脉脉iOS如何启动秒开
前言
启动是 App 给用户的第一印象,启动越慢,用户流失的概率就越高,良好的启动速度是用户体验不可缺少的一环。
通过调研业内现有的启动优化方案,针对启动各个阶段,结合脉脉自身app的情况,总结出了具体的可行性建议和可优化的项目。
加上后期不断的调优和实践,最终在app启动过程涉及到现有复杂业务环境下,实现了900ms的秒开成绩。
防劣化,建立健全app启动监控体系。通过监控大盘,及时发现问题解决问题并总结经验 。
二、认识 App是如何启动的
启动过程
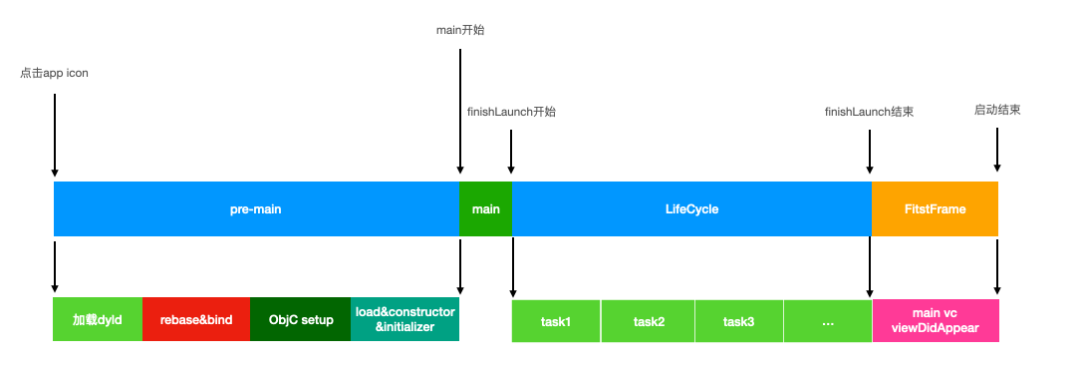
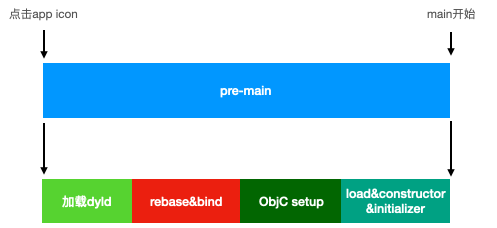
启动过程以main为界限,分为pre-main和main之后两部分
pre-main
加载dyld
动态库载入过程,会去装载app使用的动态库。而每一个动态库有它自己的依赖关系,会消耗时间去查找和读取。
rebase&binding
rebase:主要是调整镜像内部的指针,这里使用了ASLR(Address Space Layout Randomization 地址空间布局随机化)。程序每次启动后地址都会随机变化,这样程序里的所有代码地址都需要重新进行计算修复
binding:修复指向外部的指针。比如app中调用了NSLog函数打印信息,NSLog是系统函数,在程序开始运行的时候app是不知道NSLog函数指针是多少,此时就需要通过dyld_stub_binder技术找到NSLog指针地址进行调用。
Objc setup
runtime在此处初始化,对class和category进行注册,selector唯一性判断
load&constructor&initialize
调用所有类的load的方法,初始化C&C++的静态化变量,然后调用 constructor 函数
main之后
main函数
创建整个app的autoreleasepool,初始化初始window,app界面开始展示
LifeCyle
指定rootviewcontroller,调用业务代码,完成各阶段业务
First Frame
main页面viewDidAppear 完成页面第一帧渲染。至此启动完成。
三、衡量 App启动时间
打点系统监控
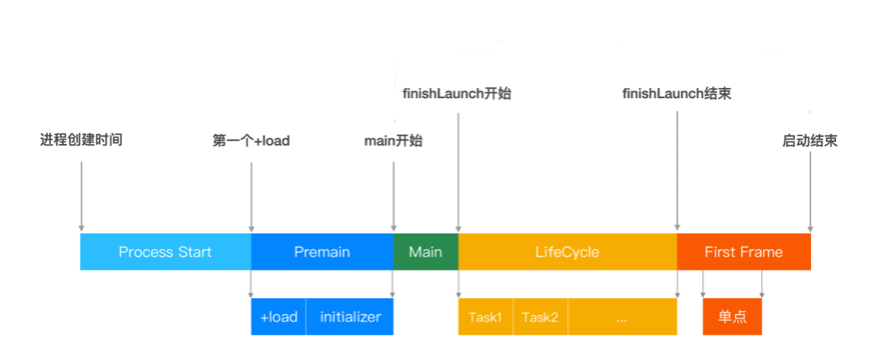
上图具体指明了目前能够做到的打点的地方,可以简化为下图形式:
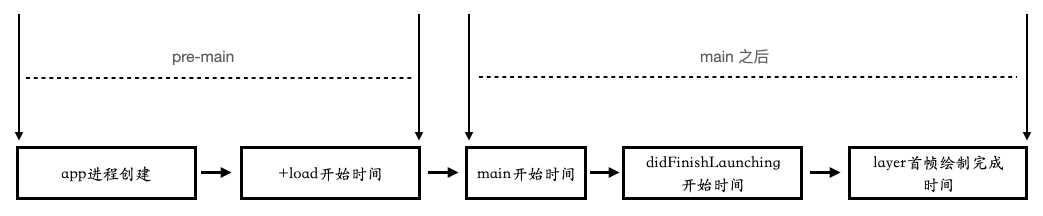
进程创建
通过 sysctl 系统调用拿到进程创建的时间戳
#import <sys/sysctl.h>
#import <mach/mach.h>
+ (BOOL)processInfoForPID:(int)pid procInfo:(struct kinfo_proc*)procInfo
{
int cmd[4] = {CTL_KERN, KERN_PROC, KERN_PROC_PID, pid};
size_t size = sizeof(*procInfo);
return sysctl(cmd, sizeof(cmd)/sizeof(*cmd), procInfo, &size, NULL, 0) == 0;
}
+ (NSTimeInterval)processStartTime
{
struct kinfo_proc kProcInfo;
