浅谈神经网络
前言
现在作为一个业余机器学习爱好者,神经网络博大精深,这里我只敢浅谈一下。这篇文章参考了很多大神们的分享,我添加了一些我的理解(私货)。可能会有一些问题、不准确或者错误的地方,请大家多多包涵。
人工智能
人工智能在现在生活中运用很广泛,在抖音中也有很多应用场景。比如在“抖音自然”活动中,通过人工智能技术,抖音可以高速精准地识别出视频中的动植物。利用人工智能来识别物体就是当前一个不错的解决方案。那么神经网络和人工智能的关系是什么呢?神经网络是机器学习中一种学习方案,而机器学习是人工智能中的一个分支,那么什么是人工智能呢?人工智能 (artificial intelligence,缩写为AI) 指创造并运用算法构建动态计算环境来模拟人类智能过程的基础。人工智能的定义可以分为两部分,即“人工”和“智能”。“人工”即由人设计,为人创造、制造。关于什么是“智能”,较有争议性。
- 人工智障
function ArtificialIntelligenceAdd(a, b) {
return a + b
}- 通过文字描述生成代码:
- GPT-3 写前端[1]
- 测试网站[2]
大佬们将人工智能定义为“系统正确解释外部数据,从这些数据中学习,并利用这些知识通过灵活地实现特定目标和任务的能力”。简单来说,人工智能努力的目标是让计算机像人类一样思考和行动。目前来说机器学习在解决一些需要大量重复工作的场景中,有不错的表现。
机器学习
机器学习是一类从数据中自动分析获得规律,并利用规律对未知数据进行预测。所以对于机器学来说,最重要的就是两方面:数据和学习方法。如下图所示,深色部分代表的更多的是学习方法,浅色部分代表更多的是数据。两者的结合中就有机器学习,而深度学习是机器学习的子集。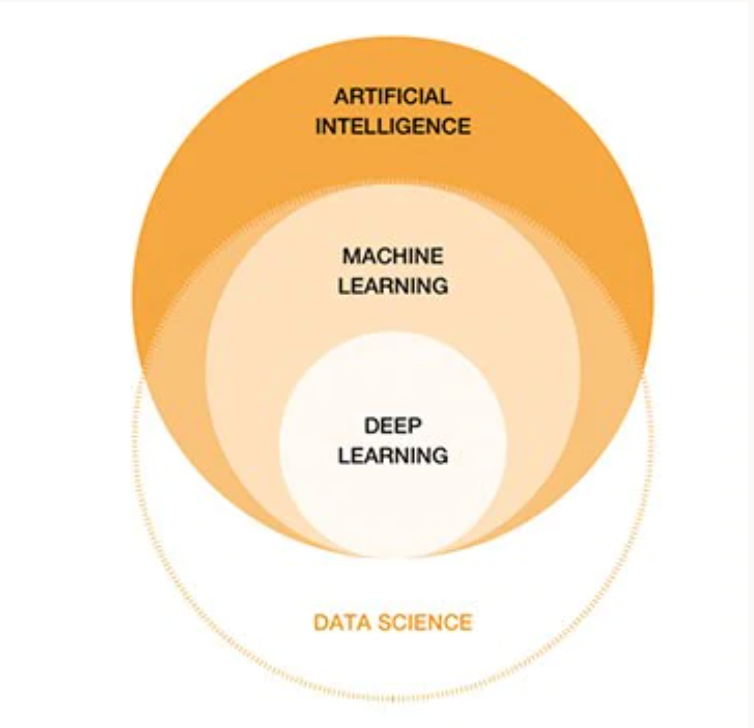
监督学习
