一文读懂 | Linux对象分配器 SLAB 算法
由于这篇文章写得比较早, 当时使用的是Linux-2.4.16版本内核, 但不影响整体的源码分析.
SLAB分配算法
上一节说过Linux内核使用伙伴系统算法来管理内存页, 但伙伴系统算法分配的单位是内存页, 就是至少要分配一个或以上的内存块. 但很多时候我们并不需要分配一个内存页, 例如我们要申请一个大小为200字节的结构体时, 如果使用伙伴系统分配算法至少申请一个内存页, 但只使用了200字节的内存, 那么剩余的3896字节就被浪费掉了.
为了解决小块内存申请的问题, Linux内核引入了 SLAB 分配算法. Linux 所使用的 SLAB 分配算法 的基础是 Jeff Bonwick 为SunOS 操作系统首次引入的一种算法。在内核中,会为有限的对象集(例如文件描述符和其他常见结构)分配大量内存。Jeff发现对内核中普通对象进行初始化所需的时间超过了对其进行分配和释放所需的时间。因此他的结论是不应该将内存释放回一个全局的内存池,而是将内存保持为针对特定目而初始化的状态。
为了更好的理解 SLAB分配算法, 我们先来介绍一下算法使用到的数据结构.
相关数据结构
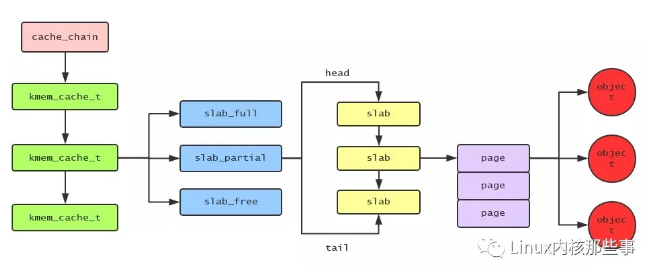
SLAB分配算法 有两个重要的数据结构, 一个是 kmem_cache_t,另外一个是 slab_t . 下面我们先来看看 kmem_cache_t 结构:
struct kmem_cache_s {
/* 1) each alloc & free */
/* full, partial first, then free */
struct list_head slabs_full;
struct list_head slabs_partial;
struct list_head slabs_free;
unsigned int objsize;
unsigned int flags; /* constant flags */
unsigned int num; /* # of objs per slab */
spinlock_t spinlock;
#ifdef CONFIG_SMP
unsigned int batchcount;
#endif
/* 2) slab additions /removals */
/* order of pgs per slab (2^n) */
unsigned int gfporder;
/* force GFP flags, e.g. GFP_DMA */
unsigned int gfpflags;
size_t colour; /* cache colouring range */
unsigned int colour_off; /* colour offset */
unsigned int colour_next; /* cache colouring */
kmem_cache_t *slabp_cache;
unsigned int growing;
unsigned int dflags; /* dynamic flags */
/* constructor func */
void (*ctor)(void *, kmem_cache_t *, unsigned long);
/* de-constructor func */
void (*dtor)(void *, kmem_cache_t *, unsigned long);
unsigned long failures;
/* 3) cache creation/removal */
char name[CACHE_NAMELEN];
struct list_head next;
...