if ([self processInfoForPID:[[NSProcessInfo processInfo] processIdentifier] procInfo:&kProcInfo])
{
return kProcInfo.kp_proc.p_un.__p_starttime.tv_sec * 1000.0 + kProcInfo.kp_proc.p_un.__p_starttime.tv_usec / 1000.0;
}
else
{
return 0;
}
}最早的 +load
和上面的分阶段监控一样,通过 AAA 为前缀命名 Pod,让 +load 第一个被执行
didFinishLaunching
此处监控可以使用第三方SDK,也可以手动加入打点来衡量
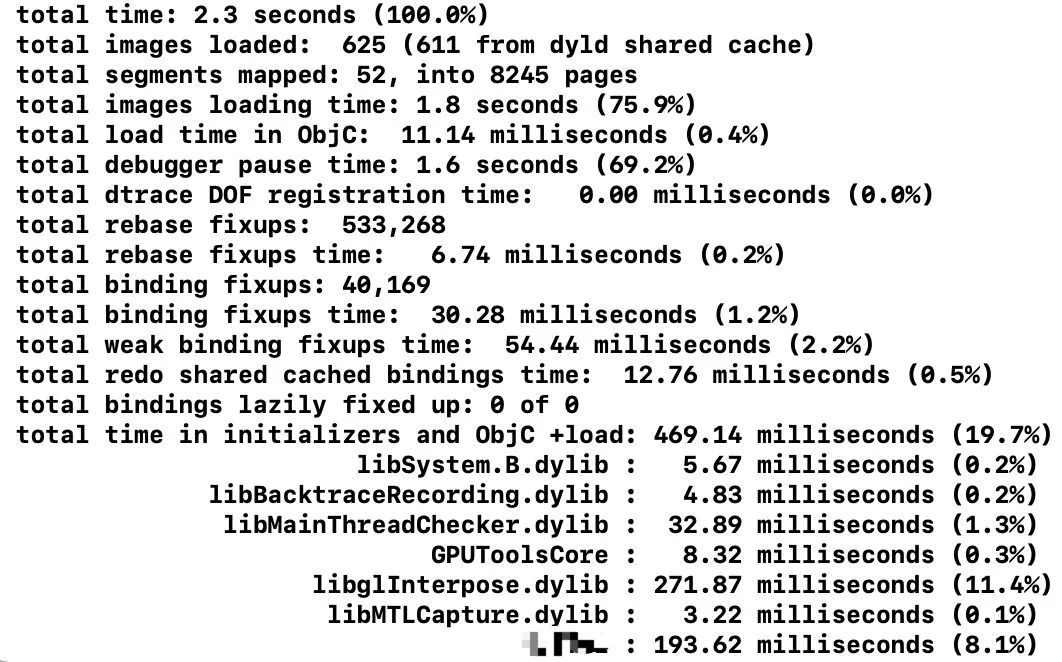
另外,对于pre-main阶段,Apple提供了一种测量方法,在 Xcode 中 Edit scheme -> Run -> Auguments 将环境变量 DYLD_PRINT_STATISTICS 设为1 。之后控制台会输出类似内容,我们可以清晰的看到每个耗时:
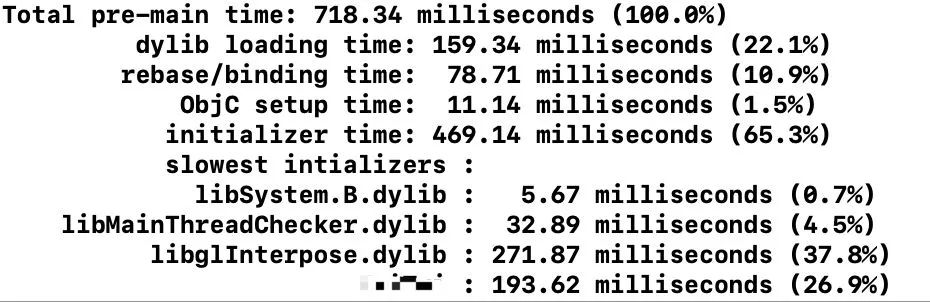
如果将 Edit scheme -> Run > Auguments 将环境变量 DYLD_PRINT_STATISTICS_DETAILS 设为1,则可以更多详细的pre-main阶段的耗时:
工具
TimeProfiler
Time Profiler是Xcode自带的时间性能分析工具,正常Time Profiler会1ms采样一次,默认只采集所有在运行线程的调用栈,最后以统计学的方式汇总。通过统计比较时间间隔之间的堆栈状态,来推算某个方法执行了多久,并获得一个近似值。Time Profiler的使用方法网上有很多使用教程,这里我们也不过多介绍,附上一篇使用文档:Instruments Tutorial with Swift: Getting Started。
取从开始启动后的2s内的时间为启动样本
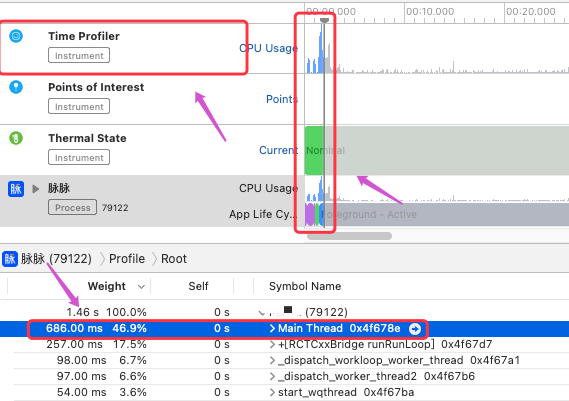
通过展开 Main Thread 经过分析发现,耗时方法在一个内存泄露检测模块,修改之后如下图:
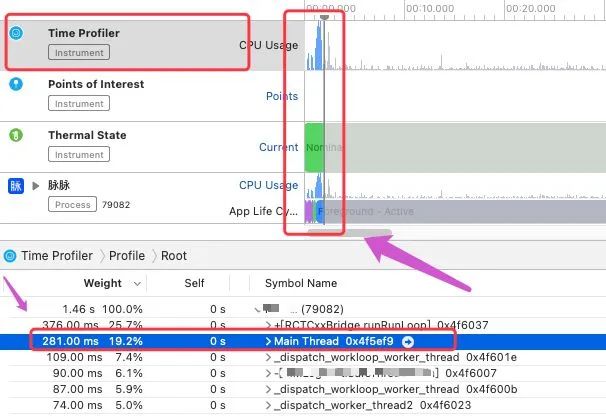
当然其他线程也有在做并发的处理,也要注意线程个数的控制
System Trace
System Trace一直作为Instruments中一个默默无闻的功能出现,模板提供了系统行为的全面信息。它显示线程的调度、系统线程的转化和内存使用情况。这个模板可以使用在OS X或iOS中。简单点说就是记录一个App运行过程中所有底层系统线程、内存的调度使用过程的工具。
脉脉iOS分析案例
现象
脉脉iOS在蜂窝网络数据状态下Debug,每次启动,相比WiFi状态下的启动时间都要长了2s左右
诊断过程
首先选中 System Load 选取时间线,到第一次出现 脉脉 线程的点,从这个时间点开始脉脉app正式启动,开始处理app内部逻辑。也就是main之后的阶段。
统计活跃的高优线程数量和CPU核心数对比,如果高于核心数量会显示成黄色,小于等于核心数量会是绿色。这个工具是用来帮助调试线程的优先级的。
系统维护了 5 个不同的线程优先级/QoS: background,utility,default,user-initiated,user-interactive。
