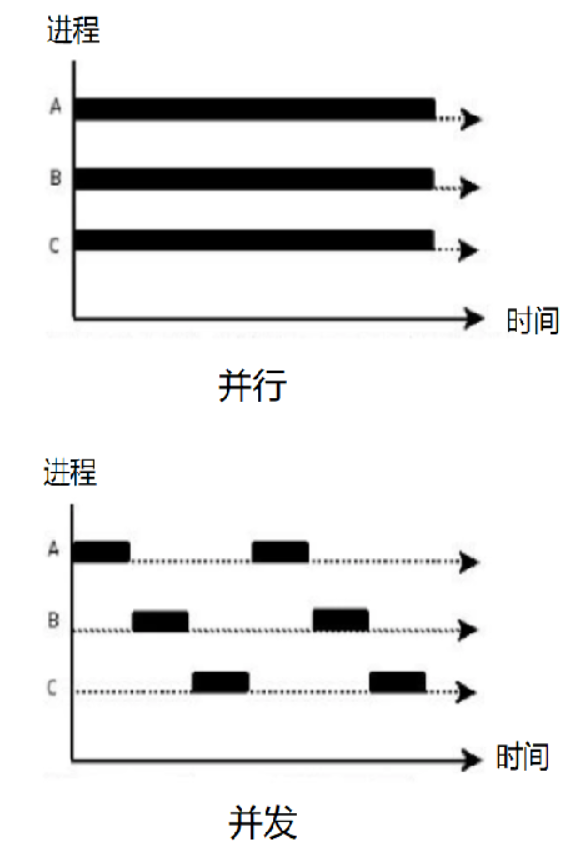
可以把上面的两条队列看成两个进程,并发就是指只有单个CPU在处理,而并行就有两个CPU在处理。为了让两个进程在单核CPU中也能得到执行,一般的做法就是让每个进程交替执行一段时间,比如让每个进程固定执行 100毫秒,执行时间使用完后切换到其他进程执行。而并行就没有这种问题,因为有两个CPU,所以两个进程可以同时执行。如下图:
concurrency-parallelism
原子操作
上面介绍过,并发有可能会打断当前执行的进程,然后替切换成其他进程执行。如果有两个进程同时对一个共享变量 count 进行加一操作,由于C语言的 count++ 操作会被翻译成如下指令:
mov eax, [count]
inc eax
mov [count], eax那么在并发的情况下,有可能出现如下问题:
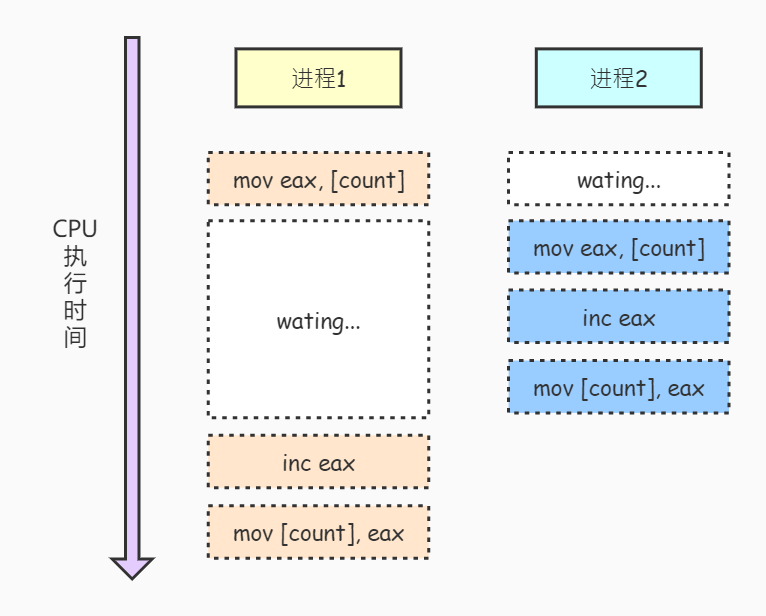
假设count变量初始值为0:
- 进程1执行完
mov eax, [count]后,寄存器eax内保存了count的值0。 - 进程2被调度执行。进程2执行
count++的所有指令,将累加后的count值1写回到内存。 - 进程1再次被调度执行,计算count的累加值仍为1,写回到内存。
虽然进程1和进程2执行了两次 count++ 操作,但是count最后的值为1,而不是2。
要解决这个问题就需要使用 原子操作,原子操作是指不能被打断的操作,在单核CPU中,一条指令就是原子操作。比如上面的问题可以把 count++ 语句翻译成指令 inc [count] 即可。Linux也提供了这样的原子操作,如对整数加一操作的 atomic_inc():
static __inline__ void atomic_inc(atomic_t *v)
{
__asm__ __volatile__(
LOCK "incl %0"
:"=m" (v->counter)
:"m" (v->counter));
}在多核CPU中,一条指令也不一定是原子操作,比如 inc [count] 指令在多核CPU中需要进行如下过程:
- 从内存将count的数据读取到cpu。
- 累加读取的值。
- 将修改的值写回count内存。
Intel x86 CPU 提供了 lock 前缀来锁住总线,可以让指令保证不被其他CPU中断,如下:
lock
inc [count]锁
原子操作 能够保证操作不被其他进程干扰,但有时候一个复杂的操作需要由多条指令来实现,那么就不能使用原子操作了,这时候可以使用 锁 来实现。
计算机科学中的 锁 与日常生活的 锁 有点类似,举个例子:比如要上公厕,首先找到一个没有人的厕所,然后把厕所门锁上。其他人要使用的话,必须等待当前这人使用完毕,并且把门锁打开才能使用。在计算机中,要对某个公共资源进行操作时,必须对公共资源进行上锁,然后才能使用。如果不上锁,那么就可能导致数据混乱的情况。
在Linux内核中,比较常用的锁有:自旋锁、信号量、读写锁 等,下面介绍一下自旋锁和信号量的实现。
自旋锁