};下面介绍一下kmem_cache_t结构中比较重要的字段:
slab_full:完全分配的slabslab_partial:部分分配的slabslab_free:没有被分配过的slabobjsize:存储的对象大小num:一个slab能够存储的对象个数gfporder:一个slab由2gfporder个内存页组成colour/colour_off/colour_next:着色区大小(后面会讲到)
slab_t结构定义如下:
typedef struct slab_s {
struct list_head list;
unsigned long colouroff;
void *s_mem; /* including colour offset */
unsigned int inuse; /* num of objs active in slab */
kmem_bufctl_t free;
} slab_t;slab_t结构各个字段的用途如下:
list:连接(全满/部分/全空)链colouroff:着色补偿s_mem:存储对象的起始内存地址inuse:已经分配多少个对象free:用于连接空闲的对象
用图来表示它们之间的关系,如下:
SLAB分配算法初始化
SLAB分配算法的初始化由 kmem_cache_init() 函数完成,如下:
void __init kmem_cache_init(void)
{
size_t left_over;
init_MUTEX(&cache_chain_sem);
INIT_LIST_HEAD(&cache_chain);
kmem_cache_estimate(0, cache_cache.objsize, 0,
&left_over, &cache_cache.num);
if (!cache_cache.num)
BUG();
cache_cache.colour = left_over/cache_cache.colour_off;
cache_cache.colour_next = 0;
}这个函数主要用来初始化 cache_cache 这个变量,cache_cache 是一个类型为 kmem_cache_t 的结构体变量,定义如下:
static kmem_cache_t cache_cache = {
slabs_full: LIST_HEAD_INIT(cache_cache.slabs_full),
slabs_partial: LIST_HEAD_INIT(cache_cache.slabs_partial),
slabs_free: LIST_HEAD_INIT(cache_cache.slabs_free),
objsize: sizeof(kmem_cache_t),
flags: SLAB_NO_REAP,
spinlock: SPIN_LOCK_UNLOCKED,
colour_off: L1_CACHE_BYTES,
name: "kmem_cache",
};为什么需要一个这样的对象呢?因为本身 kmem_cache_t 结构体也是小内存对象,所以也应该有slab分配器来分配的,但这样就出现“鸡蛋和鸡谁先出现”的问题。在系统初始化的时候,slab分配器还没有初始化,所以并不能使用slab分配器来分配一个 kmem_cache_t 对象,这时候只能通过定义一个 kmem_cache_t 类型的静态变量来来管理slab分配器了,所以 cache_cache 静态变量就是用来管理slab分配器的。
从上面的代码可知,cache_cache 的 objsize字段 被设置为 sizeof(kmem_cache_t) 的大小,所以这个对象主要是用来分配不同类型的 kmem_cache_t 对象的。
kmem_cache_init() 函数调用了 kmem_cache_estimate() 函数来计算一个slab能够保存多少个大小为 cache_cache.objsize 的对象,并保存到 cache_cache.num 字段中。一个slab中不可能全部都用来分配对象的,举个例子:一个4096字节大小的slab用来分配大小为22字节的对象,可以划分为186个,但还剩余4字节不能使用的,所以这部分内存用来作为着色区。着色区的作用是为了错开不同的slab,让CPU更有效的缓存slab。当然这属于优化部分,对slab分配算法没有多大的影响。就是说就算不对slab进行着色操作,slab分配算法还是可以工作起来的。
kmem_cache_t对象申请
kmem_cache_t 是用来管理和分配对象的,所以要使用slab分配器时,必须先申请一个 kmem_cache_t 对象,申请 kmem_cache_t 对象由 kmem_cache_create() 函数进行:
kmem_cache_t *
kmem_cache_create (const char *name, size_t size, size_t offset,
unsigned long flags, void (*ctor)(void*, kmem_cache_t *, unsigned long),
void (*dtor)(void*, kmem_cache_t *, unsigned long))
{
const char *func_nm = KERN_ERR "kmem_create: ";
size_t left_over, align, slab_size;
kmem_cache_t *cachep = NULL;
...
cachep = (kmem_cache_t *) kmem_cache_alloc(&cache_cache, SLAB_KERNEL);
if (!cachep)
goto opps;
memset(cachep, 0, sizeof(kmem_cache_t));
...