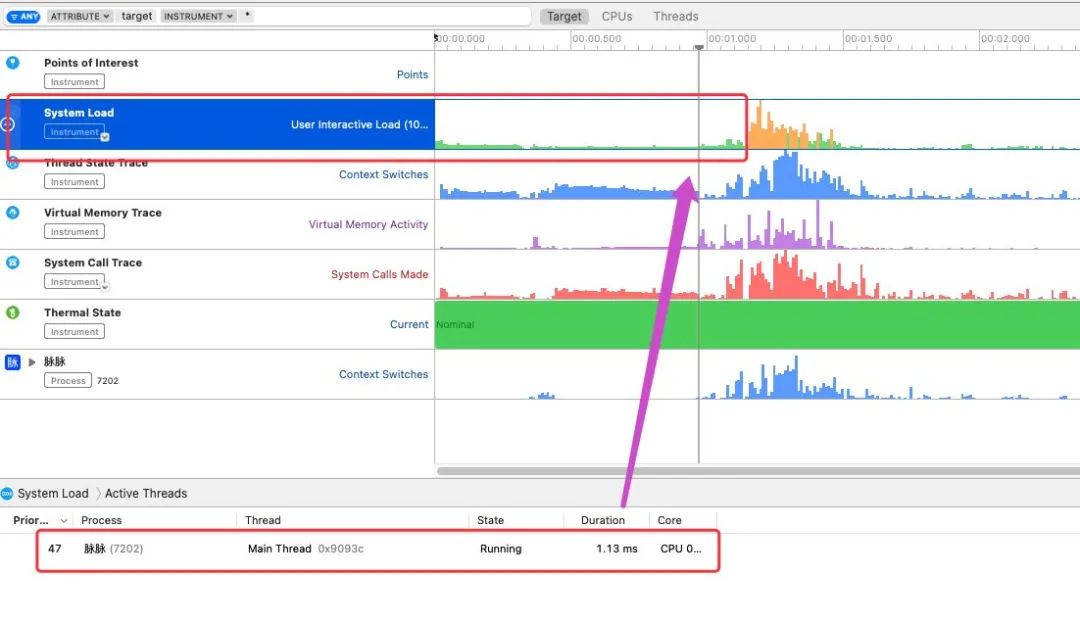
切换到主线程 Main Thread 看到一大块block的灰色状态,选取发现2.01s的卡顿,难道这是巧合?大胆猜测,这就是我们要找的卡顿2s
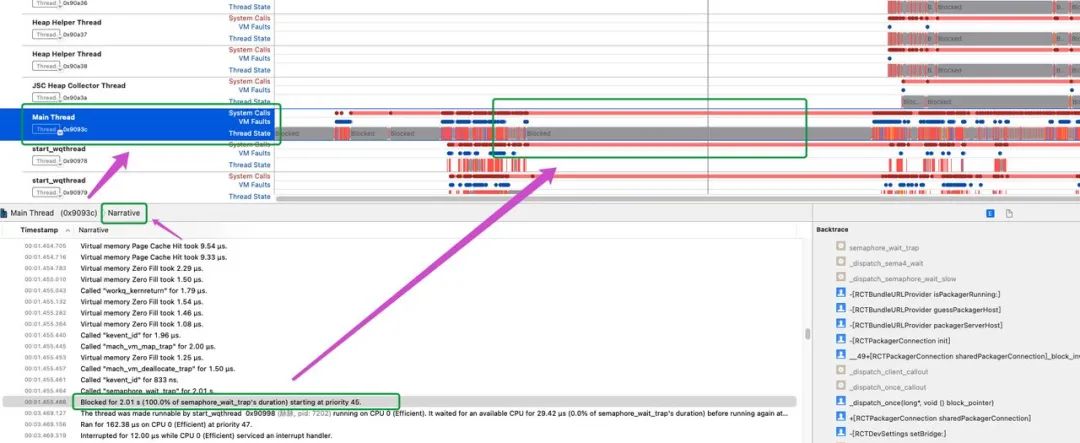
不要移动时间线,切换到 Events:Thread States,可以看到线程切换的每一个事件,和状态切换的发生的原因,观察这个事件的下一个事件,因为下个事件通常是锁被释放,线程重新进入可执行的状态。发现卡顿的下一步执行时 CPU0 上的 0x90998 的线程,换句话说是 0x90998 的线程使得主线程结束卡顿重新进入了可执行的状态。
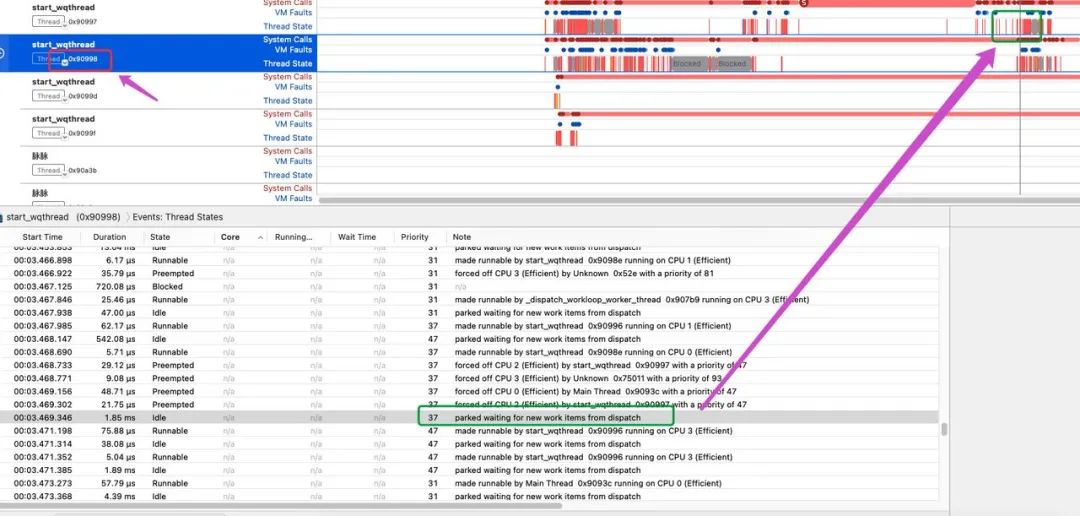
切换到 0x90998 线程,选中主线程block状态释放开始执行的时间点,可以看到 parked waiting for new woirk for dispatch,在往上追溯基本都是这句话的重复调用,可以大胆猜测基本上是在等待一个信号量。
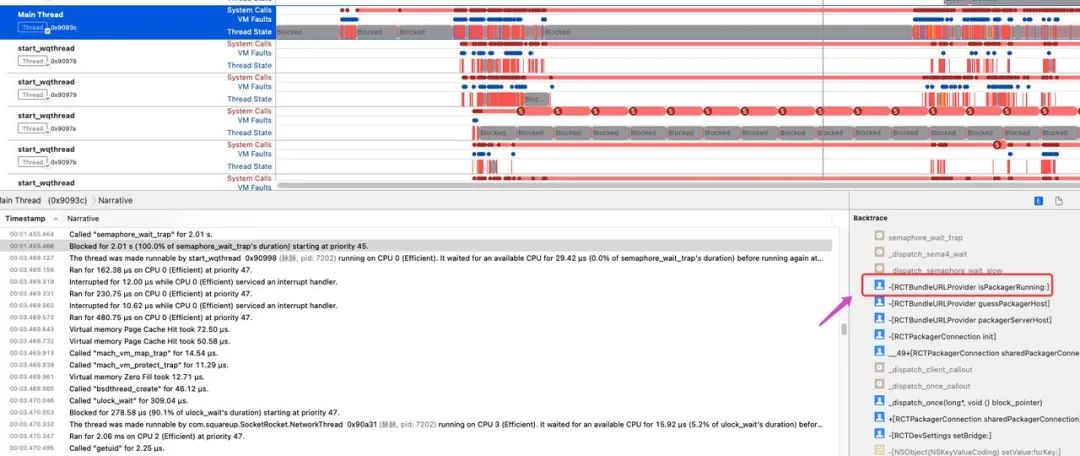
再次来到 Main Thread Block位置,双击右侧的堆栈栈顶那句话,可以看到具体的代码位置。
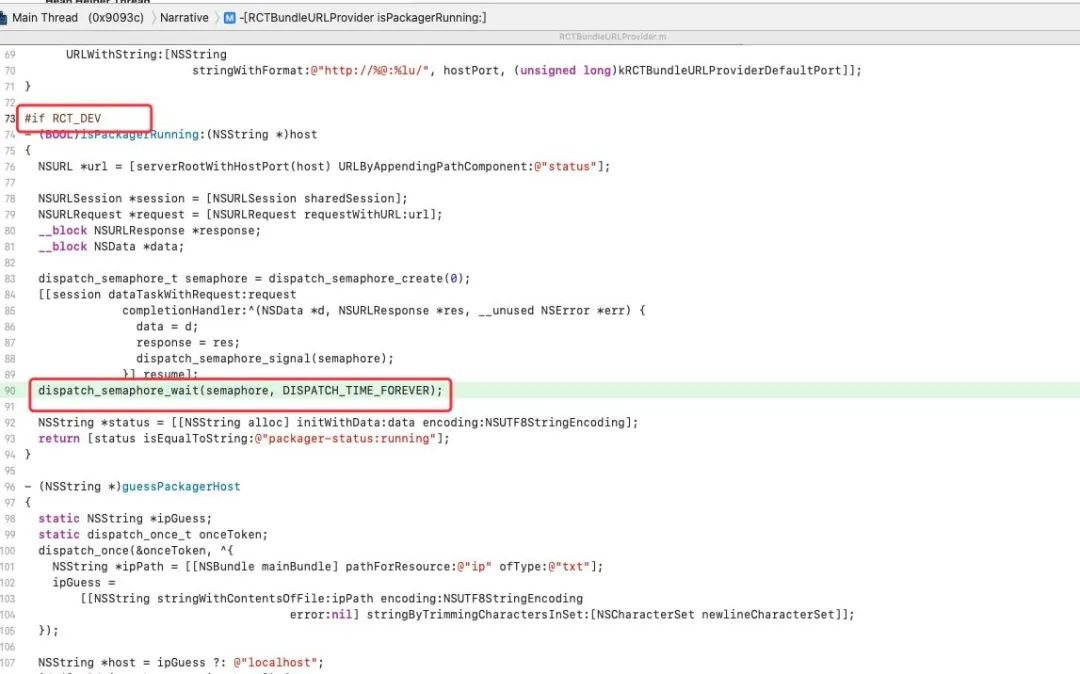
的确是在等待一个信号量,并且是 RCT_DEV 环境下才会生效,线上不受影响。通过Debug发现,这里请求的URL是 http://localhost:8081。
如果我们把这段代码注释,WiFi和5G流量下,启动速度相差无几。之前的猜测卡主2s是在等待信号的想法得到印证。
这也说明,有时就是要 敢猜敢想敢做!
通过SystemTrace工具 Debug 蜂窝数据流量环境下应用启动会卡主2s的问题终于查明!
手动下点分析
通过插桩代码,我们发现使用 OpenUDID 获取udid的时候耗时有时竟然达到400ms。分析后发现,读取 UIPasteboard 非常耗时,根据调研 UIPasteboard 使用场景在脉脉中基本可以忽略,故考虑去掉 UIPasteboard 读取逻辑。
但在 Time Profiler 里检测,OpenUDID 获取udid在所在的子线程,只消耗了 7ms。依靠 Time Profiler分析也有一定的局限性。
四、制定 App启动优化方案
整体思路
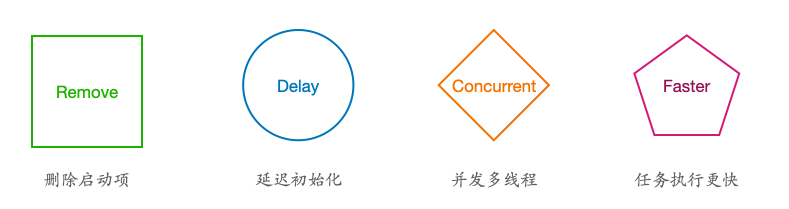
- 删掉启动项,把不需要的过时的直接删除
- 如果不能删除,尝试延迟,延迟包括第一次访问以及启动结束后找个合适的时间加载
- 不能延迟的可以尝试并发,利用好多核多线程。但也要注意控制好线程的数量和优先级
- 如果并发也不行,可以尝试让代码执行更快。比如,频繁访问的可以只获取一次就存下来
pre-main
动态库
防止劣化,需要严格管控动态库的引入
减少动态库
Apple官方建议尽量少的使用自定义的动态库,或者考虑合并多个动态库,其中一个建议是当大于6个的时候,则需要考虑合并它们。
自有动态库转静态库,或者合并动态库
源码形式的是可以通过CocoaPods命令转静态库的,如下
# CocoaPods 打包静态库 命令
# 其中 –library 指定打包成.a文件,如果不带上将会打包成.framework文件。–force 是指强制覆盖。
pod package xxxx.podspec --forceCocoaPods不使用 use_frameworks! 字段,全部引入静态库