从给定的训练数据集中学习出一个函数,当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求是包括输入和输出,也可以说是特征和目标。在监督学习的训练集中的目标是由人标注的,也就是需要人在机器学习之前就先把每个特征都标记好正确的结果,正确的标准需要人训练前定义好。
- 举个例子:我要做一个加法模型,给入两个输入(x1, x2, x3),模型给一个输出 y。那么我们需要现在准备好模型训练的数据,这些数据可能就像下面表中的,机器再通过某些方法(比如神经网络)来找寻(x1, x2, x3)和 y 之间的规律。
| x1 | x2 | x3(干扰信息) | y |
|---|---|---|---|
| 1 | 3 | 11 | 4 |
| 2 | 6 | 12 | 8 |
| 7 | 1 | 13 | 8 |
| 3 | 3 | 14 | 6 |
在监督学习中,我们需要在模型学习前就准好了数据,并且知道数据对应的基准真相(ground truth)。模型学习是要悟出来一个如何把输入变成输出的方法(函数)。监督学习极度依赖数据的可靠性。监督学习目前应用最为广泛,因为目的性很明确,而且有大量的数据清洗师,因此在业界也落地最多并且最有效果。
无监督学习
和监督学习类似,从给定的训练数据集中学习出一个函数,但是训练集没有人为标注的结果,也就是没有基准真相。想办法让机器自己探索出数据之间的关系。简单来说就是找相似。
- 举个例子:无监督学习中的运用比较多的场景之一就是聚类,也就是找出每个数据的相同点,把相似的聚集起来。比如下面是一些动物的数据:
| 眼睛数量 | 足的数量 | 手的数量 | 耳朵数量 | 使用工具 | 刷抖音 | 动物 |
|---|---|---|---|---|---|---|
| 2 | 2 | 2 | 2 | 1 | 1 | 人类 |