do {
unsigned int break_flag = 0;
cal_wastage:
kmem_cache_estimate(cachep->gfporder, size, flags,
&left_over, &cachep->num);
if (break_flag)
break;
if (cachep->gfporder >= MAX_GFP_ORDER)
break;
if (!cachep->num)
goto next;
if (flags & CFLGS_OFF_SLAB && cachep->num > offslab_limit) {
cachep->gfporder--;
break_flag++;
goto cal_wastage;
}
if (cachep->gfporder >= slab_break_gfp_order)
break;
if ((left_over*8) <= (PAGE_SIZE<<cachep->gfporder))
break; /* Acceptable internal fragmentation. */
next:
cachep->gfporder++;
} while (1);
if (!cachep->num) {
printk("kmem_cache_create: couldn't create cache %s.\n", name);
kmem_cache_free(&cache_cache, cachep);
cachep = NULL;
goto opps;
}
slab_size = L1_CACHE_ALIGN(cachep->num*sizeof(kmem_bufctl_t)+sizeof(slab_t));
if (flags & CFLGS_OFF_SLAB && left_over >= slab_size) {
flags &= ~CFLGS_OFF_SLAB;
left_over -= slab_size;
}
offset += (align-1);
offset &= ~(align-1);
if (!offset)
offset = L1_CACHE_BYTES;
cachep->colour_off = offset;
cachep->colour = left_over/offset;
if (!cachep->gfporder && !(flags & CFLGS_OFF_SLAB))
flags |= CFLGS_OPTIMIZE;
cachep->flags = flags;
cachep->gfpflags = 0;
if (flags & SLAB_CACHE_DMA)
cachep->gfpflags |= GFP_DMA;
spin_lock_init(&cachep->spinlock);
cachep->objsize = size;
INIT_LIST_HEAD(&cachep->slabs_full);
INIT_LIST_HEAD(&cachep->slabs_partial);
INIT_LIST_HEAD(&cachep->slabs_free);
if (flags & CFLGS_OFF_SLAB)
cachep->slabp_cache = kmem_find_general_cachep(slab_size,0);
cachep->ctor = ctor;
cachep->dtor = dtor;
strcpy(cachep->name, name);
#ifdef CONFIG_SMP
if (g_cpucache_up)
enable_cpucache(cachep);
#endif
down(&cache_chain_sem);
{
struct list_head *p;
list_for_each(p, &cache_chain) {
kmem_cache_t *pc = list_entry(p, kmem_cache_t, next);
if (!strcmp(pc->name, name))
BUG();
}
}
list_add(&cachep->next, &cache_chain);
up(&cache_chain_sem);
opps:
return cachep;
}kmem_cache_create() 函数比较长,所以上面代码去掉了一些不那么重要的地方,使代码更清晰的体现其原理。
在 kmem_cache_create() 函数中,首先调用 kmem_cache_alloc() 函数申请一个 kmem_cache_t 对象,我们看到调用 kmem_cache_alloc() 时,传入的就是 cache_cache 变量。申请完 kmem_cache_t对象 后需要对其进行初始化操作,主要是对 kmem_cache_t对象 的所有字段进行初始化:
- 计算需要多少个页面来作为slab的大小。
- 计算一个slab能够分配多少个对象。
- 计算着色区信息。
- 初始化
slab_full / slab_partial / slab_free链表。 - 把申请的
kmem_cache_t对象保存到cache_chain链表中。
对象分配
申请完 kmem_cache_t对象 后,就使用通过调用 kmem_cache_alloc() 函数来申请指定的对象。kmem_cache_alloc() 函数代码如下:
static inline void * kmem_cache_alloc_one_tail (kmem_cache_t *cachep, slab_t *slabp)
{
void *objp;
...
slabp->inuse++;
objp = slabp->s_mem + slabp->free*cachep->objsize;
slabp->free=slab_bufctl(slabp)[slabp->free];
if (unlikely(slabp->free == BUFCTL_END)) {
list_del(&slabp->list);
list_add(&slabp->list, &cachep->slabs_full);
}
return objp;
}
#define kmem_cache_alloc_one(cachep) \
({ \
struct list_head * slabs_partial, * entry; \
slab_t *slabp; \
\
slabs_partial = &(cachep)->slabs_partial; \
entry = slabs_partial->next; \
if (unlikely(entry == slabs_partial)) { \
struct list_head * slabs_free; \
slabs_free = &(cachep)->slabs_free; \
entry = slabs_free->next; \
if (unlikely(entry == slabs_free)) \
goto alloc_new_slab; \
list_del(entry); \
list_add(entry, slabs_partial); \
} \
slabp = list_entry(entry, slab_t, list); \
kmem_cache_alloc_one_tail(cachep, slabp); \
})
static inline void * __kmem_cache_alloc (kmem_cache_t *cachep, int flags)
{
unsigned long save_flags;
void* objp;
kmem_cache_alloc_head(cachep, flags);
try_again:
local_irq_save(save_flags);
...