rebase&binding 和 Objc setup:
减少代码量
1、基于Mach-O文件分析
objcselrefs 和 objcclassrefs 存储了所有引用到的 sel方法签名 和 class
__objc_classlist 存储了所已有的 sel 和 class
二者做个差集就知道哪些类和哪些类的 sel 用不到,但objc 支持运行时调用,删除之前还要在二次确认
2、通过打点SDK,收集代码使用数据情况,再决定要不要删除某些代码
脉脉会定期通过数据库脚本统计出日活小于10uv的页面vc和相关的view,和相关的业务线确认后会进行删除,以确保代码的有效性和简洁性。
3、通过脉脉自研的解耦合分析工具(后面会考虑开源,可以关注作者github: Andy.Li)
大致原理:数学集合运算
假如只有两个类a和类b,分析出类a提供的方法列表记为集合A,再分析出类b使用的类a的方法列表记为集合B。
集合A和集合B做差集C,集合C就类a中不再被类b使用的方法集合
此时就可以根据集合C从类a中删除对应的方法。
如果类a的所有方法都没有被类b使用,也就是类a完全不被类b使用,则可以直接删除类a。
类比到到项目中所有的类,做遍历递归差集,就可以得到全部的未被使用的类和方法,考虑删除之。
重新排列函数符号位置,降低MACH-O文件载入内存时PageFault缺页中断频率 - 二进制重排
原理
二进制重排实际上是在windows和linux上就存在的技术,旨在将启动用到的函数方法尽可能的放置在二进制文件加载的前面,并且是将函数符号地址连续的编译在一起,以减少Page Fault的次数和频率,加快启动速度。现在这项技术已经移植运用到了移动端app上。
如何理解PageFault缺页中断
操作系统为了解决安全问题和效率问题,抽象出了虚拟内存页的概念。内存都是分页访问的。这里的page指的就是内存页。(就像磁盘存储的最小单位 磁盘簇,大小是4k一样)
MacOS 、linux (4K为一页)
iOS(16K为一页)
PageFault就是缺页中断:当app调用一个方法,发现该方法没有在内存中,此时操作系统就会立刻阻塞整个app进程,触发一个缺页中断。操作系统会从磁盘中读取这页数据到物理内存上 , 然后再将其映射到虚拟内存上 ( 如果当前内存已满 , 操作系统会通过置换页算法 找一页数据进行覆盖,这也是为什么开再多的应用也不会崩掉 , 但是之前开的应用再打开时 , 就重新启动了的根本原因 )。
假如,app启动时期需要调用 method1、method5和method6,这三个方法分布在page1、page2和page3上。每装载一个内存页page都会发生一次PageFault(缺页终端)。通常一个PageFault的处理时间是0.1ms~1ms,取0.5ms计算。这三次处理PageFault时间是 3 * 0.5ms = 1.5ms。

二进制重排后

method1、method5和method6全都集中在了page1,这样只需装载page1就可以了。相比之前少了page2和page3的装载。少了两次处理PageFault时间。这次消耗的时间是 1 * 0.5ms = 0.5ms。节省了1ms
iOS App之所以能够使用二进制重排,是因为Xcode 已经提供好这个机制 , 并且 libobjc 实际上也是用了二进制重排进行优化 .