| 2 | 2 | 2 | 2 | 1 | 0 | 黑猩猩 |
| 2 | 4 | 0 | 2 | 0 | 0 | 猫 |
| 2 | 4 | 0 | 2 | 0 | 0 | 狗 |
| 2 | 0 | 0 | 2 | 0 | 0 | 鲤鱼 |
| 2 | 0 | 0 | 2 | 0 | 0 | 鲫鱼 |
如果根据上面的数据分类,明显可得第一二个数据比较相近,第三四数据比较相近,第五六数据比较相近。聚类的无监督学习就是根据这种数据,通过一些方法,不需要人为的标注基准真相,就可以做到聚合分类的作用。比如还是上面的例子中,假设机器总结出来的规律是:把每个特征的值加起来,总和就是分类的结果。通过观察结果可以发现,差值大于 2 就基本不算属于一类。比如把小明(人类)的数据和他家旺财(狗)的数据根据这个方法带入一下,就会推导出这两组数据不属于同一类。而黑猩猩又介于人类和猫狗这一类之间。监督学习更像人为先定好最终的目标的范围,机器通过输入数据给出一个范围内的答案。无监督学习会类似通过机器帮人来发掘一些信息,在通过发掘的信息来进一步处理。更不严谨的来说就是监督学习是人教机器做事,无监督学习就是机器教人做事。
半监督学习
半监督学习是有监督和无监督学习的组合,对训练中的部分数据进行标记。也就是数据标记了,但是没全标记。毕竟干净准确的数据标记是费时又费力的,因此通过结合一些标记好的数据和大量未标记的数据结合来让模型学习,在不少情况下可以节省人力也能让机器学明白。
强化学习
为了达成目标,随着环境的变动,而逐步调整其行为,并评估每一个行动之后所到的回馈是正向的或负向的。对比监督/无监督学习,监督/无监督学习像是一次性的输入输出行为,而强化学习像是对于外界一系列变化的反馈,反馈一般是奖励和惩罚。