自旋锁 只能在多核CPU系统中,其核心原理是 原子操作,原理如下图:
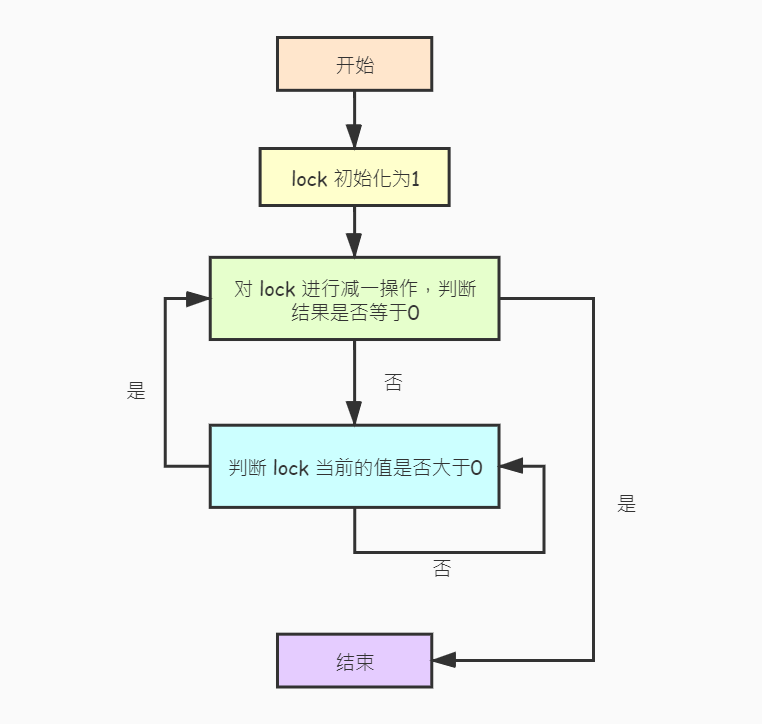
使用 自旋锁 时,必须先对自旋锁进行初始化(设置为1),上锁过程如下:
- 对自旋锁
lock进行减一操作,判断结果是否等于0,如果是表示上锁成功并返回。 - 如果不等于0,表示其他进程已经上锁,此时必须不断比较自旋锁
lock的值是否等于1(表示已经解锁)。 - 如果自旋锁
lock等于1,跳转到第一步继续进行上锁操作。
由于Linux的自旋锁使用汇编实现,所以比较苦涩难懂,这里使用C语言来模拟一下:
void spin_lock(amtoic_t *lock)
{
again:
result = --(*lock);
if (result == 0) {
return;
}
while (true) {
if (*lock == 1) {
goto again;
}
}
}上面代码将 result = --(*lock); 当成原子操作,解锁过程只需要把 lock 设置为1即可。由于自旋锁会不断尝试上锁操作,并不会对进程进行调度,所以在单核CPU中可能会导致 100% 的CPU占用率。另外,自旋锁只适合粒度比较小的操作,如果操作粒度比较大,就需要使用信号量这种可调度进程的锁。
信号量
与 自旋锁 不一样,当当前进程对 信号量 进行上锁时,如果其他进程已经对其进行上锁,那么当前进程会进入睡眠状态,等待其他进程对信号量进行解锁。过程如下图:
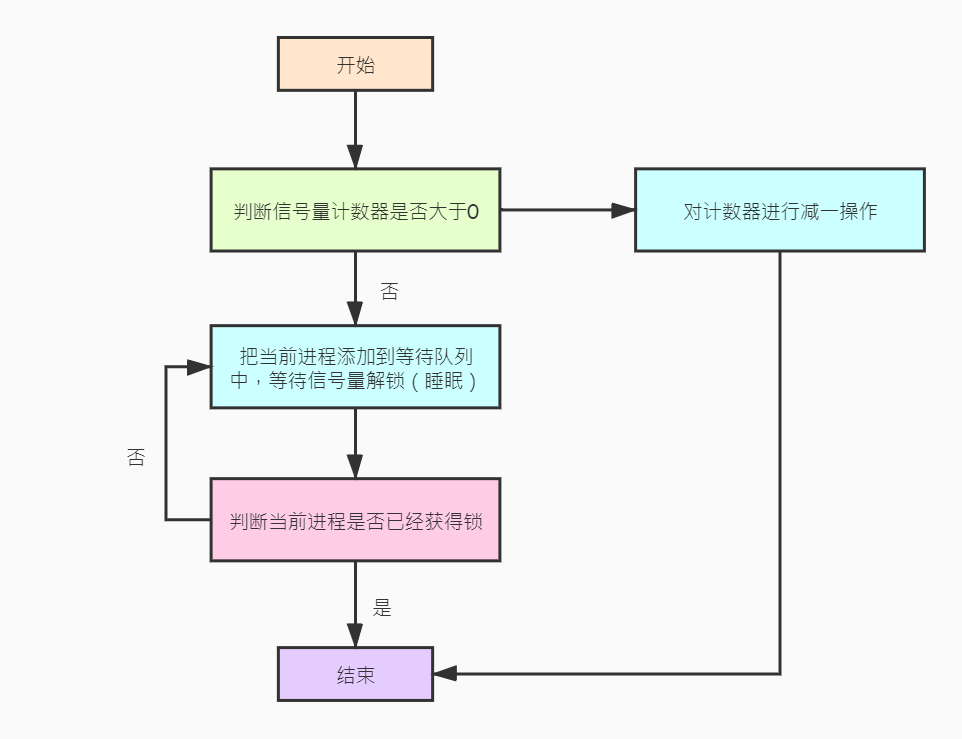
在Linux内核中,信号量使用 struct semaphore 表示,定义如下:
struct semaphore {
raw_spinlock_t lock;
unsigned int count;
struct list_head wait_list;
};各个字段的作用如下:
lock:自旋锁,用于对多核CPU平台进行同步。count:信号量的计数器,上锁时对其进行减一操作(count--),如果得到的结果为大于等于0,表示成功上锁,如果小于0表示已经被其他进程上锁。wait_list:正在等待信号量解锁的进程队列。
信号量 上锁通过 down() 函数实现,代码如下:
void down(struct semaphore *sem)
{
unsigned long flags;
spin_lock_irqsave(&sem->lock, flags);
if (likely(sem->count > 0))
sem->count--;
else
__down(sem);
spin_unlock_irqrestore(&sem->lock, flags);
}上面代码可以看出,down() 函数首先对信号量进行自旋锁操作(为了避免多核CPU竞争),然后比较计数器是否大于0,如果是对计数器进行减一操作,并且返回,否则调用 __down() 函数进行下一步操作。__down() 函数实现如下:
static noinline void __sched __down(struct semaphore *sem)
{