获取启动加载所有的函数的符号
只有准确获取了app启动所用到的函数方法,对其进行重新排列,才能做到启动加速,那么如何获取这些函数符号呢?
Hook
oc 或者 swift @objc dynamic 修饰的方法,调用都会通过 objc_MsgSend 发送消息,hook objc_MsgSend 可以做到这个方法的检测。但如果是可变参数个数,则需要汇编来获取参数
二进制静态扫描
Mach-O文件在特定段Segment和Section里存储着符号及函数数据,通过静态扫描Mach-O文件,主要是分析获取load方法和c++ constructor 构造方法。
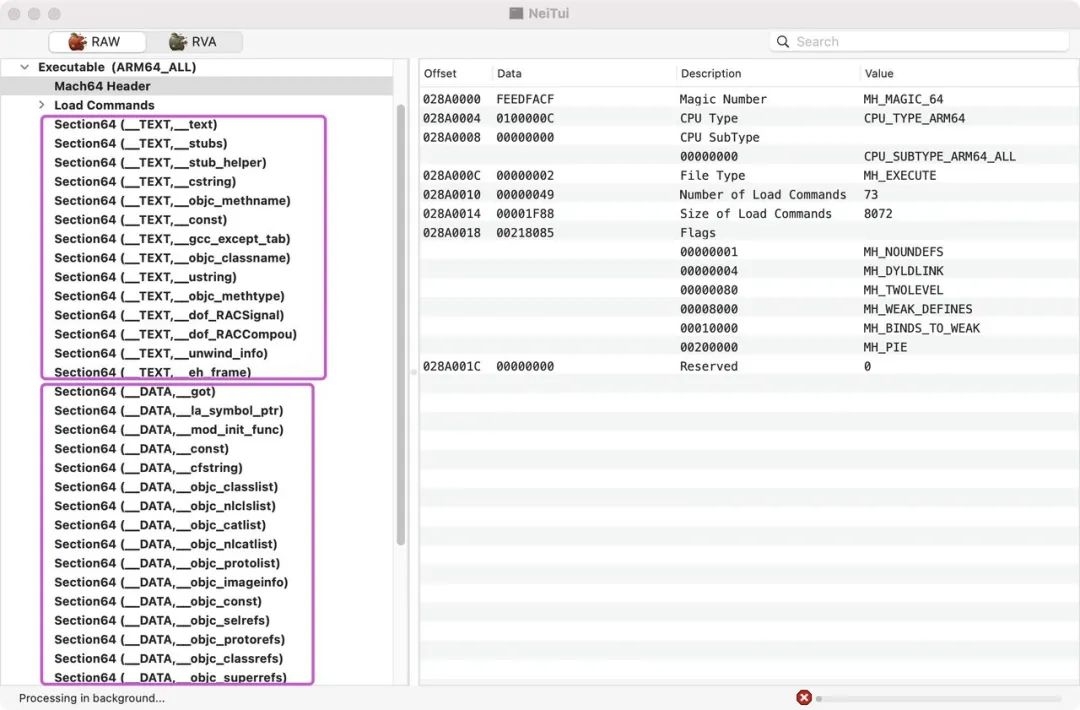
clang 汇编插桩
clang 本身已经提供了一个代码覆盖率检测机制(SanitizerCoverage),来实现我们获取所有符号的需求
前两种都或多或少存在一些问题,并不是完美的状态,网上的资料有很多,可以自行查阅。接下来主要是通过clang 插桩的方式来hook所有的函数符号
clang插桩
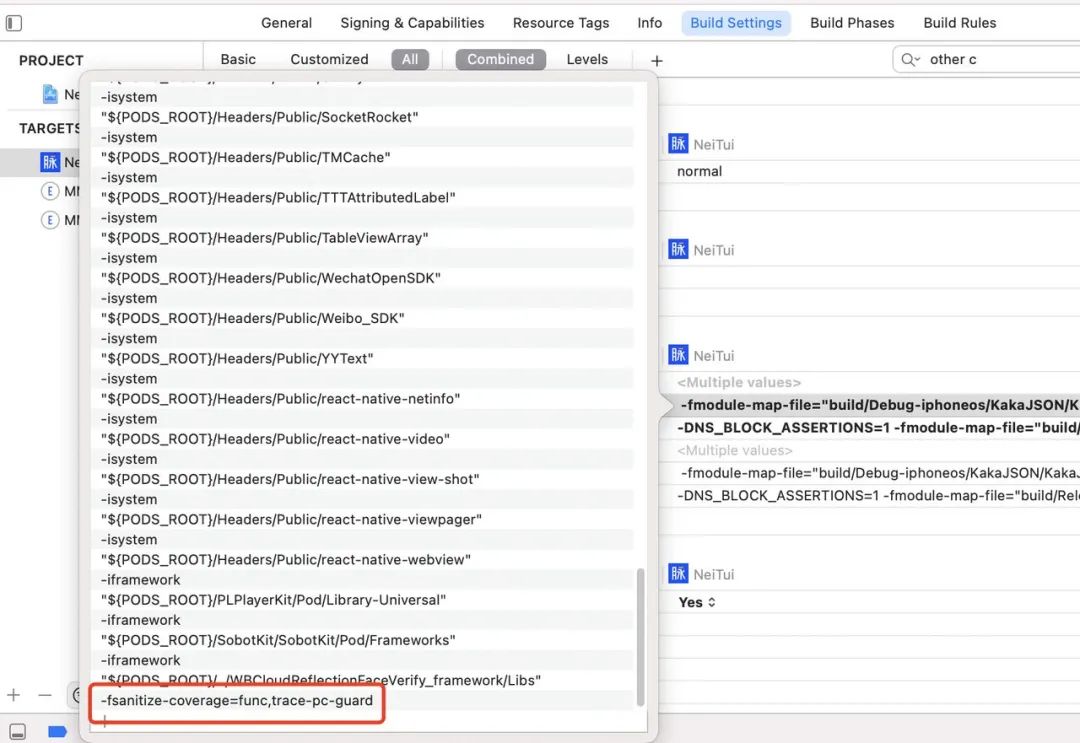
Xcode如何配置
在目标工程 Target -> Build Settings -> Other C Flags 添加 -fsanitize-coverage=func, trace-pc-guard。
如果有swfit代码,也要在 Other Swift Flags 添加 -sanitize-coverage=func 和 __-sanitize=undefined__
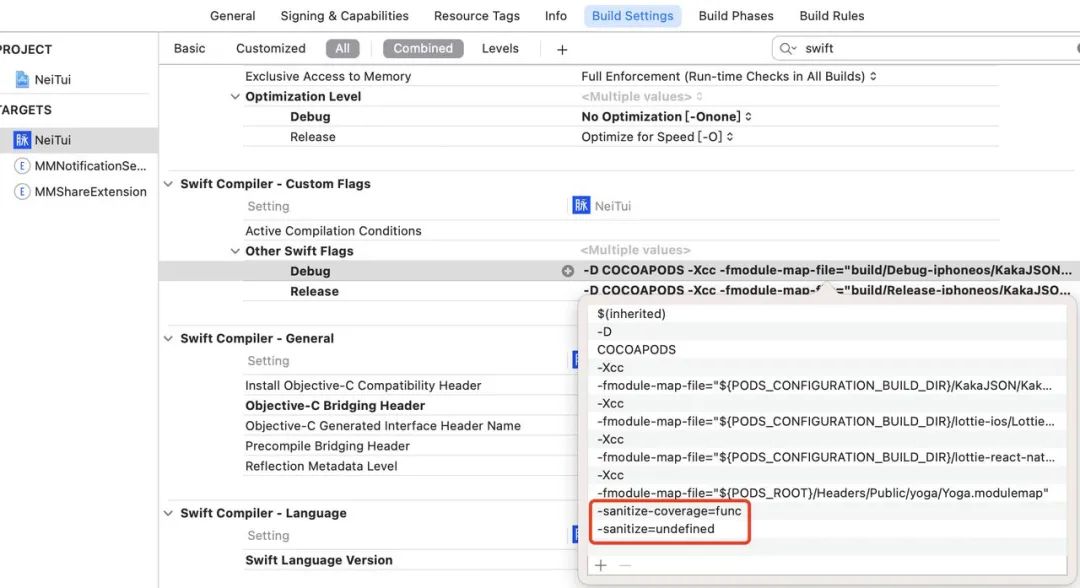
(如果有源码编译的Framework也要添加这些配置。CocoaPods引入的第三方库不建议添加上述配置)
添加hook代码
LLVM内置了一个简单的代码覆盖率检测(SanitizerCoverage)。它在函数级、基本块级和边缘级插入对用户定义函数的调用,并提供了这些回调的默认实现。在认为启动结束的位置添加代码,就能够拿到启动到指定位置调用到的所有函数符号。
void __sanitizer_cov_trace_pc_guard_init(uint32_t *start,
uint32_t *stop) {
static uint64_t N; // Counter for the guards.
