如何实现多人协作的在线文档
引言:由于业务需要,在工作中接触到了在线文档、在线Excel。但是在调研阶段发现国内相关文章比较匮乏,所以结合工作实践和自己的一些思考,写几篇文章剖析实现在线文档和在线Excel的一些技术方案。为了避免涉及到公司隐私,所以文章中一些数据结构的设计和非关键场景都写的比较简略。我们主要从需求分析、方案设计、技术选型等几个方面介绍如何实现多人协作的在线文档。
需求分析
我们借鉴领域驱动模型的思路进行需求分析。需求中包含人和文档两个实体。人的主要属性有:用户ID、用户名。文档的主要属性有:文档ID、文档内容、创建者、创建时间。人和文档的关系非常简单:一个人可以有多个文档,一个文档只归属某一个人,属于一对多的关系。
因为文档内容不能被随便阅读和修改,所以还要有权限管理,权限是一种值对象。权限的值有:阅读、编辑。人对文档可以有阅读权限或编辑权限。
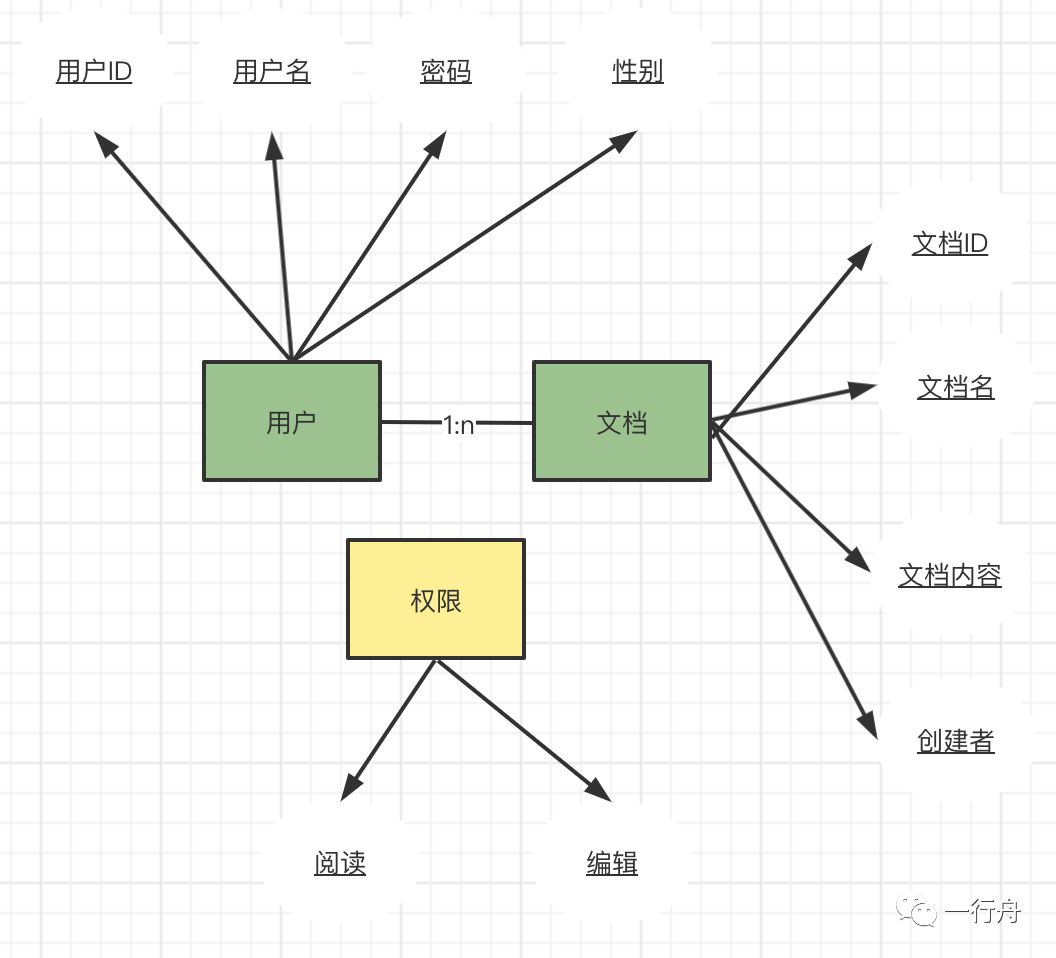
为了实现以上功能我们把系统拆分成五大模块:人员管理、文档管理、权限管理、协作和前端文档编辑器。
方案设计
人员管理
因为人员管理不是本文的重点,所以我们只做一个简要的设计,主要是为了辅助说明后面的设计。 表结构主要字段有:
| 字段 | 描述 |
|---|---|
| 用户ID | 唯一标识一个用户 |
| 用户名 | |
| 密码 | |
| 手机号 | |
| 邮箱 | |
| 性别 | |
| 注册时间 | |
| 上次登录时间 | . |
下面介绍下该模块的主要逻辑。
用户注册
- 前端把用户填写的用户名、密码、手机号等信息加密后发送给服务端。
- 服务端拿到数据,再和生成的唯一用户ID一起,存入表中。
用户登录
- 前端要求用户输入用户名+密码并发送给服务端,服务端校验用户名和密码的正确性。
- 校验通过后,根据用户名+密码+密钥+时间戳生成有时效性的Token,返回给客户端。
- 登录之后前端所有请求都带着Token信息。服务端根据Token获取当前登录用户信息并判断请求是否合法。
文档管理
文档的表结构设计:
| 字段 | 描述 |
|---|---|
| 文档ID | 唯一标识一个文档 |
| 文档名称 | |
| 文档内容 | |
| 创建者ID | 和用户ID关联 |
| 创建时间 | . |
创建文档
- 前端发送文档名称、文档内容给服务端
- 服务端生成唯一的文档ID,从Token中获取到用户ID,获取服务器时间然后把数据一起存入数据库中
- 服务端返回文档ID给前端
修改文档
这里的修改是指修改文档的内容。我们为了及时保存用户编辑的内容,需要在用户编辑过程中实时把数据传递给服务端。如果每次都发送全部文档内容给服务端,虽然服务端的处理逻辑会比较简单,但是每次请求都有很多冗余数据,浪费大量的带宽。所以我们最好只发送变化的内容给服务端,让服务端根据当前文档内容和变化内容合并生成最新的文档内容。