objp = kmem_cache_alloc_one(cachep);
local_irq_restore(save_flags);
return objp;
alloc_new_slab:
...
local_irq_restore(save_flags);
if (kmem_cache_grow(cachep, flags))
goto try_again;
return NULL;
}
void * kmem_cache_alloc (kmem_cache_t *cachep, int flags)
{
return __kmem_cache_alloc(cachep, flags);
}kmem_cache_alloc() 函数被我展开之后如上代码,kmem_cache_alloc() 函数的主要步骤是:
- 从
kmem_cache_t对象的slab_partial列表中查找是否有slab可用,如果有就直接从slab中分配一个对象。 - 如果
slab_partial列表中没有可用的slab,那么就从slab_free列表中查找可用的slab,如果有可用slab,就从slab分配一个对象,并且把此slab放置到slab_partial列表中。 - 如果
slab_free列表中没有可用的slab,那么就调用kmem_cache_grow()函数申请新的slab来进行对象的分配。kmem_cache_grow()函数会调用__get_free_pages()函数来申请内存页并且初始化slab.
一个slab的结构如下图:
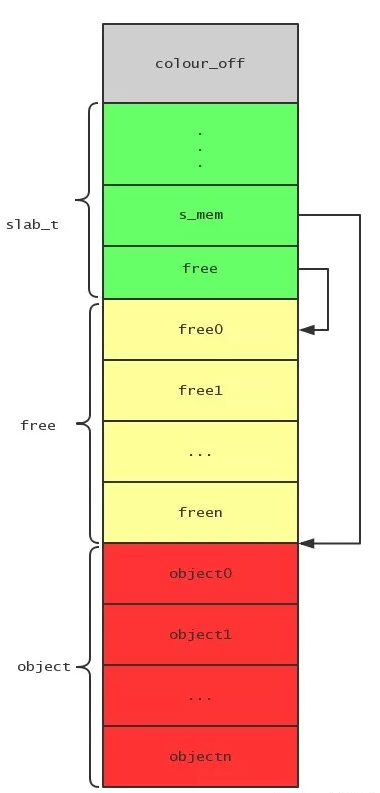
灰色部分是着色区,绿色部分是slab管理结构,黄色部分是空闲对象链表的索引,红色部分是对象的实体。我们可以看到slab结构的s_mem字段指向了对象实体列表的起始地址。
分配对象的时候就是先通过slab结构的free字段查看是否有空闲的对象可用,free字段保存了空闲对象链表的首节点索引。
对象释放
对象的释放比较简单,主要通过调用 kmem_cache_free() 函数完成,而 kmem_cache_free() 函数最终会调用 kmem_cache_free_one() 函数,代码如下:
static inline void kmem_cache_free_one(kmem_cache_t *cachep, void *objp)
{
slab_t* slabp;
CHECK_PAGE(virt_to_page(objp));
slabp = GET_PAGE_SLAB(virt_to_page(objp));
{
unsigned int objnr = (objp-slabp->s_mem)/cachep->objsize;
slab_bufctl(slabp)[objnr] = slabp->free;
slabp->free = objnr;
}
STATS_DEC_ACTIVE(cachep);
{
int inuse = slabp->inuse;
if (unlikely(!--slabp->inuse)) {
list_del(&slabp->list);
list_add(&slabp->list, &cachep->slabs_free);
} else if (unlikely(inuse == cachep->num)) {
list_del(&slabp->list);
list_add(&slabp->list, &cachep->slabs_partial);
}
}
}对象释放的时候首先会把对象的索引添加到slab的空闲对象链表中,然后根据slab的使用情况移动slab到合适的列表中。
- 如果slab所有对象都被释放完时,把slab放置到
slab_free列表中。 - 如果对象所在的slab原来在
slab_full中,那么就把slab移动到slab_partial中。