if (start == stop || *start) return; // Initialize only once.
printf("INIT: %p %p\n", start, stop);
for (uint32_t *x = start; x < stop; x++)
*x = ++N; // Guards should start from 1.
}
//原子队列
static OSQueueHead symboList = OS_ATOMIC_QUEUE_INIT;
//定义符号结构体
typedef struct{
void * pc;
void * next;
}SymbolNode;
void __sanitizer_cov_trace_pc_guard(uint32_t *guard) {
//if (!*guard) return; // Duplicate the guard check.
void *PC = __builtin_return_address(0);
SymbolNode * node = malloc(sizeof(SymbolNode));
*node = (SymbolNode){PC,NULL};
//入队
// offsetof 用在这里是为了入队添加下一个节点找到 前一个节点next指针的位置
OSAtomicEnqueue(&symboList, node, offsetof(SymbolNode, next));
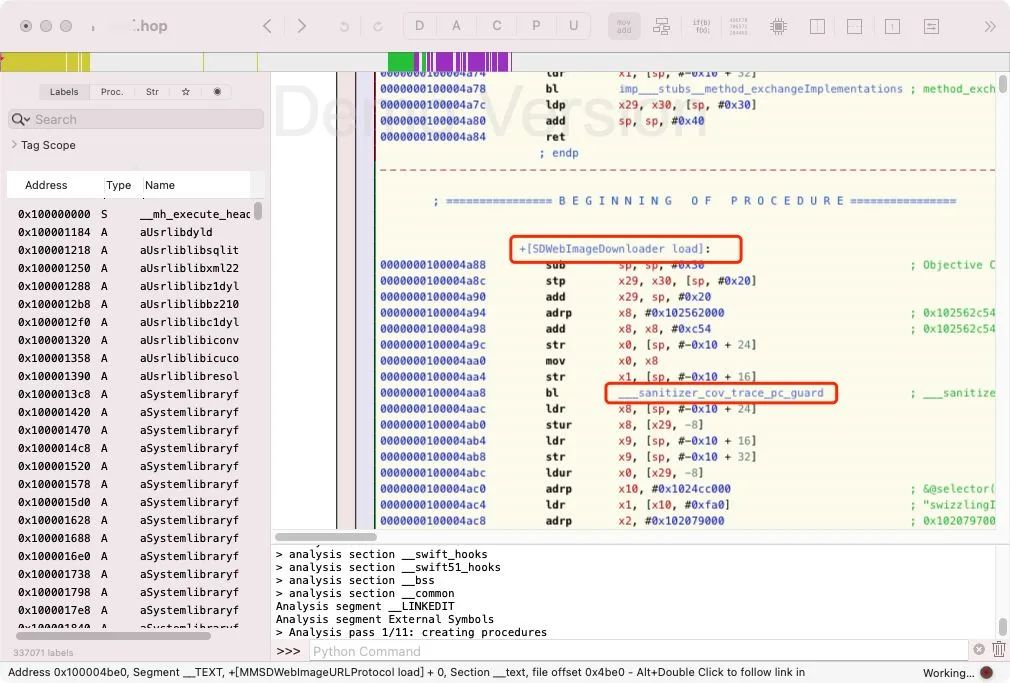
}运行工程,通过Hopper反编译工具可以看到在函数内部一开始就添加了 额外方法的汇编代码,这样就做到了 静态插桩
脉脉自研二进制重排预分析工具(已开源)
此工具详细介绍了如何生成 linked_map.txt 和 lb.order文件,以及如何预验证重排效果。
目的
在没有上线之前可以分析出对App启动优化节省的大致时间,起到指导作用。(具体能优化多少,以线上数据为准)
建议
因为工程的代码随着开发的进行会不断的改变位置或者删减,之前已经排好的顺序有些会失效。
每隔三个月执行一次二进制重排更新,确保 PageFault 次数维持在一个较低的稳定的水平。
输出示例
---> 分析结果:
linked map __Text(链接文件):
起始地址:0x100006A60
结束地址:0x1021E75E8
分配的虚拟内存页个数:2169
order symbol(重排文件):
需要重排的符号个数:4630
分布的虚拟内存页个数:392
二进制重排后分布的虚拟内存页个数:99
内存缺页中断减少的个数:293
预估节省的时间:146ms 如何反向验证
用二进制重排之后的工程,再次分别编译出 linked_map.txt 和 lb.order 文件,使用此工具再次运行检查。可以得到如下结果
---> 分析结果:
linked map __Text(链接文件):
起始地址:0x100006A60
结束地址:0x1021E75E8
分配的虚拟内存页个数:2169
order symbol(重排文件):
需要重排的符号个数:4630
分布的虚拟内存页个数:99
二进制重排后分布的虚拟内存页个数:99
内存缺页中断减少的个数:0
预估节省的时间:0ms 可以看出重排后的二进制文件已经不需要再次进行重排了。至此,二进制重排线下预评估结束。
工具开源地址:https://github.com/lyandy/Linked_Order_Analyze
load&constructor&initialize
+load 尽量不要使用
在 pre-main 时期,objc 会向 dyld 注册一个 init 回调,当 dyld 将要执行载入 image 的 initializers 流程时 (依赖的所有 image 已走完 initializers 流程时),init 回调被触发,在这个回调中,objc 会按照父类-子类-分类顺序调用 +load 方法。因为 +load 方法执行地足够早,并且只执行一次,所以我们通常会在这个方法中进行 method swizzling 或者自注册操作。也正是因为 +load 方法调用时间点的特殊性,导致此方法的耗时监测较为困难,而如何使监测代码先于 +load 方法执行成为解决此问题的关键点。
脉脉自研了一套 hook 监测 +load 执行时间方案,并结合 CocoaPods 实现了一行代码集成耗时监测的功能。(后续会开源)
__attribute__((constructor)) 尽量不要使用
如果函数被设定为 constructor 属性,则该函数会在 main 函数执行之前被自动的执行。执行时间太长,会大大增加启动时间。
C/C++静态化变量迁移
1、std:string 转换成 const char * 2、静态变量移动到方法内部
因为方法内部的静态变量会在方法第一次调用的时候初始化
main 之后
启动器
启动是需要一个框架来管控的,脉脉采用的是流控制方案。
为什么需要启动器呢?