如何发送变化的内容呢?我们可以把用户对文档内容的操作分成三类:新增、修改、删除。新增就是给文档添加内容,修改就是修改文档的某一段内容,删除就是删除了文档的某一段内容。对这三类操作我们可以使用Json形式来表示:
{
op:"", // 操作 add:新增,update:修改, delete:删除
start:"", // 开始位置下标
end: "", // 结束位置下标
text:"", // 修改内容
}这样修改文档的流程就是
- 前端生成修改数据发送给服务端
- 服务端从数据库中获取文档内容,然后根据用户的行为合并操作,最后保存到数据库中。
用户在编辑一篇文章时,往往需要很多次数据传输。Json的数据格式虽然能很好的表达语意,但是每次传输也需要发送较多的字节,浪费带宽;而且Json的序列化和反序列化过程也相对低效。我们可以采用Google的Protobuf协议来代替,它是基于二进制的传输协议,在传输内容大小和解析速度上都强于Json。
message Doc {
enum Op{
add:0;
update:1;
delete:2;
}
required Op op = 0;
required int32 start = 1;
required int32 end = 5;
string text = "修改内容"
}这里协议比较简单,自己按照规则拼接字符串也是可以的。考虑到后续功能的可扩展性,还是建议采用Protobuf协议。
修改文档的流程还有顺序问题,我们假设用户的操作是这样的:
- 用户先删除了5个字“12345”
- 添加了5个字“一二三四五”
- 又修改了其中的前两个字是“你好”
正常顺序下最后的结果是:你好三四五。但是如果服务端的执行顺序变成了3、1、2,那最后的结果变成了:一二三四五。这显然是不符合预期的。所以我们要保证服务端顺序处理前端发过来的请求。
保证顺序执行有几个方案:
- 前端请求由异步变成同步
- 前端每次请求都生成连续递增的ID,服务端判断如果递增ID不连续了,就短暂的等待
- 把对同一个文档的操作代理到同一个服务器,服务端单进程接收请求,并把数据存入有序队列。队列的消费端正常消费就可以了。
方案一在请求多的时候,处理效率太低会影响用户体验,可以直接排除掉。方案二主要依赖客户端生成递增ID,是比较不错的方案。方案三依赖单进程和有序队列保证顺序。虽然单进程在并发量高的情况下很难抗压,但是如果根据文档ID去做负载均衡也可以比较好的控制流量,毕竟对一个文档的修改QPS也高不到哪去。 当然也可以把方案二和方案三结合使用。
查看文档
- 前端发送要查看的文档ID给服务端
- 服务端根据文档ID返回文档内容
删除文档
- 前端发送要删除的文档ID给服务端
- 服务端根据文档ID删除对应文档
权限管理
当前需求的权限场景特别适合ABAC的权限模型。 用户属性:只要是正常登录用户即可 环境属性:普通的文档内容 操作属性:文档的读和写 对象属性:文档
所以,我们存储权限信息的表结构主要字段有:
| 字段 | 描述 |
|---|---|
| 用户属性 | 用户ID |
| 环境属性 | 没有做特殊的加密设置 |
| 操作属性 | 读/写 |