- 举个例子:有个段子说让 AI 学习狼抓羊,最后狼选择撞死自己。这个段子就是强化学习的过程。假设这个段子中是一个 2D 的地图,那么狼每秒钟都要选择向上下左右一个方向移动,移动后如果碰到羊就有奖励(正反馈),但是只要抓不到羊,每秒钟都会负反馈(惩罚)。找到一种规律,能让狼得分最高,就是强化学习的过程。

神经网络
不管是监督学习、无监督学习还是强化学习,总要有个具体的学习方法吧。人工神经网络(Artificial Neural Network,ANN)就是目前最火也是相对最有效的学习方法。也是神经网络的活跃和可塑性,促使了深度学习的诞生。
发展历史
先回顾一下神经网络的发展历史。
- 最早在1943 年,沃伦·麦卡洛克[3]和沃尔特·皮茨[4]基于数学和一种称为阈值逻辑的算法创造了一种神经网络的计算模型。
- 1975 年,保罗·韦伯斯[5]对神经网络做重大改进,发明的反向传播算法[6]。
- 1980s 年,卷积神经网络(CNN/ Convolutional neural network)的概念被提出。不过因为硬件计算力的限制,神经网络的发展和研究都进步的缓慢了很长时间。
- 1993 年,一家在后来改变了业界的公司建立了——NVIDIA。
- 1999 年,NVIDIA 发明了 GPU——GeForce 256,GPU 可并行运行大量计算的能力带来不一样的体验,也带来新的想法。
- 2006 年,革命性的框架CUDA亮相。CUDA 本身是由 NVIDIA 推出的通用并行计算架构,基于 CUDA 编程可以利用 GPUs 的并行计算引擎来更加高效地解决比较复杂的计算难题,使 GPU 不再局限于图片渲染领域。
- 正所谓大力出奇迹,只要机器计算(枚举)地够快,没有什么答案是算(背)不出来的。和图像最相近的 CNN 就爆发了,大约从2010 年开始,各种基于机器学习的图像处理方案如雨后春笋般层出不穷,而且效果都很好。因为 CNN 十分优秀的表现,学术界和工业界越来越多的先驱们结合使用 GPU,又开始对神经网络开始了大规模的研究。