全局并发调度
比如 AB 任务并发,C 任务等待 AB 执行完毕,框架调度还能减少线程数量和控制优先级
延迟执行
提供一些时机,业务可以做预热性质的初始化
精细化监控
所有任务的耗时都能监控到,线下自动化监控也能受益
管控
启动任务的顺序调整,新增/删除都能通过 Code Review 管控
脉脉自研的流控制器方案流程
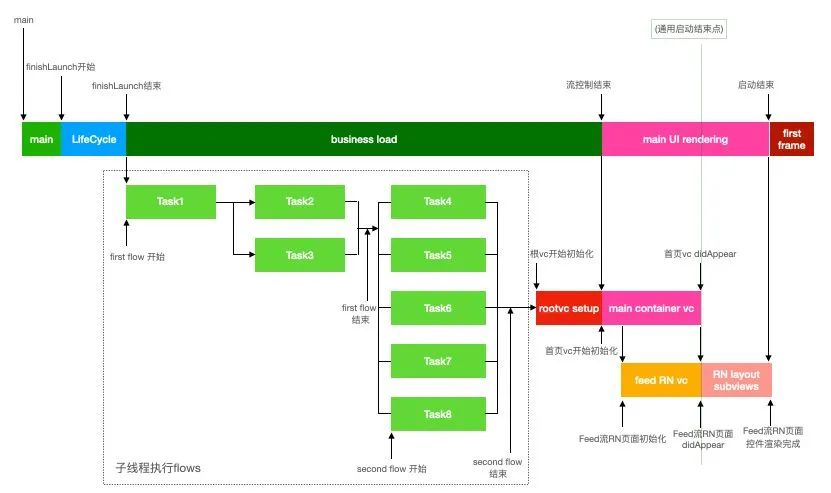
脉脉的启动流程大致分为三个阶段
流控制器
从Task1到Task8分为两个Flow Category,基础支撑Category和业务流Category。这些业务流flow中有广告、新手引导、资料补全引导、业务拉新等众多逻辑。解耦合和精细化管控每个Task所执行的代码,启动流程得以规范化治理,启动速度也大大加快。
主容器加载
包含了底部5个tab容器的加载,其中首页tab会被优先加载,其他4个懒加载。
RN首页首帧渲染
通常首页容器加载完毕,就认为是启动结束的点,如上图虚线的位置。但脉脉的启动结束点是首页RN Feed流第一帧渲染结束的点。
优化方式
三方SDK
有些三方 SDK 的启动耗时很高,将第三方SDK延后或并发。有些SDK已经分布在了不同的flow里并发,但flow内部还可以做并发,但要注意线程数量的控制
高频次方法
有些方法的单个耗时不高,但是在启动路径上会调用很多次的,这种累计起来的耗时也不低,比如读 Info.plist 里面的配置:
+ (NSString *)plistChannel
{
return [[[NSBundle mainBundle] infoDictionary] objectForKey:@"CHANNEL_NAME"];
}锁
线程间一些信号量等待锁,有可能会长时间卡主启动流程的方法,需要移除或者换种方式去做。
线程数量
线程的数量和优先级都会影响启动时间。在介绍 System Trace 工具的环节,有讲到高优先级线程和CPU数量的关系。瞬时开启过多的线程,占用了太多的内存和CPU,反而会拖慢启动速度
图片
启动难免会用到很多图,有没有办法优化图片加载的耗时呢?
用 Asset 管理图片而不是直接放在 bundle 里。Asset 会在编译期做优化,让加载的时候更快。
此外在 Asset 中加载图片是要比 Bundle 快的,因为 UIImage imageNamed 要遍历 Bundle 才能找到图。
加载 Asset 中图的耗时主要在在第一次张图,因为要建立索引,可以通过把启动的图放到一个小的 Asset 里来减少这部分耗时。每次创建 UIImage 都需要 IO,在首帧渲染的时候会解码。所以可以通过提前子线程预加载(创建 UIImage)来优化这部分耗时。
Fishhook
fishhook 是一个用来 hook C 函数的库,但这个库的第一次调用耗时很高,最好不要带到线上。fishhook 是遍历 Mach-O 的多个段来找函数指针和函数符号名的映射关系,带来的副作用就是要大量的 Page In,对于大型 App 来说在 iPhone X 冷启耗时 200ms+。
如果不得不用 fishhook,请在子线程调用,且不要在在 dyldregister_func_for_add_image 直接调用 fishhook。因为这个方法会持有 dyld 的一个全局互斥锁,主线程在启动的时候系统库经常会调用 dlsym 和 dlopen。其内部也需要这个锁,造成上文提到的子线程阻塞主线程。
首帧渲染
不同 App 的业务形态不同,优化方式也相差的比较多,几个常见的优化点:
LottieView
lottie 是 airbnb 用来做 AE 动画的库,但是加载动画的 json 和读图是比较慢的,可以先显示一帧静态图,启动结束后再开始动画,或者子线程预先把图和 json 设置到 lottie cache 里
Lazy 初始化 View
不要先创建设置成 hidden,这是很不好的习惯
AutoLayout
AutoLayout 的耗时也是比较高的,但这块往往历史包袱比较重,可以评估 ROI 看看要不要改成 frame
Loading 动画
App 一般都会有个 loading 动画表示加载中,这个动画最好不要用 gif,线下测量一个 60 帧的 gif 加载耗时接近 70ms
五、验证 脉脉App启动优化效果
pre-main
二进制重排效果
应用启动90分位耗时降低 600ms,且非常稳定
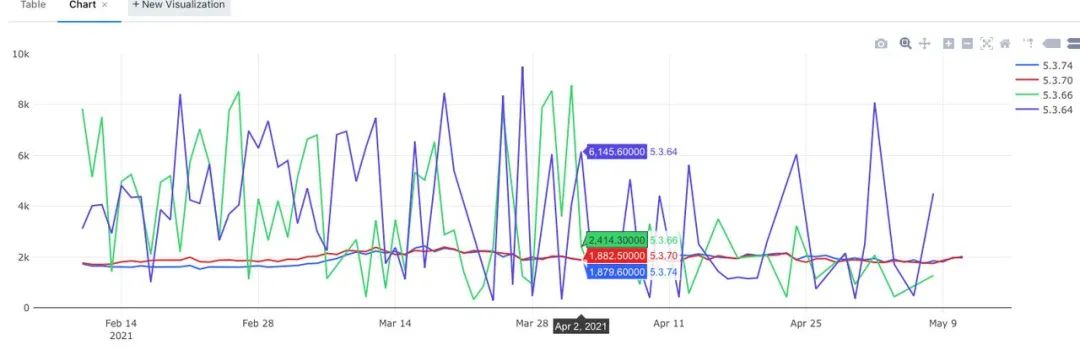