| 对象属性 | 文档ID |
下面介绍下该模块的主要逻辑。
开通权限
- 前端发送文档ID和权限类型(读/写)给服务端
- 服务端根据文档ID和Token中的用户ID,在权限表中添加记录,并返回成功
删除权限
- 前端发送文档ID和权限类型(读/写)给服务端
- 服务端根据文档ID和Token中的用户ID,在权限表中删除记录,并返回成功
校验权限
我们可以实现一个中间键,当用户请求某文档内容时,判断其是否为创建者。如果不是再从权限表中查询用户是否有权限查看或者编辑权限。修改文档内容时也是同样的逻辑,就不再赘述了。
协作
合并冲突
当多个人同时修改一个文档时,处理内容冲突的几种方式:
- 文档加锁:当有人修改文档时,对整个文档加写锁,别人都只能看不可编辑。虽然实现简单,不过协作的体验会特别差。
- diff+patch的合并算法:diff+patch是常用的文档内容比较和合并算法,Linux本身就提供了diff和patch命令支持文件的比较和合并。git也使用了diff+patch方法来合并文件,当无法解决冲突时,会把冲突抛给用户手动合并。
- OT算法:相比diff+patch来讲OT算法往往能带来更好的合并结果。不过OT算法的实现也更复杂一些。目前Google文档、腾讯文档、石墨文档等都是采用了OT算法。我们后面单独写文章来聊一聊diff+patch和OT算法。
协作通知
为了更好的协作,文档编辑者需要看到同时编辑文档的人,还需要看到别人修改的内容,来减少冲突,达到协作的目的。
大家打开文档编辑页面的时间是不同步的,为了让大家互相看到,而且互相看到对方修改的内容,就需要服务端主动给客户端推送消息。此场景下采用长链接的方案是比较合适的。
前文也提到过,文档修改频繁的时候,发送数据的频次会很高,如果是HTTP请求会导致每次请求都携带头信息,建立连接等开销,所以修改文档内容的数据上报也可以采用长链接。同时,服务端维护一个协作列表来存放所有正在被编辑的文档和每个文档的在线用户,可以类比为一个聊天室。
文档修改者加入
- 前端打开一个文档时,发送请求给服务端,服务端检查协作列表中是否有当前文档。
- 如果有则把当前用户加入此文档修改者列表;如果没有就把当前文档加入协作列表,同时把当前用户ID写入其中。
- 服务端通过长链接给文档列表中的所有其他用户推送消息,告知大家有用户加入协作。
文档修改者退出逻辑和加入基本相同就不再赘述了。
修改内容
- 前端把修改数据发送给服务端
- 服务端暂存多个用户的操作,并根据OT算法把用户操作合并,最后和数据库存储的文档内容合并
- 把合并完的文档内容保存到数据库中
- 服务端根据文档ID,读取协作列表中的用户,给所有用户发送合并结果
- 客户端把合并结果与本地文档内容合并
文档编辑器
编辑功能
文档编辑器需要支持,文档内容编辑、文字样式调整、插入图片、插入链接等一系列功能。 实现内容可编辑的方案有textarea标签和contenteditable属性可以选择。但是textarea标签对其他需求的实现很难支持,而且不方便控制。所以我们选用contenteditable=true来实现文档内容的编辑。