- 随时 GPU 的算力越来越强,模型的大小(深度)也越来越大,大约在2014 年出现了残差神经网络,该网络有效解决了网络过深导致机器难以学习的问题,极大解放了神经网络的深度限制,于是出现了深度学习的概念。
工作原理
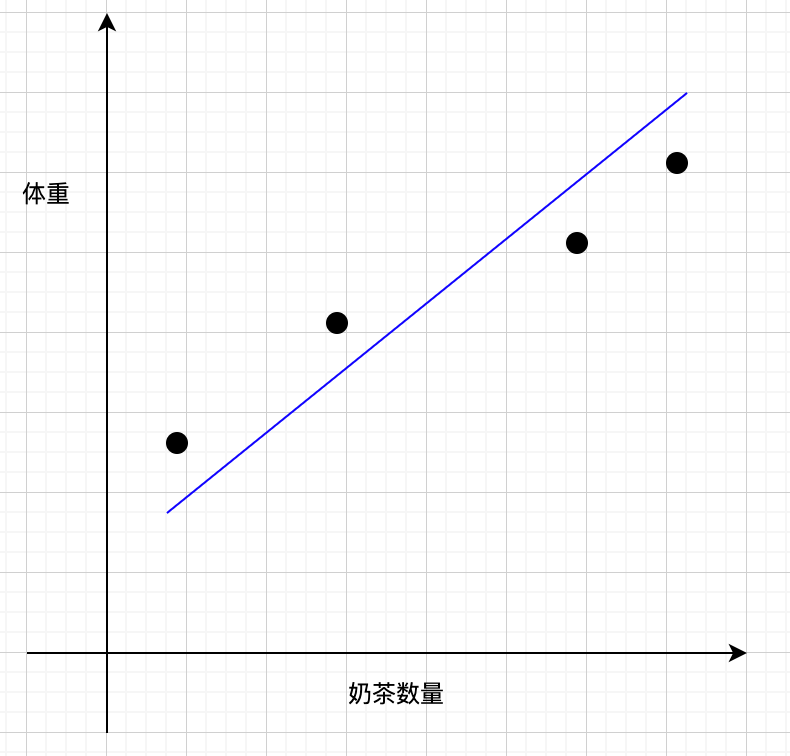
这里举一个利用神经网络做监督学习的例子。假设我统计了我 4 个周的体重和奶茶数量,想找一个出一个函数来代表出奶茶杯数和体重的关系,自己找太麻烦了,希望通过训练机器找出一个 :
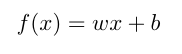
这样的公式简单预测一下。x 就是每周的奶茶数量,也是训练过程中的输入,也就是特征。每周统计的体重就是基准真相。f(x)的结果是机器每次预测出来的体重。w 和 b 的值一开始都是随机的,通过数次迭代,让机器找到最合适的 w 和 b 值。
- w 一般被称为 weight 或者参数、权重。
- b 一般被称为 bias 或者偏置。
这个过程中有 2 个问题:1. 怎么知道训练的结果好不好。2. 如何根据结果来矫正模型。
损失函数(Loss Function)
损失函数就是来反映模型训练效果的方法。损失函数通过计算每轮预测结果和真实结果的差值来展示学习的成果。损失函数或简单或复杂,只要有效反映出预测值和基准真相的差距即可,一个比较简单的损失函数如下:
function simpleLossFun(prediction, groundtruth) {
return Math.abs(prediction - groundtruth);
}机器(模型)在学习过程中的目的只有一个,就是将损失值最小化。
反向传播(Back Propagation)