未重排的版本:5.3.64、5.3.66
已重排的版本:5.3.70、5.3.74
main 之后
启动耗时再次降低 500ms,实现了秒开
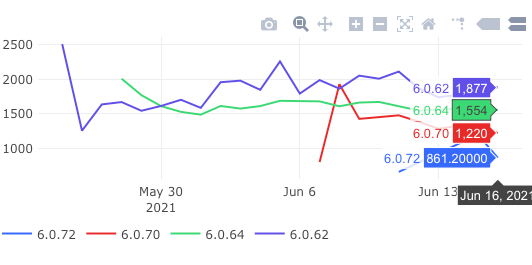
优化前的版本:6.0.62、6.0.64
优化后的版本:6.0.70、6.0.72
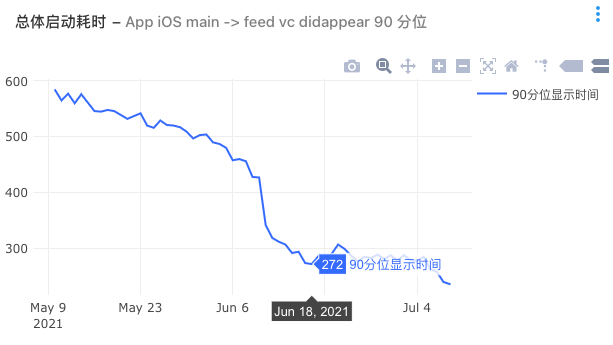
总体启动耗时native部分的优化,在2021年6月10号 6.0.70 版本上线后,由之前的600ms降到了270ms,降了接近300ms多。
同时通过统计从feed vc didappear到RN首帧渲染也降低了200ms左右。
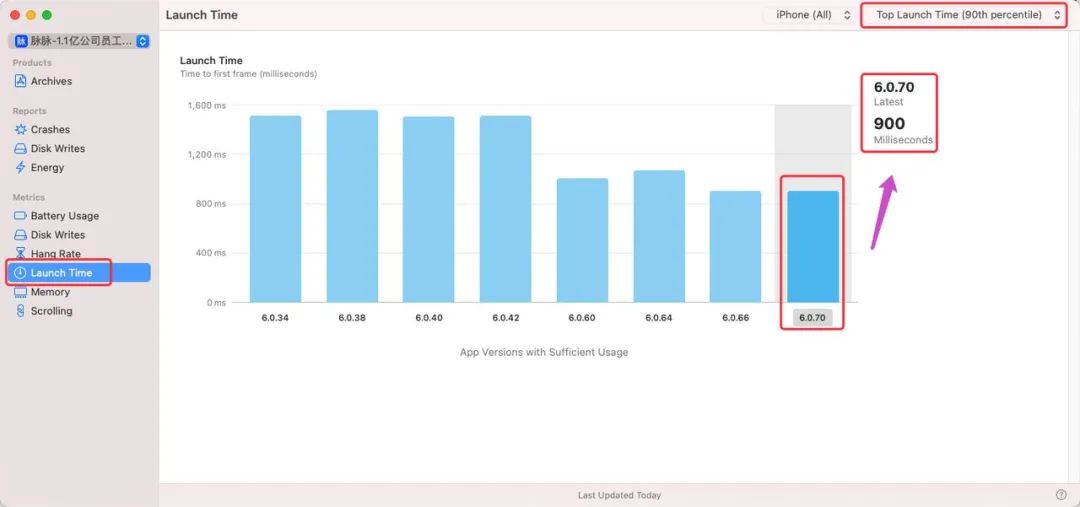
从Xcode自带的统计工具Organizer也可以看出,6.0.70版本启动时间90分位为900ms, 实现秒开
六、补充 非常规优化手段
+load 方法迁移
+load 除了方法本身的耗时,还会引起大量 PageFault,
另外 +load 的存在对 App 稳定性也是冲击,因为 Crash 了捕获不到。
举个例子,很多 容器需要把协议绑定到类,所以需要在启动的早期(+load)里注册
+ (void)load
{
[ProtocolClass registerClass:IMPClass forProtocol:@protocol(myProcotol)]
}本质上只要知道协议和类的对应关系即可,利用 clang attribute,这个过程可以迁移到编译期, 在Mach-O文件的末尾再添加一个Section段,Mach-O装载进内存加载Section段的时候,再去做Class和Protocol的对应关系。这种方式已经运用到脉脉自动化解耦合工具里。
typedef struct{
const char * cls;
const char * protocol;
}_mm_pair;
#if DEBUG
#define MM_SERVICE(PROTOCOL_NAME,CLASS_NAME)\
__used static Class<PROTOCOL_NAME> _MM_VALID_METHOD(void){\
return [CLASS_NAME class];\
}\
__attribute((used, section(_MM_SEGMENT "," _MM_SECTION ))) static _mm_pair _MM_UNIQUE_VAR = \
{\
_TO_STRING(CLASS_NAME),\
_TO_STRING(PROTOCOL_NAME),\
};\
#else
__attribute((used, section(_MM_SEGMENT "," _MM_SECTION ))) static _mm_pair _MM_UNIQUE_VAR = \
{\
_TO_STRING(CLASS_NAME),\
_TO_STRING(PROTOCOL_NAME),\
};\
#endif 当时脉脉iOS做解耦合的时候采用的,添加 ProtocolSect Section Data段
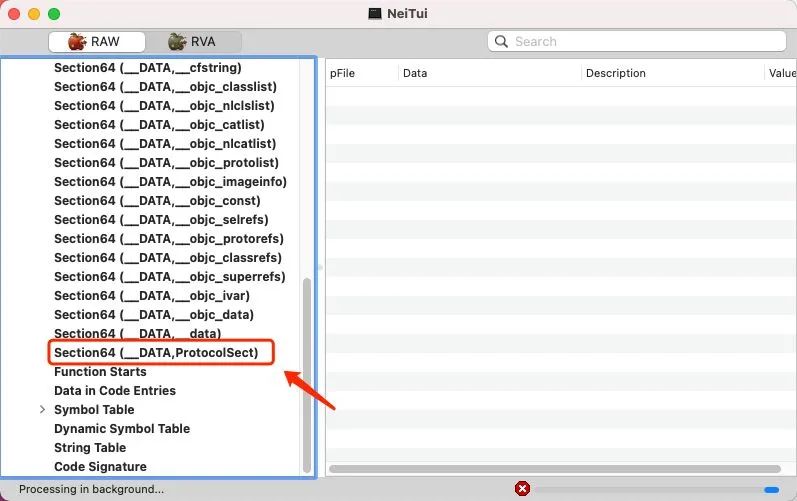
__Text段 重命名迁移
App Store 会对上传的 App 的 TEXT 段加密,在发生 PageFault 的时候会解密,解密的过程是很耗时的。
既然会 TEXT 段加密,那么直接的思路就是把 TEXT 段中的内容移动到其它段,ld 也有个参数 rename_section 支持重命名。
不建议使用此种方式优化,原因如下:
1、__TEXT 段迁移最难解决的问题是ld链接失败问题,是由 CPU 对寻址范围的限制以及 ld64 链接器的缺陷导致。 2、被迁移的__TEXT 段段,无法配合dSYM文件做符号化
PGO优化启动时间
PGO是苹果官方提供的工具,具体使用方法是点击xcode工具栏
Product -> Perform Action -> Generate Optimization Profile 按xcode提示操作即可
不建议使用此种方式优化,原因如下:
1、如果项目中有 swift 代码,那么这种方式就不能用了,因为 swift 不支持 PGO。
2、代码发生变更,Xcode 会提示 profdata file out of date,需要每个版本或者每隔一段时间重新生成