上报功能
文档修改时,内容的上报,需要文档编辑器处理好。不能用户每输入一个字符就上报一次,这样频繁的发送数据会给服务端带来很大压力,也是没有必要的。所以客户端的上报需要做防抖处理。上报的过程中有可能会因为网络闪断等原因导致上报失败,此时需要重试。
服务可能因为长时间的网络中断或者服务器异常导致数据上报失败。此时前端可以先把用户修改存储在浏览器本地的LocalStorage中,不过需要注意浏览器本地缓存通常有5M的大小限制。本地存储除了在网络异常时发挥作用,在实现Ctrl+Z操作时,也可以起到记录之前操作的作用。
长链接
需要有一个单独的模块管理长链接,统一处理上报的接口和服务端下发的数据,做好数据的封装和解析;并及时的反馈给用户连接成功、数据保存成功、连接异常等信息。
大文档的加载
对于大文档的加载,我们需要做异步处理。根据滚动条滚动的位置,在服务端异步的获取更多数据。
其他功能
前端编辑器的其他模块我们可以根据其功能范围拆分:比如控制文字大小、颜色的功能模块;控制文字对齐方式的模块;控制插入内容的模块;支持Ctrl+C、Ctrl+V、Ctrl+Z的模块等等。拆分好之后根据功能实现就可以了,这里就不一一分析了。
技术选型
存储
存储方面,当前场景使用关系型数据库比较合适。我们可以根据文档和用户的数量级选择合适的数据库。通常千万级别的数据量选择MySQL就可以了,如果数据更多的话我们可以选择TIDB或者MySQL分库分表的方案。 当然采用MongoDB和PG也都可以满足需求,我们可以结合公司的DBA运维能力自行选择。 补充一下,如果考虑文档内容的搜索,只选择一种存储结构是不够的。需要单独为文档建立索引,可以选择使用ES集群为文档创建全文索引。而且索引的创建和MySQL的增删改比起来是比较耗时的操作,所以创建索引往往放在异步流程中。而且用户创建一个文档也很少立马就对它搜索。
长链接
当前常用的长链接方案主要有“HTTP/2 + SSE”和WebSocket两种,WebSocket更成熟一些,优先选择。
消息队列
建议采用RocketMQ,因为
- RocketMQ支持同步/异步刷盘,支持同步/异步写副本,消息的可靠性更有保障。
- RocketMQ支持顺序消息。
当然写入性能方面要比Kafka弱一些。但是在线文档的场景里,消息的可靠性和顺序更加重要。
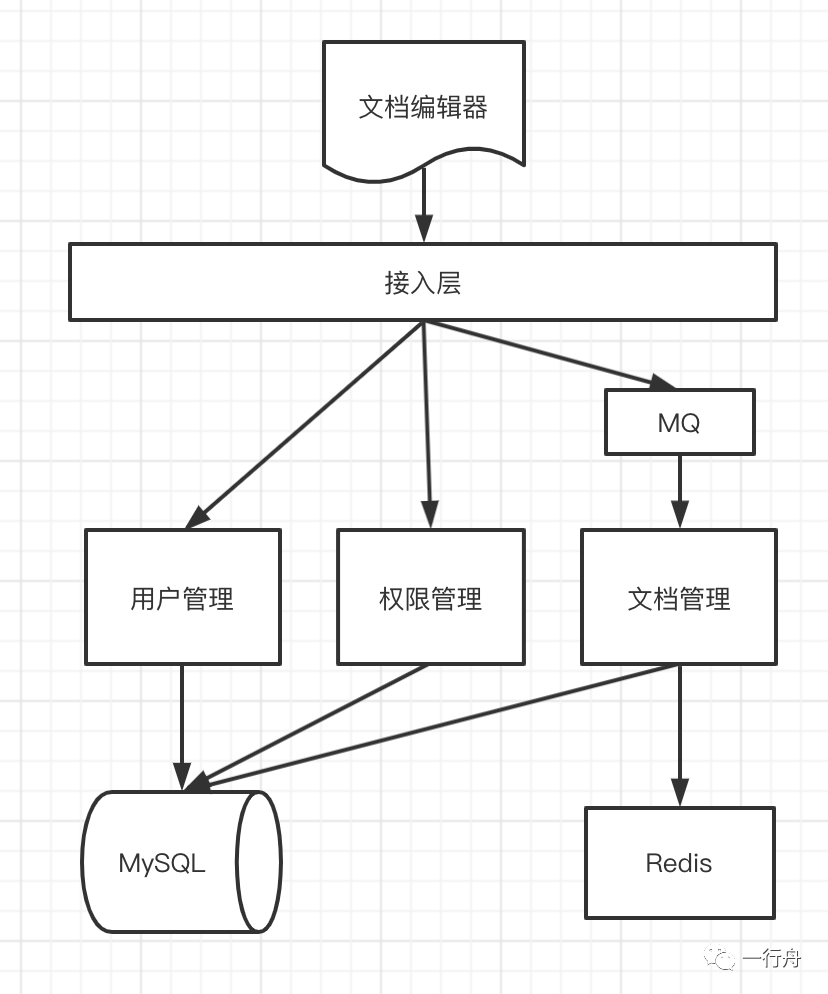
架构设计
基于上面的分析,我们设计的部署架构图如下
总结
以上就是我对多人协作在线文档的分析和设计方案,其中包含了前后端交互流程、文档的存储和服务的部署方案。为了突出主要问题和逻辑,文中很多设计和技术点都是点到为止,给大家造成困扰的地方大家可以自行搜索下关键字或者留言交流。
当然还有很多问题我们没有讨论,比如文档版本的管理、数据可靠性,大文档编辑和存储、文档的安全等等。更多的问题,我们在后续的文章里再和大家探讨。
有问题的地方欢迎大家留言,一起探讨。