如何来矫正模型就需要用到反向传播。反向传播就是用来计算梯度,基本上所有的优化算法都是在反向传播算出梯度之后进行改进的。在这个例子中,矫正模型就是矫正 w 和 b 的数值,尤其是 w 对 f(x)最为重要。有效能体现 w 和 f(x)的关系就是对函数求导,
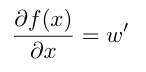
求导通过极限的概念对 f(x)进行局部的线性逼近,w' 就反应了 f(x)在 x 这一点的变化率/梯度,借用大佬的话:
函数关于每个变量的导数指明了整个表达式对于该变量的敏感程度。
这里也可以引入向量的角度来看待求导,通过求导得出的导数(梯度),w',代表了正负代表了变化的方向,导数的大小代表了变化的力度,通过调整 w 可以影响到 w',也就影响了这一点上的向量的大小和方向,从而影响了整个线段的走向。同理也可以带入物理的角度,求导也是求瞬时速度,速度的大小和方向也随 w 变化而变化。因此在我们不修改 x,而可以通过求得梯度 w',后续再根据 w' 来调整 w 来影响预测值,使 loss 的数值不断降低。
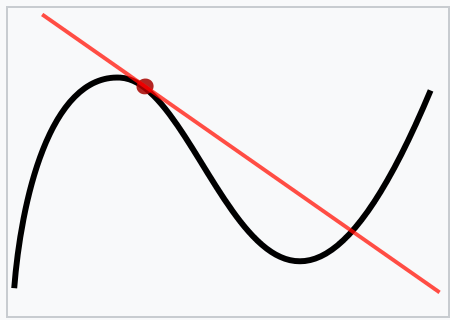
多特征函数
单一特征信息很难让模型预测出正确的结果,一般需要多维度特征信息。继续我们之前奶茶和体重的例子,我还是想找出一个函数来预测我体重的变化的规律。我发现有时候我喝了多好杯奶茶,但是体重增长不明显,有时候我不怎么喝奶茶,但是体重还是往上涨。我觉得可能会我的运动量,杯子大小,喝可乐的数量等等信息有关,这些信息之前的模型不知道,所以只根据奶茶数量预测的体重变化就不准。之前机器只考虑奶茶杯数一个特征的:
换成神经网络的图,大概如下: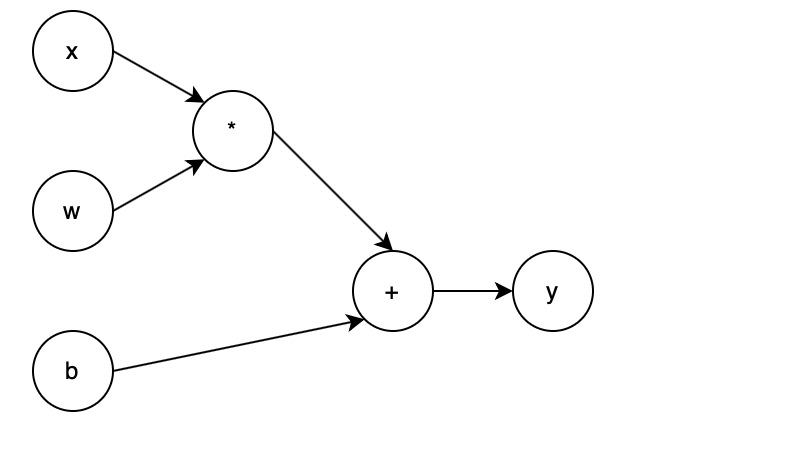
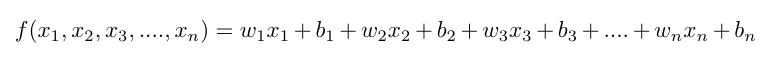