__down_common(sem, TASK_UNINTERRUPTIBLE, MAX_SCHEDULE_TIMEOUT);
}
static inline int __down_common(struct semaphore *sem,
long state, long timeout)
{
struct task_struct *task = current;
struct semaphore_waiter waiter;
// 把当前进程添加到等待队列中
list_add_tail(&waiter.list, &sem->wait_list);
waiter.task = task;
waiter.up = 0;
for (;;) {
...
__set_task_state(task, state);
spin_unlock_irq(&sem->lock);
timeout = schedule_timeout(timeout);
spin_lock_irq(&sem->lock);
if (waiter.up) // 当前进程是否获得信号量锁?
return 0;
}
...
}__down() 函数最终调用 __down_common() 函数,而 __down_common() 函数的操作过程如下:
- 把当前进程添加到信号量的等待队列中。
- 切换到其他进程运行,直到被其他进程唤醒。
- 如果当前进程获得信号量锁(由解锁进程传递),那么函数返回。
接下来看看解锁过程,解锁过程主要通过 up() 函数实现,代码如下:
void up(struct semaphore *sem)
{
unsigned long flags;
raw_spin_lock_irqsave(&sem->lock, flags);
if (likely(list_empty(&sem->wait_list))) // 如果没有等待的进程, 直接对计数器加一操作
sem->count++;
else
__up(sem); // 如果有等待进程, 那么调用 __up() 函数进行唤醒
raw_spin_unlock_irqrestore(&sem->lock, flags);
}
static noinline void __sched __up(struct semaphore *sem)
{
// 获取到等待队列的第一个进程
struct semaphore_waiter *waiter = list_first_entry(
&sem->wait_list, struct semaphore_waiter, list);
list_del(&waiter->list); // 把进程从等待队列中删除
waiter->up = 1; // 告诉进程已经获得信号量锁
wake_up_process(waiter->task); // 唤醒进程
}解锁过程如下:
- 判断当前信号量是否有等待的进程,如果没有等待的进程, 直接对计数器加一操作
- 如果有等待的进程,那么获取到等待队列的第一个进程。
- 把进程从等待队列中删除。
- 告诉进程已经获得信号量锁
- 唤醒进程。