这样的多元函数在求导时可以结合高斯消元法来做。换成神经网络大概类似于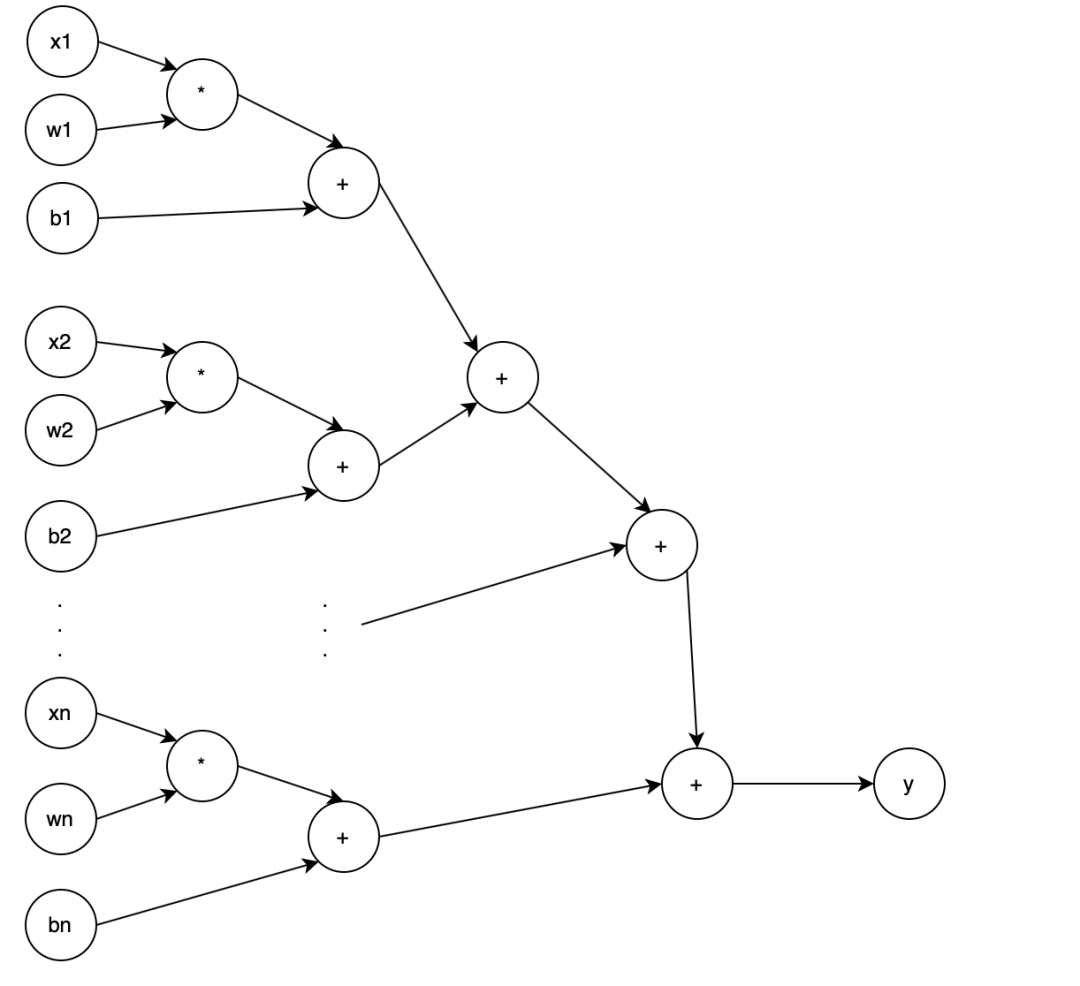
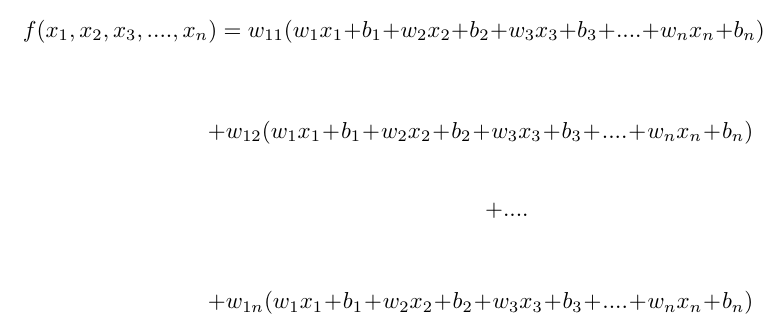
神经网络就类似: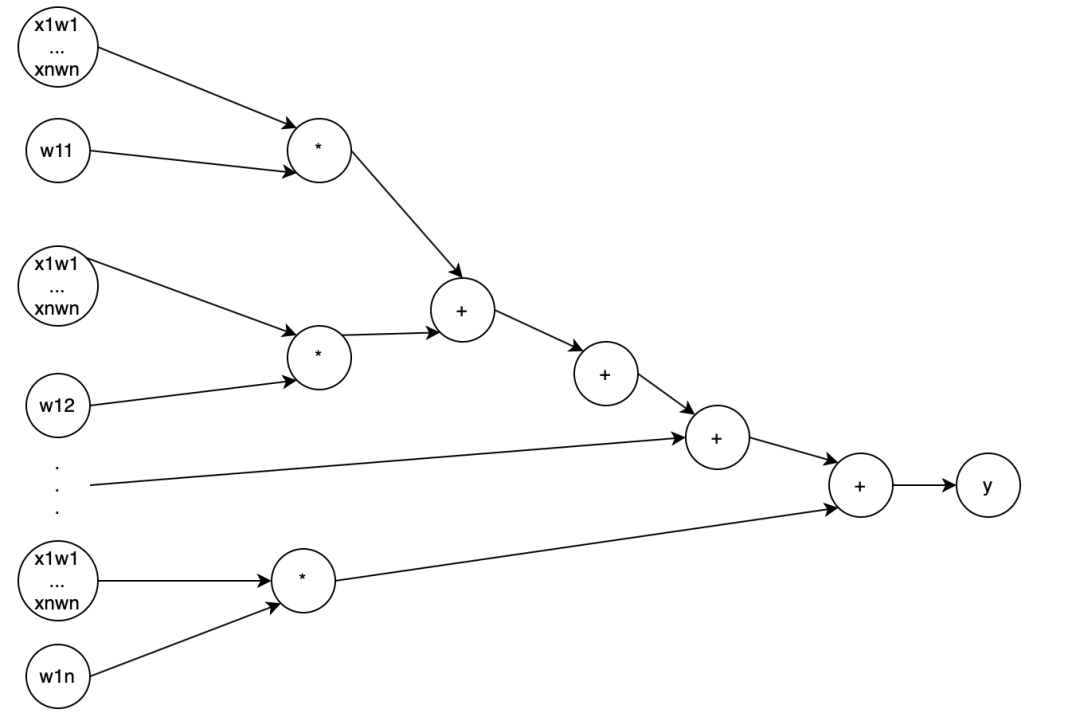
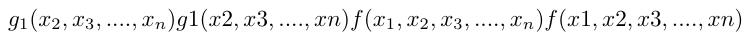
变成

以此类推,我们可以对
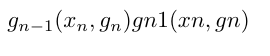
求道得出值,并一步一步向后把链条上所有节点的导数求出。借用 CS231N 的图:
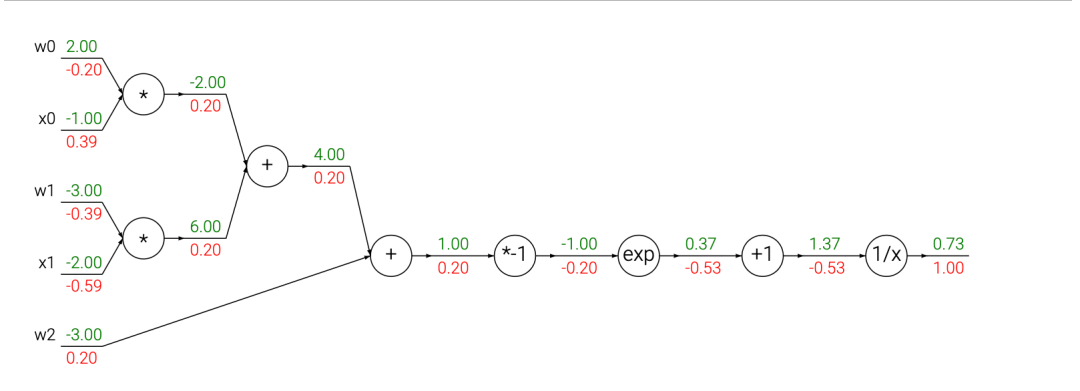
更新参数
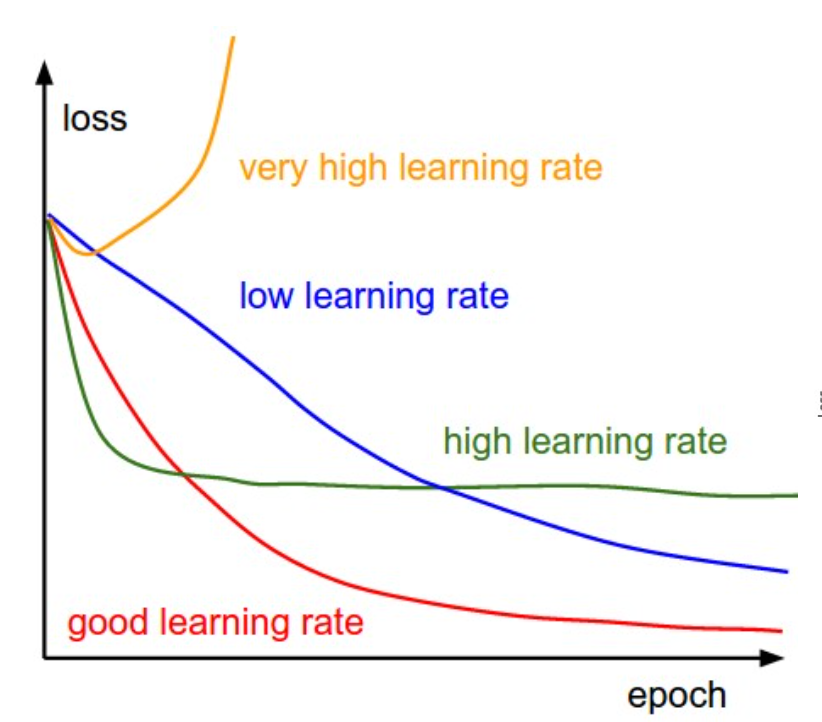
计算完每个 weight 的梯度之后,我们需要用梯度来更新参数。新的问题就是每次更新多少呢?这里需要引入新的参数:学习率(learning rate)。(学习率 * 梯度) 就是每次模型中 weight 更新的大小。那么又一个新的问题来了,学习率该怎么设置呢?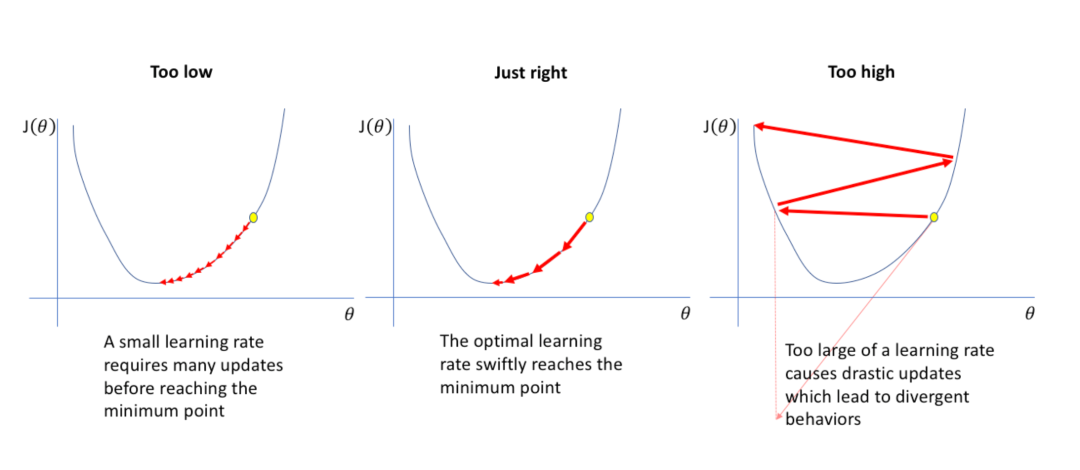
总体过程
模型的一轮培训过程分为 4 步
- 向前传播:模型接受输入,预测结果
- 计算 Loss:计算预测和真实值的损失值
- 反向传播:计算出每个 weight 的梯度
- 矫正参数:根据梯度、学习率和衰减参数来更新参数
一般来说模型培训的过程也是围绕着 4 步。设计向前传播的过程,设计 loss 函数,根据准确率来调整学习率,衰减参数,初始 weight 等。通过不断循环上述 4 步骤 n 轮,模型最终拟合出来一个函数,这个函数就是我们要的模型。